
大批量定時任務管理利器HashedWheelTimer
和同事討論一個定時稽核的需求,運營設定稽核通過的時間,到了這個時間之後,相關內容自動稽核通過,本是個小的需求,但是考慮到如果需要定時稽核的東西很多,這樣大量的定時任務帶來的一系列問題,然後逐步的討論到了netty的HashedWheelTimer這個的實現。
方案一 單定時器方案
描述:
把所有需要定時稽核的資源放到redis中,例如sorted set中,需要稽核通過的時間作為score值。後臺啟動一個定時器,定時輪詢sortedSet,當score值小於當前時間,則執行任務稽核通過。
問題
這個方案在小批量資料的情況下沒有問題,但是在大批量任務的情況下就會出現問題了,因為每次都要輪詢全量的資料,逐個判斷是否需要執行,一旦輪詢任務執行比較長,就會出現任務無法按照定時的時間執行的問題。
方案二 多定時器方案
描述
每個需要定時完成的任務都啟動一個定時任務,然後等待完成之後銷燬
問題
這個方案帶來的問題很明顯,定時任務比較多的情況下,會啟動很多的執行緒,這樣伺服器會承受不了之後崩潰。基本上不會採取這個方案。
方案三 借用redis的過期通知功能
描述
和方案一類似,針對每一個需要定時稽核的任務,設定過期時間,過期時間也就是稽核通過的時間,訂閱redis的過期事件,當這個事件發生時,執行相應的稽核通過任務。
問題
這個方案來說是借用了redis這種中介軟體來實現我們的功能,這中實際上屬於redis的釋出訂閱功能中的一部分,針對redis釋出訂閱功能是不推薦我們在生產環境中做業務操作的,通常redis內部(例如redis叢集節點上下線,選舉等等來使用),我們業務系統使用它的這個事件會產生如下兩個問題
1、redis釋出訂閱的不穩定問題
2、redid釋出訂閱的可靠性問題
具體可以參考
方案四 Hash分層記時輪演算法
也許你和我一樣都是第一次聽說這個東西,這個東西就是專為大批量定時任務管理而生。具體論文詳見參考文獻[2]
演算法概要
簡要的說這個是一個輪,裡面有指標,指標會根據設定的時間單位旋轉,任務根據一些演算法會落在相應的槽位上。如下圖
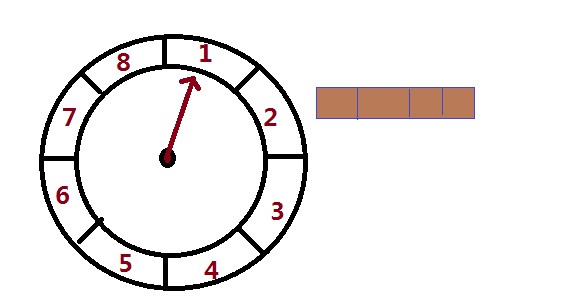
首先會有一個輪,這個輪在這裡分成了8個槽位,任務任務新增的時候會根據相應的演算法對槽位個數取模,得到任務會儲存在具體哪個槽位,每個槽位是一個連結串列結構,任務儲存了任務的過期時間(任務執行時間),任務需要執行需要指標轉的輪數,指標(tick)
例如上圖: 槽位為8個槽位 Bucket 指標每個時間間隔(100ms)會往下走一個槽位,這個時間間隔叫做tickDuration 那相當於每隔8*100ms=800ms,會輪詢一圈。
HashedWheelTimer
演算法理解起來比較簡單,並且也有成熟的實現,那就是在netty中有一個HashedWheelTimer這個類,把這個演算法實現了出來。接下來分析分析一下它的這個程式碼。
初始化
在這個類上定義的有幾個比較重要的屬性
/**
*這個work是一個內部類,實現了Runable介面,是比較核心的一個類,包裝了具體任務的執行,把任務放到具體如何放到某個槽位上,指標往下走的具體方法,任務取消等。
*/
private final Worker worker = new Worker();
/**
*工作執行緒,這個就是整個HashedWheelTimer啟動的起點
*/
private final Thread workerThread;
/**
*當前任務的狀態,1代表任務已經開始執行,0任務初始化,2任務已關閉
*/
public static final int WORKER_STATE_INIT = 0;
public static final int WORKER_STATE_STARTED = 1;
public static final int WORKER_STATE_SHUTDOWN = 2;
/**
*這個很核心的一個概念,就是指標往下走的單位,在HashedWheelTimer這個類中,預設是100ms指標往下走一個單位
*/
private final long tickDuration;
/**
* 這個就是指的時間輪,有多少個槽位,wheel的大小就是多大,HashedWheelTimer中預設槽位有512個
*/
private final HashedWheelBucket[] wheel;
/**
* 主要輔助計算任務會儲存在哪個槽位上,mask =wheel.length-1
*/
private final int mask;
/**
*所有要執行的任務的任務佇列
*/
private final Queue<HashedWheelTimeout> timeouts = PlatformDependent.newMpscQueue();
/**
*所有要取消的任務的任務佇列
*/
private final Queue<HashedWheelTimeout> cancelledTimeouts = PlatformDependent.newMpscQueue();
/**
*HashedWheelTimer例項開始執行的時間,是納秒數,開始時間是System.nanotime()
*/
private volatile long startTime;
這些屬性的定義和概念對映到上面時間輪演算法上就是下圖的樣子了。

HashedWheelTimer初始化主要是在它的建構函式中,提供了多種過載方式,只需要看最全的建構函式即可。
/**
* Creates a new timer.
* @param threadFactory 執行任務的工廠
* @param tickDuration 指標往下走一步的時間間隔
* @param unit 指標往下走一步的時間單位,秒,毫秒。納秒等
* @param ticksPerWheel 時間輪的大小,也就是槽位的個數
*/
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts) {
/**
* 先校驗引數的合法性,對threadFactory,時間單位,時間間隔,時間輪大小做了限制
*/
if (threadFactory == null) {
throw new NullPointerException("threadFactory");
}
if (unit == null) {
throw new NullPointerException("unit");
}
if (tickDuration <= 0) {
throw new IllegalArgumentException("tickDuration must be greater than 0: " + tickDuration);
}
if (ticksPerWheel <= 0) {
throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);
}
// 建立槽位,實際上就是初始化HashedWheelBucket陣列,直接new出來的
wheel = createWheel(ticksPerWheel);
//用來計算槽位的輔助變數,一會兒會在Worker中尋找槽位時使用到
mask = wheel.length - 1;
...
//初始化執行緒,是用threadFactory創建出來的一個worker執行緒
workerThread = threadFactory.newThread(worker);
...
}
任務新增和執行
當需要新增一個定時任務的時候,是通過newTimeout方法新增的,新增的任務必須實現TimerTask介面的run方法。任務新增之後,無需顯式的開啟任務,新增之後任務會自動開啟,等到了執行的時間會被自動執行。客戶端使用的方式如下:
@Test
public void testRun() throws Exception{
final CountDownLatch latch = new CountDownLatch(1);
HashedWheelTimer hashedWheelTimer = new HashedWheelTimer();
hashedWheelTimer.newTimeout(timeout -> {
System.out.println("hello world");
latch.countDown();
}, 5, TimeUnit.SECONDS);
latch.await();
System.out.println("執行結束");
}
5秒鐘之後會被輸出"hello world",然後任務執行完畢。既然任務的新增和執行入口都是通過newTimeout這個方法搞定的,那就看一下這個方法裡面有哪些祕密吧。
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
...
start();
...
/**
* 可以看到任務存活的時間計算,當前時間的毫秒數加上我們設定的時間,然後減去程式開始執行的時間。這是一個時間段
*/
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}
進去看了之後,這個方法很簡單,有兩個關鍵的方法呼叫 1、start(),這個方法主要是看當前HashedWheelTimer的狀態是否已經啟動,如果沒有啟動則會呼叫workThread執行緒的啟動方法。2、計算超時時間和任務新增。我們傳進來的任務會被包裝成一個HashWheelTimeout這個類,包裝之後會把這個包裝類放到timeouts這個阻塞佇列中去,實際上這時候任務並沒有放到某個具體槽位中,只是先放到阻塞佇列中,等待work從這個佇列中取值然後放到具體的槽位上,HashedWheelTimer是一個雙向連結串列,上面圖中已經有這個類的類圖結構,再貼一次:

我們傳進來的任務就是它的task屬性,然後會根據當前時間、過期時間和任務開始時間計算出它的deadline,同事計算出它剩餘的輪數(remainingRounds)。
任務執行實際上是呼叫的它的expire方法。當expire的時候會呼叫具體的業務任務的run方法。
那HashedWheelTimer的expire方法是什麼時候被執行的呢。上面也也說到在HashedWheelTimer中有一個workThread,這裡面會執行work。能讀到這個地方來的人應該很少了吧,不過能到這個地方你是幸運的,因為work這個類也就是實現這個演算法中最核心的一個類了,先來概覽一下這個類
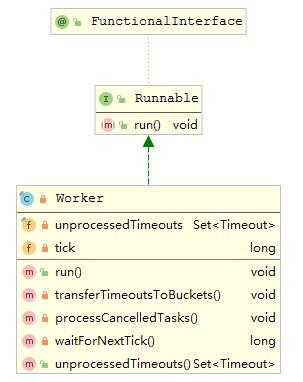
這個類實現了Runable介面,也就說是一個執行緒類,然後它會被workTread呼叫執行啟動。
- transferTimeoutsToBuckets 把新加入的定時任務從阻塞佇列中取出然後放到相應的bucket中
- processCancelledTasks 把取消的定時任務從阻塞佇列中取出,然後從相應的bucket中remove掉
- waitForNextTick 指標往下走的方法,經過一個時間單位,指標會往下走,指向下一個bucket
run方法會一直迴圈從阻塞佇列中取值,然後放到bucket中,指標迴圈往下走,對remainderRounds對於0的任務進行執行,不是0的減一
do {
/**
* 裡面是一個Thread.sleep操作,模擬指標一步一步往下走的操作。
*/
final long deadline = waitForNextTick();
if (deadline > 0) {
/**
* 計算任務將要落到槽位,這本應該是個取模運算,不過這裡用了一個小技巧,就是把取模運算換為了“按位與”,因為“按位與”要比取模運算快的多,
* 這個技巧就是當mast的值為2的n次方-1時,能達到取模的效果。這裡要感謝一下王洪濤的分享
*/
int idx = (int) (tick & mask);
processCancelledTasks();
//取到具體bucket,然後把任務放從阻塞佇列中拿到,放到bucket中
HashedWheelBucket bucket =
wheel[idx];
transferTimeoutsToBuckets();
//這裡面會呼叫所有HashedWheelTimeout的方法,就是看他的剩餘的輪數是不是大於0,如果是的話則會被執行,不是的話剩餘輪數減1
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
小結
到此原始碼部分的分析基本上也就完畢了。當然還有一些取消任務的操作沒有分析,這些無外乎是一些反向操作。再拿來原始碼看一眼即可。這個裡面涉及到的東西比較多,有很多的java的高階的用法,實際上是可以嘗試借鑑的,例如自定義的阻塞佇列,這個佇列的特性是面向多個生產者單個消費者。還有被volatile修飾的變數,threadFactory的使用等等。通過學習原始碼,能夠理清思路,增長見識。
後繼
當然HashedWheelTimer這個類屬於全記憶體任務計算,通常在我們真正的業務中,是不會把這些任務直接放到jvm記憶體中的,要不然重啟之後任務不都會消失了麼,這樣我們需要重寫HashedWheelTimer,只需要對它任務的新增和獲取進行重寫到相應的持久化中介軟體中即可(例如資料庫或者es等等)
參考和引用
[1][redis的釋出訂閱缺陷]
[[2]][Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facil] [Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facil]: http://www.cs.columbia.edu/~nahum/w6998/papers/sosp87-timing-wheels.pdf "Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facil"
[[3]][Hashed and Hierarchical Timing Wheels] [Hashed and Hierarchical Timing Wheels]: http://www.cse.wustl.edu/~cdgill/courses/cs6874/TimingWheels.ppt "Hashed and Hierarchica