
第四篇 跟蹤過程以及openvslam中的相關實現詳解
阿新 • • 發佈:2019-09-12
在成功初始化之後,會建立地圖以及區域性地圖。

建立地圖
在初始化正常過後,緊接著會建立地圖
// src/openvslam/module/initializer.cc:67
// create new map, then check the state is succeeded or not
create_map_for_monocular(curr_frm);建立單目地圖 在init_matches_中,將所有匹配點對兒中沒有三角化的位置標記為無效 以初始幀為原點,設定當前幀的位姿 建立初始幀和當前幀的關鍵幀 計算幀描述子對應的bow向量 將關鍵幀新增入map_db_中 更新幀統計資訊 逐個匹配點 建立landmark:lm就是特徵點對應的世界座標下的點 將lm和關鍵幀關聯起來 向lm中新增可觀測資訊:關鍵幀和對應的特徵點id 計算lm的描述子 計算lm的幾何資訊 將lm加入map_db_ global_bundle_adjuster 計算初始關鍵幀的中位深度值 更改當前關鍵幀t的尺度和lm尺度,(將深度中間值設定為1的尺度,1.0 / median_depth) 更新當前幀的位姿 設定地圖的起始關鍵幀
計算lm的描述子
一個lm可能被很多幀看到,每個幀中由於拍攝的時間、空間、光照條件的原因導致相同的特徵點的描述子會稍微不同,通過計算找到一個與其他描述子距離相近的描述子作為最終lm的描述子。
計算lm的幾何資訊
max_valid_dist_ = dist * scale_factor; min_valid_dist_ = max_valid_dist_ / ref_keyfrm->scale_factors_.at(num_scale_levels - 1); max_valid_dist_: 特徵點(世界座標系下)到參考幀相機位置(世界座標系下)的最大有效距離,在計算的時候將特徵點所處的影象金字塔層數也考慮進來 min_valid_dist_: 特徵點(世界座標系下)到參考幀相機位置(世界座標系下)的最小有效距離
Vec3_t mean_normal = Vec3_t::Zero(); unsigned int num_observations = 0; for (const auto& observation : observations) { auto keyfrm = observation.first; const Vec3_t cam_center = keyfrm->get_cam_center(); const Vec3_t normal = pos_w_ - cam_center; mean_normal = mean_normal + normal / normal.norm(); ++num_observations; } mean_normal_:
計算初始關鍵幀的中位深度值
將關鍵幀中的lm(世界座標系)轉為關鍵幀座標系下,對深度排序後獲取中間深度值。
更新區域性地圖及後續
// src/openvslam/tracking_module.cc:183
update_local_map();
更新區域性地圖
更新區域性關鍵幀(區域性關鍵幀的限制是60個)
統計出當前幀和相鄰的關鍵幀共享的lm數量
通過比較共享lm的數量,將共享lm數量最多的關鍵幀設定為最近的共視關鍵幀
將有共視的關鍵幀都新增到local_keyfrms_
將有共視的關鍵幀的相鄰關鍵幀中的top10也加入local_keyfrms_
將最近的共視關鍵幀設定為當前跟蹤模組的參考關鍵幀
更新區域性lm:將local_keyfrms_中的lm都新增為local_landmarks_
將所有的關鍵幀傳入mapper_模組
設定跟蹤模組狀態為Tracking儲存參考關鍵幀到當前幀的變換矩陣=last_cam_pose_from_ref_keyfrm_
tracking流程
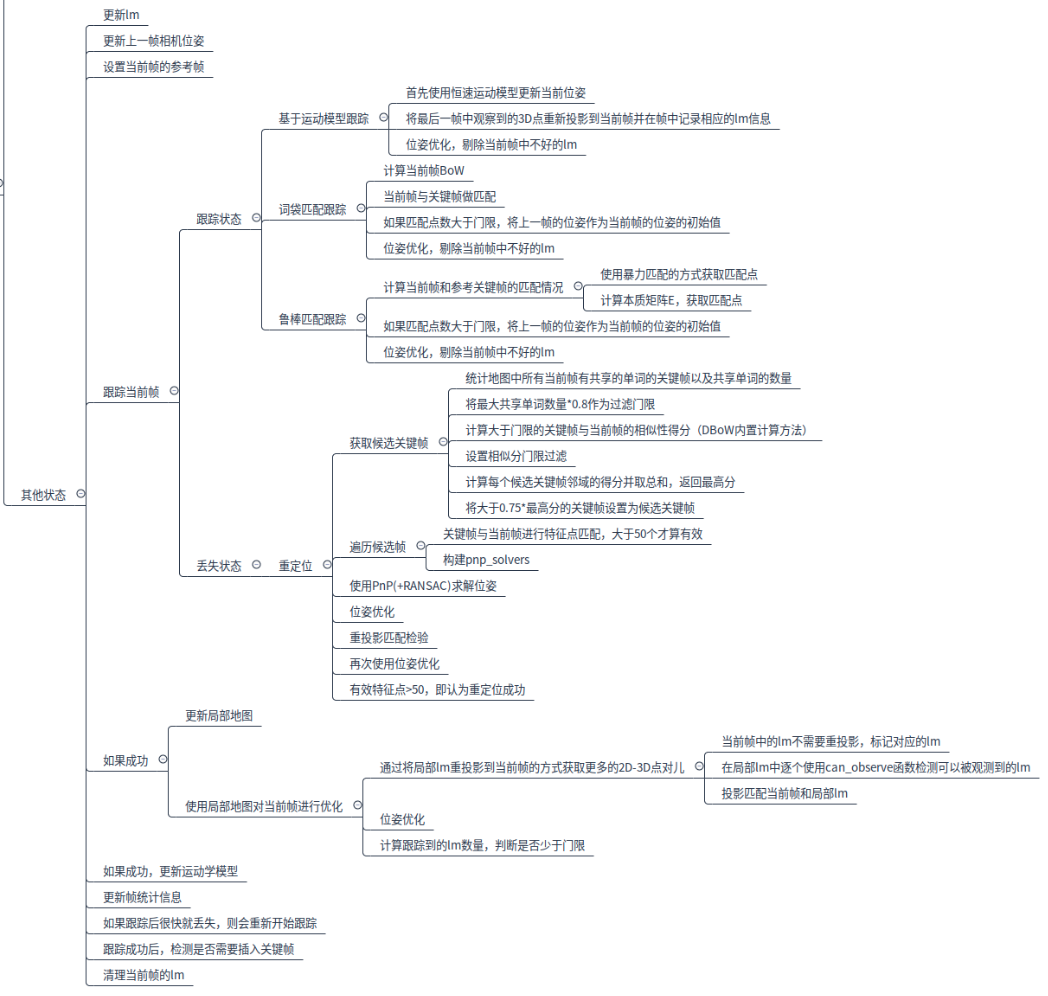
更新lm:全域性BA會優化lm的位置,因此將上一幀lm中調整為優化過的值
更新上一幀相機位姿:mapping模組有可能優化該位姿
設定當前幀的參考關鍵幀:=跟蹤模組的參考關鍵幀
跟蹤當前幀(track_current_frame)
如果成功:
更新區域性地圖
使用區域性地圖對當前幀進行優化
如果成功:
更新運動學模型update_motion_model
更新幀統計資訊
如果跟蹤後很快就丟失,則會重新開始跟蹤
跟蹤成功後,檢測是否需要插入關鍵幀
1.當前的幀id不大於上個關鍵幀id+max_num_frms_(這裡max_num_frms_=fps)
2.當前的幀id不小於上個關鍵幀id+min_num_frms_(這裡max_num_frms_=0)
3.有一定的匹配點但是不能太多,太多說明視覺變化比較小,不需要新關鍵點;
新增關鍵幀
單目直接新增
立體和RGBD,按深度降序排列,新增前100深度且大於true_depth_thr_的lm
清理當前幀的lm跟蹤當前幀
\\ src/openvslam/tracking_module.cc:278
bool tracking_module::track_current_frame()有三種跟蹤方法:
motion_based_track:
bow_match_based_track:
robust_match_based_track:
一種重點位方法:
relocalize
// Tracking mode
if (velocity_is_valid_ && last_reloc_frm_id_ + 2 < curr_frm_.id_) {
// if the motion model is valid
succeeded = frame_tracker_.motion_based_track(curr_frm_, last_frm_, velocity_);
}
if (!succeeded) {
succeeded = frame_tracker_.bow_match_based_track(curr_frm_, last_frm_, ref_keyfrm_);
}
if (!succeeded) {
succeeded = frame_tracker_.robust_match_based_track(curr_frm_, last_frm_, ref_keyfrm_);
}bow_match_based_track
計算當前幀BoW
當前幀與關鍵幀做匹配:使用bow tree
如果匹配點數大於num_matches_thr_=10,將上一幀的位姿作為當前幀的位姿的初始值,使用pose_optimizer_進行優化。
剔除當前幀中不好的lm(優化中會將一些lm設值為outliers)
robust_match_based_track
計算當前幀和參考關鍵幀的匹配情況(match_frame_and_keyframe)
使用暴力匹配的方式獲取匹配點(brute_force_match)
計算本質矩陣E,獲取匹配點(essential_solver)
如果匹配點數大於num_matches_thr_=10,將上一幀的位姿作為當前幀的位姿的初始值,使用pose_optimizer_進行優化。
剔除當前幀中不好的lm(優化中會將一些lm設值為outliers)在計算本質矩陣E的時候使用的是歸一化平面上的點對兒,而不是影象上的畫素點對兒。
motion_based_track
基於運動模型跟蹤,這裡的運動模型就是恆速運動模型。
首先使用恆速運動模型更新當前位姿
將最後一幀中觀察到的3D點重新投影到當前幀並在幀中記錄相應的lm資訊(match_current_and_last_frames)
計算當前幀到上一幀的平移向量trans_lc
非單目可以判斷運動方向
將最後一幀的特徵點對應的3D點重新投影到當前幀,在重投影位置尋找特徵點,進行匹配
pose optimization
剔除當前幀中不好的lm(優化中會將一些lm設值為outliers)重定位
跟蹤失敗後會呼叫該函式進行重定位。
tracking_module初始化中會對module::relocalizer進行初始化
relocalizer( data::bow_database* bow_db,
const double bow_match_lowe_ratio = 0.75, const double proj_match_lowe_ratio = 0.9,
const unsigned int min_num_bow_matches = 20, const unsigned int min_num_valid_obs = 50);重定位有關的變數
//! initial candidates for loop or relocalization
std::unordered_set<keyframe*> init_candidates_;
//! number of shared words between the query and the each of keyframes contained in the database
std::unordered_map<keyframe*, unsigned int> num_common_words_;
//! similarity scores between the query and the each of keyframes contained in the database
std::unordered_map<keyframe*, float> scores_;
//! pairs of score and keyframe which has the larger score than the minimum one
std::vector<std::pair<float, keyframe*>> score_keyfrm_pairs_;
//! pairs of total score and keyframe which has the larger score than the minimum one
std::vector<std::pair<float, keyframe*>> total_score_keyfrm_pairs_;獲取候選關鍵幀(acquire_relocalization_candidates)
統計地圖中所有當前幀有共享的單詞的關鍵幀以及共享單詞的數量(set_candidates_sharing_words)
將最大共享單詞數量*0.8作為過濾門限
計算大於門限的關鍵幀與當前幀的相似性得分(DBoW內建計算方法)
設定相似分門限過濾
計算每個候選關鍵幀(score_keyfrm_pairs)鄰域的得分並取總和,返回最高分best_total_score
將大於0.75*best_total_score的關鍵幀設定為候選關鍵幀
遍歷候選幀
關鍵幀與當前幀進行特徵點匹配(bow_matcher_.match_frame_and_keyframe),>50個才算有效
構建pnp_solvers
使用PnP(+RANSAC)求解位姿
使用pose_optimizer優化
重投影匹配檢驗proj_matcher_.match_frame_and_keyframe
再次使用pose_optimizer優化
有效特徵點>50,即認為重定位成功使用區域性地圖對當前幀進行優化
//src/openvslam/tracking_module.cc:209
succeeded = optimize_current_frame_with_local_map();通過將區域性lm重投影到當前幀的方式獲取更多的2D-3D點對兒(search_local_landmarks)
當前幀中的lm不需要重投影,標記對應的lm
在區域性lm中逐個使用can_observe函式檢測可以被觀測到的lm
投影匹配當前幀和區域性lm
pose_optimizer
計算跟蹤到的lm數量,判斷是否少於門限can_observe
獲取lm的世界座標值pos_w
判斷該lm是否可以重投影到當前幀的影象平面
通過判斷有效距離檢查是否在orb_scale中
檢測角度是否有效0.5度
預測當前lm所對應的影象金字塔層數更新運動學模型
這裡的運動學模型是恆速模型:
更新速度velocity = curr_frm.cam_pose_cw * last_frm_cam_pose_wc
後面用來更新位姿:curr_frm.set_cam_pose(velocity * last_frm.cam_pose_cw) 這時候last_frm.cam_pose_cw就是上一幀的curr_frm.cam_pose_cw
問題
- 恆速模型沒搞明白;