
4.Sentinel原始碼分析— Sentinel是如何做到降級的?
各位中秋節快樂啊,我覺得在這個月圓之夜有必要寫一篇原始碼解析,以表示我內心的高興~
Sentinel原始碼解析系列:
1.Sentinel原始碼分析—FlowRuleManager載入規則做了什麼?
2. Sentinel原始碼分析—Sentinel是如何進行流量統計的?
3. Sentinel原始碼分析— QPS流量控制是如何實現的?
在我的第二篇文章裡面2. Sentinel原始碼分析—Sentinel是如何進行流量統計的?裡面介紹了整個Sentinel的主流程是怎樣的。所以降級的大致流程可以概述為:
1. 設定降級策略,是根據平均響應時間還是異常比例來進行降級的
2. 根據資源建立一系列的插槽
3. 依次呼叫插槽,根據設定的插槽型別來進行降級
我們先來看個例子,方便大家自己斷點跟蹤:
private static final String KEY = "abc"; private static final int threadCount = 100; private static int seconds = 60 + 40; public static void main(String[] args) throws Exception { List<DegradeRule> rules = new ArrayList<DegradeRule>(); DegradeRule rule = new DegradeRule(); rule.setResource(KEY); // set threshold rt, 10 ms rule.setCount(10); rule.setGrade(RuleConstant.DEGRADE_GRADE_RT); rule.setTimeWindow(10); rules.add(rule); DegradeRuleManager.loadRules(rules); for (int i = 0; i < threadCount; i++) { Thread entryThread = new Thread(new Runnable() { @Override public void run() { while (true) { Entry entry = null; try { TimeUnit.MILLISECONDS.sleep(5); entry = SphU.entry(KEY); // token acquired pass.incrementAndGet(); // sleep 600 ms, as rt TimeUnit.MILLISECONDS.sleep(600); } catch (Exception e) { block.incrementAndGet(); } finally { total.incrementAndGet(); if (entry != null) { entry.exit(); } } } } }); entryThread.setName("working-thread"); entryThread.start(); } }
其他的流程基本上和第二篇文章裡介紹的差不多,這篇文章來介紹Sentinel的主流程,Sentinel的降級策略全部都是在DegradeSlot中進行操作的。
DegradeSlot
public class DegradeSlot extends AbstractLinkedProcessorSlot<DefaultNode> { @Override public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, boolean prioritized, Object... args) throws Throwable { DegradeRuleManager.checkDegrade(resourceWrapper, context, node, count); fireEntry(context, resourceWrapper, node, count, prioritized, args); } }
DegradeSlot會直接呼叫DegradeRuleManager進行降級的操作,我們直接進入到DegradeRuleManager.checkDegrade方法中。
DegradeRuleManager#checkDegrade
public static void checkDegrade(ResourceWrapper resource, Context context, DefaultNode node, int count)
throws BlockException {
//根據resource來獲取降級策略
Set<DegradeRule> rules = degradeRules.get(resource.getName());
if (rules == null) {
return;
}
for (DegradeRule rule : rules) {
if (!rule.passCheck(context, node, count)) {
throw new DegradeException(rule.getLimitApp(), rule);
}
}
}這個方法邏輯也是非常的清晰,首先是根據資源名獲取到註冊過的降級規則,然後遍歷規則集合呼叫規則的passCheck,如果返回false那麼就丟擲異常進行降級。
DegradeRule#passCheck
public boolean passCheck(Context context, DefaultNode node, int acquireCount, Object... args) {
//返回false直接進行降級
if (cut.get()) {
return false;
}
//降級是根據資源的全域性節點來進行判斷降級策略的
ClusterNode clusterNode = ClusterBuilderSlot.getClusterNode(this.getResource());
if (clusterNode == null) {
return true;
}
//根據響應時間降級策略
if (grade == RuleConstant.DEGRADE_GRADE_RT) {
//獲取節點的平均響應時間
double rt = clusterNode.avgRt();
if (rt < this.count) {
passCount.set(0);
return true;
}
//rtSlowRequestAmount預設是5
// Sentinel will degrade the service only if count exceeds.
if (passCount.incrementAndGet() < rtSlowRequestAmount) {
return true;
}
// 根據異常比例降級
} else if (grade == RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO) {
double exception = clusterNode.exceptionQps();
double success = clusterNode.successQps();
double total = clusterNode.totalQps();
// If total amount is less than minRequestAmount, the request will pass.
if (total < minRequestAmount) {
return true;
}
// In the same aligned statistic time window,
// "success" (aka. completed count) = exception count + non-exception count (realSuccess)
double realSuccess = success - exception;
if (realSuccess <= 0 && exception < minRequestAmount) {
return true;
}
if (exception / success < count) {
return true;
}
// 根據異常數降級
} else if (grade == RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT) {
double exception = clusterNode.totalException();
if (exception < count) {
return true;
}
}
//根據設定的時間視窗進行重置
if (cut.compareAndSet(false, true)) {
ResetTask resetTask = new ResetTask(this);
pool.schedule(resetTask, timeWindow, TimeUnit.SECONDS);
}
return false;
}這個方法首先會去獲取cut的值,如果是true那麼就直接進行限流操作。然後會根據resource獲取ClusterNode全域性節點。往下分別根據三種不同的策略來進行降級。
DEGRADE_GRADE_RT根據響應時間進行降級
if (grade == RuleConstant.DEGRADE_GRADE_RT) {
//獲取節點的平均響應時間
double rt = clusterNode.avgRt();
if (rt < this.count) {
passCount.set(0);
return true;
}
//rtSlowRequestAmount預設是5
// Sentinel will degrade the service only if count exceeds.
if (passCount.incrementAndGet() < rtSlowRequestAmount) {
return true;
}
}如果是根據響應時間進行降級,那麼會獲取clusterNode的平均響應時間,如果平均響應時間大於所設定的count(預設是毫秒),那麼就呼叫passCount加1,如果passCount大於5,那麼直接降級。
所以看到這裡我們應該知道根據平均響應時間降級前幾個請求即使響應過長也不會立馬降級,而是要等到第六個請求到來才會進行降級。
我們進入到clusterNode的avgRt方法中看一下是如何獲取到clusterNode的平均響應時間的。
clusterNode是StatisticNode的例項
StatisticNode#avgRt
java public double avgRt() { //獲取當前時間視窗內呼叫成功的次數 long successCount = rollingCounterInSecond.success(); if (successCount == 0) { return 0; } //獲取視窗內的響應時間 return rollingCounterInSecond.rt() * 1.0 / successCount; }e
這個方法主要是呼叫rollingCounterInSecond獲取成功次數,然後再獲取視窗內的響應時間,用總響應時間除以次數得到平均每次成功呼叫的響應時間。
在1.Sentinel原始碼分析—FlowRuleManager載入規則做了什麼?中,我已經具體講述了StatisticNode裡面的rollingCounterInMinute實現原理,rollingCounterInMinute是按分鐘進行統計的時間視窗。現在我們來講一下rollingCounterInSecond按秒來進行統計的時間視窗。
在StatisticNode裡面初始化rollingCounterInSecond:
private transient volatile Metric rollingCounterInSecond = new ArrayMetric(SampleCountProperty.SAMPLE_COUNT,
IntervalProperty.INTERVAL);在這個初始化的方法裡,會傳入兩個引數,SampleCountProperty.SAMPLE_COUNT的值是2,
IntervalProperty.INTERVAL的值是1000。
我們進入到ArrayMetric的構造方法中:
private final LeapArray<MetricBucket> data;
public ArrayMetric(int sampleCount, int intervalInMs) {
this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs);
}在建立ArrayMetric例項的時候會給data建立一個OccupiableBucketLeapArray例項。
OccupiableBucketLeapArray
public OccupiableBucketLeapArray(int sampleCount, int intervalInMs) {
// This class is the original "CombinedBucketArray".
super(sampleCount, intervalInMs);
this.borrowArray = new FutureBucketLeapArray(sampleCount, intervalInMs);
}OccupiableBucketLeapArray繼承LeapArray這個抽象類,初始化的時候會呼叫父類的構造器:
LeapArray
public LeapArray(int sampleCount, int intervalInMs) {
AssertUtil.isTrue(sampleCount > 0, "bucket count is invalid: " + sampleCount);
AssertUtil.isTrue(intervalInMs > 0, "total time interval of the sliding window should be positive");
//intervalInMs是sampleCount的整數
AssertUtil.isTrue(intervalInMs % sampleCount == 0, "time span needs to be evenly divided");
//每個小視窗的時間跨度
this.windowLengthInMs = intervalInMs / sampleCount;
//視窗的長度
this.intervalInMs = intervalInMs;
//視窗個數
this.sampleCount = sampleCount;
this.array = new AtomicReferenceArray<>(sampleCount);
}OccupiableBucketLeapArray在初始化的時候也會建立一個FutureBucketLeapArray例項賦值給borrowArray。
FutureBucketLeapArray也是繼承LeapArray:
public FutureBucketLeapArray(int sampleCount, int intervalInMs) {
// This class is the original "BorrowBucketArray".
super(sampleCount, intervalInMs);
}直接通過呼叫父類LeapArray的構造方法進行初始化。
到這裡rollingCounterInSecond的建立過程講完了。
下面我們再回到StatisticNode中,在呼叫StatisticNode的avgRt方法的時候會呼叫rollingCounterInSecond.success()方法獲取當前時間視窗的呼叫成功次數:
ArrayMetric#success
public long success() {
//設定或更新當前的時間視窗
data.currentWindow();
long success = 0;
//獲取窗口裡有效的Bucket
List<MetricBucket> list = data.values();
for (MetricBucket window : list) {
success += window.success();
}
return success;
}這裡的data是的父類是LeapArray,LeapArray裡面有一個array陣列,用來記錄時間視窗,在我們這裡是基於秒鐘的時間視窗,所以array的大小為2。data的結構圖我直接從1.Sentinel原始碼分析—FlowRuleManager載入規則做了什麼?中拿過來:
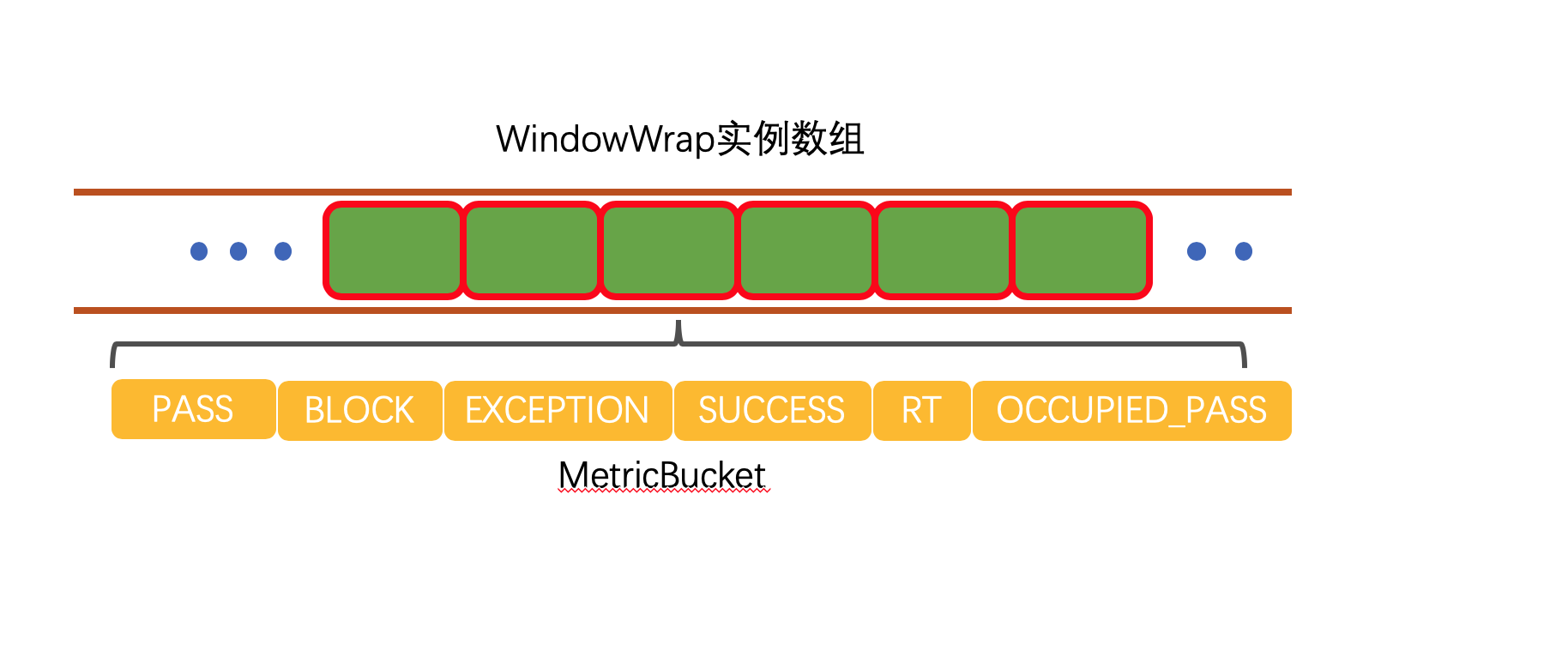
只不過這裡的WindowWrap陣列元素只有兩個,每一個WindowWrap元素由MetricBucket物件構成,用來統計資料,如:通過次數、阻塞次數、異常次數等~
呼叫data的currentWindow方法會呼叫到LeapArray的currentWindow方法中去:
LeapArray#currentWindow
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
//通過當前時間判斷屬於哪個視窗
int idx = calculateTimeIdx(timeMillis);
//計算出視窗開始時間
// Calculate current bucket start time.
long windowStart = calculateWindowStart(timeMillis);
while (true) {
//獲取數組裡的老資料
WindowWrap<T> old = array.get(idx);
if (old == null) {
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
if (array.compareAndSet(idx, null, window)) {
// Successfully updated, return the created bucket.
return window;
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
// 如果對應時間視窗的開始時間與計算得到的開始時間一樣
// 那麼代表當前即是我們要找的視窗物件,直接返回
} else if (windowStart == old.windowStart()) {
return old;
} else if (windowStart > old.windowStart()) {
//如果當前的開始時間小於原開始時間,那麼就更新到新的開始時間
if (updateLock.tryLock()) {
try {
// Successfully get the update lock, now we reset the bucket.
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
//一般來說不會走到這裡
// Should not go through here, as the provided time is already behind.
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}這裡我簡單介紹一下這個方法,這個方法的詳細講解已經在第一篇原始碼分析裡做了。
這個方法裡面會根據當前的時間戳來計算出array數組裡面的index,然後去array陣列中找相應的資料,如果節點已經存在,那麼用CAS更新一個新的節點;如果節點是新的,那麼直接返回;如果節點失效了,設定當前節點,清除所有失效節點。
這裡我直接引用1.Sentinel原始碼分析—FlowRuleManager載入規則做了什麼?中的例子:
1. 如果array資料裡面的bucket資料如下所示:
NULL B4
|_______|_______|
800 1000 1200
^
time=888
正好當前時間所對應的槽位裡面的資料是空的,那麼就用CAS更新
2. 如果array裡面已經有資料了,並且槽位裡面的視窗開始時間和當前的開始時間相等,那麼直接返回
B3 B4
||_______|_______||___
800 1000 1200 timestamp
^
time=888
3. 例如當前時間是1676,所對應窗口裡面的資料的視窗開始時間小於當前的視窗開始時間,那麼加上鎖,然後設定槽位的視窗開始時間為當前視窗開始時間,並把槽位裡面的資料重置
(old)
B0
|_______||_______|
... 1200 1400
^
time=1676再回到ArrayMetric的success方法中,往下走呼叫data.values()方法:
LeapArray#success
public List<T> values(long timeMillis) {
if (timeMillis < 0) {
return new ArrayList<T>();
}
int size = array.length();
List<T> result = new ArrayList<T>(size);
for (int i = 0; i < size; i++) {
WindowWrap<T> windowWrap = array.get(i);
if (windowWrap == null || isWindowDeprecated(timeMillis, windowWrap)) {
continue;
}
result.add(windowWrap.value());
}
return result;
}這個方法就是用來獲取所有有效的MetricBucket,並返回。
然後通過呼叫MetricBucket的success方法獲取被成功呼叫的次數。
我們接著來看ArrayMetric的rt方法:
public long rt() {
data.currentWindow();
long rt = 0;
//獲取當前時間視窗的統計資料
List<MetricBucket> list = data.values();
//統計當前時間視窗的平均相應時間之和
for (MetricBucket window : list) {
rt += window.rt();
}
return rt;
}這個方法和上面的success方法差不多,獲取所有的MetricBucket的rt資料求和返回。
然後就可以通過rt方法返回的時間總和除以成功呼叫的總和求得平均數。
我們再回到DegradeRule的passCheck方法中的響應時間降級策略中:
if (grade == RuleConstant.DEGRADE_GRADE_RT) {
//獲取節點的平均響應時間
double rt = clusterNode.avgRt();
if (rt < this.count) {
passCount.set(0);
return true;
}
//rtSlowRequestAmount預設是5
// Sentinel will degrade the service only if count exceeds.
if (passCount.incrementAndGet() < rtSlowRequestAmount) {
return true;
}
// 根據異常比例降級
}
//省略
return false;如果求得的平均響應時間小於設定的count時間,那麼就重置passCount並返回true,表示不丟擲異常;如果有連續5次的響應時間都超過了count,那麼就返回false丟擲異常進行降級。
DEGRADE_GRADE_EXCEPTION_RATIO根據異常比例降級
if (grade == RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO) {
//獲取每秒異常的次數
double exception = clusterNode.exceptionQps();
//獲取每秒成功的次數
double success = clusterNode.successQps();
//獲取每秒總呼叫次數
double total = clusterNode.totalQps();
// If total amount is less than minRequestAmount, the request will pass.
// 如果總呼叫次數少於5,那麼不進行降級
if (total < minRequestAmount) {
return true;
}
// In the same aligned statistic time window,
// "success" (aka. completed count) = exception count + non-exception count (realSuccess)
double realSuccess = success - exception;
if (realSuccess <= 0 && exception < minRequestAmount) {
return true;
}
if (exception / success < count) {
return true;
}
}
。。。
return false;這個方法中獲取成功呼叫的Qps和異常呼叫的Qps,驗證後,然後求一下比率,如果沒有大於count,那麼就返回true,否則返回false丟擲異常。
我們再進入到exceptionQps方法中看一下:
StatisticNode#exceptionQps
public double exceptionQps() {
return rollingCounterInSecond.exception() / rollingCounterInSecond.getWindowIntervalInSec();
}rollingCounterInSecond.getWindowIntervalInSec方法是表示視窗的時間長度,用秒來表示。這裡返回的是1。
ArrayMetric#exception
public long exception() {
data.currentWindow();
long exception = 0;
List<MetricBucket> list = data.values();
for (MetricBucket window : list) {
exception += window.exception();
}
return exception;
}這個方法和我上面分析的差不多,大家看看就好了。
根據異常數降級DEGRADE_GRADE_EXCEPTION_COUNT
if (grade == RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT) {
double exception = clusterNode.totalException();
if (exception < count) {
return true;
}
}根據異常數降級是非常的直接的,直接根據統計的異常總次數判斷是否超過count。
到這裡就講完了降級的實現