
mr 程式自定義分組的實現
阿新 • • 發佈:2019-10-04

AreaPartitioner
package cn.itcast.hadoop.mr.areapartition; import java.util.HashMap; import org.apache.hadoop.mapreduce.Partitioner; public class AreaPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE> { private static HashMap<String, Integer> areaMap = new HashMap<>(); static { areaMap.put("135", 0); areaMap.put("136", 1); areaMap.put("137", 2); areaMap.put("138", 3); areaMap.put("139", 4); } @Override public int getPartition(KEY key, VALUE value, int numPartitions) { // 從 key 中拿到手機號,查詢手機歸屬字典,不同省份返回不同的組號 int areaCoder = areaMap.get(key.toString().substring(0, 3)) == null ? 5 : areaMap.get(key.toString().substring(0, 3)); return areaCoder; } }
FlowSumArea
package cn.itcast.hadoop.mr.areapartition; import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.itcast.hadoop.mr.flowsum.FlowBean; /** * 對流量原始日誌進行流量統計,將不同省份的使用者統計結果輸出到不同檔案 * 需要自定義改造兩個機制: * 1.改造分割槽的邏輯,自定義一個parttioner * 2.自定義 reduce task 的併發任務數量 * * @author [email protected] * */ public class FlowSumArea { public static class FlowSumAreaMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //拿一行資料 String line = value.toString(); //切分各個欄位 String[] fields = StringUtils.split(line, "\t"); //拿到我們需要的欄位 String phoneNB = fields[1]; long u_flow = Long.parseLong(fields[7]); long d_flow = Long.parseLong(fields[8]); //封裝成 kv 並輸出 context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow)); } } public static class FlowSumAreaReducer extends Reducer<Text, FlowBean, Text, FlowBean>{ @Override protected void reduce(Text key, Iterable<FlowBean> values,Context context) throws IOException, InterruptedException { long up_flow_counter = 0; long d_flow_counter = 0; for(FlowBean bean: values){ up_flow_counter += bean.getUp_flow(); d_flow_counter += bean.getD_flow(); } context.write(key, new FlowBean(key.toString(), up_flow_counter, d_flow_counter)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowSumArea.class); job.setMapperClass(FlowSumAreaMapper.class); job.setReducerClass(FlowSumAreaReducer.class); //設定我們自定義的邏輯定義 job.setPartitionerClass(AreaPartitioner.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //設定reduce的任務併發數,應該跟分組的數量保持一致 job.setNumReduceTasks(6); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1); } }
打包 jar 包,上傳:
![]()
上面最後一個加個 2 。。

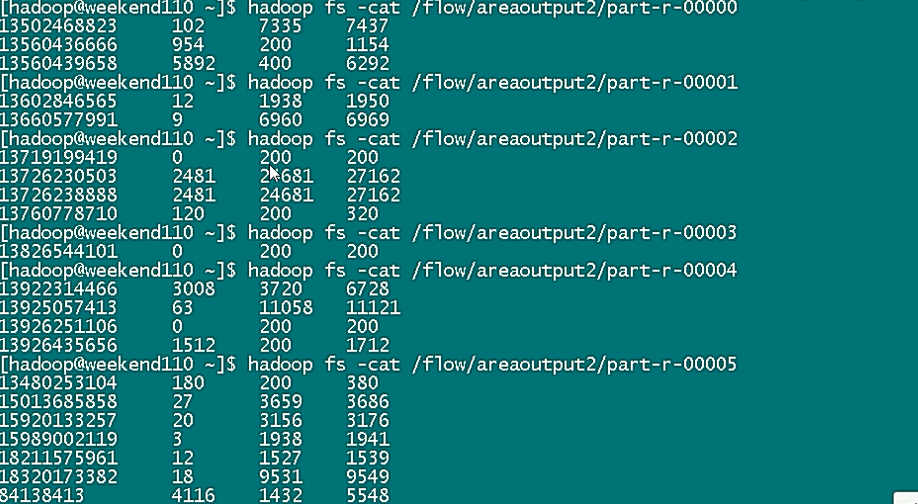
reduce 併發數量如果 < 分組數,會報錯;但是改成 1 不會報錯。。。
reduce 併發數量如果 < 分組數,多的分組沒有資料
map 不會涉及到業務邏輯,,如果有 10 個map ,每個就處理 1/10 的資料,map 的併發量是可以任意去設定的。