
增強學習Q-learning分析與演示(入門)
一些說明、參閱
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/blob/master/contents/1_command_line_reinforcement_learning/treasure_on_right.py
https://github.com/simoninithomas/Deep_reinforcement_learning_Course/blob/master/Q%20learning/FrozenLake/Q%20Learning%20with%20FrozenLake.ipynb
https://www.cnblogs.com/hhh5460/p/10134018.html
http://baijiahao.baidu.com/s?id=1597978859962737001&wfr=spider&for=pc
https://www.jianshu.com/p/29db50000e3f
問題提出
為了實現自走的路徑,並儘量避免障礙,設計一個路徑。
如圖所示,當機器人在圖中的任意網格中時,怎樣讓它明白周圍環境,最終到達目標位置。
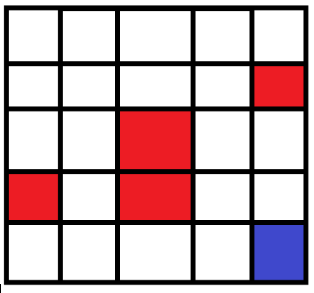
這裡給出一個執行結果:
首先給他們編號如下:作為位置的標識。
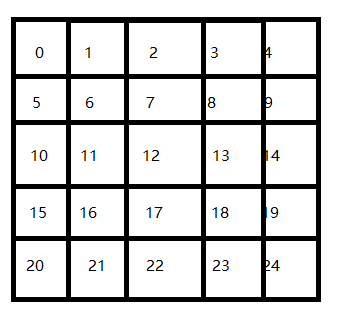
然後利用Q-Learning的獎賞機制,完成資料表單更新,最終更新如下:
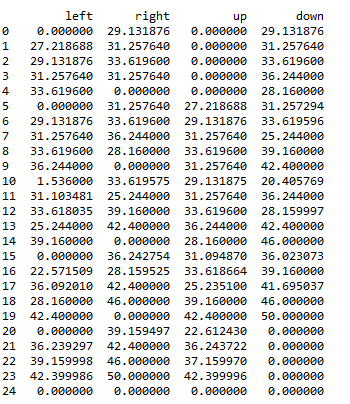
在機器人實際選擇路徑時,按照該表中的最大值選擇,最終走到24號位置,並避開了紅色方塊。
如初始位置在4時候,首先選擇了最大值向左到3,然後在3處選擇了最大值向下,然後到8處選擇了向下,等等,最終完成路徑的選擇。而這種選擇正是使用Q-Learning實現的。
Q-learning的想法
獎賞機制
在一個陌生的環境中,機器人首先的方向是隨機選擇的,當它從起點開始出發時,選擇了各種各樣的方法,完成路徑。
但是在機器人碰到紅色方塊後,給予懲罰,則經過多次後,機器人會避開懲罰位置。
當機器人碰到藍色方塊時,給予獎賞,經過多次後,機器人傾向於跑向藍色方塊的位置。
具體公式
完成獎賞和懲罰的過程表達,就是用值表示吧。
首先建立的表是空表的,就是說,如下這樣的表是空的,所有值都為0:

在每次行動後,根據獎懲情況,更新該表,完成學習過程。在實現過程中,將獎懲情況也編製成一張表。表格式如上圖類似。
而獎懲更新公式為:
貝爾曼方程:
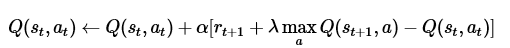
其中的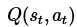 表示當前的Q表,就是上圖25行4列的表單。
表示當前的Q表,就是上圖25行4列的表單。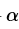 表示學習率,
表示學習率, 表示下一次行為會得到的獎懲情況,
表示下一次行為會得到的獎懲情況,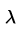 表示一個貪婪係數,在這裡的公式中,就是說,如果它的數值比較大,則更傾向於對遠方的未來獎賞。
表示一個貪婪係數,在這裡的公式中,就是說,如果它的數值比較大,則更傾向於對遠方的未來獎賞。
(該式子在很多網頁文字中並沒有固定的格式,如貪婪係數,在有些時候是隨著步數的增加而遞減的(可能)。
推薦閱讀:
https://www.jianshu.com/p/29db50000e3f
等,其中包括了更新Q表中的一些過程。
程式碼實現-準備過程
不得不說的是該程式碼參閱了:https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/blob/master/contents/1_command_line_reinforcement_learning/treasure_on_right.py
他的程式碼講解:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/2-1-general-rl/
他設計了一種方案實現了機器人在一維空間中如何移動,但是不涉及障礙物的問題,並使用了較高的程式設計能力,有顯示路徑過程。
而本文側重於如何表示出路徑,完成思路示例。
匯入對應的庫函式,並建立問題模型:
import numpy as np import pandas as pd import time
N_STATES = 25 # the length of the 2 dimensional world ACTIONS = ['left', 'right','up','down'] # available actions EPSILON = 0.3 # greedy police ALPHA = 0.8 # learning rate GAMMA = 0.9 # discount factor MAX_EPISODES = 100 # maximum episodes FRESH_TIME = 0.00001 # fresh time for one move
建立Q表的函式:
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
return table
行為選擇的函式:
行為選擇過程中,使用這樣長的表示也就是為了表達:在邊界時候,機器人的路徑有些不能選的,要不就超出索引的表格了。。
當貪婪係數更小時,更傾向於使用隨機方案,或者當表初始時所有資料都為0,則使用隨機方案進行行為選擇。
當np.random.uniform()< =EPSILON時,則使用已經選擇過的最優方案完成Qlearning的行為選擇,也就是說,機器人並不會對遠方的未知目標表示貪婪。(這裡的表達是和上述公式的貪婪係數大小的作用是相反過來的)
def choose_action(state, q_table):
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
if state==0:
action_name=np.random.choice(['right','down'])
elif state>0 and state<4:
action_name=np.random.choice(['right','down','left'])
elif state==4:
action_name=np.random.choice(['left','down'])
elif state==5 or state==15 or state==10 :
action_name=np.random.choice(['right','up','down'])
elif state==9 or state==14 or state==19 :
action_name=np.random.choice(['left','up','down'])
elif state==20:
action_name=np.random.choice(['right','up'])
elif state>20 and state<24:
action_name=np.random.choice(['right','up','left'])
elif state==24:
action_name=np.random.choice(['left','up'])
else:
action_name=np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
獎賞表達:
函式中引數S,表示state(狀態),a表示action(行為),行為0到3分別表示左右上下。該表中,給出了在當前狀態下,下一個方向會導致的獎懲情況。
def get_init_feedback_table(S,a):
tab=np.ones((25,4))
tab[8][1]=-10;tab[4][3]=-10;tab[14][2]=-10
tab[11][1]=-10;tab[13][0]=-10;tab[7][3]=-10;tab[17][2]=-10
tab[16][0]=-10;tab[20][2]=-10;tab[10][3]=-10;
tab[18][0]=-10;tab[16][1]=-10;tab[22][2]=-1;tab[12][3]=-10
tab[23][1]=50;tab[19][3]=50
return tab[S,a]
獲取獎懲:
該函式呼叫了上一個獎懲表示的函式,獲得獎懲資訊,其中的引數S,A,同上。
當狀態S,A符合了下一步獲得最終的結果時,則結束(終止),表示完成了目標任務。否則更新位置S
def get_env_feedback(S, A):
action={'left':0,'right':1,'up':2,'down':3};
R=get_init_feedback_table(S,action[A])
if (S==19 and action[A]==3) or (S==23 and action[A]==1):
S = 'terminal'
return S,R
if action[A]==0:
S-=1
elif action[A]==1:
S+=1
elif action[A]==2:
S-=5
else:
S+=5
return S, R
程式碼實現-開始訓練
首先初始化Q表,然後設定初始路徑就是在0位置(也就是說每次機器人,從位置0開始出發)
訓練迭代次數MAX_EPISODES已經在之前設定。
在每一代的訓練過程中,選擇行為(隨機或者使用Q表原有),然後根據選擇的行為和當前的位置,獲得獎懲情況:S_, R
當沒有即將發生的行為不會到達最終目的地時候,使用:
q_target = R + GAMMA * q_table.iloc[S_, :].max() q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A])
這兩行完成q表的更新。(對照貝爾曼方程)
當完成時候,即終止,開始下一代的訓練。
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
S = 0
is_terminated = False
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
print(1)
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A]) # update
S = S_ # move to next state
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)
效果-總結
效果其實和開頭一樣,調整合適的引數,最終輸出的q表自然有對應的影響。
明顯可以得到的是,貪婪係數會影響訓練時間等。
所有程式碼就是以上。可以使用eclipse的pydev下進行執行,除錯。並觀察沒一步對錶格的影響
&n