
計算機 編碼 解碼
目錄
- 1 字元 & 編碼
- 2 記事本下的亂碼
- 3 UTF-8解碼過程
- 4 UTF-16解碼過程
- 5 ISO-8859-1
- 6 byte範圍
在閱讀本文章之前,我建議你首先看阮一峰的部落格:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
1 字元 & 編碼
字元:
是文字和符號的總稱。一個漢字、標點符號、英文字母、數字,這都是字元
字符集:
是多個字元的集合。我們可以理解為一本大字典。字符集種類很多,每個字符集包含的字元個數也不同。常見的字符集有:ASCII字符集、Unicode字符集、GB2312字符集、ISO-8859-1字符集等
字元編碼:
計算機只能識別二進位制1和0。字符集中的字元,計算機是不能直接識別的,所以要將字符集轉換為計算機可以識別的二進位制,這個轉換過程就是編碼,而字元編碼就是將二進位制的數與字符集中的字元對應起來的一套規則
全形和半形(針對中文字符集):

中文字符集將ASCII裡本來就有的大小寫英文字母、阿拉伯數字、標點符號重新編寫了一套兩個位元組長的編碼,這就是 “ 全形 ”字元,而原來在127以下的那些就叫 “ 半形 ”字元了。全形和半形只針對於字母、數字和標點而言的,對於中文字是沒有全形和半形區分的。
全形字元:字母和數字與漢字佔等寬位置的字並且佔2個位元組 半形字元:正常ASCII字型寬度且佔一個位元組
全形字元:abcdef123 -- 字型要寬一點 總共有18個位元組
半形字元:abcedf123 -- 字型要窄一點 總共有 9個位元組GB2312、GBK、GB18030區別:
GB2312支援的漢字太少。1995年的漢字擴充套件規範GBK1.0收錄了21886個符號,它分為漢字區和圖形符號區。漢字區包括21003個字元。2000年的GB18030是取代GBK1.0的正式國家標準。該標準收錄了27484個漢字,同時還收錄了藏文、蒙文、維吾爾文等主要的少數民族文字。現在的PC平臺必須支援GB18030,對嵌入式產品暫不作要求。所以手機、MP3一般只支援GB2312。
從ASCII、GB2312、GBK到GB18030,這些編碼方法是向下相容的,即同一個字元在這些方案中總是有相同的編碼,後面的標準支援更多的字元。在這些編碼中,英文和中文可以統一地處理。區分中文編碼的方法是高位元組的最高位不為0。按照程式設計師的稱呼,GB2312、GBK到GB18030都屬於雙位元組字符集 (DBCS)。
Unicode漢字範圍:
Unicode採用兩位元組表示,因此總共能表示65536個字元,漢字的開始編號是 19968,十六進位制表示 \u4E00,最後一個漢字的位置編號是40869,十六進位制表示 \u9FA5。[\u4E00-\u9FA5]
Unicode中每個字元的編碼都是2個位元組,包括英文字母、數字。
2 記事本下的亂碼
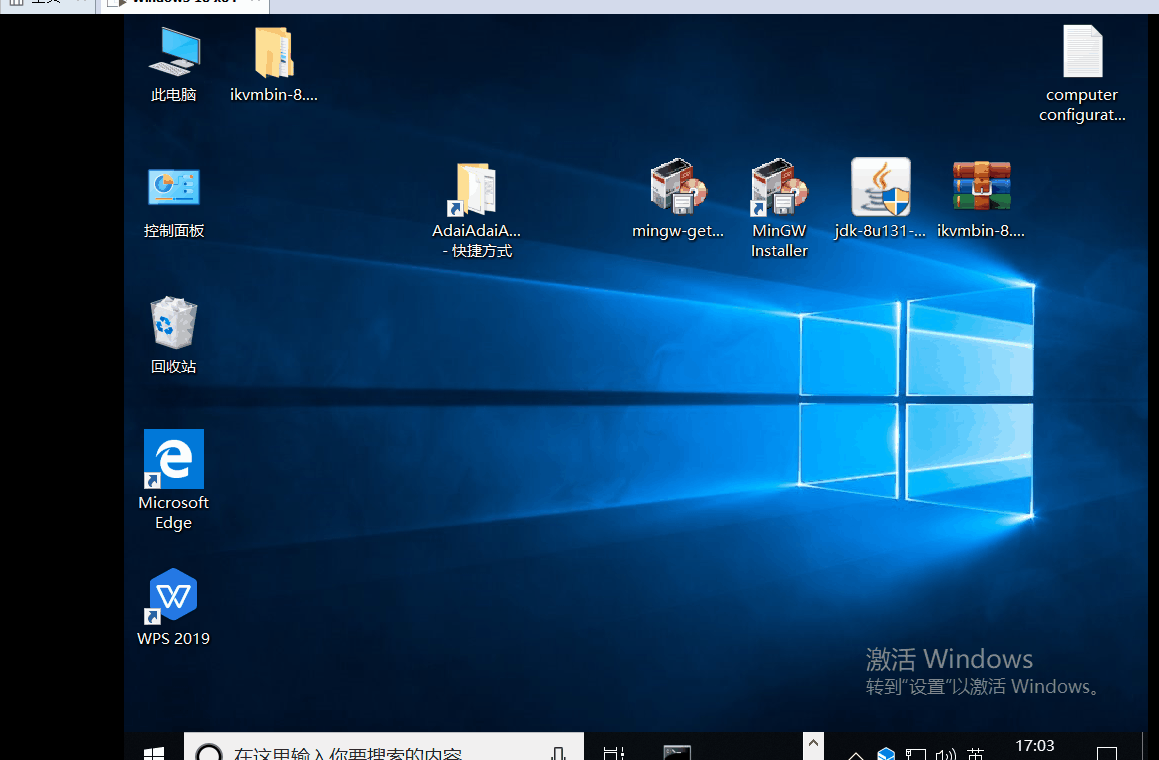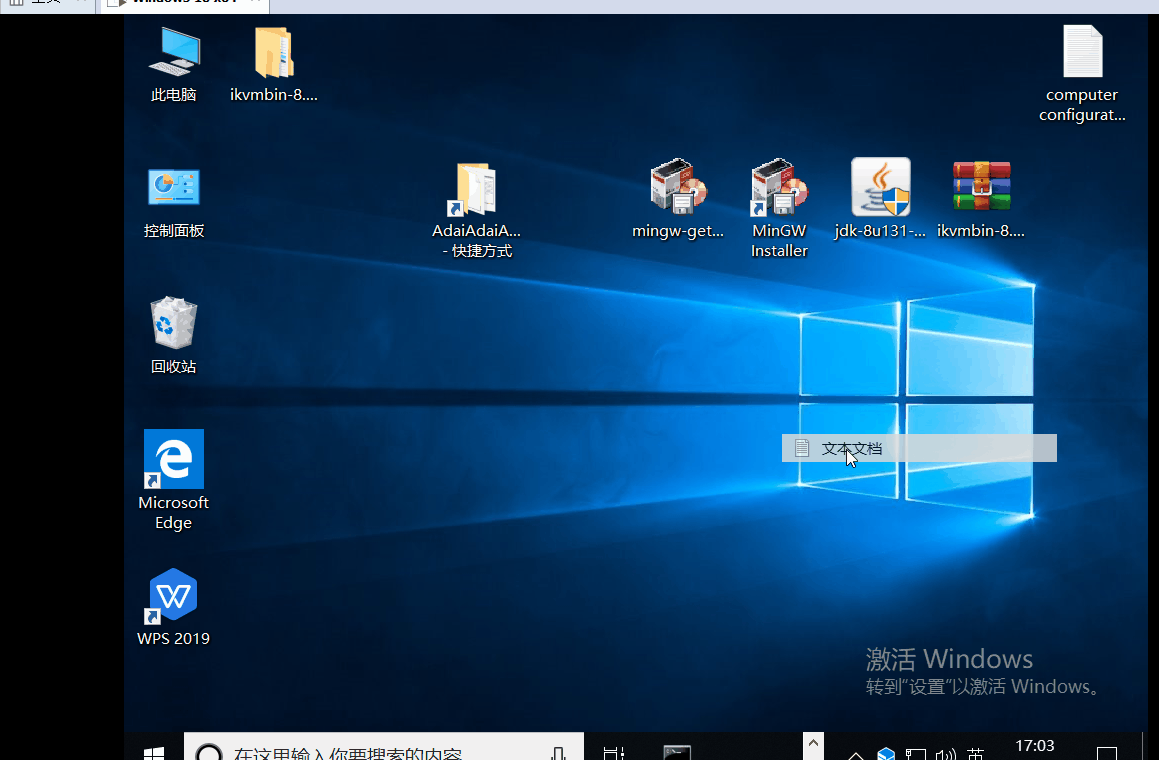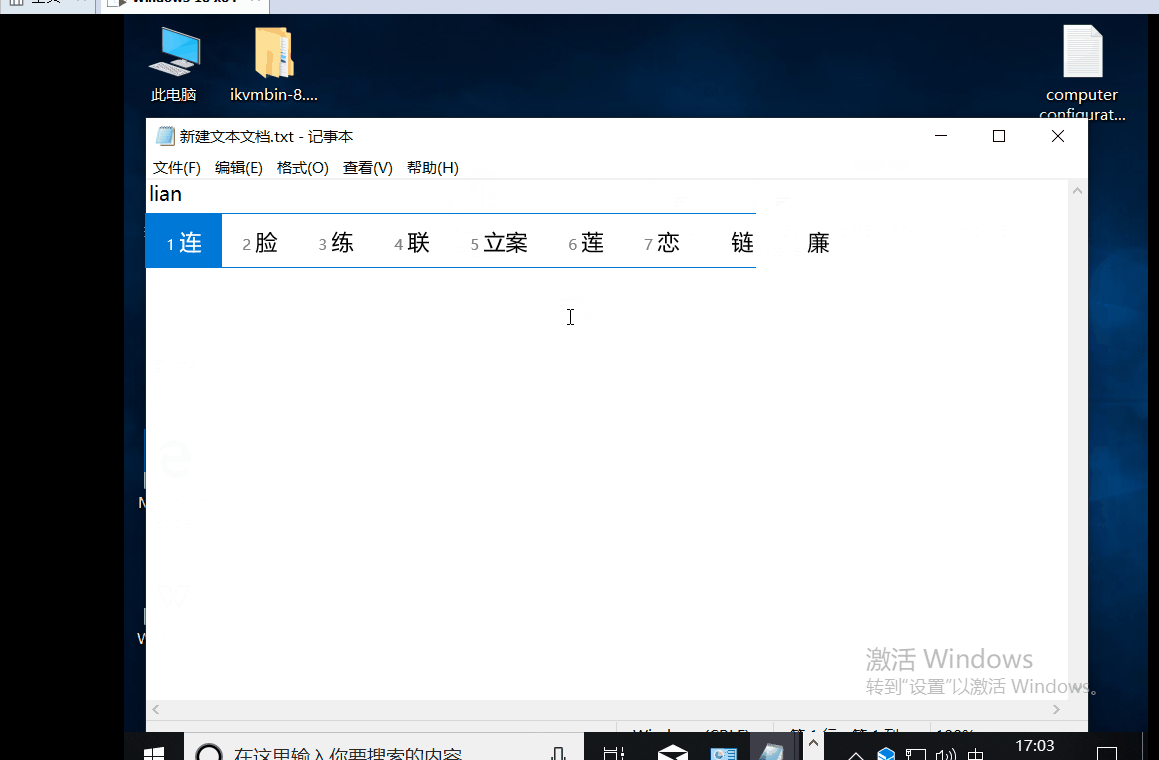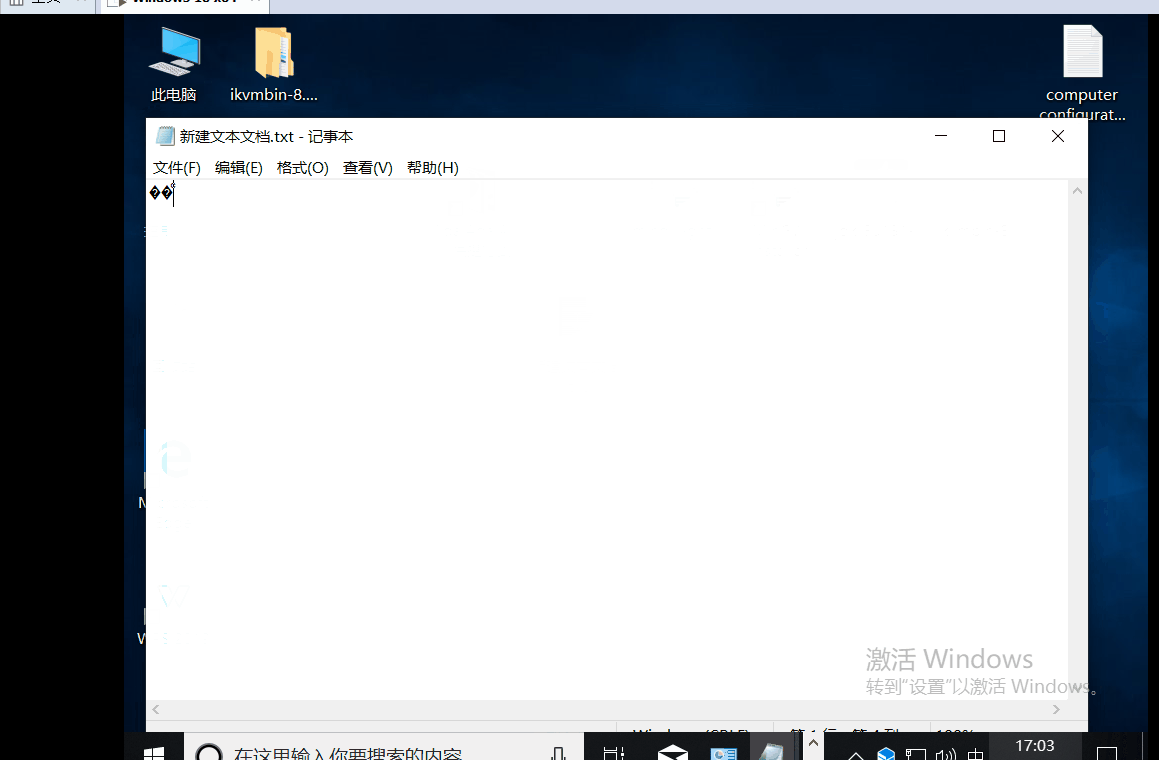
我們知道在window下記事本,輸入聯通,然後儲存再開啟,會出現亂碼情況,以前只知道是GB2312和UTF-8編碼衝撞了,並沒有認真研究底層原理,今天我們就一起來看看真正的原因是什麼。
當新建一個文字檔案的時候,記事本的編碼預設是ANSI編碼
ANSI是一種字元編碼標準,其實就是各個國家或地區的國標。對於中國地區就是GB2312編碼,中國臺灣地區就是BIG5編碼,對於日本就是JIS編碼,對於美國自然就是ASCII碼等等。
如果在ANSI的編碼輸入漢字,那麼他實際就是GB2312系列的編碼,在這種編碼下,”聯通“的十六進位制和二進位制編碼是:
C1 1100 0001
AA 1010 1010
CD 1100 1101
AB 1010 1000
如果大家不知道如何獲取指定編碼字元的二進位制,可以通過程式來處理,也可以通過文字編輯器檢視。這裡我是通過Java程式來獲取 “聯通” 在GB2312下的二進位制
public class Demo {
public static void main(String[] args) throws Exception {
String str = "聯通";
byte[] bytes = str.getBytes("GB2312");
for (byte b : bytes) {
System.out.print(Integer.toBinaryString(b) +"\r\n");
}
}
}輸出結果:
1111111111111111111111111 1000001
1111111111111111111111111 0101010
1111111111111111111111111 1001101
1111111111111111111111111 0101000
這裡要注意,因為呼叫的是Integer.toBinaryString(b),而一個int在Java中佔4個位元組,byte只佔一個位元組,所以前三個位元組全都是1,我們只用關注後面8位即可。
如果你看了 阮一峰 的部落格,那麼你現在已經知道了UTF-8的編碼規則
Unicode符號範圍 | UTF-8編碼方式
(十六進位制) | (二進位制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx !!!第一類
0000 0080-0000 07FF | 110xxxxx 10xxxxxx !!!第二類
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx記事本儲存聯通的二進位制為:
1100 0001 1010 1010
1100 1101 1010 1000
這剛好和UTF-8第二類編碼一致,所以這個時候,記事本就會誤以為該檔案應該以UTF-8編碼的方式開啟,然後就按照UTF-8的方式處理這些二進位制,因為前兩個位元組 1100 0001 1010 1010的實際有效位數是00001 101010,轉換成十六進位制是6a,但是6a卻屬於第一類,這個時候就產生亂碼了。因此,平常開發儘可能少使用txt。
3 UTF-8解碼過程
有一個UTF-8編碼的文字,文字內容如下:
aá一
分別是英文字母a,發育字母á,中文漢字一
一:獲取十六進位制編碼
通過16進位制工具,檢視16進位制編碼(我本人使用的是Sublime 外掛 hexViewer)
61 c3 a1 e4 b8 80
二:計算二進位制編碼
01100001
11000011
10100001
11100100
10111000
10000000
三:根據UTF-8編碼規則將位元組分組後:
01100001
11000011
10100001
11100100
10111000
10000000
四:重新計算,得出對應的Unicode字符集的二進位制編碼
00000000 01100001 注意在Unicode中是兩個位元組表示一個字元,因此這裡會補 00000000
00000000 11111001
01001110 00000000
五: 計算機從Unicode中查詢出字符集為
a
á
一
4 UTF-16解碼過程
aá一 這三個字元,不過這次是用UTF-16 BE儲存的,及大頭模式,如果對大頭和小頭方式不清楚的,請先看阮一峰的部落格
一:獲取十六進位制編碼
通過16進位制工具,檢視16進位制編碼(我本人使用的是Sublime 外掛 hexViewer)
fe ff 00 61 00 e1 4e 00
fe ff表示的是UTF-16 大頭模式,僅僅用於標記位元組順序,不表示具體的字元。
二:計算二進位制編碼
00000000
01100001
00000000
11100001
01001110
00000000
三:根據UTF-16編碼規則將位元組分組後:
UTF-16兩個位元組表示一個字元,即使是ASCII也是這樣。
00000000 01100001
00000000 11100001
01001110 00000000
因為Unicode定義的標準就是兩個位元組表示一個字元,而UTF-16具體實現剛好就是用兩個位元組表示一個字元,因此這裡就不需要再進行處理了
四:計算機從Unicode中查詢出字符集為
a
á
一
Unicode將世界上的文字和二進位制一一對應起來,並規定2個位元組表示一個字元。
但是沒有規定這個二進位制程式碼應該如何儲存,並且在網路上如何傳輸。
而UTF-8和UTF-16定義了這些二進位制程式碼應該如何儲存,並且在網路上如何傳輸。不過最後,程式都會按照UTF-8和UTF-16的規則去解析這些二進位制,然後轉換成Unicode,然後再通過一一對應,查詢到該字元。
無論是UTF-8還是UTF-16編碼的字元,最後轉換成Unicode字元的二進位制都是一樣的,因為他們遵循同一個Unicode標準。
5 ISO-8859-1
以前開發JSP的時候,預設就是ISO-8859-1編碼。
ASCII只能表示128個字元,而一個位元組能夠表示256種字元,ASCII編碼浪費了一個位元組接近一半的空間。
所以ISO-8859-1擴充套件了ASCII編碼,在ASCII編碼之上又增加了西歐語言、希臘語、泰語、阿拉伯語、希伯來語對應的文字元號,它是向下相容ASCII編碼的。
因為ISO-8859-1編碼範圍使用了單位元組內的所有空間,在支援ISO-8859-1的系統中傳輸和儲存其他任何編碼的位元組流都不會被拋棄。換言之,把其他任何編碼的位元組流當作ISO-8859-1編碼看待都沒有問題。這是個很重要的特性,MySQL資料庫預設編碼是Latin1就是利用了這個特性。ASCII編碼是一個7位的容器,ISO-8859-1編碼是一個8位的容器。
6 byte範圍
在整理字元研究的時候,發現一個問題
public class Demo {
public static void main(String[] args) throws Exception {
String str = "聯通";
byte[] bytes = str.getBytes("GB2312");
for (byte b : bytes) {
System.out.println(b);
}
}
}輸出:
-63
-86
-51
-88
剛開始的時候,不是很理解為什麼Java程式會輸出負值。想了一下,忽然想起在Java中
byte範圍 -128-127
而bytes中儲存的二進位制是
1100 0001
1010 1010
1100 1101
1010 1000
最高位的1,Java中的byte無法處理,只能當做符號位,以補碼儲存。
參考資料:
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://pcedu.pconline.com.cn/empolder/gj/other/0505/616631_all.html#content_page_2
作者:一杯熱咖啡AAA出處:https://www.cnblogs.com/AdaiCoffee/
本文以學習、研究和分享為主,歡迎轉載。如果文中有不妥或者錯誤的地方還望指出,以免誤人子弟。如果你有更好的想法和意見,可以留言討論,謝謝