
一次使用scrapy的問題記錄
前景描述:
需要獲取某APP的全國訂單量,及搶單量。由於沒有全國的選項所以只能分別對每一個城市進行訂單的遍歷。爬蟲每天執行一次,一次獲取48小時內的訂單,從資料庫中取出昨天的資料進行對比,有訂單被搶則更新,無則不操作。(更新邏輯在這裡不重要,重要的是爬取邏輯)。每個訂單有釋出時間,根據釋出時間判斷,在48小時外的就停止爬取,開始爬取下一個城市。
先看第一版:
#spider # 構造一些請求引數,此處省略 # 從配置中讀取所有城市列表 cities = self.settings['CITY_CH'] # end_signal為某個城市爬取完畢的訊號, self.end_signal = False for city in cities: # 通過for迴圈對每個城市進行訂單爬取 post_data.update({'locationName':city}) count = 1 while not self.end_signas: post_data.update({'pageNum':str(count)}) data = ''.join(json.dumps(post_data, ensure_ascii=False).split()) sign = MD5Util.hex_digest(api_key + data + salt).upper() params = { 'apiKey':api_key, 'data':data, 'system':system, 'sign':sign } meta = {'page':count} yield scrapy.Request(url=url, method='POST', body=json.dumps(params, ensure_ascii=False), headers=self.headers, callback=self.parse,meta=meta, dont_filter=True) count+=1 self.end_signal = False def parse(self,response): # 略
# 在spiderMiddleware中根據返回的item中的訂單時間進行判斷(此處不詳寫) def process_spider_output(self, response, result, spider): result_bkp = [] for res in result: if res['order_time'] < before_date(2): #before_date為自定義的時間函式 logger.info("{%s}爬取完畢,開始爬取下一個城市" % (res['city_name'])) spider.end_signal = True break result_bkp.append(res.copy()) return result_bkp
乍一看沒有問題,遍歷每個城市,再到解析 解析完後返回item到spiderMiddleware中進行判斷訂單是否超過48小時,超過就設定
self.end_signal為True跳出spider中的while迴圈,注意while迴圈後面又將這個引數設定False然後下個城市的迴圈就開始了。
問題來了:
spider中將request返回出去新增到佇列中,這裡有一個佇列,當response下載好返回回來通過parse函式去處理的時候也有一個佇列,眾所周知運氣不好的人總會偶爾遇到一點網路問題,來舉個栗子就清楚了
栗子:spider中將城市A的1、2、3訂單頁(2、3為超過48小時的訂單頁),新增到佇列中,下載器去下載的時候可能第2頁代理掛了,第三頁超過48小時,中介軟體判斷成功設定self.end_signal=True進行下一個城市的爬取。城市B添加了1、2、3(都在48小時內),這個時候城市A的第二頁訂單下載完成了在中介軟體中判斷又將self.end_signal=True,於是城市B後面的訂單也就都沒了,都沒了。。。,直接開始了下一個城市的訂單!
一版總結:
不要在一個非同步的程式中通過一個全域性變數去控制整個程式的流程。(總結的不好,可以幫我總結一下)
第二版:
既然不能通過全域性變數來控制,那能不能讓每個城市帶一個標識來指明訂單爬取結束。
先看程式碼
#spider
cities = self.settings['CITY_CH']
# end_signal為某個城市爬取完畢的訊號,
self.end_signal = False
for city in cities:
# 通過for迴圈對每個城市進行訂單爬取
post_data.update({'locationName':city})
count = 1
print(cities)
print(city)
while in cities:
post_data.update({'pageNum':str(count)})
data = ''.join(json.dumps(post_data, ensure_ascii=False).split())
sign = MD5Util.hex_digest(api_key + data + salt).upper()
params = {
'apiKey':api_key,
'data':data,
'system':system,
'sign':sign
}
meta = {'page':count}
yield scrapy.Request(url=url, method='POST', body=json.dumps(params, ensure_ascii=False),
headers=self.headers, callback=self.parse,meta=meta, dont_filter=True)
count+=1
self.end_signal = False
def parse(self,response):
# 略
# 在spiderMiddleware中根據返回的item中的訂單時間進行判斷(此處不詳寫)
def process_spider_output(self, response, result, spider):
result_bkp = []
for res in result:
if res['order_time'] < before_date(2): #before_date為自定義的時間函式
if res['city_name'] in spider.cities:
spider.cities.remove(res['city_name'])
logger.info("{%s}爬取完畢,開始爬取下一個城市" % (res['city_name']))
break
result_bkp.append(res.copy())
return result_bkp
看邏輯也有點意思,判斷這個城市是否在列表中,在的話說明還沒爬取完畢,爬取完畢了就刪除這個城市。嗯!執行一下!
有意思的來了,第一個城市爬取正常,第二個城市不見了,上訴程式碼中列印的城市沒有顯示第二個城市,直接跳到了最後一個(設就三個城市) 怎麼被吞了呢。
敏感資料就不截圖了。
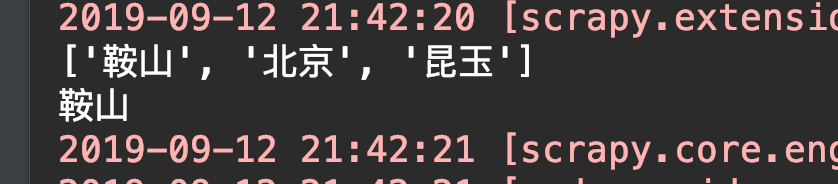
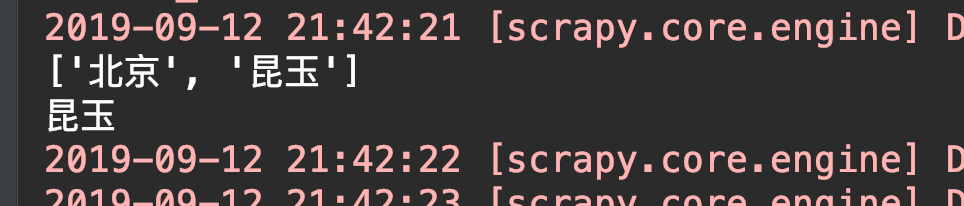
可以看到 列印的城市列表中明明還有北京的沒有被刪除,為啥直接到最後一個城市了呢?
可能有大佬已經看出來了,我是生生打斷點除錯了半天,甚至懷疑是for迴圈內部有什麼bug。
最後靈機一動(滑稽),難倒是因為城市列表的問題?我for迴圈它,然後又在他內部去刪除它裡面的元素,可以這樣嗎?
寫個demo測試一下
cities = ['鞍山', '北京', '昆玉',]
for city in cities:
cities.remove('鞍山')
print(city)# 錯誤就來了! 果然不能在迴圈它的時候再對它進行刪除操作
ValueError: list.remove(x): x not in list至於在執行scrapy的時候為什麼沒有報這個錯誤,可能是在別的地方做了異常處理,但是有這個問題在,我們先去修復它一下。
將for city in cities改為for city in cities.copy(),完美解決!!!
還有一個小點就是python的值傳遞和地址傳遞,在處理item的時候要注意。