
Flink Checkpoint 問題排查實用指南
在 Flink 中,狀態可靠性保證由 Checkpoint 支援,當作業出現 failover 的情況下,Flink 會從最近成功的
Checkpoint 恢復。在實際情況中,我們可能會遇到 Checkpoint 失敗,或者 Checkpoint 慢的情況,本文會統一聊一聊
Flink 中 Checkpoint 異常的情況(包括失敗和慢),以及可能的原因和排查思路。
1. Checkpoint 流程簡介
首先我們需要了解 Flink 中 Checkpoint 的整個流程是怎樣的,在瞭解整個流程之後,我們才能在出問題的時候,更好的進行定位分析。
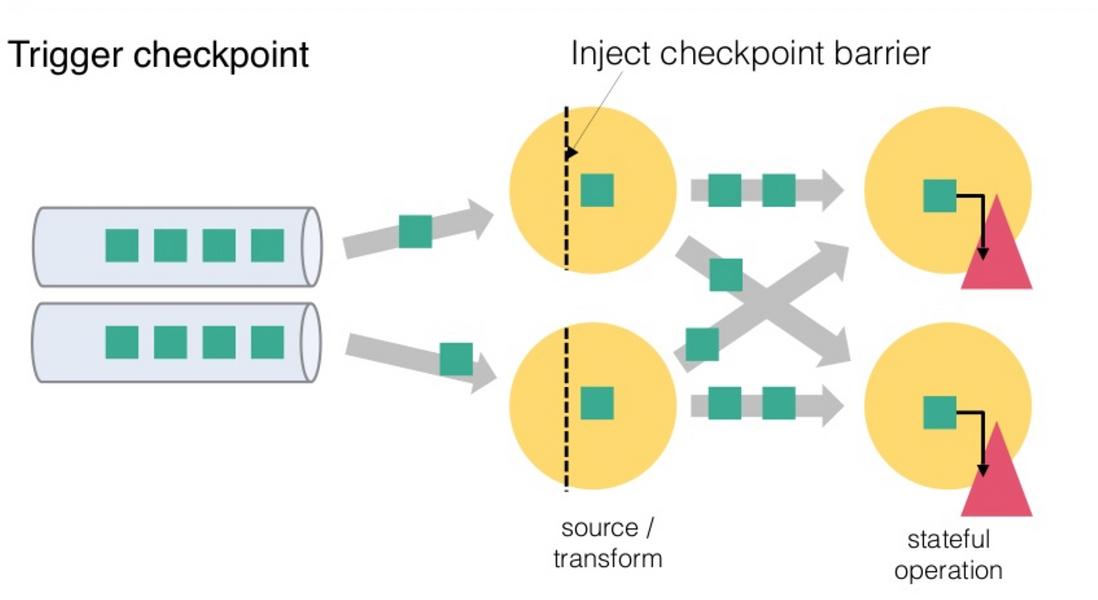
從上圖我們可以知道,Flink 的 Checkpoint 包括如下幾個部分:
1.JM trigger checkpoint
2.Source 收到 trigger checkpoint 的 PRC,自己開始做 snapshot,並往下游傳送 barrier
3.下游接收 barrier(需要 barrier 都到齊才會開始做 checkpoint)
4.Task 開始同步階段 snapshot
5.Task 開始非同步階段 snapshot
6.Task snapshot 完成,彙報給 JM
上面的任何一個步驟不成功,整個 checkpoint 都會失敗。
**2 Checkpoint 異常情況排查
2.1 Checkpoint 失敗**
可以在 Checkpoint 介面看到如下圖所示,下圖中 Checkpoint 10423 失敗了。
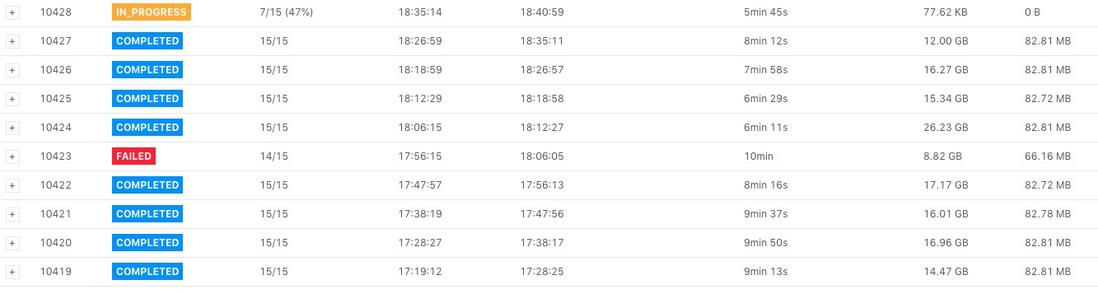
點選 Checkpoint 10423 的詳情,我們可以看到類系下圖所示的表格(下圖中將 operator 名字擷取掉了)。
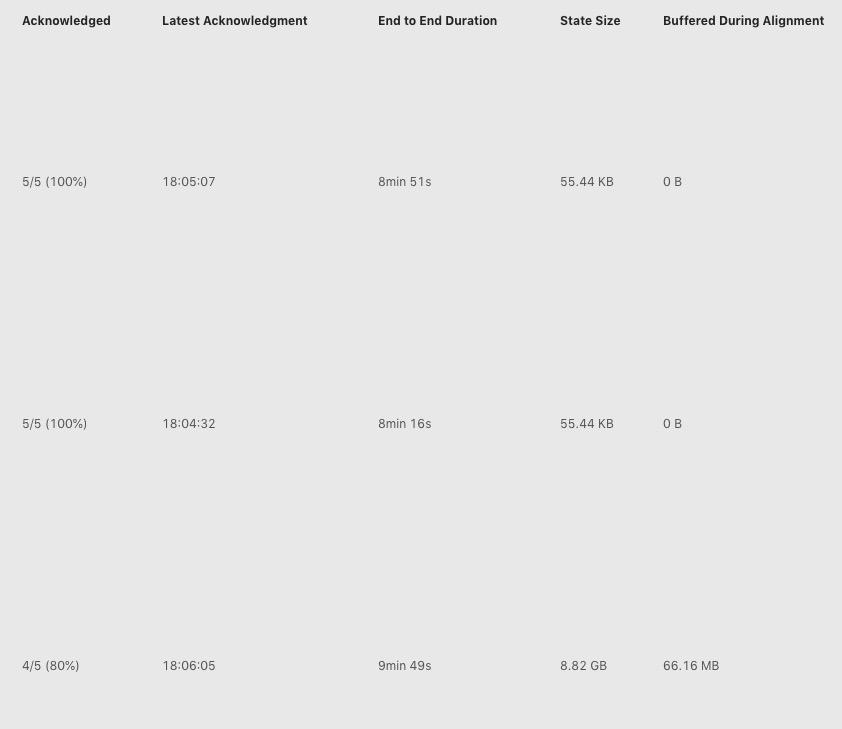
上圖中我們看到三行,表示三個 operator,其中每一列的含義分別如下:
1.其中 Acknowledged 一列表示有多少個 subtask 對這個 Checkpoint 進行了 ack,從圖中我們可以知道第三個 operator 總共有 5 個 subtask,但是隻有 4 個進行了 ack;
2.第二列 Latest Acknowledgement 表示該 operator 的所有 subtask 最後 ack 的時間;
3.End to End Duration
4.
State Size 表示當前 Checkpoint 的 state 大小 – 主要這裡如果是增量 checkpoint 的話,則表示增量大小;5.
Buffered During Alignment 表示在 barrier 對齊階段積攢了多少資料,如果這個資料過大也間接表示對齊比較慢);Checkpoint 失敗大致分為兩種情況:Checkpoint Decline 和 Checkpoint Expire。
2.1.1 Checkpoint Decline
我們能從 jobmanager.log 中看到類似下面的日誌
Decline checkpoint 10423 by task 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178. 其中
10423 是 checkpointID,0b60f08bf8984085b59f8d9bc74ce2e1 是 execution id,85d268e6fbc19411185f7e4868a44178 是 job id,我們可以在 jobmanager.log 中查詢 execution id,找到被排程到哪個 taskmanager 上,類似如下所示:
019-09-02 16:26:20,972 INFO [jobmanager-future-thread-61] org.apache.flink.runtime.executiongraph.ExecutionGraph - XXXXXXXXXXX (100/289) (87b751b1fd90e32af55f02bb2f9a9892) switched from SCHEDULED to DEPLOYING.
2019-09-02 16:26:20,972 INFO [jobmanager-future-thread-61] org.apache.flink.runtime.executiongraph.ExecutionGraph - Deploying XXXXXXXXXXX (100/289) (attempt #0) to slot container_e24_1566836790522_8088_04_013155_1 on hostnameABCDE
從上面的日誌我們知道該 execution 被排程到 hostnameABCDE 的 container_e24_1566836790522_8088_04_013155_1 slot 上,接下來我們就可以到 container container_e24_1566836790522_8088_04_013155 的 taskmanager.log 中查詢 Checkpoint 失敗的具體原因了。
另外對於 Checkpoint Decline 的情況,有一種情況我們在這裡單獨抽取出來進行介紹:Checkpoint Cancel。
當前 Flink 中如果較小的 Checkpoint 還沒有對齊的情況下,收到了更大的 Checkpoint,則會把較小的 Checkpoint 給取消掉。我們可以看到類似下面的日誌:
$taskNameWithSubTaskAndID: Received checkpoint barrier for checkpoint 20 before completing current checkpoint 19. Skipping current checkpoint.
這個日誌表示,當前 Checkpoint 19 還在對齊階段,我們收到了 Checkpoint 20 的 barrier。然後會逐級通知到下游的 task checkpoint 19 被取消了,同時也會通知 JM 當前 Checkpoint 被 decline 掉了。
在下游 task 收到被 cancelBarrier 的時候,會列印類似如下的日誌:
DEBUG
$taskNameWithSubTaskAndID: Checkpoint 19 canceled, aborting alignment.
或者
DEBUG
$taskNameWithSubTaskAndID: Checkpoint 19 canceled, skipping alignment.
或者
WARN
$taskNameWithSubTaskAndID: Received cancellation barrier for checkpoint 20 before completing current checkpoint 19. Skipping current checkpoint.
上面三種日誌都表示當前 task 接收到上游傳送過來的 barrierCancel 訊息,從而取消了對應的 Checkpoint。
2.1.2 Checkpoint Expire
如果 Checkpoint 做的非常慢,超過了 timeout 還沒有完成,則整個 Checkpoint 也會失敗。當一個 Checkpoint 由於超時而失敗是,會在 jobmanager.log 中看到如下的日誌:
Checkpoint 1 of job 85d268e6fbc19411185f7e4868a44178 expired before completing.
表示 Chekpoint 1 由於超時而失敗,這個時候可以可以看這個日誌後面是否有類似下面的日誌:
Received late message for now expired checkpoint attempt 1 from 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178.
可以按照 2.1.1 中的方法找到對應的 taskmanager.log 檢視具體資訊。
下面的日誌如果是 DEBUG 的話,我們會在開始處標記 DEBUG
我們按照下面的日誌把 TM 端的 snapshot 分為三個階段,開始做 snapshot 前,同步階段,非同步階段:
DEBUG
Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks (4/4)
這個日誌表示 TM 端 barrier 對齊後,準備開始做 Checkpoint。
DEBUG
2019-08-06 13:43:02,613 DEBUG org.apache.flink.runtime.state.AbstractSnapshotStrategy - DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@70442baf, checkpointDirectory=xxxxxxxx, sharedStateDirectory=xxxxxxxx, taskOwnedStateDirectory=xxxxxx, metadataFilePath=xxxxxx, reference=(default), fileStateSizeThreshold=1024}, synchronous part) in thread Thread[Async calls on Source: xxxxxx
_source -> Filter (27/70),5,Flink Task Threads] took 0 ms.
上面的日誌表示當前這個 backend 的同步階段完成,共使用了 0 ms。
DEBUG
DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@7908affe, checkpointDirectory=xxxxxx, sharedStateDirectory=xxxxx, taskOwnedStateDirectory=xxxxx, metadataFilePath=xxxxxx, reference=(default), fileStateSizeThreshold=1024}, asynchronous part) in thread Thread[pool-48-thread-14,5,Flink Task Threads] took 369 ms
上面的日誌表示非同步階段完成,非同步階段使用了 369 ms
在現有的日誌情況下,我們通過上面三個日誌,定位 snapshot 是開始晚,同步階段做的慢,還是非同步階段做的慢。然後再按照情況繼續進一步排查問題。
2.2 Checkpoint 慢
在 2.1 節中,我們介紹了 Checkpoint 失敗的排查思路,本節會分情況介紹 Checkpoint 慢的情況。
Checkpoint 慢的情況如下:比如 Checkpoint interval 1 分鐘,超時 10 分鐘,Checkpoint 經常需要做 9 分鐘(我們希望 1 分鐘左右就能夠做完),而且我們預期 state size 不是非常大。
對於 Checkpoint 慢的情況,我們可以按照下面的順序逐一檢查。
2.2.0 Source Trigger Checkpoint 慢
這個一般發生較少,但是也有可能,因為 source 做 snapshot 並往下游傳送 barrier 的時候,需要搶鎖(這個現在社群正在進行用 mailBox 的方式替代當前搶鎖的方式,詳情參考[1])。如果一直搶不到鎖的話,則可能導致 Checkpoint 一直得不到機會進行。如果在 Source 所在的 taskmanager.log 中找不到開始做 Checkpoint 的 log,則可以考慮是否屬於這種情況,可以通過 jstack 進行進一步確認鎖的持有情況。
2.2.1 使用增量 Checkpoint
現在 Flink 中 Checkpoint 有兩種模式,全量 Checkpoint 和 增量 Checkpoint,其中全量 Checkpoint 會把當前的 state 全部備份一次到持久化儲存,而增量 Checkpoint,則只備份上一次 Checkpoint 中不存在的 state,因此增量 Checkpoint 每次上傳的內容會相對更好,在速度上會有更大的優勢。
現在 Flink 中僅在 RocksDBStateBackend 中支援增量 Checkpoint,如果你已經使用 RocksDBStateBackend,可以通過開啟增量 Checkpoint 來加速,具體的可以參考 [2]。
2.2.2 作業存在反壓或者資料傾斜
我們知道 task 僅在接受到所有的 barrier 之後才會進行 snapshot,如果作業存在反壓,或者有資料傾斜,則會導致全部的 channel 或者某些 channel 的 barrier 傳送慢,從而整體影響 Checkpoint 的時間,這兩個可以通過如下的頁面進行檢查:
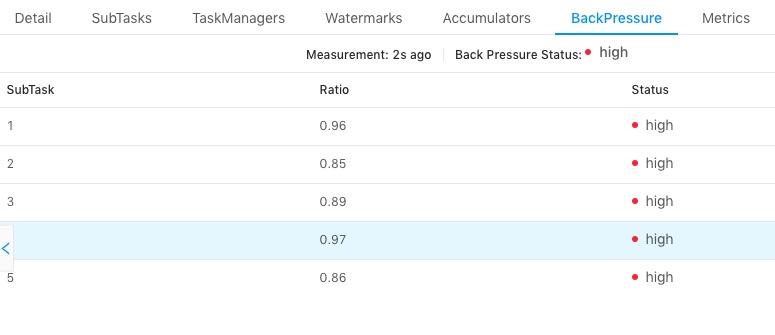
上圖中我們選擇了一個 task,檢視所有 subtask 的反壓情況,發現都是 high,表示反壓情況嚴重,這種情況下會導致下游接收 barrier 比較晚。
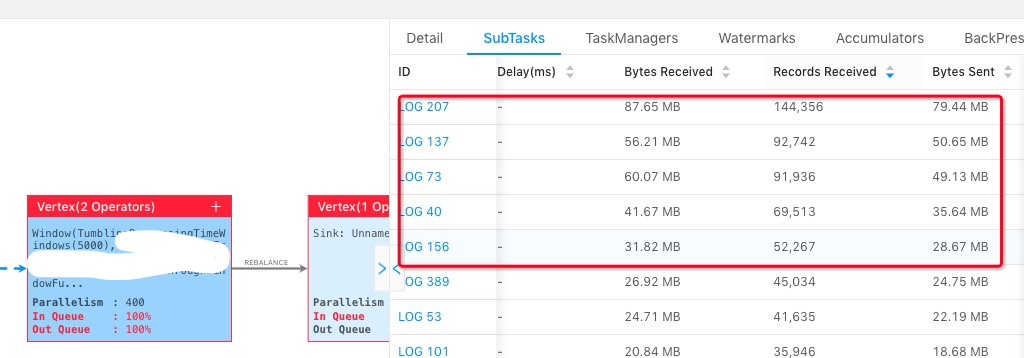
上圖中我們選擇其中一個 operator,點選所有的 subtask,然後按照 Records Received/Bytes Received/TPS 從大到小進行排序,能看到前面幾個 subtask 會比其他的 subtask 要處理的資料多。
如果存在反壓或者資料傾斜的情況,我們需要首先解決反壓或者資料傾斜問題之後,再檢視 Checkpoint 的時間是否符合預期。
2.2.2 Barrier 對齊慢
從前面我們知道 Checkpoint 在 task 端分為 barrier 對齊(收齊所有上游傳送過來的 barrier),然後開始同步階段,再做非同步階段。如果 barrier 一直對不齊的話,就不會開始做 snapshot。
barrier 對齊之後會有如下日誌列印:
DEBUG
Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks (4/4)
如果 taskmanager.log 中沒有這個日誌,則表示 barrier 一直沒有對齊,接下來我們需要了解哪些上游的 barrier 沒有傳送下來,如果你使用 At Least Once 的話,可以觀察下面的日誌:
DEBUG
Received barrier for checkpoint 96508 from channel 5
表示該 task 收到了 channel 5 來的 barrier,然後看對應 Checkpoint,再檢視還剩哪些上游的 barrier 沒有接受到,對於 ExactlyOnce 暫時沒有類似的日誌,可以考慮自己新增,或者 jmap 檢視。
2.2.3 主執行緒太忙,導致沒機會做 snapshot
在 task 端,所有的處理都是單執行緒的,資料處理和 barrier 處理都由主執行緒處理,如果主執行緒在處理太慢(比如使用 RocksDBBackend,state 操作慢導致整體處理慢),導致 barrier 處理的慢,也會影響整體 Checkpoint 的進度,在這一步我們需要能夠檢視某個 PID 對應 hotmethod,這裡推薦兩個方法:
1.多次連續 jstack,檢視一直處於 RUNNABLE 狀態的執行緒有哪些;
2.使用工具 AsyncProfile dump 一份火焰圖,檢視佔用 CPU 最多的棧;
如果有其他更方便的方法當然更好,也歡迎推薦。
2.2.4 同步階段做的慢
同步階段一般不會太慢,但是如果我們通過日誌發現同步階段比較慢的話,對於非 RocksDBBackend 我們可以考慮檢視是否開啟了非同步 snapshot,如果開啟了非同步 snapshot 還是慢,需要看整個 JVM 在幹嘛,也可以使用前一節中的工具。對於 RocksDBBackend 來說,我們可以用 iostate 檢視磁碟的壓力如何,另外可以檢視 tm 端 RocksDB 的 log 的日誌如何,檢視其中 SNAPSHOT 的時間總共開銷多少。
RocksDB 開始 snapshot 的日誌如下:
2019/09/10-14:22:55.734684 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:83] Started the snapshot process -- creating snapshot in directory /tmp/flink-io-87c360ce-0b98-48f4-9629-2cf0528d5d53/XXXXXXXXXXX/chk-92729
snapshot 結束的日誌如下:
2019/09/10-14:22:56.001275 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:145] Snapshot DONE. All is good
2.2.5 非同步階段做的慢
對於非同步階段來說,tm 端主要將 state 備份到持久化儲存上,對於非 RocksDBBackend 來說,主要瓶頸來自於網路,這個階段可以考慮觀察網路的 metric,或者對應機器上能夠觀察到網路流量的情況(比如 iftop)。
對於 RocksDB 來說,則需要從本地讀取檔案,寫入到遠端的持久化儲存上,所以不僅需要考慮網路的瓶頸,還需要考慮本地磁碟的效能。另外對於 RocksDBBackend 來說,如果覺得網路流量不是瓶頸,但是上傳比較慢的話,還可以嘗試考慮開啟多執行緒上傳功能[3]。
3 總結
在第二部分內容中,我們介紹了官方編譯的包的情況下排查一些 Checkpoint 異常情況的主要場景,以及相應的排查方法,如果排查了上面所有的情況,還是沒有發現瓶頸所在,則可以考慮新增更詳細的日誌,逐步將範圍縮小,然後最終定位原因。
上文提到的一些 DEBUG 日誌,如果 flink dist 包是自己編譯的話,則建議將 Checkpoint 整個步驟內的一些 DEBUG 改為 INFO,能夠通過日誌瞭解整個 Checkpoint 的整體階段,什麼時候完成了什麼階段,也在 Checkpoint 異常的時候,快速知道每個階段都消耗了多少時間。
本文作者:邱從賢(山智)
原文連結:https://yq.aliyun.com/articles/718452?utm_content=g_1000076725
本文為雲棲社群原創內容,未經