
從零開始入門 K8s | 應用編排與管理:Job & DaemonSet
一、Job
需求來源
Job 背景問題
首先我們來看一下 Job 的需求來源。我們知道 K8s 裡面,最小的排程單元是 Pod,我們可以直接通過 Pod 來執行任務程序。這樣做將會產生以下幾種問題:
- 我們如何保證 Pod 內程序正確的結束?
- 如何保證程序執行失敗後重試?
- 如何管理多個任務,且任務之間有依賴關係?
- 如何並行地執行任務,並管理任務的佇列大小?
Job:管理任務的控制器
我們來看一下 Kubernetes 的 Job 為我們提供了什麼功能:
- 首先 kubernetes 的 Job 是一個管理任務的控制器,它可以建立一個或多個 Pod 來指定 Pod 的數量,並可以監控它是否成功地執行或終止;
- 我們可以根據 Pod 的狀態來給 Job 設定重置的方式及重試的次數;
- 我們還可以根據依賴關係,保證上一個任務執行完成之後再執行下一個任務;
- 同時還可以控制任務的並行度,根據並行度來確保 Pod 執行過程中的並行次數和總體完成大小。
用例解讀
我們根據一個例項來看一下Job是如何來完成下面的應用的。
Job 語法

上圖是 Job 最簡單的一個 yaml 格式,這裡主要新引入了一個 kind 叫 Job,這個 Job 其實就是 job-controller 裡面的一種型別。 然後 metadata 裡面的 name 來指定這個 Job 的名稱,下面 spec.template 裡面其實就是 pod 的 spec。
這裡面的內容都是一樣的,唯一多了兩個點:
- 第一個是 restartPolicy,在 Job 裡面我們可以設定 Never、OnFailure、Always 這三種重試策略。在希望 Job 需要重新執行的時候,我們可以用 Never;希望在失敗的時候再執行,再重試可以用 OnFailure;或者不論什麼情況下都重新執行時 Alway;
- 另外,Job 在執行的時候不可能去無限的重試,所以我們需要一個引數來控制重試的次數。這個 backoffLimit 就是來保證一個 Job 到底能重試多少次。
所以在 Job 裡面,我們主要重點關注的一個是 restartPolicy 重啟策略和 backoffLimit 重試次數限制
Job 狀態

Job 建立完成之後,我們就可以通過 kubectl get jobs 這個命令,來檢視當前 job 的執行狀態。得到的值裡面,基本就有 Job 的名稱、當前完成了多少個 Pod,進行多長時間。
**AGE **的含義是指這個 Pod 從當前時間算起,減去它當時建立的時間。這個時長主要用來告訴你 Pod 的歷史、Pod 距今建立了多長時間。**DURATION **主要來看我們 Job 裡面的實際業務到底運行了多長時間,當我們的效能調優的時候,這個引數會非常的有用。**COMPLETIONS **主要來看我們任務裡面這個 Pod 一共有幾個,然後它其中完成了多少個狀態,會在這個欄位裡面做顯示。
檢視 Pod
<br />下面我們來看一下 Pod,其實 Job 最後的執行單元還是 Pod。我們剛才建立的 Job 會創建出來一個叫“pi”的一個 Pod,這個任務就是來計算這個圓周率,Pod 的名稱會以“${job-name}-${random-suffix}”,我們可以看一下下面 Pod 的 yaml 格式。
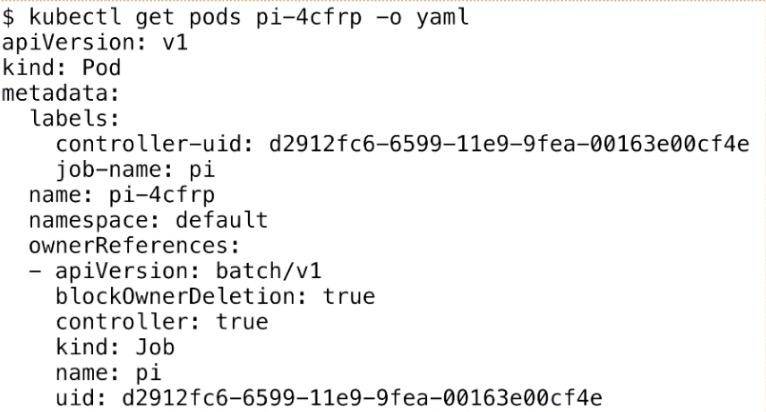
它比普通的 Pod 多了一個叫 ownerReferences,這個東西來宣告此 pod 是歸哪個上一層 controller 來管理。可以看到這裡的 ownerReferences 是歸 batch/v1,也就是上一個 Job 來管理的。這裡就聲明瞭它的 controller 是誰,然後可以通過 pod 返查到它的控制器是誰,同時也能根據 Job 來查一下它下屬有哪些 Pod。
並行執行 Job
我們有時候有些需求:希望 Job 執行的時候可以最大化的並行,並行出 n 個 Pod 去快速地執行。同時,由於我們的節點數有限制,可能也不希望同時並行的 Pod 數過多,有那麼一個管道的概念,我們可以希望最大的並行度是多少,Job 控制器都可以幫我們來做到。
這裡主要看兩個引數:一個是 completions,一個是 parallelism。
- 首先第一個引數是用來指定本 Pod 佇列執行次數。可能這個不是很好理解,其實可以把它認為是這個 Job 指定的可以執行的總次數。比如這裡設定成 8,即這個任務一共會被執行 8 次;
- 第二個引數代表這個並行執行的個數。所謂並行執行的次數,其實就是一個管道或者緩衝器中緩衝佇列的大小,把它設定成 2,也就是說這個 Job 一定要執行 8 次,每次並行 2 個 Pod,這樣的話,一共會執行 4 個批次。
檢視並行 Job 執行
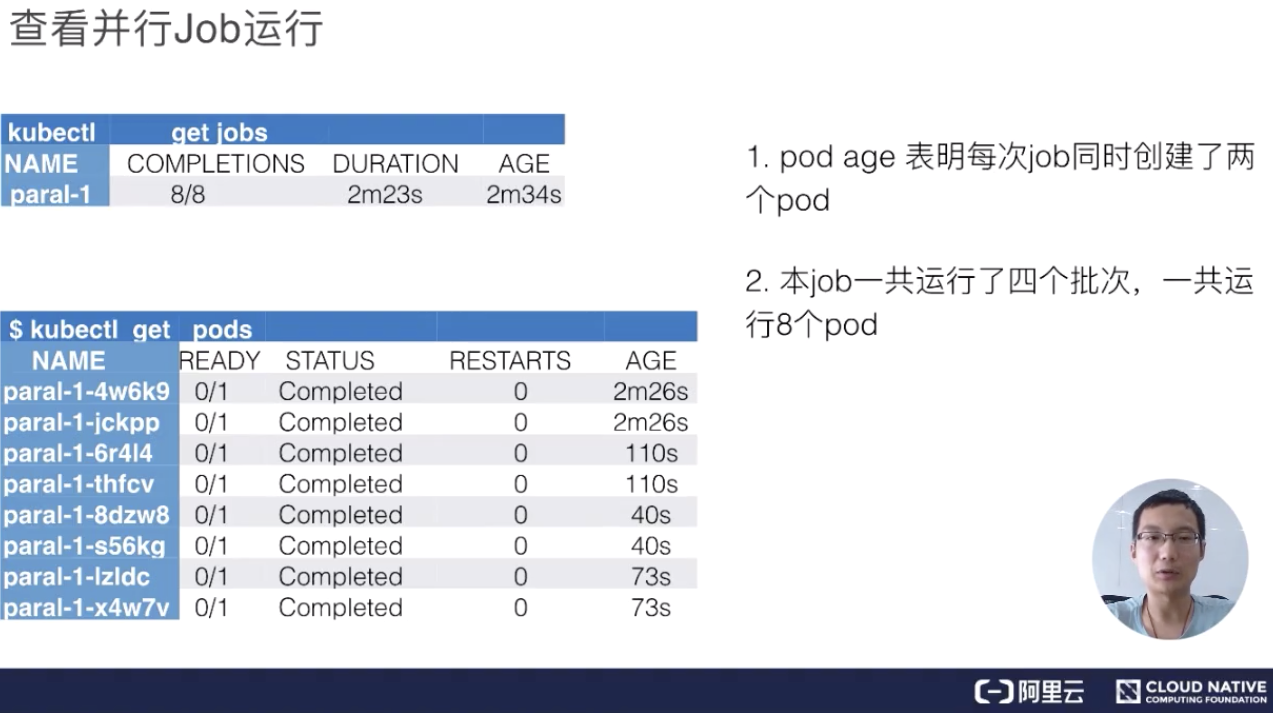
下面來看一下它的實際執行效果,上圖就是當這個 Job 整體執行完畢之後可以看到的效果,首先看到 job 的名字,然後看到它一共創建出來了 8 個 pod,執行了 2 分 23 秒,這是建立的時間。
接著來看真正的 pods,pods 總共出來了 8 個 pod,每個 pod 的狀態都是完成的,然後來看一下它的 AGE,就是時間。從下往上看,可以看到分別有 73s、40s、110s 和 2m26s。每一組都有兩個 pod 時間是相同的,即:時間段是 40s 的時候是最後一個建立、 2m26s 是第一個建立的。也就是說,總是兩個 pod 同時創建出來,並行完畢、消失,然後再建立、再執行、再完畢。
比如說,剛剛我們其實通過第二個引數來控制了當前 Job 並行執行的次數,這裡就可以瞭解到這個緩衝器或者說管道佇列大小的作用。
Cronjob 語法

下面來介紹另外一個 Job,叫做 CronJob,其實也可以叫定時執行 Job。CronJob 其實和 Job 大體是相似的,唯一的不同點就是它可以設計一個時間。比如說可以定時在幾點幾分執行,特別適合晚上做一些清理任務,還有可以幾分鐘執行一次,幾小時執行一次等等,這就叫定時任務。
定時任務和 Job 相比會多幾個不同的欄位:
-
schedule:schedule 這個欄位主要是設定時間格式,它的時間格式和 Linux 的 crontime 是一樣的,所以直接根據 Linux 的 crontime 書寫格式來書寫就可以了。舉個例子: */1 指每分鐘去執行一下 Job,這個 Job 需要做的事情就是打印出大約時間,然後打印出“Hello from the kubernetes cluster” 這一句話;
-
**startingDeadlineSeconds:**即:每次執行 Job 的時候,它最長可以等多長時間,有時這個 Job 可能執行很長時間也不會啟動。所以這時,如果超過較長時間的話,CronJob 就會停止這個 Job;
-
concurrencyPolicy:就是說是否允許並行執行。所謂的並行執行就是,比如說我每分鐘執行一次,但是這個 Job 可能執行的時間特別長,假如兩分鐘才能執行成功,也就是第二個 Job 要到時間需要去執行的時候,上一個 Job 還沒完成。如果這個 policy 設定為 true 的話,那麼不管你前面的 Job 是否執行完成,每分鐘都會去執行;如果是 false,它就會等上一個 Job 執行完成之後才會執行下一個;
-
**JobsHistoryLimit:**這個就是每一次 CronJob 執行完之後,它都會遺留上一個 Job 的執行歷史、檢視時間。當然這個額不能是無限的,所以需要設定一下歷史存留數,一般可以設定預設 10 個或 100 個都可以,這主要取決於每個人叢集不同,然後根據每個人的叢集數來確定這個時間。
操作演示
Job 的編排檔案
下面看一下具體如何使用 Job。
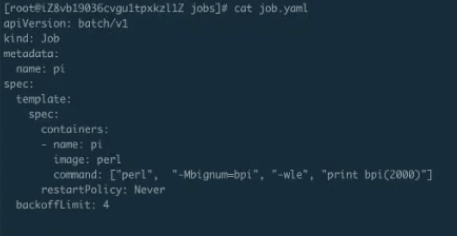
Job 的建立及執行驗證
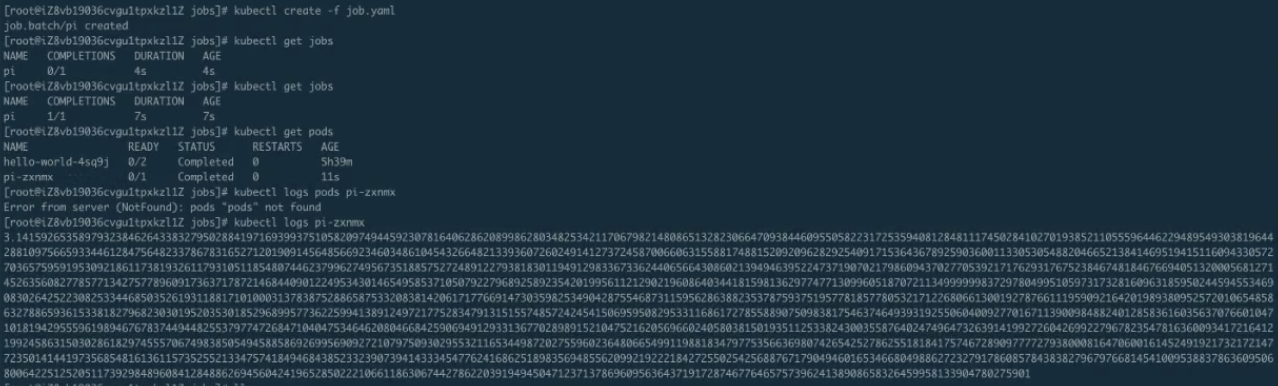
首先看一下 job.yaml。這是一個非常簡單的計算 pi 的一個任務。使用 kubectl creat-f job.yaml,這樣 job 就能提交成功了。來看一下 kubectl.get.jobs,可以看到這個 job 正在執行;get pods 可以看到這個 pod 應該是執行完成了,那麼接下來 logs 一下這個 job 以及 pod。可以看到下圖裡面打印出來了圓周率。
並行 Job 的編排檔案
下面再來看第二個例子:
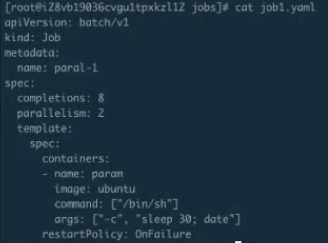
並行 Job 的建立及執行驗證
這個例子就是指剛才的並行執行 Job 建立之後,可以看到有第二個並行的 Job。
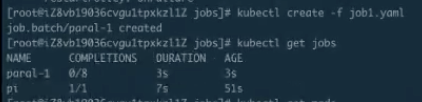
現在已經有兩個 Pod 正在 running,可以看到它大概執行了快到 30s。
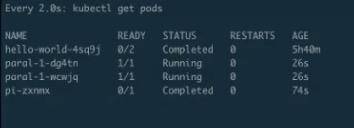
30s 之後它應該會起第二個。
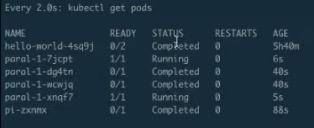
第一批的 pod 已經執行完畢,第二批的 pod 正在 running,每批次分別是兩個Pod。也就是說後面每隔 40s 左右,就會有兩個 pod 在並行執行,它一共會執行 4 批,共 8 個 pod,等到所有的 pod 執行完畢,就是剛才所說的並行執行的緩衝佇列功能。
過一段時間再看這個 pods,可以發現第二批已經執行結束,接下來開始建立第三批······
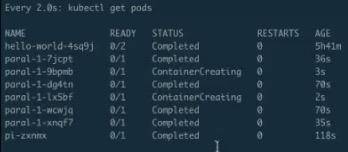
Cronjob 的編排檔案
下面來看第三個例子 —— CronJob。 CronJob 是每分鐘執行一次,每次一個 job。
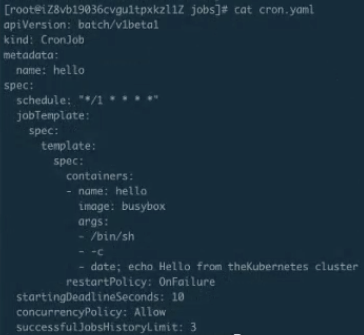
Cronjob 的建立及執行驗證
如下圖 CronJob 已經建立了,可以通過 get cronjob 來看到當前有一個 CronJob,這個時候再來看 jobs,由於它是每分鐘執行一次,所以得稍微等一下。
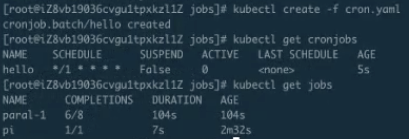
同時可以看到,上一個 job 還在執行,它的時間是 2m12s 左右,它的完成度是 7/8、6/8,剛剛看到 7/8 到 8/8,也就是說我們上一個任務執行了最後一步,而且每次都是兩個兩個地去執行。每次兩個執行的 job 都會讓我們在執行一些大型工作流或者工作任務的時候感到特別的方便。
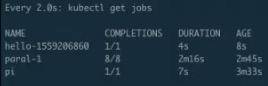
上圖中可以看到突然出現了一個 job,“hello-xxxx”這個 job 就是剛才所說的 CronJob。它距離剛才 CronJob 提交已經過去 1 分鐘了,這樣就會自動創建出來一個 job,如果不去幹擾它的話,它以後大概每一分鐘都會創建出來這麼一個 job,除非等我們什麼時候指定它不可以再執行的時候它才會停止建立。
在這裡 CronJob 其實主要是用來運作一些清理任務或者說執行一些定時任務。比如說 Jenkins 構建等方面的一些任務,會特別有效。
架構設計
Job 管理模式
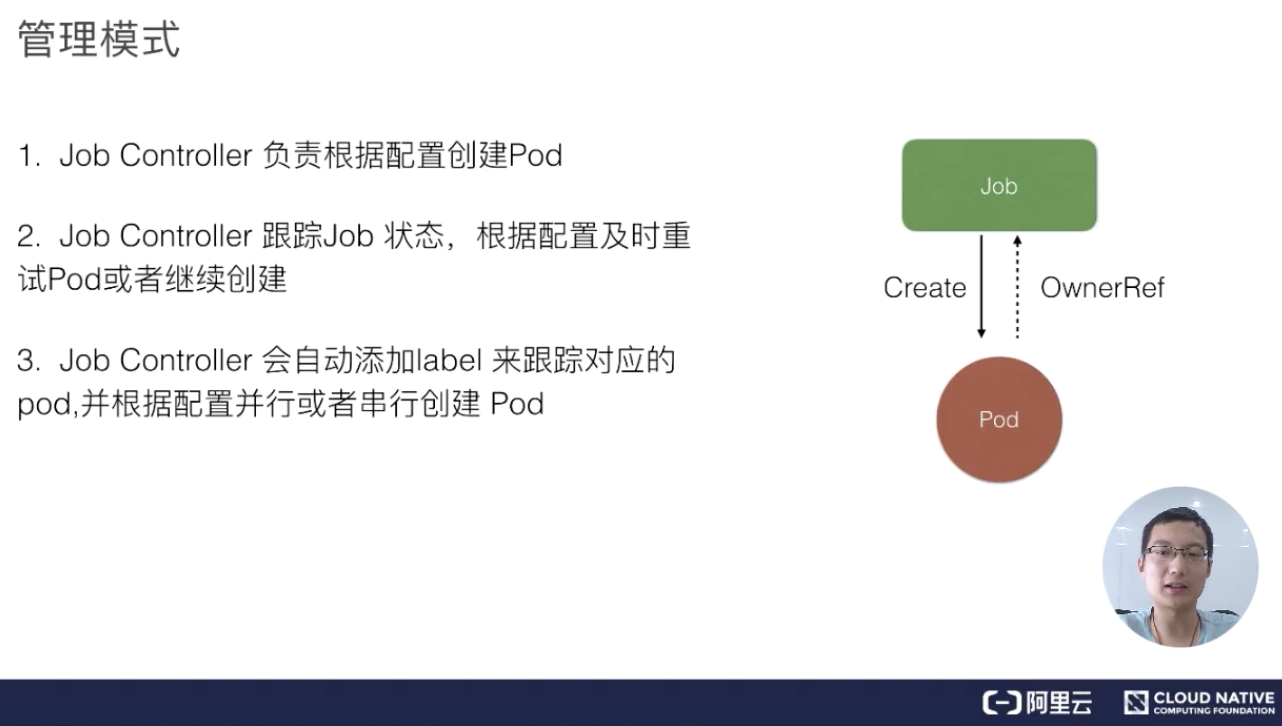
我們來看一下 job 的架構設計。Job Controller 其實還是主要去建立相對應的 pod,然後 Job Controller 會去跟蹤 Job 的狀態,及時地根據我們提交的一些配置重試或者繼續建立。同時我們剛剛也提到,每個 pod 會有它對應的 label,來跟蹤它所屬的 Job Controller,並且還去配置並行的建立, 並行或者序列地去建立 pod。
Job 控制器
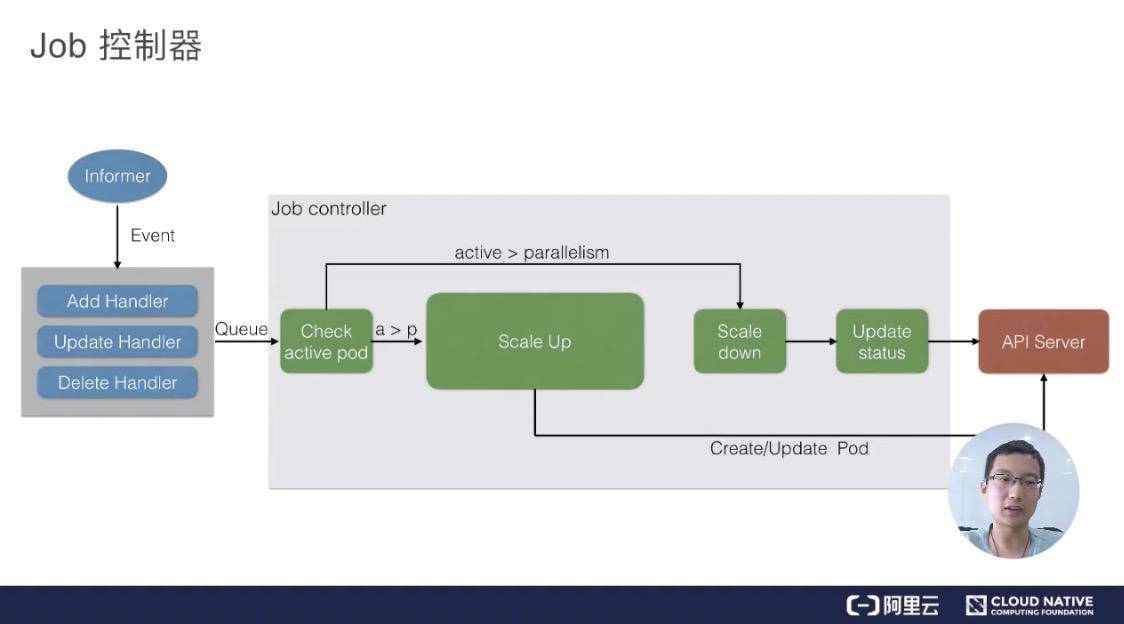
上圖是一個 Job 控制器的主要流程。所有的 job 都是一個 controller,它會 watch 這個 API Server,我們每次提交一個 Job 的 yaml 都會經過 api-server 傳到 ETCD 裡面去,然後 Job Controller 會註冊幾個 Handler,每當有新增、更新、刪除等操作的時候,它會通過一個記憶體級的訊息佇列,發到 controller 裡面。
通過 Job Controller 檢查當前是否有執行的 pod,如果沒有的話,通過 Scale up 把這個 pod 創建出來;如果有的話,或者如果大於這個數,對它進行 Scale down,如果這時 pod 發生了變化,需要及時 Update 它的狀態。
同時要去檢查它是否是並行的 job,或者是序列的 job,根據設定的配置並行度、序列度,及時地把 pod 的數量給創建出來。最後,它會把 job 的整個的狀態更新到 API Server 裡面去,這樣我們就能看到呈現出來的最終效果了。
二、DaemonSet
需求來源
DaemonSet 背景問題
下面介紹第二個控制器:**DaemonSet。**同樣的問題:如果我們沒有 DaemonSet 會怎麼樣?下面有幾個需求:
- 首先如果希望每個節點都運行同樣一個 pod 怎麼辦?
- 如果新節點加入叢集的時候,想要立刻感知到它,然後去部署一個 pod,幫助我們初始化一些東西,這個需求如何做?
- 如果有節點退出的時候,希望對應的 pod 會被刪除掉,應該怎麼操作?
- 如果 pod 狀態異常的時候,我們需要及時地監控這個節點異常,然後做一些監控或者彙報的一些動作,那麼這些東西運用什麼控制器來做?
DaemonSet:守護程序控制器
DaemonSet 也是 Kubernetes 提供的一個 default controller,它實際是做一個守護程序的控制器,它能幫我們做到以下幾件事情:
- 首先能保證叢集內的每一個節點都執行一組相同的 pod;
- 同時還能根據節點的狀態保證新加入的節點自動建立對應的 pod;
- 在移除節點的時候,能刪除對應的 pod;
- 而且它會跟蹤每個 pod 的狀態,當這個 pod 出現異常、Crash 掉了,會及時地去 recovery 這個狀態。
用例解讀
DaemonSet 語法
下面舉個例子來看一下,DaemonSet.yaml 會稍微長一些。

首先是 kind:DaemonSet。如果之前學過 deployment,其實我們再看這個 yaml 會比較簡單。例如它會有 matchLabel,通過 matchLabel 去管理對應所屬的 pod,這個 pod.label 也要和這個 DaemonSet.controller.label 想匹配,它才能去根據 label.selector 去找到對應的管理 Pod。下面 spec.container 裡面的東西都是一致的。<br /> <br />這裡用 fluentd 來做例子。DaemonSet 最常用的點在於以下幾點內容:
-
首先是儲存,GlusterFS 或者 Ceph 之類的東西,需要每臺節點上都執行一個類似於 Agent 的東西,DaemonSet 就能很好地滿足這個訴求;
-
另外,對於日誌收集,比如說 logstash 或者 fluentd,這些都是同樣的需求,需要每臺節點都執行一個 Agent,這樣的話,我們可以很容易蒐集到它的狀態,把各個節點裡面的資訊及時地彙報到上面;
-
還有一個就是,需要每個節點去執行一些監控的事情,也需要每個節點去運行同樣的事情,比如說 Promethues 這些東西,也需要 DaemonSet 的支援。
檢視 DaemonSet 狀態
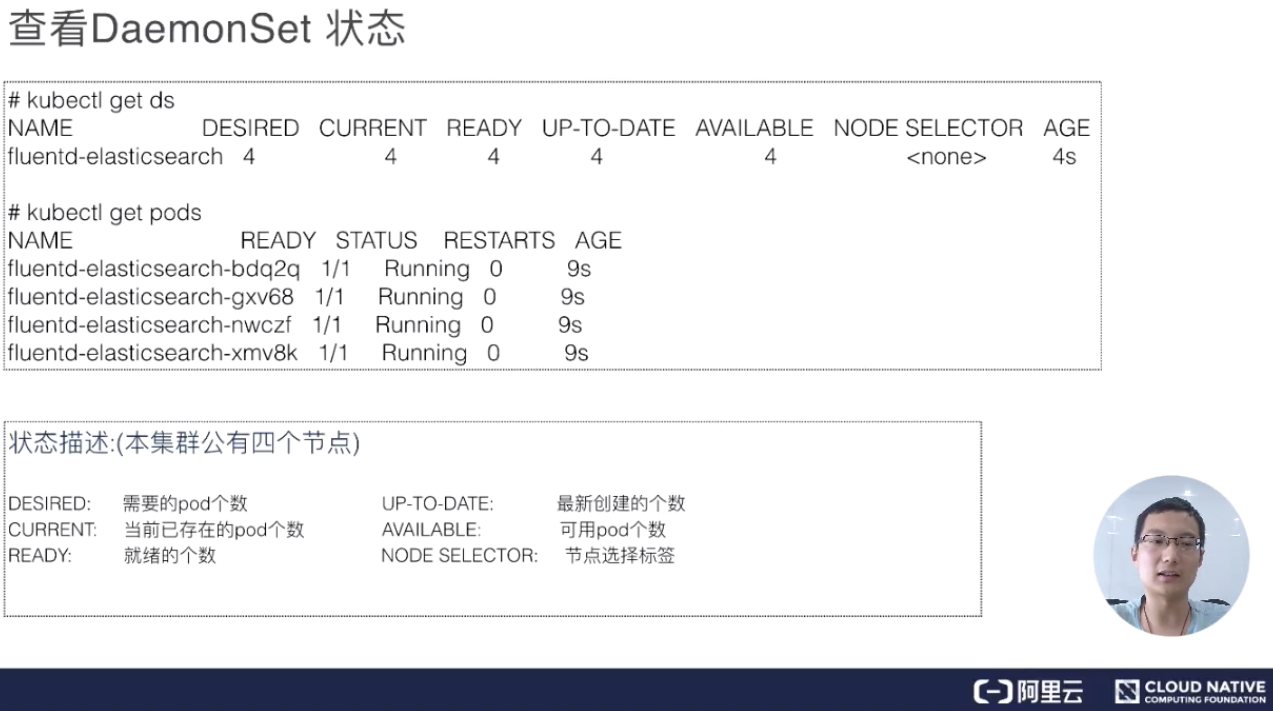
建立完 DaemonSet 之後,我們可以使用 kubectl get DaemonSet(DaemonSet 縮寫為 ds)。可以看到 DaemonSet 返回值和 deployment 特別像,即它當前一共有正在執行的幾個,然後我們需要幾個,READY 了幾個。當然這裡面,READY 都是隻有 Pod,所以它最後創建出來所有的都是 pod。
這裡有幾個引數,分別是:需要的 pod 個數、當前已經建立的 pod 個數、就緒的個數,以及所有可用的、通過健康檢查的 pod;還有 NODE SELECTOR,因為 NODE SELECTOR 在 DaemonSet 裡面非常有用。有時候我們可能希望只有部分節點去執行這個 pod 而不是所有的節點,所以有些節點上被打了標的話,DaemonSet 就只執行在這些節點上。比如,我只希望 master 節點執行某些 pod,或者只希望 Worker 節點執行某些 pod,就可以使用這個 NODE SELECTOR。
更新 DaemonSet

其實 DaemonSet 和 deployment 特別像,它也有兩種更新策略:一個是 RollingUpdate,另一個是 OnDelete。
-
RollingUpdate 其實比較好理解,就是會一個一個的更新。先更新第一個 pod,然後老的 pod 被移除,通過健康檢查之後再去見第二個 pod,這樣對於業務上來說會比較平滑地升級,不會中斷;
-
OnDelete 其實也是一個很好的更新策略,就是模板更新之後,pod 不會有任何變化,需要我們手動控制。我們去刪除某一個節點對應的 pod,它就會重建,不刪除的話它就不會重建,這樣的話對於一些我們需要手動控制的特殊需求也會有特別好的作用。
操作演示
DaemonSet 的編排
下面舉一個例子。比如說我們去改了些 DaemonSet 的映象,然後看到了它的狀態,它就會去一個一個地更新。
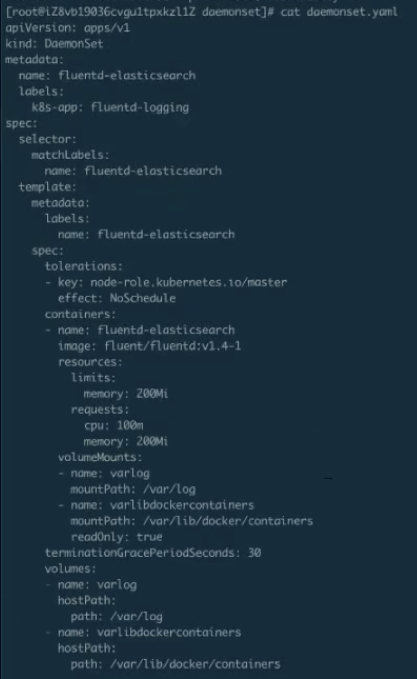
上圖這個就是剛才 DaemonSet 的 yaml,會比剛才會多一些, 我們做一些資源的限制,這個都不影響。
DaemonSet 的建立與執行驗證
下面我們建立一下 DaemonSet ,然後再看一下它的狀態。下圖就是我們剛才看到的 DaemonSet 在 ready 裡打出來的狀態。

從下圖中可以看到,一共有 4 個 pod 被創建出來。為什麼是 4 個 pod呢?因為只有 4 個節點,所以每個節點上都會執行一個對應的 pod。
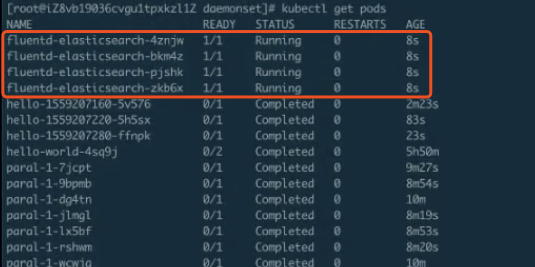
DaemonSet 的更新
這時,我們來更新 DaemonSet, 執行完了kubectl apply -f 後,它的 DaemonSet 就已經更新了。接下來我們去檢視 DaemonSet 的更新狀態。
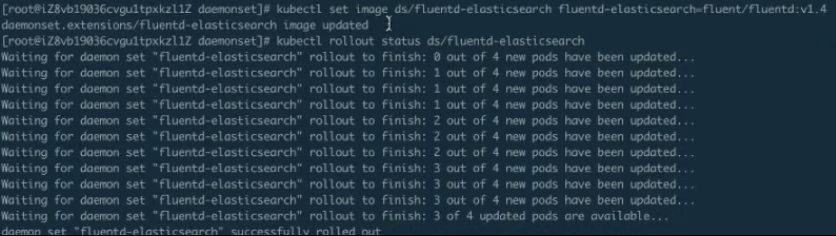
上圖中可以看到:DaemonSet 預設這個是 RollingUpdate 的,我們看到是 0-4,現在是 1-4,也就是說它在更新第一個,第一個更新完成會去更新第二個,第二個更新完,就更新第三個······這個就是 RollingUpdate。RollingUpdate 可以做到全自動化的更新,不用有人值守,而是一個一個地去自動更新,更新的過程也比較平滑,這樣可以有利於我們在現場釋出或者做一些其他操作。<br />
上圖結尾處可以看到,整個的 DaemonSet 已經 RollingUpdate 完畢。
架構設計
DaemonSet 管理模式

接下來看一下 DaemonSet 架構設計。DaemonSet 還是一個 controller,它最後真正的業務單元也是 Pod,DaemonSet 其實和 Job controller 特別相似,它也是通過 controller 去 watch API Server 的狀態,然後及時地新增 pod。唯一不同的是,它會監控節點的狀態,節點新加入或者消失的時候會在節點上建立對應的 pod,然後同時根據你配置的一些 affinity 或者 label 去選擇對應的節點。
DaemonSet 控制器
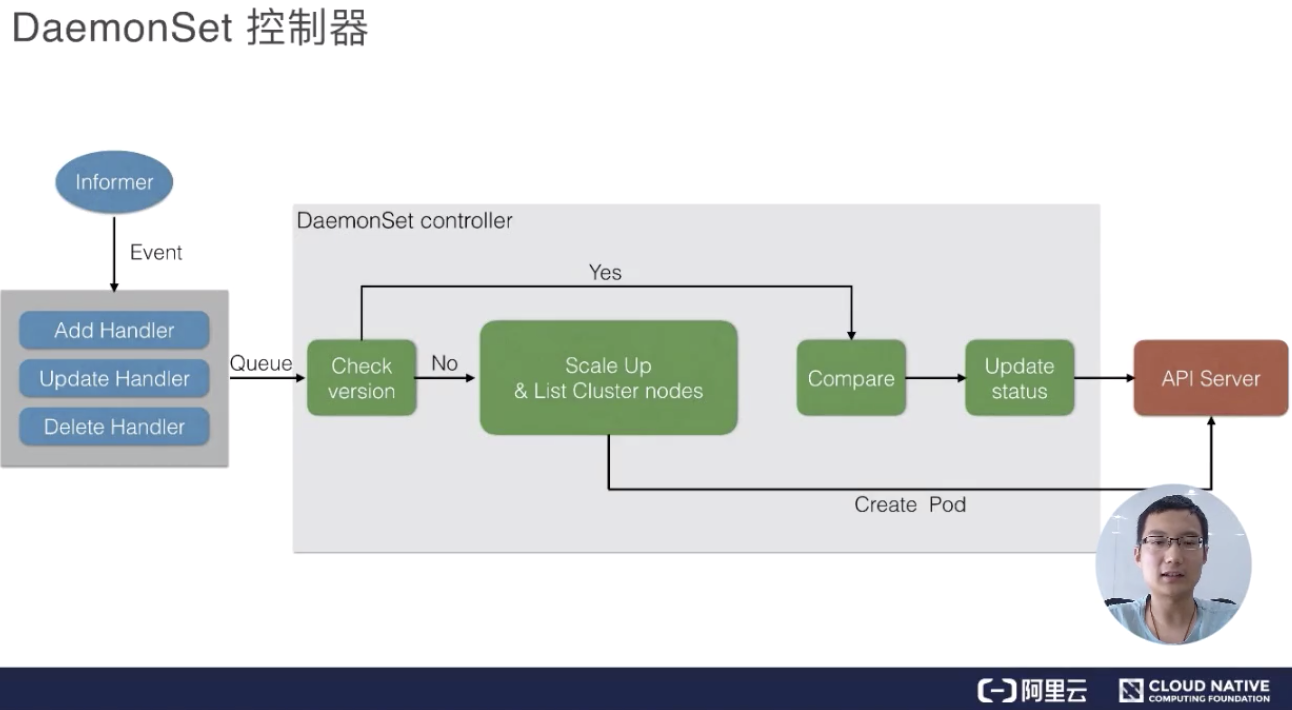
最後我們來看一下 DaemonSet 的控制器,DaemonSet 其實和 Job controller 做的差不多:兩者都需要根據 watch 這個 API Server 的狀態。現在 DaemonSet 和 Job controller 唯一的不同點在於,DaemonsetSet Controller需要去 watch node 的狀態,但其實這個 node 的狀態還是通過 API Server 傳遞到 ETCD 上。
當有 node 狀態節點發生變化時,它會通過一個記憶體訊息佇列發進來,然後DaemonSet controller 會去 watch 這個狀態,看一下各個節點上是都有對應的 Pod,如果沒有的話就去建立。當然它會去做一個對比,如果有的話,它會比較一下版本,然後加上剛才提到的是否去做 RollingUpdate?如果沒有的話就會重新建立,Ondelete 刪除 pod 的時候也會去做 check 它做一遍檢查,是否去更新,或者去建立對應的 pod。
當然最後的時候,如果全部更新完了之後,它會把整個 DaemonSet 的狀態去更新到 API Server 上,完成最後全部的更新
本文總結
- Job & CronJobs 基礎操作與概念解析:本文詳細介紹了 Job 和 CronJob 的概念,並通過兩個實際的例子介紹了 Job 和 CronJob 的使用,對於 Job 和 CronJob 內的各種功能便籤都進行了詳細的演示;
- DaemonSet 基礎操作與概念解析:通過類比 Deployment 控制器,我們理解了一下 DaemonSet 控制器的工作流程與方式,並且通過對 DaemonSet 的更新瞭解了滾動更新的概念和相對應的操作方式。
“阿里巴巴雲原生微信公眾號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦雲原生流行技術趨勢、雲原生大規模的落地實踐,做最懂雲原生開發者的技術公眾