
實現一個正則表示式引擎in Python(一)
前言
專案地址:Regex in Python
開學摸魚了幾個禮拜,最近幾天用Python造了一個正則表示式引擎的輪子,在這裡記錄分享一下。
實現目標
實現了所有基本語法
st = 'AS342abcdefg234aaaaabccccczczxczcasdzxc'
pattern = '([A-Z]+[0-9]*abcdefg)([0-9]*)(\*?|a+)(zx|bc*)([a-z]+|[0-9]*)(asd|fgh)(zxc)'
regex = Regex(st, pattern)
result = regex.match()
log(result)更多示例可以在github上看到
前置知識
其實正則表示式的引擎完全可以看作是一個小型的編譯器,所以完全可以按之前寫的那個C語言的編譯器的思路來,只是沒有那麼複雜而已
- 首先進行詞法分析
- 語法分析(這裡用自頂向下)
- 語義分析 (因為正則的表達能力非常弱,所以可以省略生成AST的部分直接進行程式碼生成)
- 程式碼生成,這裡也就是進行NFA的生成
- NFA到DFA的轉換,這裡開始就是正則和狀態機的相關的知識了
- DFA的最小化
NFA和DFA
有限狀態機可以看作是一個有向圖,狀態機中有若干個節點,每個節點都可以根據輸入字元來跳轉到下一個節點,而區別NFA((非確定性有限狀態自動機)和DFA(確定性有限狀態自動機)的是DFA的下一個跳轉狀態是唯一確定的)
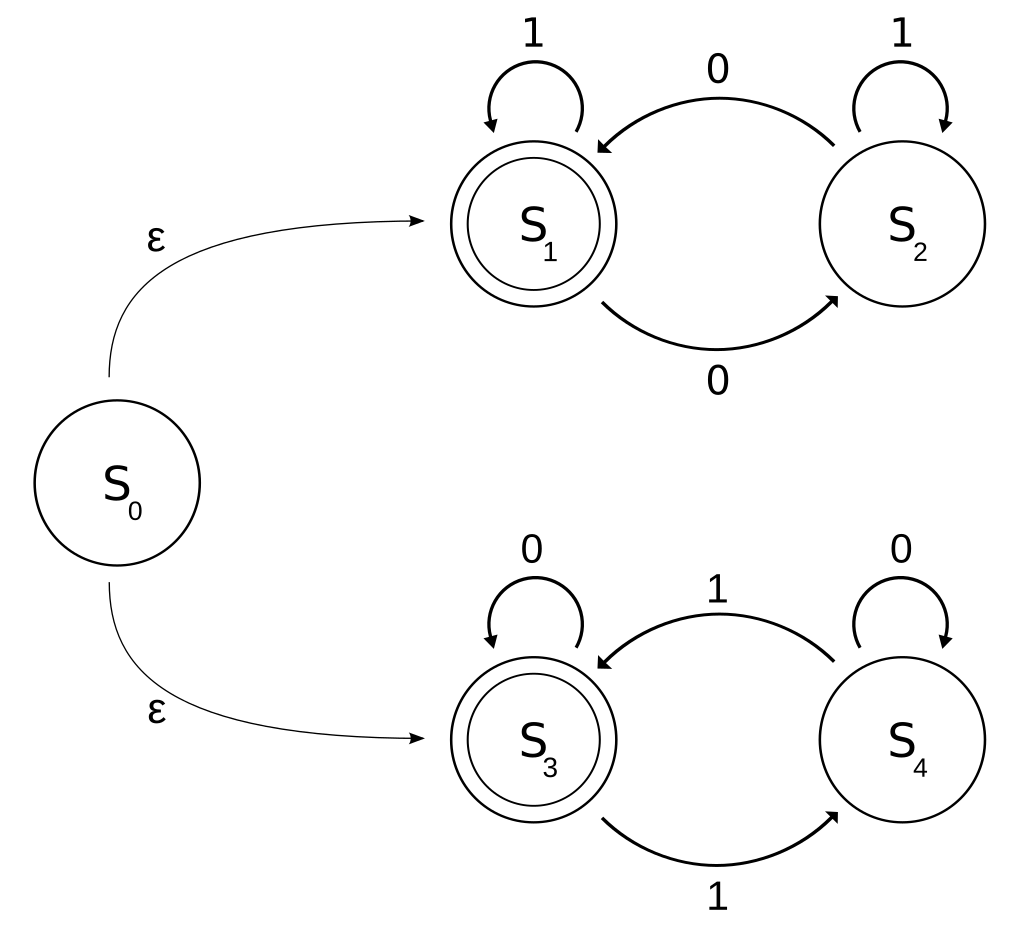
有限狀態自動機從開始的初始狀態開始讀取輸入的字串,自動機使用狀態轉移函式move根據當前狀態和當前的輸入字元來判斷下一個狀態,但是NFA的下一個狀態不是唯一確定的,所以只能確定的是下一個狀態集合,這個狀態集合還需要依賴之後的輸入才能確定唯一所處的狀態。如果當自動機完成讀取的時候,它處於接收狀態的話,則說明NFA可以接收這個輸入字串
對於所有的NFA最後都可以轉換為對應的DFA
NFA構造O(n),匹配O(nm)
DFA構造O(2^n),最小化O(kn'logn')(N'=O(2^n)),匹配O(m)
n=regex長度,m=串長,k=字母表大小,n'=原始的dfa大小
NFA接受的所有字串的集合是NFA接受的語言。這個語言是正則語言。
例子
對於正則表示式:[0-9]*[A-Z]+,對應的NFA就是將下面兩個NFA的節點3和節點4連線起來
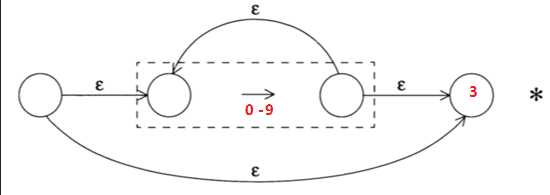
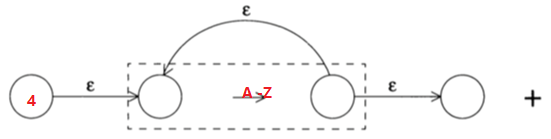
詞法分析
對於NFA和DFA其實只要知道這麼多和一些相應的演算法就已經足夠了,相應的演算法在後面提及,先完成詞法分析的部分,
這個詞法分析比之前C語言編譯器的語法分析要簡單許多,只要處理幾種可能性
- 普通字元
- 含有語義的字元
- 轉義字元
token
token沒什麼好說的,就是對應正則裡的語法
Tokens = {
'.': Token.ANY,
'^': Token.AT_BOL,
'$': Token.AT_EOL,
']': Token.CCL_END,
'[': Token.CCL_START,
'}': Token.CLOSE_CURLY,
')': Token.CLOSE_PAREN,
'*': Token.CLOSURE,
'-': Token.DASH,
'{': Token.OPEN_CURLY,
'(': Token.OPEN_PAREN,
'?': Token.OPTIONAL,
'|': Token.OR,
'+': Token.PLUS_CLOSE,
}advance
advance是詞法分析裡最主要的函式,用來返回當前輸入字元的Token型別
def advance(self):
pos = self.pos
pattern = self.pattern
if pos > len(pattern) - 1:
self.current_token = Token.EOS
return Token.EOS
text = self.lexeme = pattern[pos]
if text == '\\':
self.isescape = not self.isescape
self.pos = self.pos + 1
self.current_token = self.handle_escape()
else:
self.current_token = self.handle_semantic_l(text)
return self.current_tokenadvance的主要邏輯就是讀入當前字元,再來判斷是否是轉義字元或者是其它字元
handle_escape用來處理轉義字元,當然轉義字元最後本質上返回的還是普通字元型別,這個函式的主要功能就是來記錄當前轉義後的字元,然後賦值給lexem,供之後構造自動機使用
handle_semantic_l只有兩行,一是查表,這個表儲存了所有的擁有語義的字元,如果查不到就直接返回普通字元型別了
完整程式碼就不放上來了,都在github上
構造NFA
構造NFA的主要檔案都在nfa包下,nfa.py是NFA節點的定義,construction.py是實現對NFA的構造
NFA節點定義
NFA節點的定義也很簡單,其實這個正則表示式引擎完整的實現只有900行左右,每一部分拆開看都非常簡單
edge和input_set都是用來指示邊的,邊一共可能有四種種可能的屬性
- 對應的節點有兩個出去的ε邊
edge = PSILON = -1 - 邊對應的是字符集
edge = CCL = -2
input_set = 相應字符集 - 一條ε邊
edge = EMPTY = -3 - 邊對應的是單獨的一個輸入字元c
edge = c
- 對應的節點有兩個出去的ε邊
- status_num每個節點都有唯一的一個標識
visited則是為了debug用來遍歷NFA
class Nfa(object):
STATUS_NUM = 0
def __init__(self):
self.edge = EPSILON
self.next_1 = None
self.next_2 = None
self.visited = False
self.input_set = set()
self.set_status_num()
def set_status_num(self):
self.status_num = Nfa.STATUS_NUM
Nfa.STATUS_NUM = Nfa.STATUS_NUM + 1
def set_input_set(self):
self.input_set = set()
for i in range(ASCII_COUNT):
self.input_set.add(chr(i))簡單節點的構造
節點的構造在nfa.construction下,這裡為了簡化程式碼把Lexer作為全域性變數,讓所有函式共享
正則表示式的BNF正規化如下,這樣我們可以採用自頂向下來分析,從最頂層的group開始向下遞迴
group ::= ("(" expr ")")*
expr ::= factor_conn ("|" factor_conn)*
factor_conn ::= factor | factor factor*
factor ::= (term | term ("*" | "+" | "?"))*
term ::= char | "[" char "-" char "]" | .BNF在之前寫C語言編譯器的時候有提到:從零寫一個編譯器(二)
主入口
這裡為了簡化程式碼,就把詞法分析器作為全域性變數,讓所有函式共享
主要邏輯非常簡單,就是初始化詞法分析器,然後傳入NFA頭節點開始進行遞迴建立節點
def pattern(pattern_string):
global lexer
lexer = Lexer(pattern_string)
lexer.advance()
nfa_pair = NfaPair()
group(nfa_pair)
return nfa_pair.start_nodeterm
雖然是採用的是自頂向下的語法分析,但是從自底向上看會更容易理解,term是最底部的構建,也就是像單個字元、字符集、.符號的節點的構建
term ::= char | "[" char "-" char "]" | | .
term的主要邏輯就是根據當前讀入的字元來判斷應該構建什麼節點
def term(pair_out):
if lexer.match(Token.L):
nfa_single_char(pair_out)
elif lexer.match(Token.ANY):
nfa_dot_char(pair_out)
elif lexer.match(Token.CCL_START):
nfa_set_nega_char(pair_out)三種節點的建構函式都很簡單,下面圖都是用markdown的mermaid隨便畫畫的
- nfa_single_char
單個字元的NFA構造就是建立兩個節點然後把當前匹配的字元作為edge

def nfa_single_char(pair_out):
if not lexer.match(Token.L):
return False
start = pair_out.start_node = Nfa()
pair_out.end_node = pair_out.start_node.next_1 = Nfa()
start.edge = lexer.lexeme
lexer.advance()
return True- nfa_dot_char
. 這個的NFA和上面單字元的唯一區別就是它的edge被設定為CCL,並且設定了input_set
# . 匹配任意單個字元
def nfa_dot_char(pair_out):
if not lexer.match(Token.ANY):
return False
start = pair_out.start_node = Nfa()
pair_out.end_node = pair_out.start_node.next_1 = Nfa()
start.edge = CCL
start.set_input_set()
lexer.advance()
return False- nfa_set_nega_char
這個函式邏輯上只比上面的多了一個處理input_set
def nfa_set_nega_char(pair_out):
if not lexer.match(Token.CCL_START):
return False
neagtion = False
lexer.advance()
if lexer.match(Token.AT_BOL):
neagtion = True
start = pair_out.start_node = Nfa()
start.next_1 = pair_out.end_node = Nfa()
start.edge = CCL
dodash(start.input_set)
if neagtion:
char_set_inversion(start.input_set)
lexer.advance()
return True小結
篇幅原因,現在已經寫到了三百多行,所以就分篇寫,準備在三篇內完成。下一篇寫構造更復雜的NFA和通過構造的NFA來分析輸入字串。最後寫從NFA轉換到DFA,再最後用DFA分析輸入的字元