
Flink的Job啟動TaskManager端(原始碼分析)
前面說到了 Flink的TaskManager啟動(原始碼分析) 啟動了TaskManager
然後 Flink的Job啟動JobManager端(原始碼分析) 說到JobManager會將轉化得到的TDD傳送到TaskManager的RPC
這篇主要就講一下,Job在TaskManager端是如何啟動的
先來看一下,TaskManager端用來接收JobManager傳送過來的TDD物件的RPC介面
在TaskExecutor.java中

這個方法用於接收了一個TaskDeploymentDescriptor物件用於啟動任務(上一篇知道這裡executionGraph的每一個並行度都會呼叫deploy方法生成一個TDD)
來看一下具體接收到以後做了什麼


建立了一個Task並且將其內部的一個執行緒啟動起來了
注意這裡從TDD中得到了InputGate,Partition的資訊,用於建立InputGate,ResultPartition
InputGate用於對接上游產生的資料(消費)
ResultPartition用於往下游傳送自己產生的資料(生產)
來看一下Task建立,在Task的構造方法中
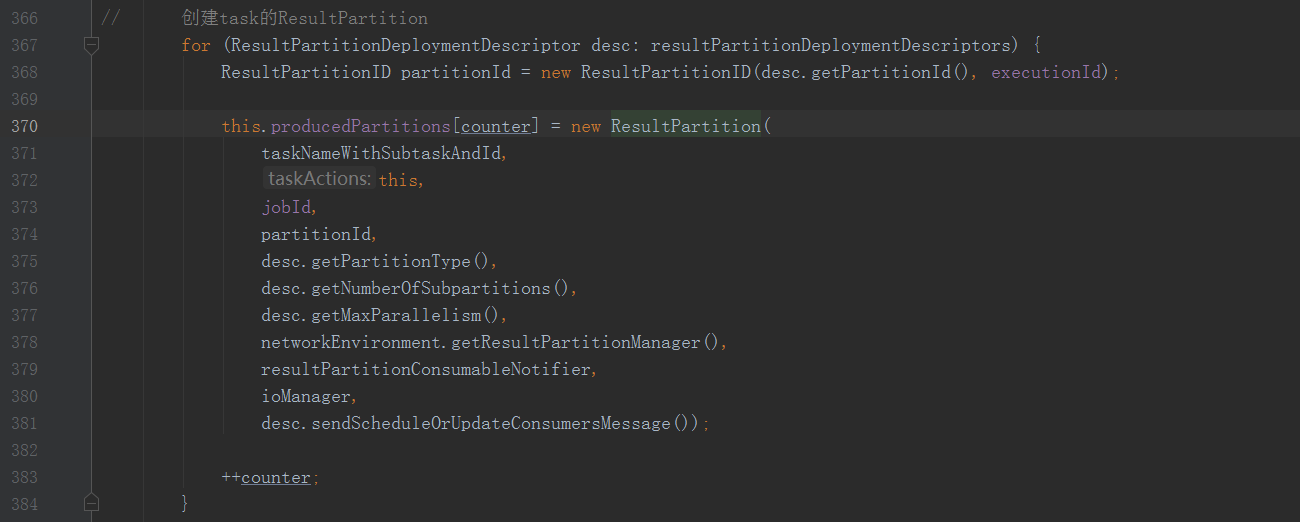
這裡看到建立了對應往下游傳送資料的ResultPartition
ResultPartition中建立的SubPartition具體分為
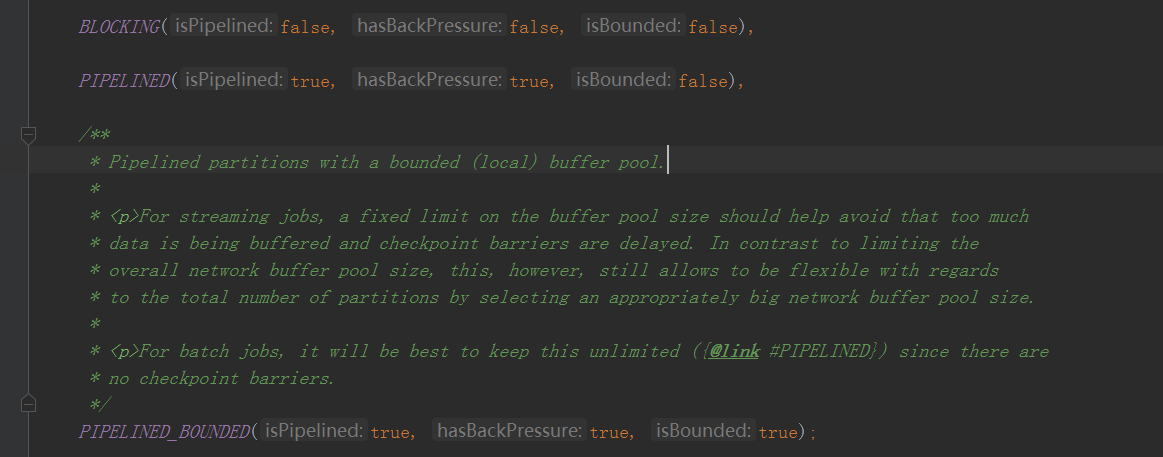
可以看到就是說三個引數分別對應
PIPELINED 可以邊消費邊生產,是有背壓的,這個partition沒有buffer數量的限制
(因為背壓的控制是通過,接收資料端公用同一個指定大小的bufferPool,以後背壓的時候講)
其他同理
這裡看一下不同型別的ResultPartitionType是建立的什麼subpartitions

BLOCKING 這種建立了一個SpillableSubpartition並且傳進去了一個ioManager(這個ioManager以後io管理細講)
大致看了一下就是說這種Subpartition是會落盤的
PIPELINED 而這種方式是完全基於記憶體的
根據上游的資訊建立好ResultPartition以後

接著建立了InputGate用於接收上游的資料,並且在create方法中

會根據partition的位置建立對應的channel,這裡可以分為
Local 就是說下游和自己是在同一臺機器
Remote 下游是需要通過網路傳送的

並且在這裡將inputGate和它所有的inputChannels關聯了起來
建立完inputGate以後Task就初始化完了,然後會被start()起來,來看下Task的run方法
在run方法中

這個地方會為初始化inputGate與ResultPartition的bufferPool(以後講到反壓在講)
繼續

這裡通過反射建立了一個StreamTask的例項
並且

呼叫了他的invoke()方法,這裡也是Job開始的邏輯,來看一下invoke方法
在invoke方法中

只要知道這裡會初始化OperatorChain這裡包含了我們使用者運算元的邏輯(這裡不細講,隨緣講到Task操作責任鏈的時候講)
然後得到了operatorChain的頭headoperator其實這裡的頭就包含了使用者的第一個運算元邏輯在裡面
然後init()方法中用上面的headoperator初始化了一個inputProcess物件並且關聯上了上面建立的inputGate(也是留到責任鏈講)
接著


這裡就是上面在init方法中建立的inputProcess,並且呼叫了他的processInput方法
重頭戲來了,來看一下processInput方法

這裡有個while(true)也就是說這裡會一直迴圈下去
來看一下他迴圈做什麼
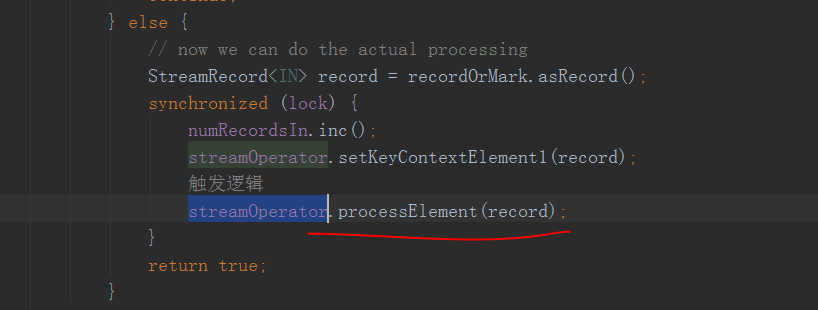
這裡!!!!這個streamOperator就是上面構造inputProcess時傳入的headOperator
這個processElement方法裡面就是呼叫使用者的方法啦
也就是不停的從上游接收到資料以後,呼叫使用者具體的處理邏輯
這裡job就啟動完成了
注意這個while迴圈內既然開始走我們使用者的邏輯,那肯定會先從inputGate關聯到的上游獲取資料
這裡就非常重要了,因為接收資料就包含了很多的機制的實現
包含了watermark處理的邏輯,水印對齊的邏輯,水印更新的邏輯,如下

以及idle停滯流邏輯,流狀態更新邏輯

以及如何接收資料邏輯,接收端反壓的邏輯,barriers對齊的邏輯,checkpoint觸發的邏輯

所以這個StreamInputProcessor.processInput()方法是一個非常重要的方法,以後隨緣更新各種機制的時候也會經常看到
&n