
Redis持久化的原理及優化
更多內容,歡迎關注微信公眾號:全菜工程師小輝~
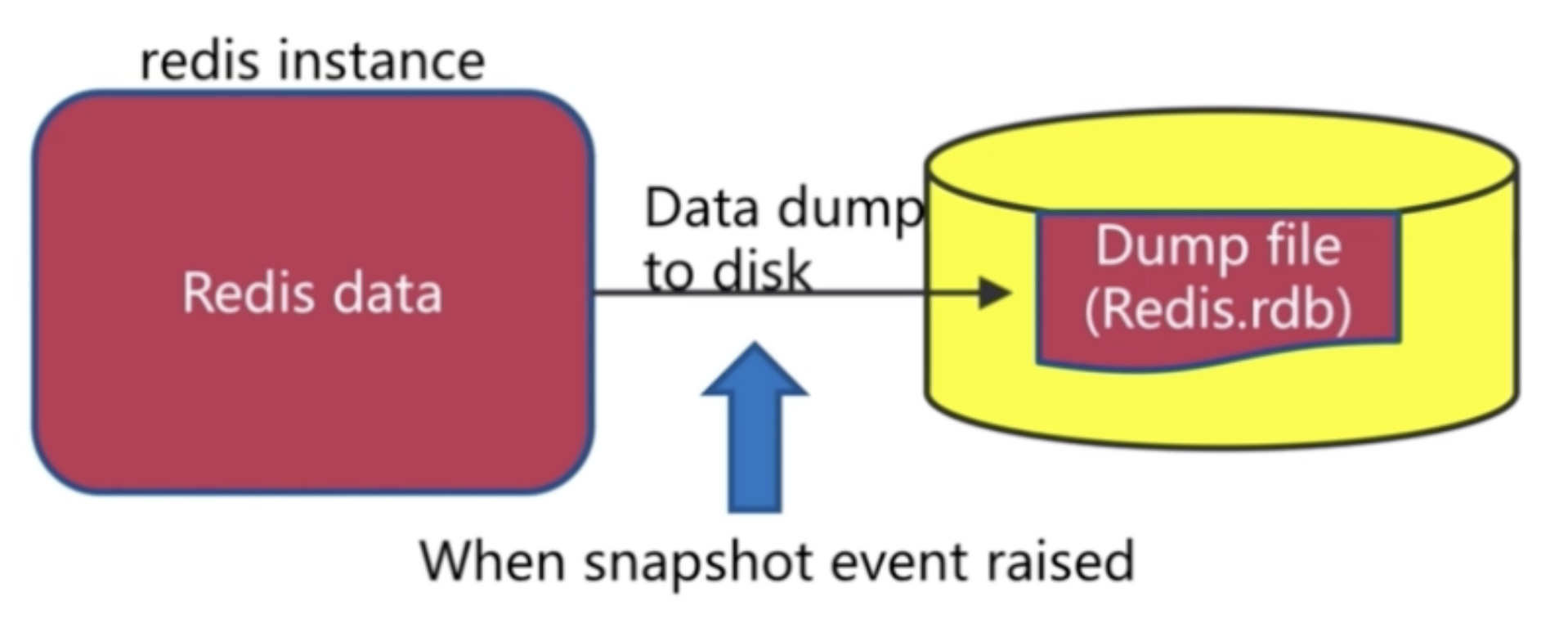
Redis提供了將資料定期自動持久化至硬碟的能力,包括RDB和AOF兩種方案,兩種方案分別有其長處和短板,可以配合起來同時執行,確保資料的穩定性。
RDB
儲存資料快照至一個RDB檔案中,用於持久化。RDB操作和Mysql Dump相似。
執行方式
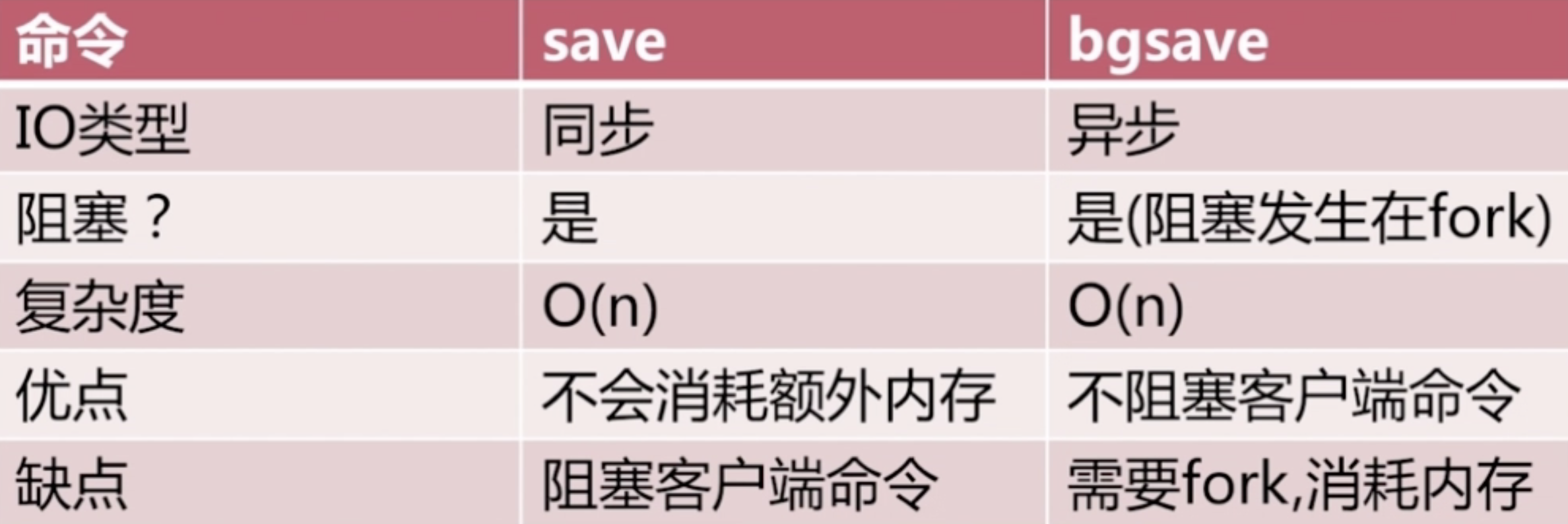
- save。同步操作,會阻塞Redis。
- bgsave。呼叫linux的fork(),然後使用新的執行緒執行復制。但是fork期間也會阻塞Redis,但是阻塞時間通常很短。
- 自動儲存。Redis配置檔案中設定了自動儲存的觸發機制,可以自定義修改,執行原理同bgsave。
save和bgsave的對比
注意:
- 如果機器上執行多個Redis,需要配置RDB檔名稱,否則多個Redis的RDB檔案會相互覆蓋。
除了上述三種執行方式,以下情況也會生成RDB檔案:
- 主從的全量複製時,主機會生成RDB檔案。
- Redis中的debug reload提供debug級別的重啟,不清空記憶體的一種重啟,這種方式也會觸發RDB檔案的生成。
- 執行shutdown時,會觸發RDB檔案的生成。
RDB的缺點
- 全量資料儲存,耗時。
- 雖然fork()採用copy-on-write策略,但仍消耗記憶體
- 寫RDB檔案消耗大量IO效能。
AOF
採用AOF持久方式時,Redis會把每一個寫請求都記錄在一個日誌檔案裡,AOF操作和Mysql Binlog相似。通過AOF重寫機制減少AOF檔案的體積,從而減少恢復時間。
執行方式
- always。Redis的每條寫命令都寫入到系統緩衝區,然後每條寫命令都使用fsync“寫入”硬碟。
- everysec。過程與always相同,只是fsync的頻率為1秒鐘一次。這個是Redis預設配置,如果系統宕機,會丟失一秒左右的資料
- no。由作業系統決定什麼時候從系統緩衝區重新整理到硬碟。

AOF重寫
為了解決AOF檔案體積膨脹的問題,Redis提供了AOF重寫功能:Redis伺服器可以建立一個新的AOF檔案來替代現有的AOF檔案,新舊兩個檔案所儲存的資料庫狀態是相同的,但是新的AOF檔案不會包含任何浪費空間的冗餘命令,通常體積會較舊AOF檔案小很多。
AOF重寫方式
- bgrewriteaof(流程與bgsave相似)
- AOF重寫配置(與RDB自動儲存相似)
AOF重寫並不需要對原有AOF檔案進行任何的讀取,寫入,分析等操作,這個功能是通過讀取伺服器當前的資料庫狀態來實現的。
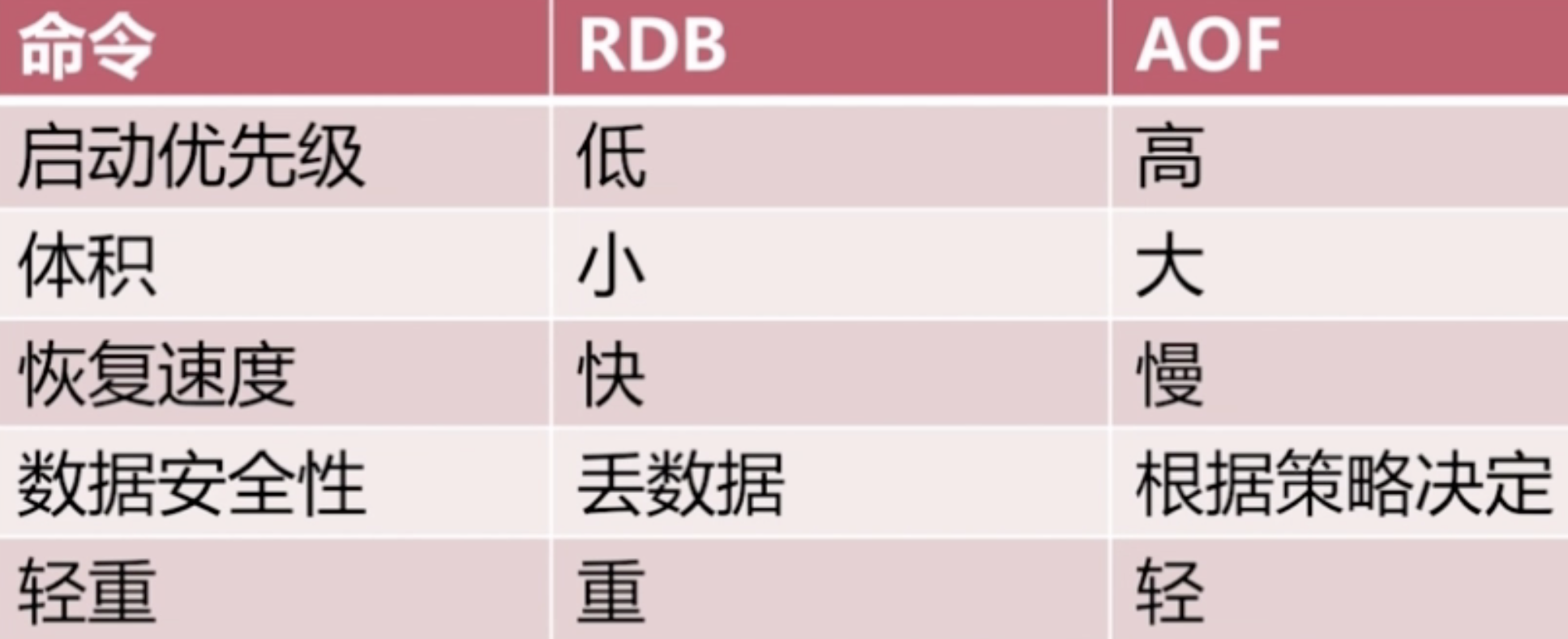
RDB vs AOF
Redis啟動時的資料載入
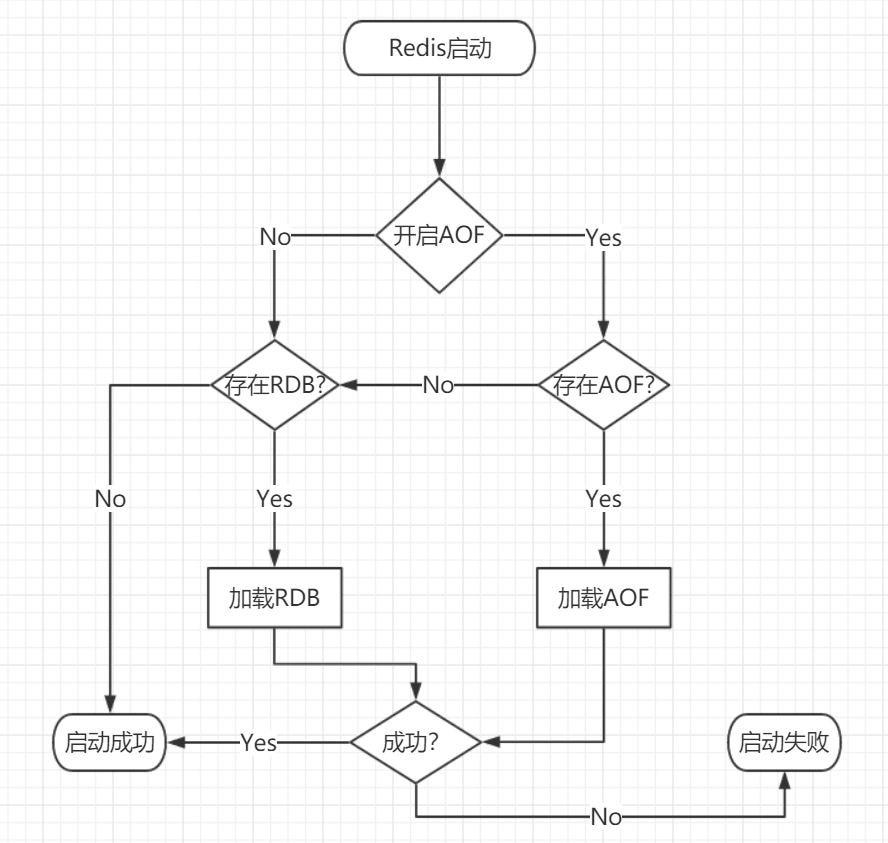
Redis啟動資料載入流程:
- AOF持久化開啟且存在AOF檔案時,優先載入AOF檔案。
- AOF關閉或者AOF檔案不存在時,載入RDB檔案。
- 載入AOF/RDB檔案成功後,Redis啟動成功。
- AOF/RDB檔案存在錯誤時,Redis啟動失敗並列印錯誤資訊。
開發運維中常見的問題
fork操作
fork()的實際開銷就是複製父程序的頁表以及給子程序建立一個程序描述符,所以速度一般比較快
記憶體量越大,耗時越長;物理機相對較快,虛擬機器相對較慢。
優化方法
- 優先使用物理機或者高效支援fork操作的虛擬化技術
- 控制Redis例項最大可用記憶體maxmemory
- 合理配置Linux記憶體分配策略:vm.overcommit_memory=1。預設值為0,會使Linux在記憶體分配時,發現不夠記憶體不足時,不會進行分配,進而造成fork阻塞
- 降低fork頻率。例如放寬AOF重寫自動觸發時機或者減少不必要的主從全量複製
程序外開銷
- CPU。RDB和AOF檔案生成,屬於CPU密集型。不要將Redis程序繫結在某個CPU上,防止單核過載;同時Redis不和CPU密集型應用一起部署。
- 記憶體。fork記憶體開銷,copy-on-write。
- 硬碟。AOF和RDB檔案的寫入。可以結合iostat和iotop進行分析。
優化方法
- 不要和高硬碟負載服務部署在一起:儲存服務、訊息佇列等
- 配置no-appendfsync-on-rewrite=yes。這樣在AOF重寫的期間,不要進行AOF追加操作(主執行緒只將資料寫入緩衝區),可以減少記憶體的開銷。
但如果AOF重寫期間,Redis宕機的話,在Linux的系統預設配置下,最多會丟失30s的資料。如果無法忍受資料丟失,no-appendfsync-on-rewrite配置no;如果應用系統無法忍受延遲,而可以容忍少量的資料丟失,則設定為yes。
- 根據寫入量決定磁碟型別:例如ssd
- 單機多例項持久化檔案目錄可以考慮分盤,或者使用類似cgroups機制進行硬碟資源的合理分配
AOF追加阻塞
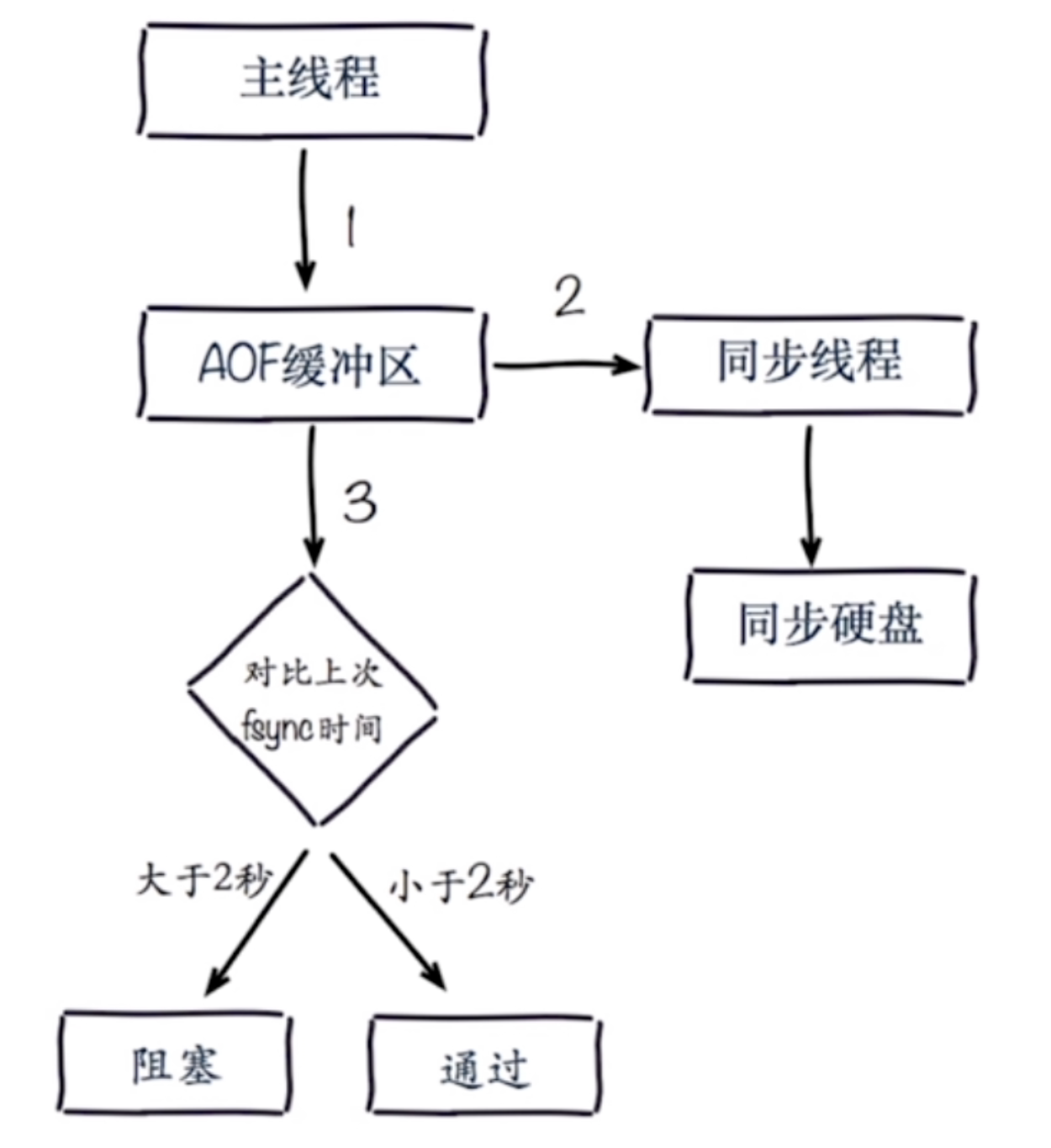
例如在AOF的everysec策略中,主執行緒會對比上次fsync的時間,如果距離上次fsync時間超過兩秒,就會造成主執行緒阻塞(等待同步執行緒同步完成)。
日常開發可以使用info persistence命令,檢視歷史發生AOF阻塞的次數;然而需要了解AOF追加阻塞的發生時間則需要檢視Redis日誌。
傳送AOF追加阻塞的時候,日誌如下:
Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.
優化方法(參考其他方面的優化點)
更多內容,歡迎關注微信公眾號:全菜工程師小輝~

相關推薦
Redis持久化原理及配置詳解(RDB方式和AOF方式)
Redis的強大功能很大程度上是由於其將所有資料都儲存在記憶體中。為了使Redis在重啟後仍能保證資料不丟失,需要將資料從記憶體中以某種形式持久化到硬碟中。Redis支援兩種持久化方式,一種是RDB方式,一種是AOF方式。可以單獨使用其中一種或兩種結合使用。(持
Redis持久化的原理及優化
更多內容,歡迎關注微信公眾號:全菜工程師小輝~ Redis提供了將資料定期自動持久化至硬碟的能力,包括RDB和AOF兩種方案,兩種方案分別有其長處和短板,可以配合起來同時執行,確保資料的穩定性。 RDB 儲存資料快照至一個RDB檔案中,用於持久化。RDB操作和Mysql Dump相似。 執行方式 save。
Redis -- 複製的原理及優化
Redis主從複製 什麼是主從複製 主從複製配置 全量複製和部分複製 故障處理 開發運維常見問題 Redis單機問題 機器故障 容量瓶頸 QPS瓶頸 主從複製的作用 資料副本
《【面試突擊】— Redis篇》-- Redis哨兵原理及持久化機制
能堅持別人不能堅持的,才能擁有別人未曾擁有的。關注程式設計大道公眾號,讓我們一同堅持心中所想,一起成長!! 《【面試突擊】— Redis篇》-- Redis哨兵原理及持久化機制 在這個系列裡,我會整理一些面試題與大家分享,幫助年後和我一樣想要在金三銀四準備跳槽的同學。我們一起鞏固、突擊面
【Spark 深入學習-08】說說Spark分區原理及優化方法
學習 格式 讀取文件 tmc 資料 數值計算 詳解 shc 存儲介質 本節內容 ------------------ · Spark為什麽要分區 · Spark分區原則及方法 · Spark分區案例 · 參考
JVM GC Collector工作原理及優化
情況 .cn 次數 線程 update mode -1 verify 測試 JVM 調優主要是調整GC以及一些執行參數: 目標: 堆不要太大,不然單次GC的時間過長導致服務器無法響應的問題 壓力測試的時候TPS平穩 盡量避免full GC 檢查是否用了並行的垃圾回收器
redis相關原理及面試官由淺到深必問的15大問題(高級)
申請 單線程 恢復 其余 異步 優先 follow 兩種 拓撲 1.redis是什麽? redis是nosql(也是個巨大的map) 單線程,但是可處理1秒10w的並發(數據都在內存中) 使用java對redis進行操作類似jdbc接口標準對mysql,有各類實現他的實現類
一文輕鬆搞懂redis叢集原理及搭建與使用
三種叢集策略: https://blog.csdn.net/q649381130/article/details/79931791 https://blog.csdn.net/qq_34337272/article/details/79982529 redis主從複製和叢集實現原理:
資料庫索引底層原理及優化
一、摘要 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型別,如BTree索引,雜湊索引,全文索引等等。為了避免混亂,本文將只關注於BTr
JVM原理及優化之二:記憶體管理
1. 記憶體分配策略: 1. 物件優先在Eden分配 2. 大物件直接進入老年代 3. 長期存活物件將進入老年代(當它的年齡增加到一定程度 (預設為15歲 ),就會被晉升到老年代中 。物件晉升老年代的年齡閾值,可以通過引數 -XX:MaxTenuringThreshold來
【基礎+實戰】JVM原理及優化系列之八:如何檢視JVM引數配置?
1. 檢視JAVA版本資訊 2. 檢視JVM執行模式 在$JAVA_HOME/jre/bin下有client和server兩個目錄,分別代表JVM的兩種執行模式。 client執行模式,針對桌面應用,載入速度比server模式快10%,而執行速度為server模
轉載:資料庫索引原理及優化
轉自:https://www.cnblogs.com/wuchanming/p/6886020.html 摘要: 本文內容主要來源於網際網路上主流文章,只是按照個人理解稍作整合,後面附有參考連結。 本文內容主要來源於網際網路上主流文章,只是按照個人理解稍作整合,後面附有
jvm原理及優化
jvm的啟動: 裝載配置 => 載入類 => 執行主方法 由類載入器載入類檔案到記憶體,包括堆,棧,方法區以及本地方法區等等,,, 方法區儲存類的資訊(常量池,欄位方法等資訊等等) 堆包含了應用程式中的系統物件 棧是執行緒私有,由一系列棧幀組成,每一次
redis持久化原理詳解
一、 Redis 提供了不同級別的持久化方式: Redis提供了兩種方式對資料進行持久化,分別是RDB和AOF。 RDB持久化方式能夠在指定的時間間隔能對你的資料進行快照儲存。 AOF持久化方式記錄每次對伺服器寫的操作,當伺服器重啟的時候會重新執行這些命令來恢復原始的資
資料庫索引原理及優化
本文內容主要來源於網際網路上主流文章,只是按照個人理解稍作整合,後面附有參考連結。 一、摘要 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL
kafka核心原理及優化措施
一、基本概念 介紹 Kafka是一個分散式的、可分割槽的、可複製的訊息系統。它提供了普通訊息系統的功能,但具有自己獨特的設計。 這個獨特的設計是什麼樣的呢? 首先讓我們看幾個基本的訊息系統術語: Kafka將訊息以topic為單位進行歸納。 將向Kafka topic釋出訊息的程式成為produce
Redis實現原理及作用
redis是一個key-value儲存系統。和Memcached類似,它支援儲存的value型別相對更多,包括string(字串)、list(連結串列)、set(集合)、zset(sorted set --有序集合)和hash(雜湊型別)。這些資料型別都支援push/p
Tomcat實現Session物件的持久化原理及配置方法介紹
當一個Session開始時,Servlet容器會為Session建立一個HttpSession物件。Servlet容器在某些情況下把這些 HttpSession物件從記憶體中轉移到檔案系統或資料庫中,在需要訪問 HttpSession資訊時再把它們載入到記憶體中。 實現: 要完成session持久化
mysql join的實現原理及優化思路
join的實現原理 join的實現是採用Nested Loop Join演算法,就是通過驅動表的結果集作為迴圈基礎資料,然後一條一條的通過該結果集中的資料作為過濾條件到下一個表中查詢資料,然後合併結果。如果有多個join,則將前面的結果集作為迴圈資料,再一次作為迴圈條件到後
Redis 複製原理及分析
############################## APPEND ONLY MODE ############################### # By default Redis asynchronously dumps the dataset on disk. If you can li