
#編譯原理# 概論(一)
概論
編譯原理筆記第一部分,內容參考:北航軟院教師邵兵課堂課件及內容、張莉著《編譯原理及編譯程式構造》、國防工業出版社的《編譯原理——學習指導與典型題解析》、AlvinZH的學習筆記以及個人理解
目前是包含了全部內容的版本,後續會推出精簡版和複習知識點版
如有建議或錯誤錯誤歡迎在評論中指出或聯絡我:QQ:847590417
閱讀目錄
1.1 編譯的一些基本概念
1.2 編譯的全過程
1.3 編譯程式的構造
1.4 編譯程式的前後處理器
1.5 編譯技術的應用
1.1 編譯的一些基本概念
低階語言(Low level language)
– 字位碼、機器語言、組合語言
– 特點:與特定的機器有關,功效高,但使用複雜、繁 瑣、費時、易出錯。
高階語言
– Fortran、Pascal、C語言等
– 特點:不依賴具體機器,移植性好,對使用者要求低,易使用,易維護等。
源程式:用編譯語言或高階語言編寫的程式
目標程式(目的碼):用目標語言所表示的程式,目標語言:沒有硬性規定,可以是某種機器的組合語言、機器語言,也可以是介於源語言和機器語言之間的“中間語言”。
翻譯程式:將源程式轉換為目標程式的程式成為翻譯程式。它是指各種語言的翻譯器,是彙編程式、編譯程式以及各種變換程式的總稱
三者關係:源程式是翻譯程式的輸入,目標程式是翻譯程式的輸出
彙編程式:
源程式用匯編語言書寫,經過翻譯程式得到用機器語言表示的程式嗎,這時的翻譯程式就稱之為彙編程式,這種翻譯過程稱為“彙編”
編譯程式:
源程式用高階語言書寫,加工後得到目標程式,這種翻譯過程稱為“編譯”
彙編程式和編譯程式都是翻譯程式,只是就愛共物件不同,組合語言格式件單和機器語言有一一對應關係,所以彙編程式要做的翻譯工作比編譯程式簡單得多。
從源程式到真正使用程式有兩個階段:編譯、執行
編譯或彙編階段即源程式通過編譯程式、彙編程式等翻譯程式變為目標程式
執行階段即通過向目標程式和其執行子程式之中輸入資料然後得到輸出資料
解釋程式:對源程式進行解釋執行的程式,對變異的道德中間語言進行解釋執行的程式。源程式轉化為解釋程式:
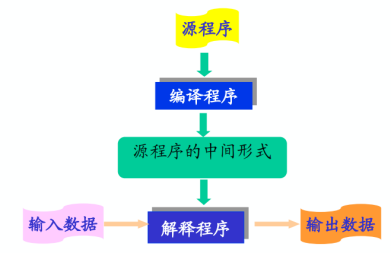
1.2 編譯的全過程
將高階語言程式翻譯成等價的目標程式的過程,一般分為五個基本階段:
詞法分析,語法分析,語義分析和生成中間程式碼,程式碼優化,生成目標程式
1.詞法分析:
分析和識別單詞
即掃描源程式(字串),根據語言的此法規則分析並識別單詞,並以某種編碼形式輸出。
單詞:是語言的基本語法單位,一般語言有四大類單詞:語言定義的關鍵字或保留字,識別符號(變數名字),常數(常量),分界符(運算子、特殊符號)。詞即最小的有意義的單詞。
該賦值語句便可識別出9個單詞
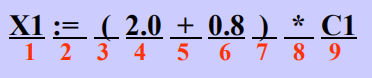
2.語法分析:
根據相應語言的文法,分析並識別出各種語法成分,如表示式、各種說明、語句、過程、函式等,並進行語法正確性檢查。
利用這種文法,語法分析便可根據其將<>中的內容給識別出來,並進行語法檢查,如有錯誤則會輸出錯誤資訊。

3.語義分析、生成中間程式碼:
對識別出的各種語法成分進行語義分析,併產生相應的中間程式碼
中間程式碼時一種介於源語言和目標語言之間的中間語言形式,生成的目的:1.便於做優化處理,2.便於編譯程式的移植(不必依賴於目標計算機,便於轉換成其他形式)
中間程式碼的形式:編譯程式設計者可以自己設計,常用的有四元式、三元式、逆波蘭表示等。
例如: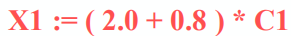
首先識別出是賦值語句,然後分析與以上的正確性,正確後生成中間程式碼
四元式(三地址指令):
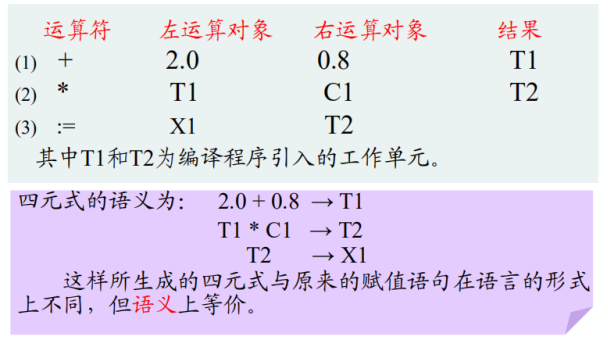
4.程式碼優化:
從四元式形式的中間程式碼可知,第一句是常量的計算,所以為了進行優化可以在編譯時計算出結果放在工作單元中,這樣不必每次都生成目標指令計算。

然後還可以對臨時工作單元的數量進行優化:T2變為T1,此時便可減少一個單元的使用。
5.生成目標程式:
生成中間程式碼後,便很容易生成目標程式(地址指令序列)了,這部分工作和機器關係很密切,所以需要根據具體機器進行。在這部分工作需要注意充分利用累加器,生成時也可進行優化處理。(該過程需要保持語義的等價性)
1.3 編譯程式的構造
1.3.1 邏輯結構
根據邏輯功能不同,可將編譯過程劃分為五個基本階段,相對應可以將實現整個編譯過程的編譯程式劃分為五個邏輯階段:

五個階段都要做兩件事:建表和查表和出錯處理,即編譯程式中都要包括表格管理和出錯處理兩部分
表格管理(建表和查表):
即及時的把源程式中的資訊和編譯過程中所產生的資訊登記在表格中,而在隨後的編譯過程中同時又要不斷地查詢這些表中的資訊,編譯過程貫穿著建表和查表的工作。
出錯處理:
規模較大的源程式難免有多種錯誤,編譯程式必須要有出錯處理的工作,即能診斷出錯誤,並向用戶報告錯誤性質和位置,以便使用者修改源程式。出錯處理能力的優劣是衡量編譯程式質量好壞的一個重要指標。
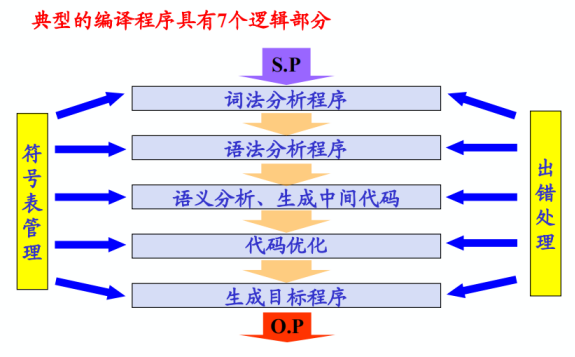
如上便是典型編譯程式的七個邏輯部分,五個邏輯階段加上兩個一直需要進行的工作。
1.3.2 遍(pass)
遍:對源程式(包括源程式的中間形式)從頭到尾掃描一次,並作有關的加工處理,生成新的源程式中間形式或目標程式,通常稱之為一遍: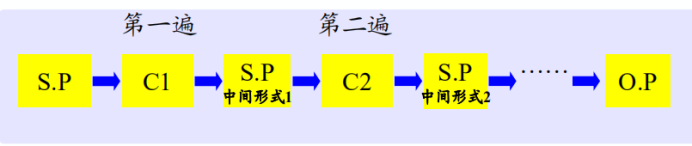
一次遍就是完成五個基本階段的工作,需要經過幾次掃描處理
一次掃描就可完成整個編譯工作的稱為“一遍掃描編譯程式”,一遍掃描的編譯程式以語法分析程式為核心。
分遍可為編譯程式的移植創造條件,主要缺點是增加了不少的重複性工作。
其結構為:
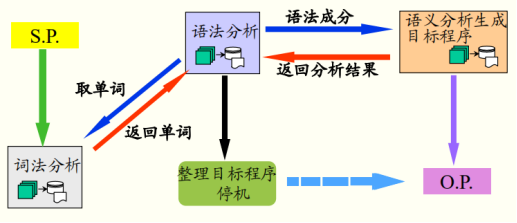
start pass到over pass(SP,OP大概是這個意思)
1.3.3 前端和後端
根據編譯程式各部分的功能可將編譯程式分成前端和後端
前端:和源程式、源語言有關的這一部分、包括詞法分析、語法分析、語義分析、中間程式碼生成、程式碼優化這些分析部分
後端:和目標機有關的部分,包括目標程式生成,和目標機有關的優化這些綜合部分
劃分的原因:
這是一種傳統方法,可以實現採用同一個編譯程式的前端,金改寫後端便可生成不同目標機上的相同源語言的編譯程式,並且還可以前後端並行進行工作。
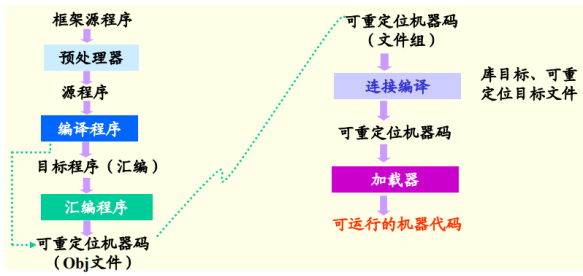
1.4 編譯程式的前後處理器
左為前,右為後
源程式:多檔案、巨集定義和紅呼叫,包括檔案
目標程式:一般為彙編程式或可重定位的機器程式碼
1.5 編譯技術的應用
語法制導的結構化編譯器,程式格式化工具,軟體測試工具,程式理解工具,高階語言的翻譯工具等