
夯實Java基礎系列4:一文了解final關鍵字的特性、使用方法,以及實現原理
目錄
- final使用
- final變數
- final修飾基本資料型別變數和引用
- final類
- final關鍵字的知識點
- final關鍵字的最佳實踐
- final的用法
- 關於空白final
- final記憶體分配
- 使用final修飾方法會提高速度和效率嗎
- 使用final修飾變數會讓變數的值不能被改變嗎;
- 如何保證陣列內部不被修改
- final方法的三條規則
- final 和 jvm的關係
- 寫 final 域的重排序規則
- 讀 final 域的重排序規則
- 如果 final 域是引用型別
- 參考文章
- 微信公眾號
- Java技術江湖
- 個人公眾號:黃小斜
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫裡檢視
https://github.com/h2pl/Java-Tutorial
喜歡的話麻煩點下Star哈
文章首發於我的個人部落格:
www.how2playlife.com
本文是微信公眾號【Java技術江湖】的《夯實Java基礎系列博文》其中一篇,本文部分內容來源於網路,為了把本文主題講得清晰透徹,也整合了很多我認為不錯的技術部落格內容,引用其中了一些比較好的部落格文章,如有侵權,請聯絡作者。
該系列博文會告訴你如何從入門到進階,一步步地學習Java基礎知識,並上手進行實戰,接著瞭解每個Java知識點背後的實現原理,更完整地瞭解整個Java技術體系,形成自己的知識框架。為了更好地總結和檢驗你的學習成果,本系列文章也會提供每個知識點對應的面試題以及參考答案。
如果對本系列文章有什麼建議,或者是有什麼疑問的話,也可以關注公眾號【Java技術江湖】聯絡作者,歡迎你參與本系列博文的創作和修訂。
final關鍵字在java中使用非常廣泛,可以申明成員變數、方法、類、本地變數。一旦將引用宣告為final,將無法再改變這個引用。final關鍵字還能保證記憶體同步,本部落格將會從final關鍵字的特性到從java記憶體層面保證同步講解。這個內容在面試中也有可能會出現。
final使用
final變數
final變數有成員變數或者是本地變數(方法內的區域性變數),在類成員中final經常和static一起使用,作為類常量使用。其中類常量必須在宣告時初始化,final成員常量可以在建構函式初始化。
public class Main {
public static final int i; //報錯,必須初始化 因為常量在常量池中就存在了,呼叫時不需要類的初始化,所以必須在宣告時初始化
public static final int j;
Main() {
i = 2;
j = 3;
}
}
就如上所說的,對於類常量,JVM會快取在常量池中,在讀取該變數時不會載入這個類。
public class Main {
public static final int i = 2;
Main() {
System.out.println("呼叫建構函式"); // 該方法不會呼叫
}
public static void main(String[] args) {
System.out.println(Main.i);
}
}
final修飾基本資料型別變數和引用
@Test
public void final修飾基本型別變數和引用() {
final int a = 1;
final int[] b = {1};
final int[] c = {1};
// b = c;報錯
b[0] = 1;
final String aa = "a";
final Fi f = new Fi();
//aa = "b";報錯
// f = null;//報錯
f.a = 1;
}final方法表示該方法不能被子類的方法重寫,將方法宣告為final,在編譯的時候就已經靜態綁定了,不需要在執行時動態繫結。final方法呼叫時使用的是invokespecial指令。
class PersonalLoan{
public final String getName(){
return"personal loan”;
}
}
class CheapPersonalLoan extends PersonalLoan{
@Override
public final String getName(){
return"cheap personal loan";//編譯錯誤,無法被過載
}
public String test() {
return getName(); //可以呼叫,因為是public方法
}
}
final類
final類不能被繼承,final類中的方法預設也會是final型別的,java中的String類和Integer類都是final型別的。
class Si{
//一般情況下final修飾的變數一定要被初始化。
//只有下面這種情況例外,要求該變數必須在構造方法中被初始化。
//並且不能有空引數的構造方法。
//這樣就可以讓每個例項都有一個不同的變數,並且這個變數在每個例項中只會被初始化一次
//於是這個變數在單個例項裡就是常量了。
final int s ;
Si(int s) {
this.s = s;
}
}
class Bi {
final int a = 1;
final void go() {
//final修飾方法無法被繼承
}
}
class Ci extends Bi {
final int a = 1;
// void go() {
// //final修飾方法無法被繼承
// }
}
final char[]a = {'a'};
final int[]b = {1};final class PersonalLoan{}
class CheapPersonalLoan extends PersonalLoan { //編譯錯誤,無法被繼承
}
@Test
public void final修飾類() {
//引用沒有被final修飾,所以是可變的。
//final只修飾了Fi型別,即Fi例項化的物件在堆中記憶體地址是不可變的。
//雖然記憶體地址不可變,但是可以對內部的資料做改變。
Fi f = new Fi();
f.a = 1;
System.out.println(f);
f.a = 2;
System.out.println(f);
//改變例項中的值並不改變記憶體地址。
Fi ff = f;
//讓引用指向新的Fi物件,原來的f物件由新的引用ff持有。
//引用的指向改變也不會改變原來物件的地址
f = new Fi();
System.out.println(f);
System.out.println(ff);
}final關鍵字的知識點
- final成員變數必須在宣告的時候初始化或者在構造器中初始化,否則就會報編譯錯誤。final變數一旦被初始化後不能再次賦值。
- 本地變數必須在宣告時賦值。 因為沒有初始化的過程
- 在匿名類中所有變數都必須是final變數。
- final方法不能被重寫, final類不能被繼承
- 介面中宣告的所有變數本身是final的。類似於匿名類
- final和abstract這兩個關鍵字是反相關的,final類就不可能是abstract的。
- final方法在編譯階段繫結,稱為靜態繫結(static binding)。
- 將類、方法、變數宣告為final能夠提高效能,這樣JVM就有機會進行估計,然後優化。
final方法的好處:
- 提高了效能,JVM在常量池中會快取final變數
- final變數在多執行緒中併發安全,無需額外的同步開銷
- final方法是靜態編譯的,提高了呼叫速度
- final類建立的物件是隻可讀的,在多執行緒可以安全共享
final關鍵字的最佳實踐
final的用法
1、final 對於常量來說,意味著值不能改變,例如 final int i=100。這個i的值永遠都是100。
但是對於變數來說又不一樣,只是標識這個引用不可被改變,例如 final File f=new File("c:\test.txt");
那麼這個f一定是不能被改變的,如果f本身有方法修改其中的成員變數,例如是否可讀,是允許修改的。有個形象的比喻:一個女子定義了一個final的老公,這個老公的職業和收入都是允許改變的,只是這個女人不會換老公而已。
關於空白final
final修飾的變數有三種:靜態變數、例項變數和區域性變數,分別表示三種類型的常量。
另外,final變數定義的時候,可以先宣告,而不給初值,這中變數也稱為final空白,無論什麼情況,編譯器都確保空白final在使用之前必須被初始化。
但是,final空白在final關鍵字final的使用上提供了更大的靈活性,為此,一個類中的final資料成員就可以實現依物件而有所不同,卻有保持其恆定不變的特徵。
public class FinalTest {
final int p;
final int q=3;
FinalTest(){
p=1;
}
FinalTest(int i){
p=i;//可以賦值,相當於直接定義p
q=i;//不能為一個final變數賦值
}
} final記憶體分配
剛提到了內嵌機制,現在詳細展開。
要知道呼叫一個函式除了函式本身的執行時間之外,還需要額外的時間去尋找這個函式(類內部有一個函式簽名和函式地址的對映表)。所以減少函式呼叫次數就等於降低了效能消耗。
final修飾的函式會被編譯器優化,優化的結果是減少了函式呼叫的次數。如何實現的,舉個例子給你看:
public class Test{
final void func(){System.out.println("g");};
public void main(String[] args){
for(int j=0;j<1000;j++)
func();
}}
經過編譯器優化之後,這個類變成了相當於這樣寫:
public class Test{
final void func(){System.out.println("g");};
public void main(String[] args){
for(int j=0;j<1000;j++)
{System.out.println("g");}
}}
看出來區別了吧?編譯器直接將func的函式體內嵌到了呼叫函式的地方,這樣的結果是節省了1000次函式呼叫,當然編譯器處理成位元組碼,只是我們可以想象成這樣,看個明白。
不過,當函式體太長的話,用final可能適得其反,因為經過編譯器內嵌之後程式碼長度大大增加,於是就增加了jvm解釋位元組碼的時間。
在使用final修飾方法的時候,編譯器會將被final修飾過的方法插入到呼叫者程式碼處,提高執行速度和效率,但被final修飾的方法體不能過大,編譯器可能會放棄內聯,但究竟多大的方法會放棄,我還沒有做測試來計算過。
下面這些內容是通過兩個疑問來繼續闡述的
使用final修飾方法會提高速度和效率嗎
見下面的測試程式碼,我會執行五次:
public class Test
{
public static void getJava()
{
String str1 = "Java ";
String str2 = "final ";
for (int i = 0; i < 10000; i++)
{
str1 += str2;
}
}
public static final void getJava_Final()
{
String str1 = "Java ";
String str2 = "final ";
for (int i = 0; i < 10000; i++)
{
str1 += str2;
}
}
public static void main(String[] args)
{
long start = System.currentTimeMillis();
getJava();
System.out.println("呼叫不帶final修飾的方法執行時間為:" + (System.currentTimeMillis() - start) + "毫秒時間");
start = System.currentTimeMillis();
String str1 = "Java ";
String str2 = "final ";
for (int i = 0; i < 10000; i++)
{
str1 += str2;
}
System.out.println("正常的執行時間為:" + (System.currentTimeMillis() - start) + "毫秒時間");
start = System.currentTimeMillis();
getJava_Final();
System.out.println("呼叫final修飾的方法執行時間為:" + (System.currentTimeMillis() - start) + "毫秒時間");
}
}
結果為:
第一次:
呼叫不帶final修飾的方法執行時間為:1732毫秒時間
正常的執行時間為:1498毫秒時間
呼叫final修飾的方法執行時間為:1593毫秒時間
第二次:
呼叫不帶final修飾的方法執行時間為:1217毫秒時間
正常的執行時間為:1031毫秒時間
呼叫final修飾的方法執行時間為:1124毫秒時間
第三次:
呼叫不帶final修飾的方法執行時間為:1154毫秒時間
正常的執行時間為:1140毫秒時間
呼叫final修飾的方法執行時間為:1202毫秒時間
第四次:
呼叫不帶final修飾的方法執行時間為:1139毫秒時間
正常的執行時間為:999毫秒時間
呼叫final修飾的方法執行時間為:1092毫秒時間
第五次:
呼叫不帶final修飾的方法執行時間為:1186毫秒時間
正常的執行時間為:1030毫秒時間
呼叫final修飾的方法執行時間為:1109毫秒時間
由以上執行結果不難看出,執行最快的是“正常的執行”即程式碼直接編寫,而使用final修飾的方法,不像有些書上或者文章上所說的那樣,速度與效率與“正常的執行”無異,而是位於第二位,最差的是呼叫不加final修飾的方法。
觀點:加了比不加好一點。
使用final修飾變數會讓變數的值不能被改變嗎;
見程式碼:
public class Final
{
public static void main(String[] args)
{
Color.color[3] = "white";
for (String color : Color.color)
System.out.print(color+" ");
}
}
class Color
{
public static final String[] color = { "red", "blue", "yellow", "black" };
}
執行結果:
red blue yellow white
看!,黑色變成了白色。
在使用findbugs外掛時,就會提示public static String[] color = { "red", "blue", "yellow", "black" };這行程式碼不安全,但加上final修飾,這行程式碼仍然是不安全的,因為final沒有做到保證變數的值不會被修改!
原因是:final關鍵字只能保證變數本身不能被賦與新值,而不能保證變數的內部結構不被修改。例如在main方法有如下程式碼Color.color = new String[]{""};就會報錯了。
如何保證陣列內部不被修改
那可能有的同學就會問了,加上final關鍵字不能保證陣列不會被外部修改,那有什麼方法能夠保證呢?答案就是降低訪問級別,把陣列設為private。這樣的話,就解決了陣列在外部被修改的不安全性,但也產生了另一個問題,那就是這個陣列要被外部使用的。
解決這個問題見程式碼:
import java.util.AbstractList;
import java.util.List;
public class Final
{
public static void main(String[] args)
{
for (String color : Color.color)
System.out.print(color + " ");
Color.color.set(3, "white");
}
}
class Color
{
private static String[] _color = { "red", "blue", "yellow", "black" };
public static List<String> color = new AbstractList<String>()
{
@Override
public String get(int index)
{
return _color[index];
}
@Override
public String set(int index, String value)
{
throw new RuntimeException("為了程式碼安全,不能修改陣列");
}
@Override
public int size()
{
return _color.length;
}
};
}
這樣就OK了,既保證了程式碼安全,又能讓陣列中的元素被訪問了。
final方法的三條規則
規則1:final修飾的方法不可以被重寫。
規則2:final修飾的方法僅僅是不能重寫,但它完全可以被過載。
規則3:父類中private final方法,子類可以重新定義,這種情況不是重寫。
程式碼示例
規則1程式碼
public class FinalMethodTest
{
public final void test(){}
}
class Sub extends FinalMethodTest
{
// 下面方法定義將出現編譯錯誤,不能重寫final方法
public void test(){}
}
規則2程式碼
public class Finaloverload {
//final 修飾的方法只是不能重寫,完全可以過載
public final void test(){}
public final void test(String arg){}
}
規則3程式碼
public class PrivateFinalMethodTest
{
private final void test(){}
}
class Sub extends PrivateFinalMethodTest
{
// 下面方法定義將不會出現問題
public void test(){}
}
final 和 jvm的關係
與前面介紹的鎖和 volatile 相比較,對 final 域的讀和寫更像是普通的變數訪問。對於 final 域,編譯器和處理器要遵守兩個重排序規則:
- 在建構函式內對一個 final 域的寫入,與隨後把這個被構造物件的引用賦值給一個引用變數,這兩個操作之間不能重排序。
- 初次讀一個包含 final 域的物件的引用,與隨後初次讀這個 final 域,這兩個操作之間不能重排序。
下面,我們通過一些示例性的程式碼來分別說明這兩個規則:
public class FinalExample {
int i; // 普通變數
final int j; //final 變數
static FinalExample obj;
```
public void FinalExample () { // 建構函式
i = 1; // 寫普通域
j = 2; // 寫 final 域
}
public static void writer () { // 寫執行緒 A 執行
obj = new FinalExample ();
}
public static void reader () { // 讀執行緒 B 執行
FinalExample object = obj; // 讀物件引用
int a = object.i; // 讀普通域
int b = object.j; // 讀 final 域
}
```
}
這裡假設一個執行緒 A 執行 writer () 方法,隨後另一個執行緒 B 執行 reader () 方法。下面我們通過這兩個執行緒的互動來說明這兩個規則。
寫 final 域的重排序規則
寫 final 域的重排序規則禁止把 final 域的寫重排序到建構函式之外。這個規則的實現包含下面 2 個方面:
- JMM 禁止編譯器把 final 域的寫重排序到建構函式之外。
- 編譯器會在 final 域的寫之後,建構函式 return 之前,插入一個 StoreStore 屏障。這個屏障禁止處理器把 final 域的寫重排序到建構函式之外。
現在讓我們分析 writer () 方法。writer () 方法只包含一行程式碼:finalExample = new FinalExample ()。這行程式碼包含兩個步驟:
- 構造一個 FinalExample 型別的物件;
- 把這個物件的引用賦值給引用變數 obj。
假設執行緒 B 讀物件引用與讀物件的成員域之間沒有重排序(馬上會說明為什麼需要這個假設),下圖是一種可能的執行時序:
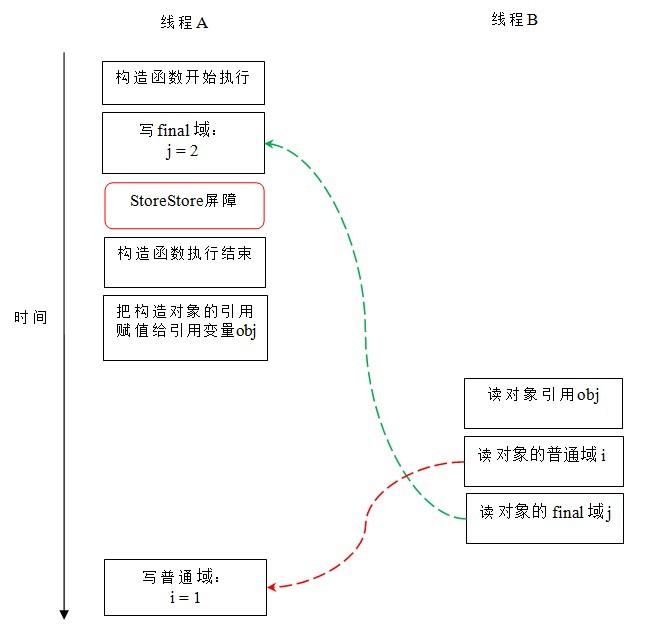
在上圖中,寫普通域的操作被編譯器重排序到了建構函式之外,讀執行緒 B 錯誤的讀取了普通變數 i 初始化之前的值。而寫 final 域的操作,被寫 final 域的重排序規則“限定”在了建構函式之內,讀執行緒 B 正確的讀取了 final 變數初始化之後的值。
寫 final 域的重排序規則可以確保:在物件引用為任意執行緒可見之前,物件的 final 域已經被正確初始化過了,而普通域不具有這個保障。以上圖為例,在讀執行緒 B“看到”物件引用 obj 時,很可能 obj 物件還沒有構造完成(對普通域 i 的寫操作被重排序到建構函式外,此時初始值 2 還沒有寫入普通域 i)。
讀 final 域的重排序規則
讀 final 域的重排序規則如下:
- 在一個執行緒中,初次讀物件引用與初次讀該物件包含的 final 域,JMM 禁止處理器重排序這兩個操作(注意,這個規則僅僅針對處理器)。編譯器會在讀 final 域操作的前面插入一個 LoadLoad 屏障。
初次讀物件引用與初次讀該物件包含的 final 域,這兩個操作之間存在間接依賴關係。由於編譯器遵守間接依賴關係,因此編譯器不會重排序這兩個操作。大多數處理器也會遵守間接依賴,大多數處理器也不會重排序這兩個操作。但有少數處理器允許對存在間接依賴關係的操作做重排序(比如 alpha 處理器),這個規則就是專門用來針對這種處理器。
reader() 方法包含三個操作:
- 初次讀引用變數 obj;
- 初次讀引用變數 obj 指向物件的普通域 j。
- 初次讀引用變數 obj 指向物件的 final 域 i。
現在我們假設寫執行緒 A 沒有發生任何重排序,同時程式在不遵守間接依賴的處理器上執行,下面是一種可能的執行時序:
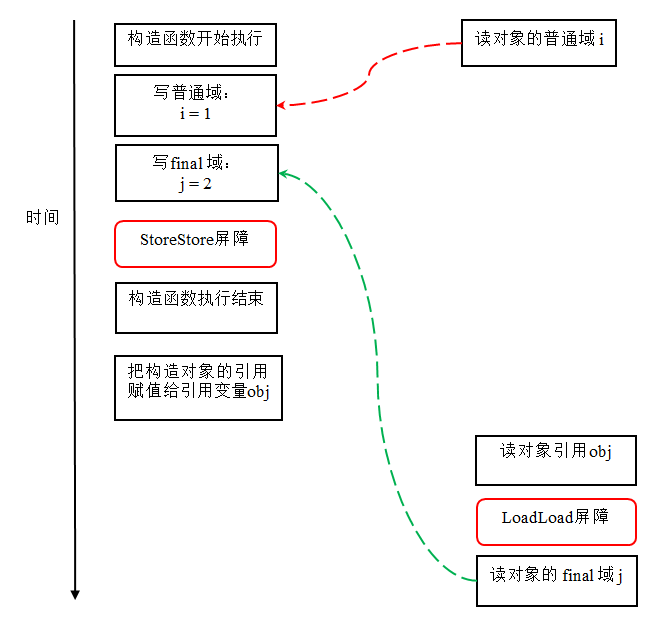
在上圖中,讀物件的普通域的操作被處理器重排序到讀物件引用之前。讀普通域時,該域還沒有被寫執行緒 A 寫入,這是一個錯誤的讀取操作。而讀 final 域的重排序規則會把讀物件 final 域的操作“限定”在讀物件引用之後,此時該 final 域已經被 A 執行緒初始化過了,這是一個正確的讀取操作。
讀 final 域的重排序規則可以確保:在讀一個物件的 final 域之前,一定會先讀包含這個 final 域的物件的引用。在這個示例程式中,如果該引用不為 null,那麼引用物件的 final 域一定已經被 A 執行緒初始化過了。
如果 final 域是引用型別
上面我們看到的 final 域是基礎資料型別,下面讓我們看看如果 final 域是引用型別,將會有什麼效果?
請看下列示例程式碼:
public class FinalReferenceExample {
final int[] intArray; //final 是引用型別
static FinalReferenceExample obj;
public FinalReferenceExample () { // 建構函式
intArray = new int[1]; //1
intArray[0] = 1; //2
}
public static void writerOne () { // 寫執行緒 A 執行
obj = new FinalReferenceExample (); //3
}
public static void writerTwo () { // 寫執行緒 B 執行
obj.intArray[0] = 2; //4
}
public static void reader () { // 讀執行緒 C 執行
if (obj != null) { //5
int temp1 = obj.intArray[0]; //6
}
}
}
這裡 final 域為一個引用型別,它引用一個 int 型的陣列物件。對於引用型別,寫 final 域的重排序規則對編譯器和處理器增加了如下約束:
- 在建構函式內對一個 final 引用的物件的成員域的寫入,與隨後在建構函式外把這個被構造物件的引用賦值給一個引用變數,這兩個操作之間不能重排序。
對上面的示例程式,我們假設首先執行緒 A 執行 writerOne() 方法,執行完後執行緒 B 執行 writerTwo() 方法,執行完後執行緒 C 執行 reader () 方法。下面是一種可能的執行緒執行時序:
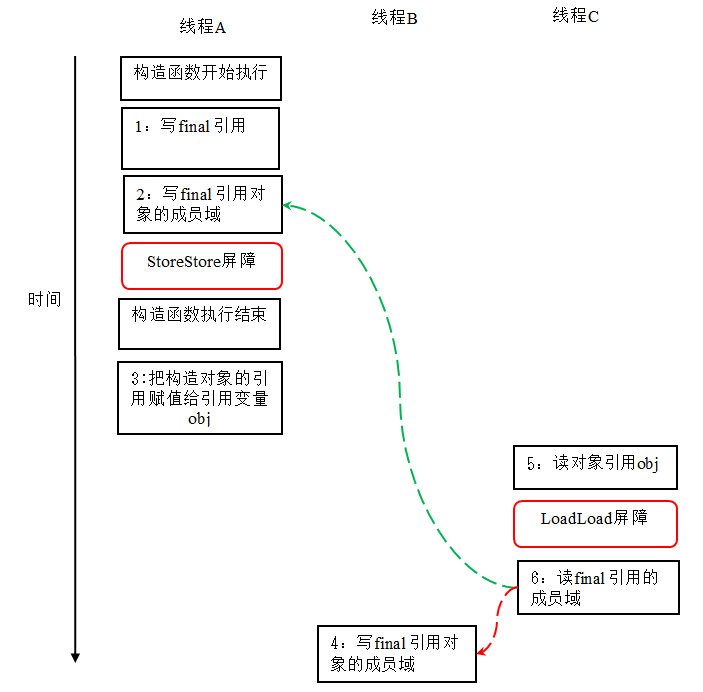
在上圖中,1 是對 final 域的寫入,2 是對這個 final 域引用的物件的成員域的寫入,3 是把被構造的物件的引用賦值給某個引用變數。這裡除了前面提到的 1 不能和 3 重排序外,2 和 3 也不能重排序。
JMM 可以確保讀執行緒 C 至少能看到寫執行緒 A 在建構函式中對 final 引用物件的成員域的寫入。即 C 至少能看到陣列下標 0 的值為 1。而寫執行緒 B 對陣列元素的寫入,讀執行緒 C 可能看的到,也可能看不到。JMM 不保證執行緒 B 的寫入對讀執行緒 C 可見,因為寫執行緒 B 和讀執行緒 C 之間存在資料競爭,此時的執行結果不可預知。
如果想要確保讀執行緒 C 看到寫執行緒 B 對陣列元素的寫入,寫執行緒 B 和讀執行緒 C 之間需要使用同步原語(lock 或 volatile)來確保記憶體可見性。
參考文章
https://www.infoq.cn/article/java-memory-model-6
https://www.jianshu.com/p/067b6c89875a
https://www.jianshu.com/p/f68d6ef2dcf0
https://www.cnblogs.com/xiaoxi/p/6392154.html
https://www.iteye.com/blog/cakin24-2334965
https://blog.csdn.net/chengqiuming/article/details/70139503
https://blog.csdn.net/hupuxiang/article/details/7362267
微信公眾號
Java技術江湖
如果大家想要實時關注我更新的文章以及分享的乾貨的話,可以關注我的公眾號【Java技術江湖】一位阿里 Java 工程師的技術小站,作者黃小斜,專注 Java 相關技術:SSM、SpringBoot、MySQL、分散式、中介軟體、叢集、Linux、網路、多執行緒,偶爾講點Docker、ELK,同時也分享技術乾貨和學習經驗,致力於Java全棧開發!
Java工程師必備學習資源: 一些Java工程師常用學習資源,關注公眾號後,後臺回覆關鍵字 “Java” 即可免費無套路獲取。

個人公眾號:黃小斜
作者是 985 碩士,螞蟻金服 JAVA 工程師,專注於 JAVA 後端技術棧:SpringBoot、MySQL、分散式、中介軟體、微服務,同時也懂點投資理財,偶爾講點演算法和計算機理論基礎,堅持學習和寫作,相信終身學習的力量!
程式設計師3T技術學習資源: 一些程式設計師學習技術的資源大禮包,關注公眾號後,後臺回覆關鍵字 “資料” 即可免費無套路獲取。

相關推薦
夯實Java基礎系列4:一文了解final關鍵字的特性、使用方法,以及實現原理
目錄 final使用 final變數 final修飾基本資料型別變數和引用 final類 final關鍵字的知識點 final關鍵字的最佳實踐 final的用法 關於空白final final記憶體分配 使用final修飾方法會提高速度和效率嗎 使用final修飾變數會讓變數的值不能被改變嗎; 如何保
夯實Java基礎系列6:一文搞懂抽象類和介面,從基礎到面試題,揭祕其本質區別!
目錄 抽象類介紹 為什麼要用抽象類 一個抽象類小故事 一個抽象類小遊戲 介面介紹 介面與類相似點: 介面與類的區別: 介面特性 抽象類和介面的區別 介面的使用: 介面最佳實踐:設計模式中的工廠模式 介面與抽象類的本質區別是什麼? 基本語法區別 設計思想區別 如何回答面試題:介面和抽象類的區別?
夯實Java基礎系列7:一文讀懂Java 程式碼塊和執行順序
目錄 Java中的構造方法 構造方法簡介 構造方法例項 例 1 例 2 Java中的幾種構造方法詳解 普通構造方法 預設構造方法 過載構造方法 java子類構造方法呼叫父類構造方法 Java中的程式碼塊簡介 Java程式碼塊使用 區域性程式碼塊 構造程式碼塊 靜態程式碼塊 Java程式碼塊、
夯實Java基礎系列19:一文搞懂Java集合類框架,以及常見面試題
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫裡檢視 https://github.com/h2pl/Java-Tutorial 喜歡的話麻煩點下Star哈 文章首發於我的個人部落格: www.how2playlife.com 本文參考 https://ww
夯實Java基礎系列22:一文讀懂Java序列化和反序列化
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫裡檢視 https://github.com/h2pl/Java-Tutorial 喜歡的話麻煩點下Star哈 文章首發於我的個人部落格: www.how2playlife.com 本文參考 http://www
夯實Java基礎系列23:一文讀懂繼承、封裝、多型的底層實現原理
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫裡檢視 https://github.com/h2pl/Java-Tutorial 喜歡的話麻煩點下Star哈 文章首發於我的個人部落格: www.how2playlife.com 從JVM結構開始談多型 Jav
夯實Java基礎系列5:Java檔案和Java包結構
目錄 Java中的包概念 包的作用 package 的目錄結構 設定 CLASSPATH 系統變數 常用jar包 java軟體包的型別 dt.jar rt.jar *.java檔案的奧祕 *.Java檔案簡介 為什麼一個java原始檔中只能有一個public類? Main方法 外部類的訪問許可權
夯實Java基礎系列9:深入理解Class類和Object類
目錄 Java中Class類及用法 Class類原理 如何獲得一個Class類物件 使用Class類的物件來生成目標類的例項 Object類 類構造器public Object(); registerNatives()方法; Clone()方法實現淺拷貝 getClass()方法 equals()方法
夯實Java基礎系列10:深入理解Java中的異常體系
目錄 為什麼要使用異常 異常基本定義 異常體系 初識異常 異常和錯誤 異常的處理方式 "不負責任"的throws 糾結的finally throw : JRE也使用的關鍵字 異常呼叫鏈 自定義異常 異常的注意事項 當finally遇上return JAVA異常常見面試題 參考文章 微信公眾號 Java技術
夯實Java基礎系列11:深入理解Java中的回撥機制
目錄 模組間的呼叫 多執行緒中的“回撥” Java回撥機制實戰 例項一 : 同步呼叫 例項二:由淺入深 例項三:Tom做題 參考文章
夯實Java基礎系列12:深入理解Java中的反射機制
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫裡檢視 https://github.com/h2pl/Java-Tutorial 喜歡的話麻煩點下Star哈 文章首發於我的個人部落格: www.how2playlife.com 列舉(enum)型別是Java
夯實Java基礎系列21:Java8新特性終極指南
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫裡檢視 https://github.com/h2pl/Java-Tutorial 喜歡的話麻煩點下Star哈 文章首發於我的個人部落格: www.how2playlife.com 這是一個Java8新增特性的總
Java基礎系列4:抽象類與介面的前世今生
該系列博文會告訴你如何從入門到進階,一步步地學習Java基礎知識,並上手進行實戰,接著瞭解每個Java知識點背後的實現原理,更完整地瞭解整個Java技術體系,形成自己的知識框架。 1、抽象類: 當編寫一個類時,常常會為該類定義一些方法,這些方法用以描述該類的行為方式,那麼這些方法都
機器學習概念篇:一文詳解凸函式和凸優化,乾貨滿滿
在機器學習各種優化問題中,凸集、凸函式和凸優化等概念經常出現,其是各種證明的前提條件,因此認識其性質對於優化問題的理解尤為重要,本文便就凸集、凸函式和凸優化等各種性質進行闡述,文末分享一波凸優化的學習資料和視訊! 一、幾何體的向量表示 在介紹凸集等概念之前
推薦 :一文了解AI時代的資料風險(後真相時代、演算法囚徒和權利讓渡)
當今,在基於資料的個性化推薦演算法機制滿足了人們獵奇心、窺探欲、表演慾,讓人們在網路中尋找到共鳴
一文了解網絡安全數字化轉型,Gartner的這些數字驚呆你!
紅芯企業瀏覽器 數字化轉型提起網絡安全立馬會想到Facebook泄密門受影響的用戶已達到8700 萬事實甚至比這個數字還要多得多連媒體都在感嘆網絡安全界真是“多事之秋”啊! 而Gartner近期發布的全球網絡安全產業規模發展及趨勢預測,那些關於網安行業的數字更是驚人。 “數字安全大家族”來啦 網絡安全問題由來
一文了解JVM全部垃圾回收器,從Serial到ZGC
應用 base garbage 最大收益 監控 fill 前沿 mage 記錄 《對象搜索算法與回收算法》介紹了垃圾回收的基礎算法,相當於垃圾回收的方法論。接下來就詳細看看垃圾回收的具體實現。 上文提到過現代的商用虛擬機的都是采用分代收集的,不同的區域用不同的收集器。常用的
一文了解HAProxy主要特性
本文轉自[Rancher Labs](https://mp.weixin.qq.com/s/LmK3p5ZkVEkTN9jGrd1sRg "Rancher Labs") 在Kubernetes中,Ingress物件定義了一些路由規則,這些規則規定如何將一個客戶端請求路由到指定服務,該服務執行在你的叢集中。這
Go基礎系列(4):匯入包和初始化階段
import匯入包 搜尋路徑 import用於匯入包: import ( "fmt" "net/http" "mypkg" ) 編譯器會根據上面指定的相對路徑去搜索包然後匯入,這個相對路徑是從GOROOT或GOPATH(workspace)下的src下開始搜尋的。 假如go的安裝目錄為
Java基礎系列16:使用JSONObject和JSONArray解析和構造json字串
轉自:https://www.zifangsky.cn/561.html 一 介紹 在Java開發中,我們通常需要進行XML文件或JSON字串的構造和解析。當然在Java Web開發中有一些第三方外掛是可以自動完成Java物件和json之間的轉換的,比