
HIVE學習(六) —— Hive 例項學習
案例說明 (案例資料下載)
現有如此三份資料:
1、users.dat 資料格式為: 2::M::56::16::70072,
共有6040條資料
對應欄位為:UserID BigInt, Gender String, Age Int, Occupation String, Zipcode String
對應欄位中文解釋:使用者id,性別,年齡,職業,郵政編碼
2、movies.dat 資料格式為: 2::Jumanji (1995)::Adventure|Children's|Fantasy,
共有3883條資料
對應欄位為:MovieID BigInt, Title String, Genres String
對應欄位中文解釋:電影ID,電影名字,電影型別
3、ratings.dat 資料格式為: 1::1193::5::978300760,
共有1000209條資料
對應欄位為:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
對應欄位中文解釋:使用者ID,電影ID,評分,評分時間戳
題目要求
資料要求:
(1)寫shell指令碼清洗資料。(hive不支援解析多位元組的分隔符,也就是說hive只能解析':', 不支援解析'::',所以用普通方式建表來使用是行不通的,要求對資料做一次簡單清洗)
(2)使用Hive能解析的方式進行
Hive要求:
(1)正確建表,匯入資料(三張表,三份資料),並驗證是否正確
(2)求被評分次數最多的10部電影,並給出評分次數(電影名,評分次數)
(3)分別求男性,女性當中評分最高的10部電影(性別,電影名,影評分)
(4)求movieid = 2116這部電影各年齡段(因為年齡就只有7個,就按這個7個分就好了)的平均影評(年齡段,影評分)
(5)求最喜歡看電影(影評次數最多)的那位女性評最高分的10部電影的平均影評分(觀影者,電影名,影評分)
(6)求好片(評分>=4.0)最多的那個年份的最好看的10部電影
(7)求1997年上映的電影中,評分最高的10部Comedy類電影
(8)該影評庫中各種型別電影中評價最高的5部電影(型別,電影名,平均影評分)
(9)各年評分最高的電影型別(年份,型別,影評分)
(10)每個地區最高評分的電影名,把結果存入HDFS(地區,電影名,影評分)
解析
之前已經使用MapReduce程式將3張表格進行合併,所以只需要將合併之後的表格匯入對應的表中進行查詢即可。
1、正確建表,匯入資料(三張表,三份資料),並驗證是否正確
(1)分析需求
需要建立一個數據庫movie,在movie資料庫中建立3張表,t_user,t_movie,t_rating
t_user:userid bigint,sex string,age int,occupation string,zipcode string
t_movie:movieid bigint,moviename string,movietype string
t_rating:userid bigint,movieid bigint,rate double,times string
原始資料是以::進行切分的,所以需要使用能解析多位元組分隔符的Serde即可
使用RegexSerde
需要兩個引數:
input.regex = "(.*)::(.*)::(.*)"
output.format.string = "%1$s %2$s %3$s"
(2)建立資料庫
drop database if exists movie; create database if not exists movie; use movie;
(3)建立t_user表

create table t_user(
userid bigint,
sex string,
age int,
occupation string,
zipcode string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s %5$s')
stored as textfile;
(4)建立t_movie表
use movie;
create table t_movie(
movieid bigint,
moviename string,
movietype string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s')
stored as textfile;
(5)建立t_rating表
use movie;
create table t_rating(
userid bigint,
movieid bigint,
rate double,
times string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s')
stored as textfile;
(6)匯入資料
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/users.dat" into table t_user; No rows affected (0.928 seconds) 0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/movies.dat" into table t_movie; No rows affected (0.538 seconds) 0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/ratings.dat" into table t_rating; No rows affected (0.963 seconds) 0: jdbc:hive2://hadoop3:10000>
(7)驗證
select t.* from t_user t;
select t.* from t_movie t;
select t.* from t_rating t;
2、求被評分次數最多的10部電影,並給出評分次數(電影名,評分次數)
(1)思路分析:
1、需求欄位:電影名 t_movie.moviename
評分次數 t_rating.rate count()
2、核心SQL:按照電影名進行分組統計,求出每部電影的評分次數並按照評分次數降序排序
(2)完整SQL:
create table answer2 as select a.moviename as moviename,count(a.moviename) as total from t_movie a join t_rating b on a.movieid=b.movieid group by a.moviename order by total desc limit 10;
select * from answer2;

3、分別求男性,女性當中評分最高的10部電影(性別,電影名,影評分)
(1)分析思路:
1、需求欄位:性別 t_user.sex
電影名 t_movie.moviename
影評分 t_rating.rate
2、核心SQL:三表聯合查詢,按照性別過濾條件,電影名作為分組條件,影評分作為排序條件進行查詢
(2)完整SQL:
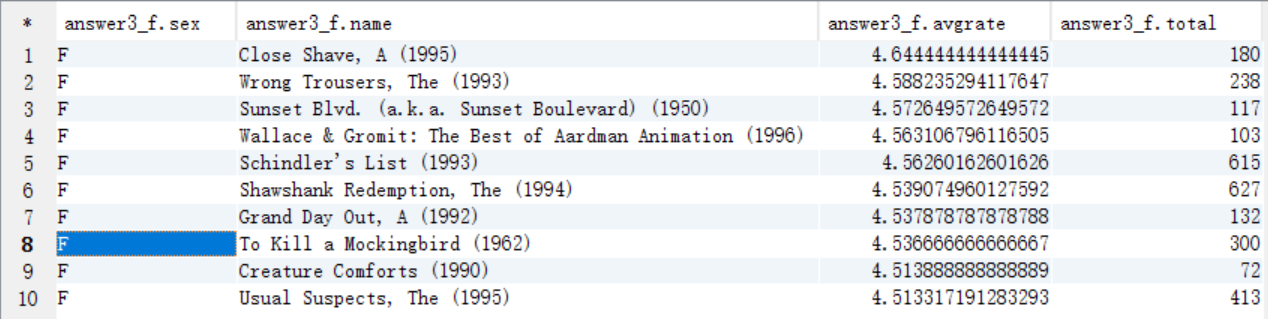
女性當中評分最高的10部電影(性別,電影名,影評分)評論次數大於等於50次
create table answer3_F as select "F" as sex, c.moviename as name, avg(a.rate) as avgrate, count(c.moviename) as total from t_rating a join t_user b on a.userid=b.userid join t_movie c on a.movieid=c.movieid where b.sex="F" group by c.moviename having total >= 50 order by avgrate desc limit 10;
select * from answer3_F;
男性當中評分最高的10部電影(性別,電影名,影評分)評論次數大於等於50次
create table answer3_M as select "M" as sex, c.moviename as name, avg(a.rate) as avgrate, count(c.moviename) as total from t_rating a join t_user b on a.userid=b.userid join t_movie c on a.movieid=c.movieid where b.sex="M" group by c.moviename having total >= 50 order by avgrate desc limit 10;
select * from answer3_M;

4、求movieid = 2116這部電影各年齡段(因為年齡就只有7個,就按這個7個分就好了)的平均影評(年齡段,影評分)
(1)分析思路:
1、需求欄位:年齡段 t_user.age
影評分 t_rating.rate
2、核心SQL:t_user和t_rating表進行聯合查詢,用movieid=2116作為過濾條件,用年齡段作為分組條件
(2)完整SQL:
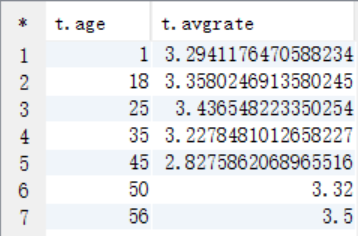
create table answer4 as select a.age as age, avg(b.rate) as avgrate from t_user a join t_rating b on a.userid=b.userid where b.movieid=2116 group by a.age;
select * from answer4;
5、求最喜歡看電影(影評次數最多)的那位女性評最高分的10部電影的平均影評分(觀影者,電影名,影評分)
(1)分析思路:
1、需求欄位:觀影者 t_rating.userid
電影名 t_movie.moviename
影評分 t_rating.rate
2、核心SQL:
A. 需要先求出最喜歡看電影的那位女性
需要查詢的欄位:性別:t_user.sex
觀影次數:count(t_rating.userid)
B. 根據A中求出的女性userid作為where過濾條件,以看過的電影的影評分rate作為排序條件進行排序,求出評分最高的10部電影
需要查詢的欄位:電影的ID:t_rating.movieid
C. 求出B中10部電影的平均影評分
需要查詢的欄位:電影的ID:answer5_B.movieid
影評分:t_rating.rate
(2)完整SQL:
A. 需要先求出最喜歡看電影的那位女性
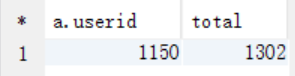
select a.userid, count(a.userid) as total from t_rating a join t_user b on a.userid = b.userid where b.sex="F" group by a.userid order by total desc limit 1;
B. 根據A中求出的女性userid作為where過濾條件,以看過的電影的影評分rate作為排序條件進行排序,求出評分最高的10部電影
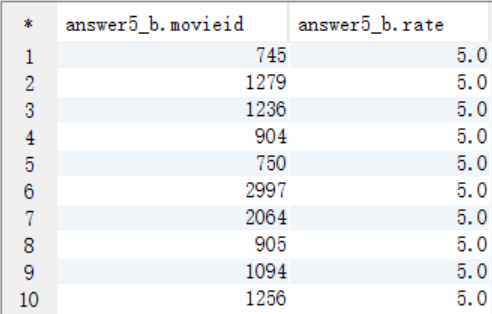
create table answer5_B as select a.movieid as movieid, a.rate as rate from t_rating a where a.userid=1150 order by rate desc limit 10;
select * from answer5_B;
C. 求出B中10部電影的平均影評分
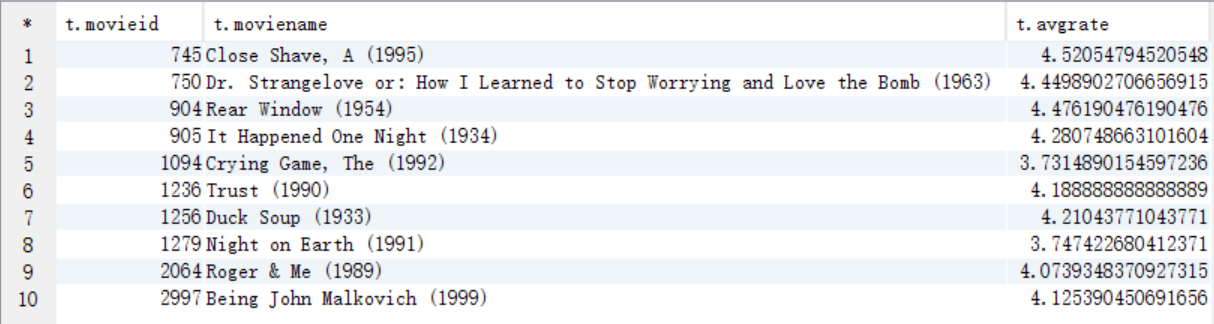
create table answer5_C as select b.movieid as movieid, c.moviename as moviename, avg(b.rate) as avgrate from answer5_B a join t_rating b on a.movieid=b.movieid join t_movie c on b.movieid=c.movieid group by b.movieid,c.moviename;
select * from answer5_C;
6、求好片(評分>=4.0)最多的那個年份的最好看的10部電影
(1)分析思路:
1、需求欄位:電影id t_rating.movieid
電影名 t_movie.moviename(包含年份)
影評分 t_rating.rate
上映年份 xxx.years
2、核心SQL:
A. 需要將t_rating和t_movie表進行聯合查詢,將電影名當中的上映年份截取出來,儲存到臨時表answer6_A中
需要查詢的欄位:電影id t_rating.movieid
電影名 t_movie.moviename(包含年份)
影評分 t_rating.rate
B. 從answer6_A按照年份進行分組條件,按照評分>=4.0作為where過濾條件,按照count(years)作為排序條件進行查詢
需要查詢的欄位:電影的ID:answer6_A.years
C. 從answer6_A按照years=1998作為where過濾條件,按照評分作為排序條件進行查詢
需要查詢的欄位:電影的ID:answer6_A.moviename
影評分:answer6_A.avgrate
(2)完整SQL:
A. 需要將t_rating和t_movie表進行聯合查詢,將電影名當中的上映年份截取出來
create table answer6_A as select a.movieid as movieid, a.moviename as moviename, substr(a.moviename,-5,4) as years, avg(b.rate) as avgrate from t_movie a join t_rating b on a.movieid=b.movieid group by a.movieid, a.moviename;
select * from answer6_A;
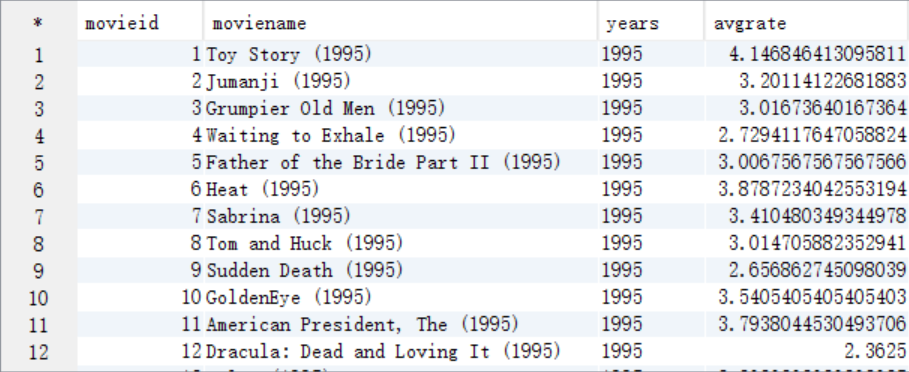
B. 從answer6_A按照年份進行分組條件,按照評分>=4.0作為where過濾條件,按照count(years)作為排序條件進行查詢
select years, count(years) as total from answer6_A a where avgrate >= 4.0 group by years order by total desc limit 1;
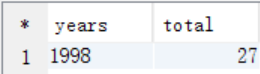
C. 從answer6_A按照years=1998作為where過濾條件,按照評分作為排序條件進行查詢
create table answer6_C as select a.moviename as name, a.avgrate as rate from answer6_A a where a.years=1998 order by rate desc limit 10;
select * from answer6_C;
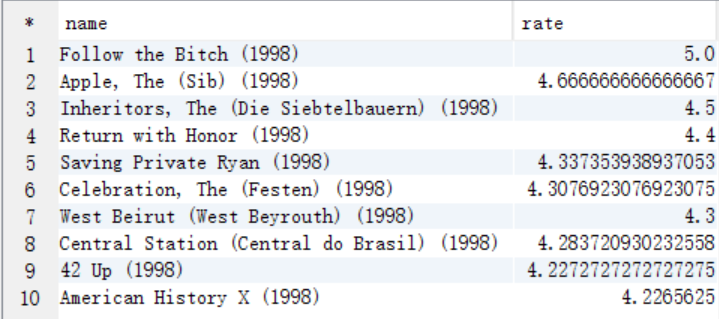
7、求1997年上映的電影中,評分最高的10部Comedy類電影
(1)分析思路:
1、需求欄位:電影id t_rating.movieid
電影名 t_movie.moviename(包含年份)
影評分 t_rating.rate
上映年份 xxx.years(最終查詢結果可不顯示)
電影型別 xxx.type(最終查詢結果可不顯示)
2、核心SQL:
A. 需要電影型別,所有可以將第六步中求出answer6_A表和t_movie表進行聯合查詢
需要查詢的欄位:電影id answer6_A.movieid
電影名 answer6_A.moviename
影評分 answer6_A.rate
電影型別 t_movie.movietype
上映年份 answer6_A.years
B. 從answer7_A按照電影型別中是否包含Comedy和按上映年份作為where過濾條件,按照評分作為排序條件進行查詢,將結果儲存到answer7_B中
需要查詢的欄位:電影的ID:answer7_A.id
電影的名稱:answer7_A.name
電影的評分:answer7_A.rate
(2)完整SQL:
A. 需要電影型別,所有可以將第六步中求出answer6_A表和t_movie表進行聯合查詢
create table answer7_A as select b.movieid as id, b.moviename as name, b.years as years, b.avgrate as rate, a.movietype as type from t_movie a join answer6_A b on a.movieid=b.movieid;
select t.* from answer7_A t;
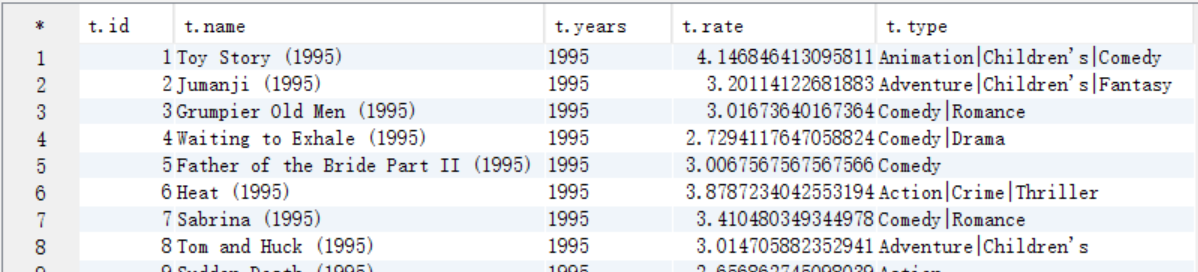
B. 從answer7_A按照電影型別中是否包含Comedy和按照評分>=4.0作為where過濾條件,按照評分作為排序條件進行查詢,將結果儲存到answer7_B中
create table answer7_B as select t.id as id, t.name as name, t.rate as rate from answer7_A t where t.years=1997 and instr(lcase(t.type),'comedy') >0 order by rate desc limit 10;
select * from answer7_B;
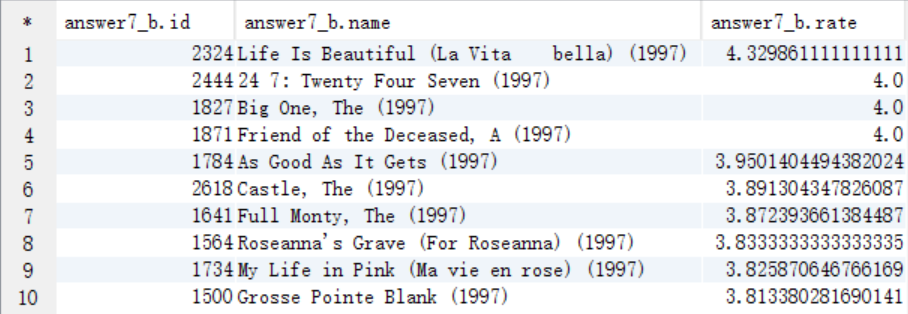
8、該影評庫中各種型別電影中評價最高的5部電影(型別,電影名,平均影評分)
(1)分析思路:
1、需求欄位:電影id movieid
電影名 moviename
影評分 rate(排序條件)
電影型別 type(分組條件)
2、核心SQL:
A. 需要電影型別,所有需要將answer7_A中的type欄位進行裂變,將結果儲存到answer8_A中
需要查詢的欄位:電影id answer7_A.id
電影名 answer7_A.name(包含年份)
上映年份 answer7_A.years
影評分 answer7_A.rate
電影型別 answer7_A.movietype
B. 求TopN,按照type分組,需要新增一列來記錄每組的順序,將結果儲存到answer8_B中
row_number() :用來生成 num欄位的值
distribute by movietype :按照type進行分組
sort by avgrate desc :每組資料按照rate排降序
num:新列, 值就是每一條記錄在每一組中按照排序規則計算出來的排序值
C. 從answer8_B中取出num列序號<=5的
(2)完整SQL:
A. 需要電影型別,所有需要將answer7_A中的type欄位進行裂變,將結果儲存到answer8_A中
create table answer8_A as select a.id as id, a.name as name, a.years as years, a.rate as rate, tv.type as type from answer7_A a lateral view explode(split(a.type,"\\|")) tv as type;
select * from answer8_A;
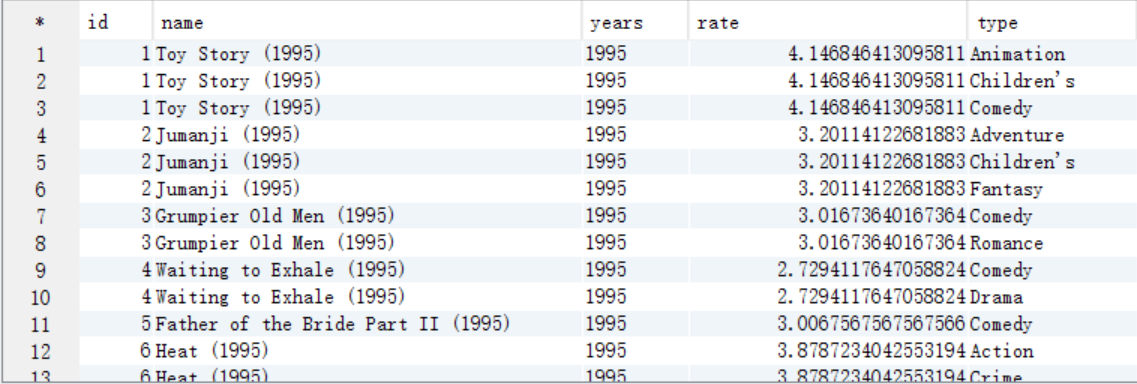
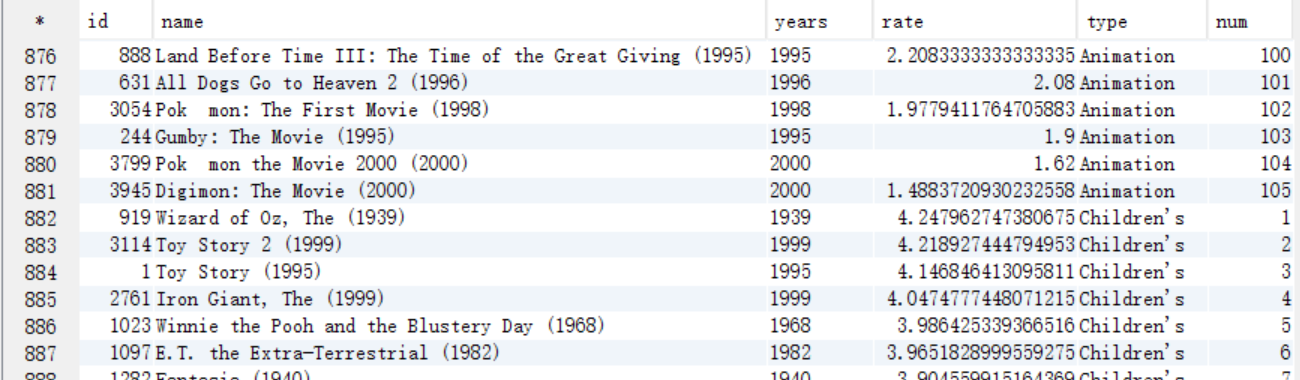
B. 求TopN,按照type分組,需要新增一列來記錄每組的順序,將結果儲存到answer8_B中
create table answer8_B as select id,name,years,rate,type,row_number() over(distribute by type sort by rate desc ) as num from answer8_A;
select * from answer8_B;
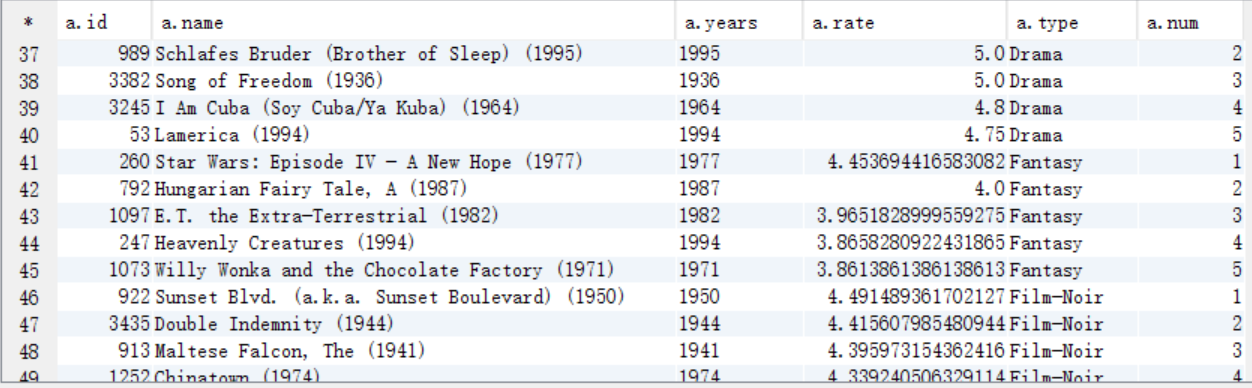
C. 從answer8_B中取出num列序號<=5的
select a.* from answer8_B a where a.num <= 5;
9、各年評分最高的電影型別(年份,型別,影評分)
(1)分析思路:
1、需求欄位:電影id movieid
電影名 moviename
影評分 rate(排序條件)
電影型別 type(分組條件)
上映年份 years(分組條件)
2、核心SQL:
A. 需要按照電影型別和上映年份進行分組,按照影評分進行排序,將結果儲存到answer9_A中
需要查詢的欄位:
上映年份 answer7_A.years
影評分 answer7_A.rate
電影型別 answer7_A.movietype
B. 求TopN,按照years分組,需要新增一列來記錄每組的順序,將結果儲存到answer9_B中
C. 按照num=1作為where過濾條件取出結果資料
(2)完整SQL:
A. 需要按照電影型別和上映年份進行分組,按照影評分進行排序,將結果儲存到answer9_A中
create table answer9_A as select a.years as years, a.type as type, avg(a.rate) as rate from answer8_A a group by a.years,a.type order by rate desc;
select * from answer9_A;
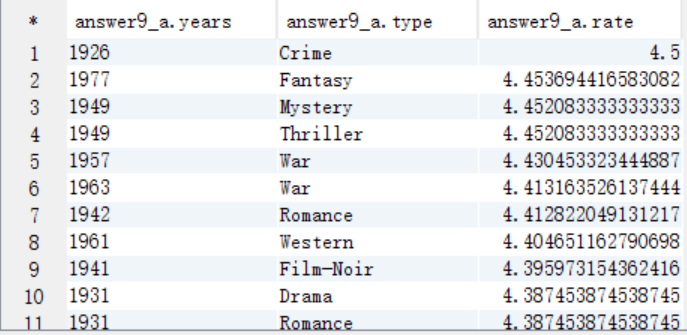
B. 求TopN,按照years分組,需要新增一列來記錄每組的順序,將結果儲存到answer9_B中
create table answer9_B as select years,type,rate,row_number() over (distribute by years sort by rate) as num from answer9_A;
select * from answer9_B;
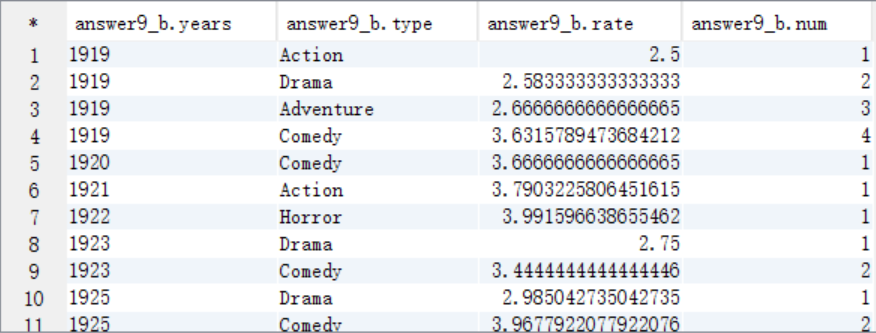
C. 按照num=1作為where過濾條件取出結果資料
select * from answer9_B where num=1;
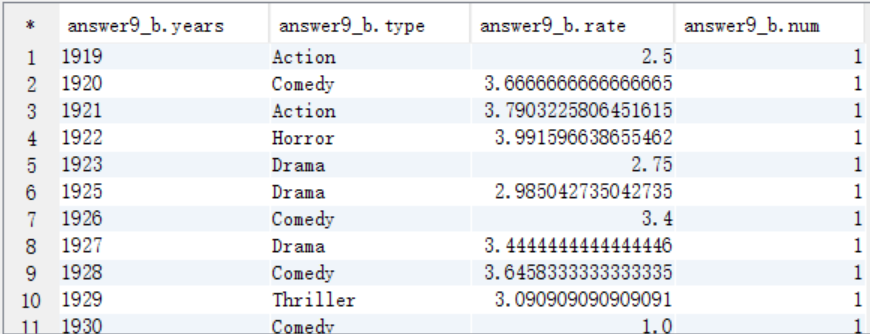
10、每個地區最高評分的電影名,把結果存入HDFS(地區,電影名,影評分)
(1)分析思路:
1、需求欄位:電影id t_movie.movieid
電影名 t_movie.moviename
影評分 t_rating.rate(排序條件)
地區 t_user.zipcode(分組條件)
2、核心SQL:
A. 需要把三張表進行聯合查詢,取出電影id、電影名稱、影評分、地區,將結果儲存到answer10_A表中
需要查詢的欄位:電影id t_movie.movieid
電影名 t_movie.moviename
影評分 t_rating.rate(排序條件)
地區 t_user.zipcode(分組條件)
B. 求TopN,按照地區分組,按照平均排序,新增一列num用來記錄地區排名,將結果儲存到answer10_B表中
C. 按照num=1作為where過濾條件取出結果資料
(2)完整SQL:
A. 需要把三張表進行聯合查詢,取出電影id、電影名稱、影評分、地區,將結果儲存到answer10_A表中
create table answer10_A as select c.movieid, c.moviename, avg(b.rate) as avgrate, a.zipcode from t_user a join t_rating b on a.userid=b.userid join t_movie c on b.movieid=c.movieid group by a.zipcode,c.movieid, c.moviename;
select t.* from answer10_A t;

B. 求TopN,按照地區分組,按照平均排序,新增一列num用來記錄地區排名,將結果儲存到answer10_B表中
create table answer10_B as select movieid,moviename,avgrate,zipcode, row_number() over (distribute by zipcode sort by avgrate) as num from answer10_A;
select t.* from answer10_B t;
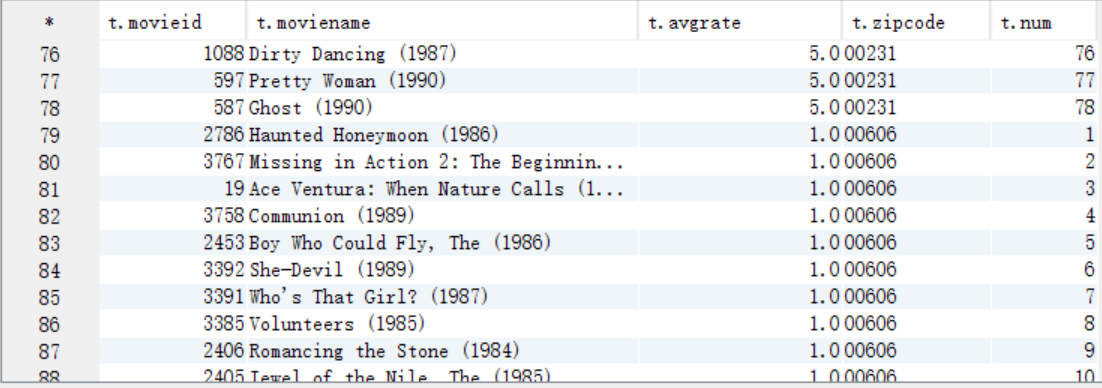
C. 按照num=1作為where過濾條件取出結果資料並儲存到HDFS上
insert overwrite directory "/movie/answer10/" select t.* from answer10_B t where t.num=1;

相關推薦
HIVE學習(六) —— Hive 例項學習
案例說明 (案例資料下載) 現有如此三份資料: 1、users.dat 資料格式為: 2::M::56
Hive 系列(六)—— Hive 檢視和索引
一、檢視 1.1 簡介 Hive 中的檢視和 RDBMS 中檢視的概念一致,都是一組資料的邏輯表示,本質上就是一條 SELECT 語句的結果集。檢視是純粹的邏輯物件,沒有關聯的儲存 (Hive 3.0.0 引入的物化檢視除外),當查詢引用檢視時,Hive 可以將檢視的定義與查詢結合起來,例如將查詢中的過濾器推
Hive學習之路 (六)Hive的DDL操作
存儲位置 BE 輔助 cond 允許 param 就是 文件夾 selected 庫操作 1、創建庫 語法結構 CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_
Hive學習之路 (六)Hive SQL之數據類型和存儲格式
OS big api 而且 好的 存儲 array 文本文件 字符串 一、數據類型 1、基本數據類型 Hive 支持關系型數據中大多數基本數據類型 類型描述示例 boolean true/false TRUE tinyint 1字
flume學習(六):使用hive來分析flume收集的日誌資料
前面已經講過如何將log4j的日誌輸出到指定的hdfs目錄,我們前面的指定目錄為/flume/events。 如果想用hive來分析採集來的日誌,我們可以將/flume/events下面的日誌資料都load到hive中的表當中去。 如果瞭解hive的load data原理
Hive學習(六)資料倉庫的表設計
資料倉庫的起源可以追溯到計算機與資訊系統發展的初期。它是資訊科技長期複雜演化的產物,並且直到今天這種演化仍然在繼續進行著。而資料倉庫容易讓人糊塗的地方在於它是一種體系結構,而不是一種技術。這點使得許多技術人員和風投都感到沮喪,因為他們希望的是打好成包的專業技術,而非具有哲學意
hadoop生態系統學習之路(六)hive的簡單使用
一、hive的基本概念與原理 Hive是基於Hadoop之上的資料倉庫,可以儲存、查詢和分析儲存在 Hadoop 中的大規模資料。Hive 定義了簡單的類 SQL 查詢語言,稱為 HQL,它允許熟悉 SQL 的使用者查詢資料,允許熟悉 MapReduce 開發
大數據學習(8)Hive基礎
fall nat value onf change expected role blog tab 什麽是Hive Hive是一個基於HDFS的查詢引擎。我們日常中的需求如果都自己去寫MapReduce來實現的話會很費勁的,Hive把日常用到的MapReduce功能,比如排序
Hive 官方手冊學習(一) Hive命令列
一、shell視窗下Hive命令列選項 hive [-hiveconf x=y]* [<-i filename>]* [<-f filename>|<-e query-string>] [-S] [-v] 注意:順序
Hive學習 (三)Hive的連線三種連線方式
目錄一、CLI連線二、HiveServer2/beeline 1、修改 hadoop 叢集的 hdfs-site.xml 配置檔案 2、修改 hadoop 叢集的 core-site.xml 配置檔案三、Web UI正文:一、CLI連線進入到 bin 目錄下,直接
Hadoop學習(三)Hive安裝
下載hive包上傳到linux主機上並解壓 這裡使用 apache-hive-2.1.1-bin.tar.gz 安裝配置 MySQL CentOS7安裝mysql提示 :No package mysql-server available. 輸入下面兩部
java學習(六)面向對象 final關鍵字
hello int java學習 xtend 最終 .sh 方法 div ext 1.被fnial修飾的方法不能被重寫,常見的為修飾類,方法,變量 /* final可以修飾類,方法,變量 特點: final可以修飾類,該類不能被繼
線程學習--(六)單例和多線程、ThreadLocal
pen single cal final ride args ash public 線程 一、ThreadLocal 使用wait/notify方式實現的線程安全,性能將受到很大影響。解決方案是用空間換時間,不用鎖也能實現線程安全。 來看一個小例子,在線程內的set、get
Linux 網卡驅動學習(六)(應用層、tcp 層、ip 層、設備層和驅動層作用解析)
local acc 每次 letter auto sizeof style article inode 本文將介紹網絡連接建立的過程、收發包流程,以及當中應用層、tcp層、ip層、設備層和驅動層各層發揮的作用。 1、應用層 對於使用socket進行網絡連接的serv
RabbitMQ學習(六):遠程結果調用
cells actor ble 隨機 get getenv all 求和 int 場景:我們需要在傳輸消息時得到結果 客服端在發送請求時會發送回調隊列,服務端處理事情完成後會將結果返回到回調隊列中,在增加關聯標誌關聯每個請求和服務返回 客戶端代碼: public
Django學習(六)---博客文章頁面的超鏈接設置
_id 三個參數 name app dex pla django (六) pat Django中的超鏈接 超鏈接的目標地址 href後面是目標地址 template中可以用 {% url ‘app_name : url_name’ param %} app_name:
別樣JAVA學習(六)繼承下(2.3)異常下
關閉 exit dsm 練習 方便 pub xtend 運行 script 1、RuntimeException Exception中有一個特殊的子類異常RuntimeException執行時異常。 假設在函數內容拋出該異常,函數上能夠不用聲明。編譯一樣
python學習(六)---文件操作
not game seek read 終端設備 fas uic med ear 文件操作文件操作流程 1、打開文件,得到文件句柄並賦值給一個變量 2、通過句柄對文件進行操作 3、關閉文件現有文件如下: Somehow, it seems the love I knew
linux學習(六)絕對路徑、相對路徑、cd、mkdir、rmdir、rm
director shell script local mkdir -p create deb blog 目錄 一、絕對路徑 就是從根開始的,如:/root、/usr/local。 二、相對路徑 相對於當前路徑的,比如我們在當前路徑下建立了一個a.txt。 [root@i
webpack學習(六)打包壓縮js和css
網頁 com 換行符 最小化 合並 標準 註意 resolve hash 打包壓縮js與css 由於webpack本身集成了UglifyJS插件(webpack.optimize.UglifyJsPlugin)來完成對JS與CSS的壓縮混淆,無需引用額外的插件, 其命令we