
細談Redis五大資料型別
文章原創於公眾號:程式猿周先森。本平臺不定時更新,喜歡我的文章,歡迎關注我的微信公眾號。

上一篇文章有提到,Redis中使用最頻繁的有5種資料型別:String、List、Hash、Set、SortSet。上一篇文章只是單純介紹了下這5種資料型別使用到的指令以及常用場景,本篇文章會談談5種資料型別的底層資料結構以及各自常用的操作命令來分別進行解析。Redis作為目前最流行的Key-Value型記憶體資料庫,不僅資料庫操作在記憶體中進行,並且可定期的將資料持久化到磁碟中,所以效能相對普通資料庫高很多,而在Redis中,每個Value實際上都是以一個redisObject結構來表示:
typedef struct redisObject{
unsigned type:4;
unsigned encoding:4;
void *ptr;
int refCount;
unsigned lru:
}
我們可以看看這幾個引數分別的含義:
type:物件的資料型別,一般情況就是5大資料型別。
encode:redisObject物件底層編碼實現,主要編碼型別有簡單動態字串,連結串列,字典,跳躍表,整數集合及壓縮列表。
*ptr:指向底層實現資料結構的指標。
refCount:計數器,當引用計數值為0將會釋放物件。
lru:最後一次訪問本物件的時間。
String資料型別
String 資料結構是簡單的 Key-Value 型別,是Redis中最常用的一種資料型別,Value 可以是string或者數字。String資料型別實際上可以儲存字串、整數、浮點數三種不同型別的值,Redis是如何做到自動識別字符串、整數、浮點數三種不同型別的值。Redis是使用C實現的,但是並未使用C中的字串,實際上Redis自己實現了一個結構體SDS來替代String型別:
struct sdshdr{
//記錄buf陣列中已使用位元組的長度
int len;
//記錄buf陣列中剩餘空間的長度
int free;
//位元組陣列,用於儲存字串
char buf[];
};
我們可以看到free引數是用來判斷剩餘可使用空間的長度,len表示字串的長度,buf儲存字串的每一個字元以及結尾的'\0'。為什麼Redis要自己實現SDS結構體呢?因為SDS結構體有幾個優點:
由於len儲存了當前字串的實際長度,所以獲取長度時間複雜度為O(1)。SDS在拼接之前會對當前字串的空間進行自動調整和擴充套件,防止當前字串資料溢位。減少記憶體分配次數,SDS拼接字串發生時,如果此時的字串長度len小於1M,則SDS會分配和len大小相同的未使用空間給free,如果此時的字串長度len大於1M,則SDS會分配和1M的未使用空間給free,當字串縮短時,縮短的空間會疊加到free中,用於後續的拼接使用。
String資料型別常用命令:
- 常用命令:set、get、decr、incr、mget 等。
String資料型別適用場景:
分散式鎖
分散式session:將分散式應用session儲存到Redis中
商品秒殺
常規計數:部落格數,閱讀數
List資料型別
List資料結構是用來儲存多個有序的字串,List中的每個字串成為元素,List提供了節點重排和節點順序訪問的能力,在Redis中,List可以在兩端push和pop元素,還可以獲取指定範圍的元素列表,獲取指定索引下標的元素等,List資料結構主要有zipList(壓縮連結串列)和LinkedList(雙向連結串列)兩種實現方式。首先我們可以先看看LinkedList的結構:
type struct list{
//表頭節點
listNode head;
//表尾節點
listNode tail;
//包含的節點總數
unsigned long len;
};
可以看到每個LinkedList中都會包含一個表頭節點head和一個表尾結點tail,在LinkedList中每個節點都會有一個prev指向前一個元素,同時還有一個next指向後一個元素,每個節點的value就是節點的值。從而實現雙向連結串列,理解起來實際上和C中的雙向連結串列有很大程度的相似性。而另一種實現方式zipList是基於連續記憶體實現,有點類似於陣列方式,但是和陣列有點不一致的是zipList的每一個entry的大小可能不一致,需要特殊方法去控制解決,但是在執行push,pop操作時會有資料的遷移,時間複雜度為O(n), 所以一般只有在元素較少時才會使用zipList,我們可以看看zipList的結構:
type struct ziplist{
//整個壓縮列表的位元組數
uint32_t zlbytes;
//記錄壓縮列表尾節點到頭結點的位元組數,直接可以求節點的地址
uint32_t zltail_offset;
//記錄了節點數,有多種型別,預設如下
uint16_t zllength;
//節點
List entryX;
}
zipList中每個節點都會有以下幾個引數資訊:
previous_entry_length:記錄前一個節點的位元組長度
content:節點所儲存的內容,可以是一個位元組陣列或者整數
encoding:記錄content屬性中所儲存的資料型別以及長度
*** List資料型別適用場景**
在渲染文章列表時可以使用List資料型別,一般情況下每個使用者都會有自己釋出的文章列表,如果需要展示文章列表,就可以使用List資料型別,不但可以有序而且可以按照索引範圍去查詢文章列表。
Set資料型別
Set資料型別和List資料型別有點類似,也可以用來儲存多個元素,但最大的一點區別在於Set資料型別不允許出現重複的元素,並且Set中的元素是無序的,所以沒辦法和List一樣通過索引下標獲取元素,但是Set型別支援多個Set集合取交集、並集、差集,所以合理使用Set資料型別,可以在實際專案開發中解決很多問題。Set資料型別有兩種資料結構:IntSet和HashTable。首先我們來看看IntSet的結構:
typedef struct intset {
// 編碼方式
uint32_t enconding;
// 集合包含的元素數量
uint32_t length;
// 儲存元素的陣列
int8_t contents[];
} intset;
當Set集合中所有元素都為整型時,Redis才會使用IntSet資料結構。有一點需要格外注意的是:IntSet資料結構是有序的。因為為了減輕效能的消耗,Redis在Set集合元素都為整型時,會使用一種基於動態陣列的結構體,同時在push元素的時候控制元素的大小順序,這樣就可以使用二分查詢演算法來對元素進行push及pop操作,這樣時間複雜度僅為O(logN)。在Set集合中元素存在非整型資料時,Redis這時會自動採用HashTable資料結構來存放資料,在HashTable中,存放的只有key值而沒有value值,所以說在HashTable中,鍵值永遠為null。我們可以看下HashTable的結構:
typedef struct dict{
//型別特定函式
dictType *type;
//雜湊表 兩個,一個用於實時儲存,一個用於rehash
dictht ht[2];
//rehash索引 資料遷移時使用
unsigned rehashidx;
}
Set資料型別使用場景:
記錄唯一值:比如登入ip,身份證號
新增標籤:可以通過標籤的交併集計算使用者喜好程度等資料。
Hash資料型別
在Redis中雜湊型別是指鍵本身又是一種鍵值對結構,也就是我們所說的物件,所以Hash資料型別用來儲存物件是最合適的資料型別。Hash資料型別的編碼可以是zipList或HashTable。當雜湊物件儲存的所有鍵值對長度小於64位元組並且元素數量少於512時使用zipList,否則使用HashTable。zipList與剛才List資料型別中講到的zipList實際上基本一致,唯一區別在於Hash儲存entry數量成對增加,所以長度一定為2的整數倍。當然,使用zipList剛才已經說過push和pop時間複雜度為O(n),所以只能在資料量少的情況下才允許使用。而HashTable其實有點類似於Java中的HashTable,HashTTable主要依賴於三個結構:dict、dictht、entry。三個結構的關係可以表示為如下這幅圖:
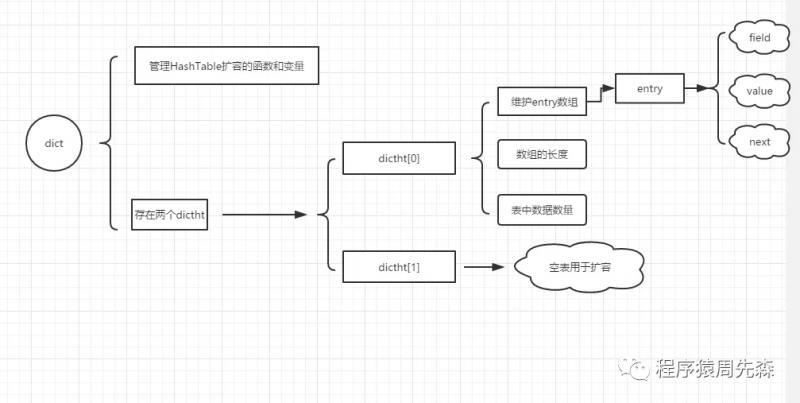
Hash資料型別適用場景:
儲存物件資料。
結合Json描述物件集合。
SortSet資料型別
有序集合是在Set集合的基礎上,保留了Set集合中不能存在重複元素的特性,但是不同的是,SortSet集合中元素是可以排序的,SortSet排序和List排序都可以使用索引下標作為排序依據,所以說SortSet實現了資料有序且鍵值對唯一的集合,SortSet的資料結構有兩種:zipList和skipList + HashTable,zipList都不用多少了,是用於資料量較少的情況,預設排序為元素從小到大。而採用skipList + HashTable的資料結構,skipList會在保證集合有序的情況下優化範圍查詢的時間複雜性,而HashTable剛才已經提到過它可以優化push和pop元素時的時間複雜性。skipList基於有序連結串列,可以建立多層索引,實現以空間複雜度來換取時間複雜度的做法,最終實現時間複雜度為O(logN)的元素查詢過程,當需要push或者pop元素時,則使用HashTable實現時間複雜度僅為O(1).
SortSet資料型別適用場景
積分排行榜:根據積分排序從小到大
獲取某個範圍的資料:考試80-100分的資料
歡迎關注公眾號:程式設計師周先森

相關推薦
細談Redis五大資料型別
文章原創於公眾號:程式猿周先森。本平臺不定時更新,喜歡我的文章,歡迎關注我的微信公眾號。 上一篇文章有提到,Redis中使用最頻繁的有5種資料型別:String、List、Hash、Set、SortSet。上一篇文章只是單純介紹了下這5種資料型別使用到的指令以及常用場景,本篇文章會談談5種資料型別的底層資
Redis 五大資料型別
Redis 資料型別 Redis支援五種資料型別:string(字串),hash(雜湊),list(列表),set(集合)及zset(sorted set:有序集合)。 String(字串) string 是 redis 最基本的型別,你可以理解成與 Memcached
Redis-五大資料型別&設定
Redis的五大資料➢ keys * • 查詢當前庫的所有鍵➢ exists <key> • 判斷某個鍵是否存在➢ type <key> • 檢視鍵的型別➢ del <key> • 刪除某個鍵➢ expire <key
Redis五大資料型別之ZSet(Scores Set)型別-常用命令
命令: zadd 格式: zadd [key值] scores[key] value 示例: zadd people 10 v1 20 v2 30 v3 40 v4 50 v5 60 v6 70 v7 建立一個zset名為people,它的key:10值為
Redis的五大資料型別
Redis的五大資料型別 一個key對應一個value: 1.String 字串 String是redis最基本的型別,一個key對應一個value; String型別是二進位制安全的,意思是redis的string可以包含任何資料: 比如:jpg圖片或
Redis常用命令總結(五大資料型別常用命令)
目錄 1.key關鍵字: Keys *:檢視當前k-v鍵值對快取中的所有key Exists key的名字,判斷某個key是否存在 Move key db -->當前庫就沒有了,被移除了 Expire key秒鐘:為給ke
Redis 的常用五大資料型別
2016-12-21 14:54:20 該系列文章連結NoSQL 資料庫簡介Redis的安裝及及一些雜項基礎知識Redis 的常用五大資料型別(key,string,hash,list,set,zset)Redis 配置檔案介紹Redis 持久化之RDBRedis 持久化之AOFRedis 主從複製Re
4、redis的五大資料型別
Redis的資料結構(五種資料型別) 字串(String) 雜湊(hash) 字串列表(list) 字串集合(set) 有序字串組合(sorted set) key的定義 不要太長(不要超過1024個位元組,降低查詢效率) 不要太短(降低可讀性)
Redis 一、資料結構與物件--五大資料型別的底層結構實現
原文地址:http://m.blog.csdn.net/u011531613/article/details/70193720 redis上手比較簡單,但是它的底層實現原理一直很讓人著迷。具體來說的話,它是怎麼做到如此高的效率的?閱讀R edis設計與實現這本書,可以
二:Redis入門步驟(五大資料型別常用操作)
1. 開啟一個 cmd 視窗 使用cd命令切換目錄到 C:\redis 執行 redis-server.exe redis.windows.conf 2.啟動: $ redis-server 3.檢視是否啟動: $ redis-cli 4.測試速度 redis-b
Redis入門之五大資料型別及常用操作
注:本片博文基本都是從redis官網摘抄整理,感興趣的可以直接去官網檢視 另外,該網站也有比較全的redis命令參考http://redisdoc.com/ 一、String(字串) string是redis最基本的型別,你可以理解成與Memcached
Redis(三)--- Redis的五大資料型別的底層實現
1、簡介 Redis的五大資料型別也稱五大資料物件;前面介紹過6大資料結構,Redis並沒有直接使用這些結構來實現鍵值對資料庫,而是使用這些結構構建了一個物件系統redisObject;這個物件系統包含了五大資料物件,字串物件(string)、列表物件(list)、雜湊物件(hash)、集合(set)物件和
Redis 設計與實現 6:五大資料型別之字串
前文 [Redis 設計與實現 2:Redis 物件](https://www.cnblogs.com/chenchuxin/p/14187921.html) 說到,五大資料型別都會封裝成 `RedisObject`。 ```c typedef struct redisObject { unsigne
Redis 設計與實現 8:五大資料型別之雜湊
雜湊物件的編碼有兩種:`ziplist`、`hashtable`。 ## 編碼一:ziplist `ziplist` 已經是我們的老朋友了,它一出現,那肯定就是為了節省記憶體啦。那麼雜湊物件是怎麼用 `ziplist` 儲存的呢? 每次插入鍵值對的時候,在 `ziplist` 列表末尾,挨著插入 `fiel
Redis常用資料型別和事物以及併發
Redis資料型別 基本型別(String int): 如 set key value 、get key 等 所有命令都是按照 key value keys * 可以將全部資料列出,其中後面的 " * " 表示資料的匹配。 setnx key value 不覆蓋設定,返回0表示失敗(原來這個key已經
Redis總結--redis的資料型別和簡單操作
一、redis的五大資料型別 1、String(字串) 2、Hash(雜湊,類似於java的Map) 3、List(列表) 4、Set(集合) 5、Zset(sorted set 有序集合) 二、常用命令: (一)key 1、exists key : 判斷某個key是否存在 2、move key d
redis的資料型別List,其原生命令和php操作Redis List函式介紹
List型別介紹 List是簡單的字串列表,按照插入順序排序,可以從列表的兩頭新增資料,一個列表最多可以包含2^32-1個元素(超過40億個元素) List原生命令 命令 命令描述 例項 LPUSH key value1 [va
redis 的資料型別
1.string型別 set key value [EX 有效時間秒] [PX 有效時間毫秒] get key 所有人共用資訊 set hot_goods [{id:1,name:’’,price:’’},{},{}…{}] 手機驗證碼 set 15807331234 1354 EX 180
redis常見資料型別操作命令,Java中使用Jedis操作Redis
redis常見資料型別操作命令 可參考地址:Http://redisdoc.com/ Java中使用Jedis操作Redis: https://www.cnblogs.com/liuling/p/2014-4-19-04.html redis鍵(key)
Redis的資料型別詳解
字串型別 雖然叫字串型別,但是裡面也可以由數字。 建立一個字串型別的key 127.0.0.1:6379> set name tom OK 127.0.0.1:6379> get name "tom" 127.0.0.1:6379> type