
分析原始碼,學會正確使用 Java 執行緒池
在日常的開發工作當中,執行緒池往往承載著一個應用中最重要的業務邏輯,因此我們有必要更多地去關注執行緒池的執行情況,包括異常的處理和分析等。本文主要聚焦在如何正確使用執行緒池上,以及提供一些實用的建議。文中會稍微涉及到一些執行緒池實現原理方面的知識,但是不會過多展開。
執行緒池的異常處理
UncaughtExceptionHandler
我們都知道Runnable介面中的run方法是不允許丟擲異常的,因此派生出這個執行緒的主執行緒可能無法直接獲得該執行緒在執行過程中的異常資訊。如下例:
public static void main(String[] args) throws Exception { Thread thread = new Thread(() -> { Uninterruptibles.sleepUninterruptibly(2, TimeUnit.SECONDS); System.out.println(1 / 0); // 這行會導致報錯! }); thread.setUncaughtExceptionHandler((t, e) -> { e.printStackTrace(); //如果你把這一行註釋掉,這個程式將不會丟擲任何異常. }); thread.start(); }
為什麼會這樣呢?其實我們看一下Thread中的原始碼就會發現,Thread在執行過程中如果遇到了異常,會先判斷當前執行緒是否有設定UncaughtExceptionHandler,如果沒有,則會從執行緒所在的ThreadGroup中獲取。
注意:每個執行緒都有自己的ThreadGroup,即使你沒有指定,並且它實現了UncaughtExceptionHandler介面。
我們看下ThreadGroup中預設的對UncaughtExceptionHandler介面的實現:
public void uncaughtException(Thread t, Throwable e) { if (parent != null) { parent.uncaughtException(t, e); } else { Thread.UncaughtExceptionHandler ueh = Thread.getDefaultUncaughtExceptionHandler(); if (ueh != null) { ueh.uncaughtException(t, e); } else if (!(e instanceof ThreadDeath)) { System.err.print("Exception in thread \"" + t.getName() + "\" "); e.printStackTrace(System.err); } } }
這個ThreadGroup如果有父ThreadGroup,則呼叫父ThreadGroup的uncaughtException,否則呼叫全域性預設的Thread.DefaultUncaughtExceptionHandler,如果全域性的handler也沒有設定,則只是簡單地將異常資訊定位到System.err中,這就是為什麼我們應當在建立執行緒的時候,去實現它的UncaughtExceptionHandler介面的原因,這麼做可以讓你更方便地去排查問題。
通過execute提交任務給執行緒池
回到執行緒池這個話題,如果我們向執行緒池提交的任務中,沒有對異常進行try...catch處理,並且執行的時候出現了異常,那會對執行緒池造成什麼影響呢?答案是沒有影響,執行緒池依舊可以正常工作,但是異常卻被吞掉了
那麼怎樣才能拿到原始的異常物件呢?我們從執行緒池的原始碼著手開始研究這個問題。當然網上關於執行緒池的原始碼解析文章有很多,這裡限於篇幅,直接給出最相關的部分程式碼:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}這個方法就是真正去執行提交給執行緒池的任務的程式碼。
這裡我們略去其中不相關的邏輯,重點關注第19行到第32行的邏輯,其中第23行是真正開始執行提交給執行緒池的任務,那麼第20行是幹什麼的呢?其實就是在執行提交給執行緒池的任務之前可以做一些前置工作,同樣的,我們看到第31行,這個是在執行完提交的任務之後,可以做一些後置工作。
beforeExecute這個我們暫且不管,重點關注下afterExecute這個方法。我們可以看到,在執行任務過程中,一旦丟擲任何型別的異常,都會提交給afterExecute這個方法,然而檢視執行緒池的原始碼我們可以發現,預設的afterExecute是個空實現,因此,我們有必要繼承ThreadPoolExecutor去實現這個afterExecute方法。
看原始碼我們可以發現這個afterExecute方法是protected型別的,從官方註釋上也可以看到,這個方法就是推薦子類去實現的。
當然,這個方法不能隨意去實現,需要遵循一定的步驟,具體的官方註釋也有講,這裡摘抄如下:
* <pre> {@code
* class ExtendedExecutor extends ThreadPoolExecutor {
* // ...
* protected void afterExecute(Runnable r, Throwable t) {
* super.afterExecute(r, t);
* if (t == null && r instanceof Future<?>) {
* try {
* Object result = ((Future<?>) r).get();
* } catch (CancellationException ce) {
* t = ce;
* } catch (ExecutionException ee) {
* t = ee.getCause();
* } catch (InterruptedException ie) {
* Thread.currentThread().interrupt(); // ignore/reset
* }
* }
* if (t != null)
* System.out.println(t);
* }
* }}</pre>那麼通過這種方式,就可以將原先可能被執行緒池吞掉的異常成功捕獲到,從而便於排查問題。
但是這裡還有個小問題,我們注意到在runWorker方法中,執行task.run();語句之後,各種型別的異常都被丟擲了,那這些被丟擲的異常去了哪裡?事實上這裡的異常物件最終會被傳入到Thread的dispatchUncaughtException方法中,原始碼如下:
private void dispatchUncaughtException(Throwable e) {
getUncaughtExceptionHandler().uncaughtException(this, e);
}可以看到它會去獲取UncaughtExceptionHandler的實現類,然後呼叫其中的uncaughtException方法,這也就回到了我們上一小節所分析的UncaughtExceptionHandler實現的具體邏輯。那麼為了拿到最原始的異常物件,除了實現UncaughtExceptionHandler介面之外,也可以考慮實現afterExecute方法。
通過submit提交任務到執行緒池
這個同樣很簡單,我們還是先回到submit方法的原始碼:
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}這裡的execute方法呼叫的是ThreadPoolExecutor中的execute方法,執行邏輯跟通過execute提交任務到執行緒池是一樣的。我們先重點關注這裡的newTaskFor方法,其原始碼如下:
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
可以看到提交的Callable物件用FutureTask封裝起來了。我們知道最終會執行到上述runWorker這個方法中,並且最核心的執行邏輯就是task.run();這行程式碼。我們知道這裡的task其實是FutureTask型別,因此我們有必要看一下FutureTask中的run方法的實現:
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}可以看到這其中跟異常相關的最關鍵的程式碼就在第17行,也就是setException(ex);這個地方。我們看一下這個地方的實現:
protected void setException(Throwable t) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = t;
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
finishCompletion();
}
}這裡最關鍵的地方就是將異常物件賦值給了outcome,outcome是FutureTask中的成員變數,我們通過呼叫submit方法,拿到一個Future物件之後,再呼叫它的get方法,其中最核心的方法就是report方法,下面給出每個方法的原始碼:
首先是get方法:
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}可以看到最終呼叫了report方法,其原始碼如下:
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}上面是一些狀態判斷,如果當前任務不是正常執行完畢,或者被取消的話,那麼這裡的x其實就是原始的異常物件,可以看到會被ExecutionException包裝。因此在你呼叫get方法時,可能會丟擲ExecutionException異常,那麼呼叫它的getCause方法就可以拿到最原始的異常物件了。
綜上所述,針對提交給執行緒池的任務可能會丟擲異常這一問題,主要有以下兩種處理思路:
- 在提交的任務當中自行try...catch,但這裡有個不好的地方就是如果你會提交多種型別的任務到執行緒池中,每種型別的任務都需要自行將異常try...catch住,比較繁瑣。而且如果你只是catch(Exception e),可能依然會漏掉一些包括Error型別的異常,那為了保險起見,可以考慮catch(Throwable t)。
- 自行實現執行緒池的afterExecute方法,或者實現Thread的UncaughtExceptionHandler介面。
下面給出我個人建立執行緒池的一個示例,供大家參考:
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(DEFAULT_QUEUE_SIZE);
statisticsThreadPool = new ThreadPoolExecutor(DEFAULT_CORE_POOL_SIZE, DEFAULT_MAX_POOL_SIZE,
60, TimeUnit.SECONDS, queue, new ThreadFactoryBuilder()
.setThreadFactory(new ThreadFactory() {
private int count = 0;
private String prefix = "StatisticsTask";
@Override
public Thread newThread(Runnable r) {
return new Thread(r, prefix + "-" + count++);
}
}).setUncaughtExceptionHandler((t, e) -> {
String threadName = t.getName();
logger.error("statisticsThreadPool error occurred! threadName: {}, error msg: {}", threadName, e.getMessage(), e);
}).build(), (r, executor) -> {
if (!executor.isShutdown()) {
logger.warn("statisticsThreadPool is too busy! waiting to insert task to queue! ");
Uninterruptibles.putUninterruptibly(executor.getQueue(), r);
}
}) {
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (t == null && r instanceof Future<?>) {
try {
Future<?> future = (Future<?>) r;
future.get();
} catch (CancellationException ce) {
t = ce;
} catch (ExecutionException ee) {
t = ee.getCause();
} catch (InterruptedException ie) {
Thread.currentThread().interrupt(); // ignore/reset
}
}
if (t != null) {
logger.error("statisticsThreadPool error msg: {}", t.getMessage(), t);
}
}
};
statisticsThreadPool.prestartAllCoreThreads();執行緒數的設定
我們知道任務一般有兩種:CPU密集型和IO密集型。那麼面對CPU密集型的任務,執行緒數不宜過多,一般選擇CPU核心數+1或者核心數的2倍是比較合理的一個值。因此我們可以考慮將corePoolSize設定為CPU核心數+1,maxPoolSize設定為核心數的2倍。
同樣的,面對IO密集型任務時,我們可以考慮以核心數乘以4倍作為核心執行緒數,然後核心數乘以5倍作為最大執行緒數的方式去設定執行緒數,這樣的設定會比直接拍腦袋設定一個值會更合理一些。
當然總的執行緒數不宜過多,控制在100個執行緒以內比較合理,否則執行緒數過多可能會導致頻繁地上下文切換,導致系統性能反不如前。
如何正確關閉一個執行緒池
說到如何正確去關閉一個執行緒池,這裡面也有點講究。為了實現優雅停機的目標,我們應當先呼叫shutdown方法,呼叫這個方法也就意味著,這個執行緒池不會再接收任何新的任務,但是已經提交的任務還會繼續執行,包括佇列中的。所以,之後你還應當呼叫awaitTermination方法,這個方法可以設定執行緒池在關閉之前的最大超時時間,如果在超時時間結束之前執行緒池能夠正常關閉,這個方法會返回true,否則,一旦超時,就會返回false。通常來說我們不可能無限制地等待下去,因此需要我們事先預估一個合理的超時時間,然後去使用這個方法。
如果awaitTermination方法返回false,你又希望儘可能線上程池關閉之後再做其他資源回收工作,可以考慮再呼叫一下shutdownNow方法,此時佇列中所有尚未被處理的任務都會被丟棄,同時會設定執行緒池中每個執行緒的中斷標誌位。shutdownNow並不保證一定可以讓正在執行的執行緒停止工作,除非提交給執行緒的任務能夠正確響應中斷。到了這一步,可以考慮繼續呼叫awaitTermination方法,或者直接放棄,去做接下來要做的事情。
執行緒池中的其他有用方法
大家可能有留意到,我在建立執行緒池的時候,還呼叫了這個方法:prestartAllCoreThreads。這個方法有什麼作用呢?我們知道一個執行緒池創建出來之後,在沒有給它提交任何任務之前,這個執行緒池中的執行緒數為0。有時候我們事先知道會有很多工會提交給這個執行緒池,但是等它一個個去建立新執行緒開銷太大,影響系統性能,因此可以考慮在建立執行緒池的時候就將所有的核心執行緒全部一次性建立完畢,這樣系統起來之後就可以直接使用了。
其實執行緒池中還提供了其他一些比較有意思的方法。比如我們現在設想一個場景,當一個執行緒池負載很高,快要撐爆導致觸發拒絕策略時,有沒有什麼辦法可以緩解這一問題?其實是有的,因為執行緒池提供了設定核心執行緒數和最大執行緒數的方法,它們分別是setCorePoolSize方法和setMaximumPoolSize方法。是的,執行緒池建立完畢之後也是可以更改其執行緒數的!因此,面對執行緒池高負荷執行的情況,我們可以這麼處理:
- 起一個定時輪詢執行緒(守護型別),定時檢測執行緒池中的執行緒數,具體來說就是呼叫getActiveCount方法。
- 當發現執行緒數超過了核心執行緒數大小時,可以考慮將CorePoolSize和MaximumPoolSize的數值同時乘以2,當然這裡不建議設定很大的執行緒數,因為並不是執行緒越多越好的,可以考慮設定一個上限值,比如50、100之類的。
- 同時,去獲取佇列中的任務數,具體來說是呼叫getQueue方法再呼叫size方法。當佇列中的任務數少於佇列大小的二分之一時,我們可以認為現線上程池的負載沒有那麼高了,因此可以考慮線上程池先前有擴容過的情況下,將CorePoolSize和MaximumPoolSize還原回去,也就是除以2。
具體來說如下圖:
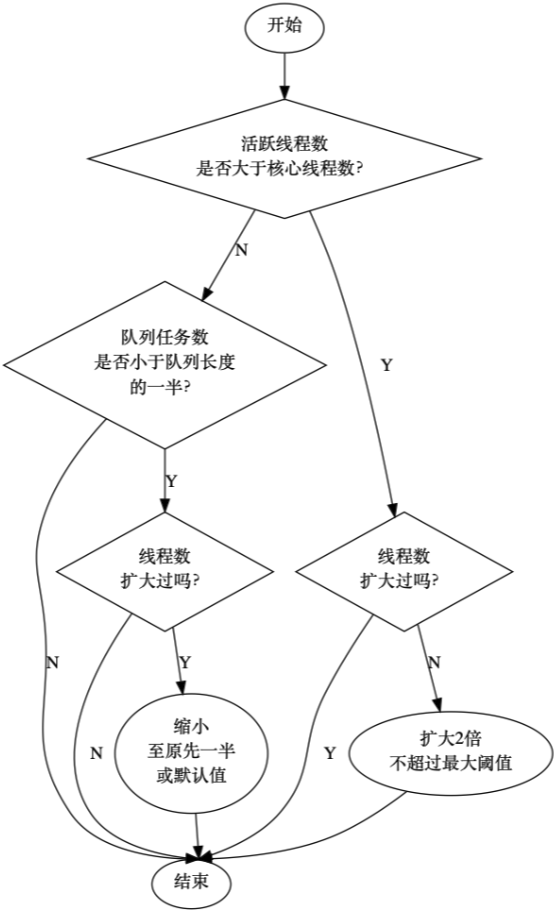
以上是我個人建議的一種使用執行緒池的方式。
執行緒池一定是最佳方案嗎?
執行緒池並非在任何情況下都是效能最優的方案。如果是一個追求極致效能的場景,可以考慮使用Disruptor,這是一個高效能佇列。排除Disruptor不談,單純基於JDK的話會不會有更好的方案?答案是有的。
我們知道在一個執行緒池中,多個執行緒是共用一個佇列的,因此在任務很多的情況下,需要對這個佇列進行頻繁讀寫,為了防止衝突因此需要加鎖。事實上在閱讀執行緒池原始碼的時候就可以發現,裡面充斥著各種加鎖的程式碼,那有沒有更好的實現方式呢?
其實我們可以考慮建立一個由單執行緒執行緒池構成的列表,每個執行緒池都使用有界佇列這種方式去實現多執行緒。這麼做的好處是,每個執行緒池中的佇列都只會被一個執行緒去操作,這樣就沒有競爭的問題。
其實這種用空間換時間的思路借鑑了Netty中EventLoop的實現機制。試想,如果執行緒池的效能真的有那麼好,為什麼Netty不用呢?
其他需要注意的地方
- 任何情況下都不應該使用可伸縮執行緒池(執行緒的建立和銷燬開銷是很大的)。
- 任何情況下都不應該使用無界佇列,單測除外。有界佇列常用的有ArrayBlockingQueue和LinkedBlockingQueue,前者基於陣列實現,後者基於連結串列。從效能表現上來看,LinkedBlockingQueue的吞吐量更高但是效能並不穩定,實際情況下應當使用哪一種建議自行測試之後決定。順便說一句,Executors的newFixedThreadPool採用的是LinkedBlockingQueue。
- 推薦自行實現RejectedExecutionHandler,JDK自帶的都不是很好用,你可以在裡面實現自己的邏輯。如果需要一些特定的上下文資訊,可以在Runnable實現類中新增一些自己的東西,這樣在RejectedExecutionHandler中就可以直接使用了。
怎樣做到不丟任務
這裡其實指的是一種特殊情況,就是比如突然遇到了一股流量尖峰,導致執行緒池負載已經非常高了,即快要觸發拒絕策略的時候,我們可以怎麼做來儘量防止提交的任務丟失。一般來說當遇到這種情況的時候,應當儘快觸發報警通知研發人員來處理。之後不管是限流也好,還是增加機器也好,甚至是上Kafka、Redis甚至是資料庫用來暫存任務資料也是可以的,但畢竟遠水救不了近火,如果我們希望在正式解決這個問題之前,先儘可能地緩解,可以考慮怎麼做呢?
首先可以考慮的就是我前面提到的動態增大執行緒池中的執行緒數,但是假如已經擴容過了,此時不應繼續擴容,否則可能導致系統的吞吐量更低。在這種情況下,應當自行實現RejectedExecutionHandler,具體來說就是在實現類中,單獨開一個單執行緒的執行緒池,然後呼叫原執行緒池的getQueue方法的put方法,將塞不進去的任務再次嘗試塞進去。當然在佇列滿的時候是塞不進去的,但那至少也只是阻塞了這個單獨的執行緒而已,並不影響主流程。
當然,這種方案是治標不治本的,面對流量激增這種場景其實業界有很多成熟的做法,只是單純從執行緒池的角度來看的話,這種方式不失為一種臨時有效的解決方案。
作者簡介
呂亞東,某風控領域網際網路公司技術專家,主要關注高效能,高併發以及中介軟體底層原理和調優等領域。email:[email protected]
---------------------------------------------
讀完文章先別走,歡迎大家轉發就文章相關內容進行討論與轉發,我們後續會從評論區抽取 9 名評論優質的讀者贈送《實戰Java虛擬機器———JVM故障診斷與效能優化(第2版)》一書。感謝 @博文視點 提供的獎品。

簡介:《實戰Java虛擬機器———JVM故障診斷與效能優化(第2版)》第1~3章介紹了Java虛擬機器的定義、總體架構、常用配置引數。第4~5章介紹了垃圾回收的演算法和各種垃圾回收器。第6章介紹了Java虛擬機器的效能監控和故障診斷工具。第7章詳細介紹了對Java堆的分析方法和案例。第8章介紹了Java虛擬機器對多執行緒,尤其是對鎖的支援。第9~10章介紹了Java虛擬機器的核心—Class檔案結構,以及Java虛擬機器中類的裝載系統。第11章介紹了Java虛擬機器的執行系統和位元組碼,並給出了通過ASM框架進行位元組碼注入的案例。
購買地址:京東
同時也歡迎大家踴躍投稿,每一期的投稿文章作者也會獲得贈書噢!
投稿要求見: