
Java NIO之理解I/O模型(二)
前言
上一篇文章講解了I/O模型的一些基本概念,包括同步與非同步,阻塞與非阻塞,同步IO與非同步IO,阻塞IO與非阻塞IO。這次一起來了解一下現有的幾種IO模型,以及高效IO的兩種設計模式,也都是屬於IO模型的基礎知識。
UNIX下可用的五種I/O模型
根據UNIX網路程式設計對IO模型的分類,UNIX提供了5種IO模型,下面分別來介紹一下。
阻塞I/O模型
最常見的一種IO模型,之前介紹過,一個read操作是分兩個階段的,第一個階段是,等待資料準備就緒,第二個階段是將資料拷貝到呼叫這個IO的執行緒中。阻塞是發生在第一個階段的,當資料沒有準備好時,會一直阻塞使用者執行緒,當資料就緒後再將資料拷貝到執行緒中,並返回結果給使用者執行緒。
大致過程如下圖。
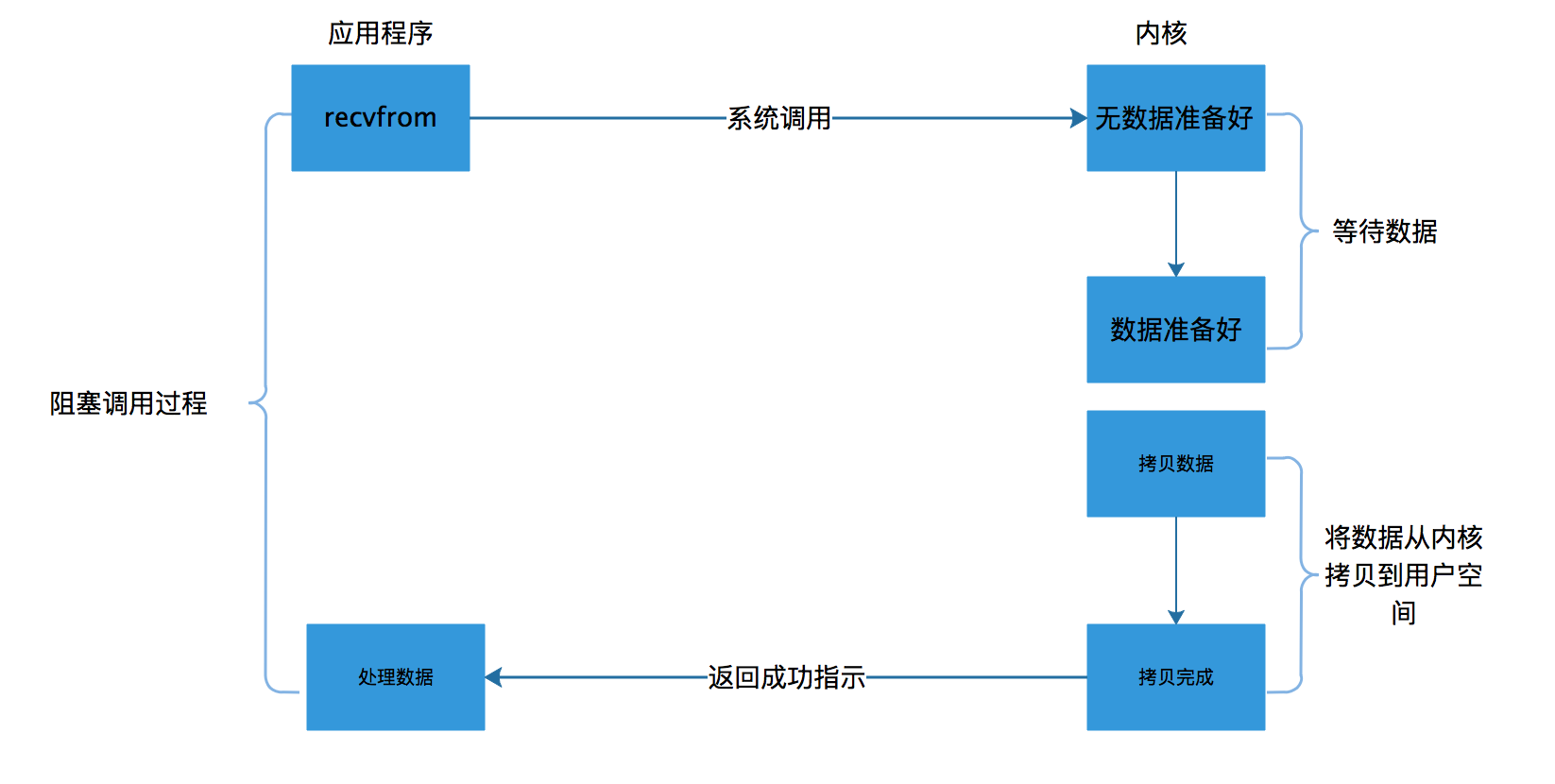
其實,大部分的socket介面都是典型的阻塞型。所謂阻塞型的介面是指系統呼叫(一般是IO介面)不返回呼叫結果並讓當前執行緒一直阻塞,只有當該系統呼叫獲得結果或者超時出錯時才返回。
通過介紹了阻塞IO,我們很容易就會發現它的問題,那就是阻塞會是使用者執行緒無法進行任何運算和請求。一般我們的處理這種問題的情況是使用多執行緒,每個連結建立一個執行緒,或是使用執行緒池來管理執行緒,或許可以緩解部分壓力,但是不能解決所有問題。多執行緒模型可以方便高效的解決小規模的服務請求,但面對大規模的服務請求,多執行緒模型也會遇到瓶頸,可以用非阻塞介面來嘗試解決這個問題。
非阻塞I/O模型
非阻塞IO模型是這樣一個過程,當應用程式發起一個read操作時,並不會阻塞,而是立刻會收到一個結果。應用程式的執行緒發現返回結果是一個error時,它就知道資料還沒有準備好,於是它可以再次傳送read操作。一旦資料準備好了,並且又再次收到了使用者執行緒的請求,那麼它馬上就將資料拷貝到了使用者記憶體,然後返回。
這樣的一個過程,其實是需要使用者執行緒不斷的去詢問系統是否準備好了資料,這樣就會一直佔用CPU資源。但是這種模型是在只專門提供某種功能的系統才有。
大致過程如下: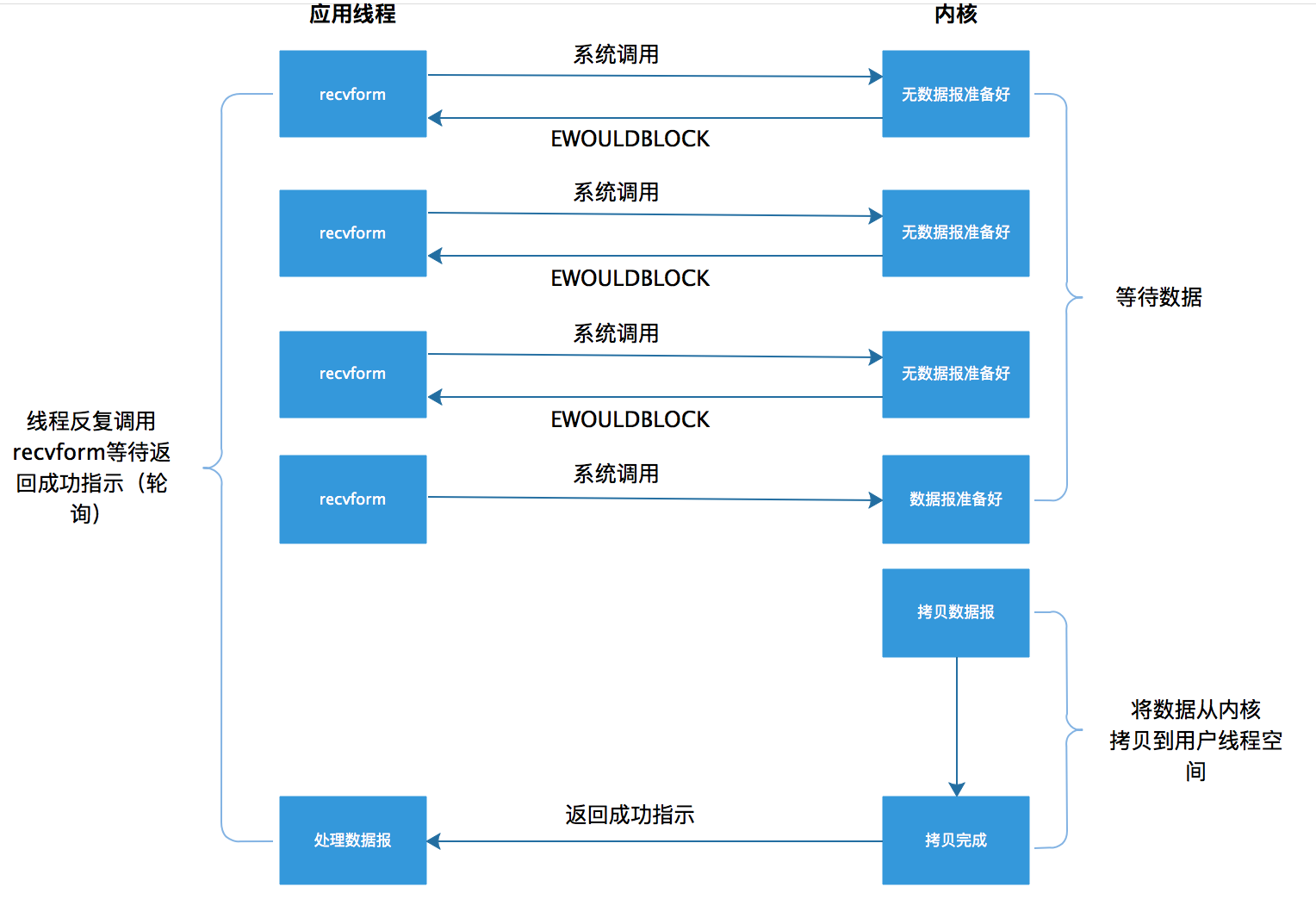
多路I/O複用模型
在介紹多路複用I/O時就要先簡單說明一下,select函式和poll函式。
select函式
select函式允許程序指示核心等待多個事件中的任何一個事件發生,並且只在有一個或多個事件發生或經歷一段指定的時間後才喚醒它。
- 舉個例子,我們可以呼叫select,告知核心僅在下列情況發生時才返回:
- 集合 {1,4,5} 中的任何描述符準備好讀;
- 集合 {2,7} 中的任何描述符準備好寫;
- 集合 {1,4} 中的任何描述符有異常條件待處理;
- 已經經歷10.2秒;
也就是說,我們呼叫select告知核心對哪些描述符(讀、寫或異常條件)感興趣以及等待多長時間。
poll函式
poll函式起源於SVR3,最初侷限於流裝置。SVR4取消了這種限制,允許poll工作在任何描述符上。poll函式提供的功能與select函式類似,但是poll沒有最大檔案描述符數量的限制。
select函式和poll函式將就緒的檔案描述符告訴程序後,如果程序沒有對其進行IO操作,那麼下次呼叫select函式或者poll函式時會再次報告這些檔案描述符, 所以他們一般不會丟失就緒的訊息,這種方式稱為水平觸發(Level Triggered)。
簡單的解了select函式和poll函式後,下面我們就繼續說多路I/O複用模型。多路IO複用模型就是呼叫select或poll函式,並且此模型的阻塞過程就是發生在呼叫這兩個函式中的,而不是發生在真正的的I/O系統呼叫上的,使用select或poll的好處在於可以用單個執行緒或程序,處理多個網路連線的IO。整個過程就是select或poll函式會不斷的輪詢所負責的socket,當某個socket有資料到達了,就通知使用者執行緒或程序。
大概呼叫如下:

Java中的NIO實際上就是使用的多路IO複用模型,通過selector.select()去查詢每個通道是否有到達事件,如果沒有事件,則一直阻塞在那裡,因此多路複用IO模型也會阻塞使用者執行緒,只不過執行緒是被select函式阻塞的而不是被scoket IO阻塞的。
所以多路複用IO模型和非阻塞IO有類似之處,但是多路複用IO模型的效率是比非阻塞IO模型要高的,因為在非阻塞IO中,不斷的詢問scoket狀態的是通過使用者執行緒去進行的,而多路複用IO模型,輪詢每個scoket狀態是核心在進行的,這個效率是比使用者執行緒要高很多的。這樣也能看出來多路複用IO模型比較適合連結數比較多的情況。
不過此模型也是存在問題的,由於多路複用IO模型是通過輪詢的方式來檢測是否有事件到達,並對到達的事件逐一響應,一旦事件響應體很大或是響應事件數量過多,就會消耗大量的時間去處理事件,從而影響整個過程的及時性。為了應對這種情況linux系統提供了epoll介面,但是除了linux的其他作業系統對epoll介面的支援又有很多差異,所以雖然epoll解決了事件檢測的時效性問題,但是在跨平臺能力上卻並不能得到很好的支援。
訊號驅動IO模型
在訊號驅動IO模型中,讓核心在資料報準備就緒時傳送SIGIO訊號通知使用者執行緒。
整個過程如下:

首先開啟套接字的訊號驅動式IO功能,並通過sigaction系統呼叫安裝一個訊號處理函式。該系統呼叫將立即返回,程序繼續工作,也就是說沒有被阻塞。當資料報準備好讀取時,核心就為該程序產生一個SIGIO訊號。我們隨後就可以在訊號處理函式中呼叫recvfrom讀取資料報,並通知使用者程序資料已經準備好了,可以讀取了。
這種模型的優點在於等待資料報到達期間不會被阻塞,使用者程序可以繼續執行,只要等待來自訊號處理函式的通知即可。
非同步IO模型
非同步IO模型的過程是這樣的,當用戶執行緒發起read操作時,告知核心啟動讀取資料操作,並讓核心在整個操作(包括將資料從核心複製到我們自己的緩衝區)完成後通知我們。這樣在核心執行讀取資料操作時,使用者執行緒可以繼續執行,當接收到核心在整個操作都完成的訊號時,就可以直接去使用資料了。
大致過程如下:
在非同步IO模型中,IO操作的兩個階段都不會阻塞使用者執行緒或程序,這兩個階段都是由核心完成的,然後傳送一個訊號告知使用者執行緒或程序操作已完成。非同步IO模型與訊號驅動IO模型的區別在於,訊號驅動IO模型是由核心通知使用者執行緒何時啟動一個IO操作,而非同步IO模型是由核心通知我們IO操作何時完成,非同步IO模型中使用者執行緒並不需要進行實際的讀寫操作,只需要在核心操作完成後,接到讀取完成訊號後,直接使用資料即可。
非同步IO是需要作業系統底層支援的,Linux從核心2.6版本才開始支援非同步IO。在Java 7中就已經支援非同步IO了。
兩種高效能IO設計模式Reactor和Proactor
Reactor模式
Reactor的意思是反應器,字面意思就是立即反應。
Reactor的工作方式:
(1)應用程式註冊讀就緒事件和相關聯的事件處理器
(2)Reactor阻塞等待核心事件通知
(3)Reactor收到通知,然後分發可讀寫事件(讀寫準備就緒)到使用者事件處理函式
(4)使用者讀取資料,並處理資料
(5)事件處理器完成實際的讀操作,處理讀到的資料,註冊新的事件,然後返還控制權。
大致過程是,每個應用程式宣佈它對某個socket感興趣,然後就需要到Reactor中註冊感興趣事件以及相關的處理函式。當socket發現有事件到達時,就會按順序對每個事件進行處理(呼叫處理函式),當所有事件處理完成後,會繼續迴圈這整個操作。
過程如下圖所示:

從這個設計模式的處理過程中可以看出,多路IO複用模型就是使用的 Reactor模式,並且這種設計模式還是體現的同步IO。
Proactor模式
Proactor的意思是主動器,主動去完成相應的工作不影響主流程。
Proactor模式的工作方式:
(1)應用程式初始化一個非同步讀取操作,然後註冊相應的事件處理器,此時事件處理器不關注讀取就緒事件,而是關注讀取完成事件,這是區別於Reactor的關鍵。
(2)事件分離器等待讀取操作完成事件
(3)在事件分離器等待讀取操作完成的時候,作業系統呼叫核心執行緒完成讀取操作,並將讀取的內容放入使用者傳遞過來的快取區中。這也是區別於Reactor的一點,Proactor中,應用程式需要傳遞快取區。
(4)事件分離器捕獲到讀取完成事件後,啟用應用程式註冊的事件處理器,事件處理器直接從快取區讀取資料,而不需要進行實際的讀取操作。
非同步IO模型就是使用的Proactor模式。
參考資料:
《Unix網路程式設計》
https://www.cnblogs.com/dolphin0520/p/3916526.html
https://www.cnblogs.com/findumars/p/6361627.html
http://ifeve.com/io%E6%A8%A1%E5%9E%8B%E8%A7%A3%E6%83%91/
&n