
網路程式設計之多執行緒——GIL全域性直譯器鎖
網路程式設計之多執行緒——GIL全域性直譯器鎖
一、引子
定義: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.) 結論:在Cpython直譯器中,同一個程序下開啟的多執行緒,同一時刻只能有一個執行緒執行,無法利用多核優勢
首先需要明確的一點是GIL並不是Python的特性,它是在實現Python解析器(CPython)時所引入的一個概念。就好比C++是一套語言(語法)標準,但是可以用不同的編譯器來編譯成可執行程式碼。有名的編譯器例如GCC,INTEL C++,Visual C++等。Python也一樣,同樣一段程式碼可以通過CPython,PyPy,Psyco等不同的Python執行環境來執行。像其中的JPython就沒有GIL。然而因為CPython是大部分環境下預設的Python執行環境。所以在很多人的概念裡CPython就是Python,也就想當然的把GIL歸結為Python語言的缺陷。所以這裡要先明確一點:GIL並不是Python的特性,Python完全可以不依賴於GIL。
二、GIL介紹
GIL本質就是一把互斥鎖,既然是互斥鎖,所有互斥鎖的本質都一樣,都是將併發執行變成序列,以此來控制同一時間內共享資料只能被一個任務所修改,進而保證資料安全。
可以肯定的一點是:保護不同的資料的安全,就應該加不同的鎖。
要想了解GIL,首先確定一點:每次執行python程式,都會產生一個獨立的程序。例如python test.py,python aaa.py,python bbb.py會產生3個不同的python程序
驗證python test.py只會產生一個程序:
#test.py內容 import os,time print(os.getpid()) time.sleep(1000) #開啟終端執行 python3 test.py #在windows下檢視 tasklist |findstr python #在linux下下檢視 ps aux |grep python
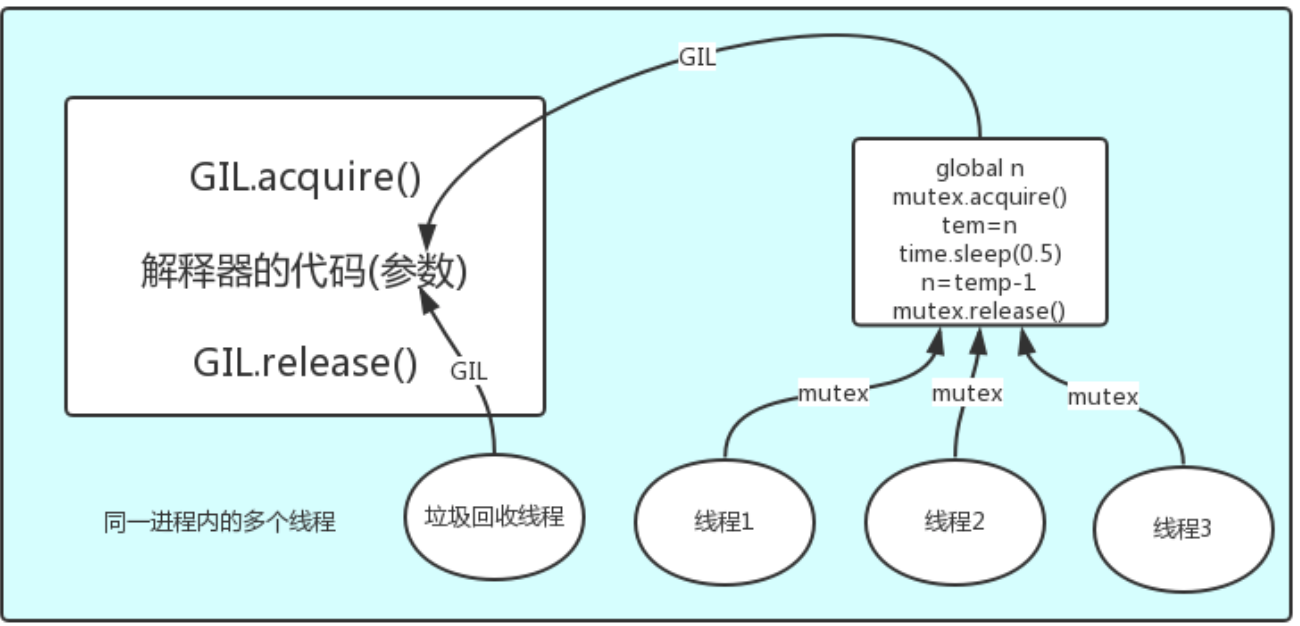
在一個python的程序內,不僅有test.py的主執行緒或者由該主執行緒開啟的其他執行緒,還有直譯器開啟的垃圾回收等直譯器級別的執行緒,總之,所有執行緒都執行在這一個程序內,毫無疑問。
1、所有資料都是共享的,這其中,程式碼作為一種資料也是被所有執行緒共享的(test.py的所有程式碼以及Cpython直譯器的所有程式碼)
例如:test.py定義一個函式work(程式碼內容如下圖),在程序內所有執行緒都能訪問到work的程式碼,於是我們可以開啟三個執行緒然後target都指向該程式碼,能訪問到意味著就是可以執行。
2、所有執行緒的任務,都需要將任務的程式碼當做引數傳給直譯器的程式碼去執行,即所有的執行緒要想執行自己的任務,首先需要解決的是能夠訪問到直譯器的程式碼。綜上:
如果多個執行緒的target=work,那麼執行流程是
多個執行緒先訪問到直譯器的程式碼,即拿到執行許可權,然後將target的程式碼交給直譯器的程式碼去執行
直譯器的程式碼是所有執行緒共享的,所以垃圾回收執行緒也可能訪問到直譯器的程式碼而去執行,這就導致了一個問題:對於同一個資料100,可能執行緒1執行x=100的同時,而垃圾回收執行的是回收100的操作,解決這種問題沒有什麼高明的方法,就是加鎖處理,如下圖的GIL,保證python直譯器同一時間只能執行一個任務的程式碼。
三、GIL與Lock
機智的同學可能會問到這個問題:Python已經有一個GIL來保證同一時間只能有一個執行緒來執行了,為什麼這裡還需要lock?
首先,我們需要達成共識:鎖的目的是為了保護共享的資料,同一時間只能有一個執行緒來修改共享的資料
然後,我們可以得出結論:保護不同的資料就應該加不同的鎖。
最後,問題就很明朗了,GIL 與Lock是兩把鎖,保護的資料不一樣,前者是直譯器級別的(當然保護的就是直譯器級別的資料,比如垃圾回收的資料),後者是保護使用者自己開發的應用程式的資料,很明顯GIL不負責這件事,只能使用者自定義加鎖處理,即Lock,如下圖:
分析:
1、100個執行緒去搶GIL鎖,即搶執行許可權
2、肯定有一個執行緒先搶到GIL(暫且稱為執行緒1),然後開始執行,一旦執行就會拿到lock.acquire()
3、極有可能執行緒1還未執行完畢,就有另外一個執行緒2搶到GIL,然後開始執行,但執行緒2發現互斥鎖lock還未被執行緒1釋放,於是阻塞,被迫交出執行許可權,即釋放GIL
4、直到執行緒1重新搶到GIL,開始從上次暫停的位置繼續執行,直到正常釋放互斥鎖lock,然後其他的執行緒再重複2 3 4的過程程式碼示範:
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
print(n) #結果肯定為0,由原來的併發執行變成序列,犧牲了執行效率保證了資料安全,不加鎖則結果可能為99四、GIL與多執行緒
有了GIL的存在,同一時刻同一程序中只有一個執行緒被執行。
聽到這裡,有的同學立馬質問:程序可以利用多核,但是開銷大,而python的多執行緒開銷小,但卻無法利用多核優勢,也就是說python沒用了,php才是最牛逼的語言?
彆著急,還沒講完呢。
要解決這個問題,我們需要在幾個點上達成一致:
1、cpu到底是用來做計算的,還是用來做I/O的?
2、多cpu,意味著可以有多個核並行完成計算,所以多核提升的是計算效能
3、每個cpu一旦遇到I/O阻塞,仍然需要等待,所以多核對I/O操作沒什麼用處一個工人相當於cpu,此時計算相當於工人在幹活,I/O阻塞相當於為工人幹活提供所需原材料的過程,工人幹活的過程中如果沒有原材料了,則工人幹活的過程需要停止,直到等待原材料的到來。
如果你的工廠乾的大多數任務都要有準備原材料的過程(I/O密集型),那麼你有再多的工人,意義也不大,還不如一個人,在等材料的過程中讓工人去幹別的活。
反過來講,如果你的工廠原材料都齊全,那當然是工人越多,效率越高
結論:
1、對計算來說,cpu越多越好,但是對於I/O來說,再多的cpu也沒用
2、當然對執行一個程式來說,隨著cpu的增多執行效率肯定會有所提高(不管提高幅度多大,總會有所提高),這是因為一個程式基本上不會是純計算或者純I/O,所以我們只能相對的去看一個程式到底是計算密集型還是I/O密集型,從而進一步分析python的多執行緒到底有無用武之地假設我們有四個任務需要處理,處理方式肯定是要玩出併發的效果,解決方案可以是:
方案一:開啟四個程序
方案二:一個程序下,開啟四個執行緒單核情況下,分析結果:
1、如果四個任務是計算密集型,多核意味著平行計算,在python中一個程序中同一時刻只有一個執行緒執行用不上多核,方案一勝
2、如果四個任務是I/O密集型,再多的核也解決不了I/O問題,方案二勝結論:
現在的計算機基本上都是多核,python對於計算密集型的任務開多執行緒的效率並不能帶來多大效能上的提升,甚至不如序列(沒有大量切換),但是,對於IO密集型的任務效率還是有顯著提升的。五、多執行緒效能測試
如果併發的多個任務是計算密集型:多程序效率高
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本機為4核
start=time.time()
for i in range(4):
p=Process(target=work) #耗時5s多
p=Thread(target=work) #耗時18s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))如果併發的多個任務是I/O密集型:多執行緒效率高
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
print('===>')
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本機為4核
start=time.time()
for i in range(400):
# p=Process(target=work) #耗時12s多,大部分時間耗費在建立程序上
p=Thread(target=work) #耗時2s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))應用:
1、多執行緒用於IO密集型,如socket,爬蟲,web
2、多程序用於計算密集型,如金融分析