
zookeeper叢集執行原理簡單解析
ZooKeeper與客戶端
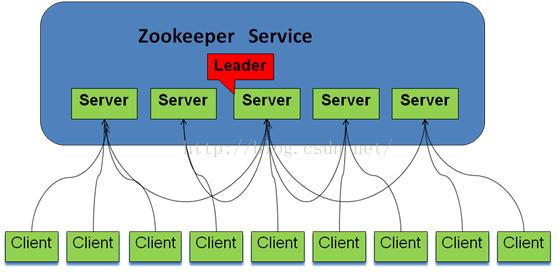
每個Server在工作過程中有三種狀態:
LOOKING:當前Server不知道leader是誰,正在搜尋
LEADING:當前Server即為選舉出來的leader
FOLLOWING:leader已經選舉出來,當前Server與之同步
Zookeeper節點資料操作流程
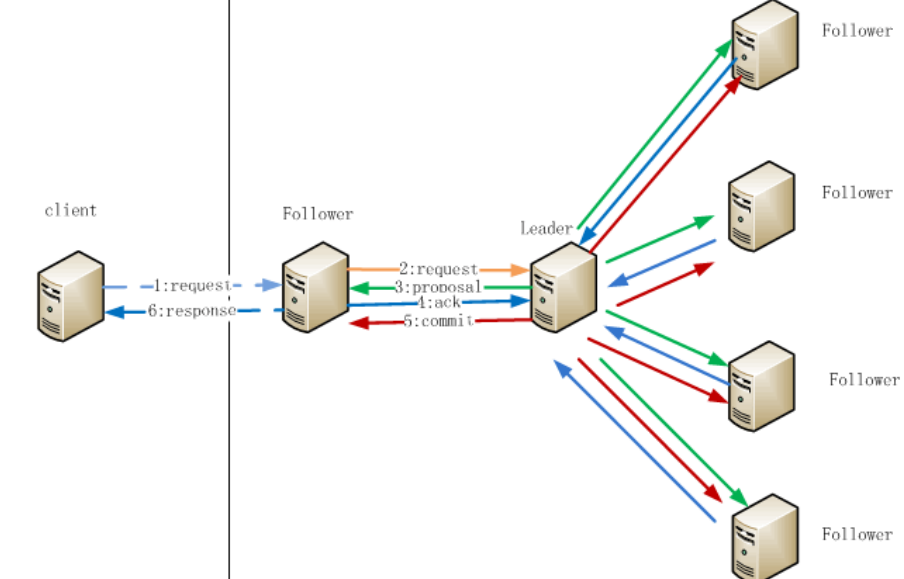
注:
1.在Client向Follwer發出一個寫的請求
2.Follwer把請求傳送給Leader
3.Leader接收到以後開始發起投票並通知Follwer進行投票
4.Follwer把投票結果傳送給Leader
5.Leader將結果彙總後如果需要寫入,則開始寫入同時把寫入操作通知給Leader,然後commit;
6.Follwer把請求結果返回給Client
Follower主要有四個功能:
1. 向Leader傳送請求(PING訊息、REQUEST訊息、ACK訊息、REVALIDATE訊息);
2 .接收Leader訊息並進行處理;
3 .接收Client的請求,如果為寫請求,傳送給Leader進行投票;
4 .返回Client結果。
Follower的訊息迴圈處理如下幾種來自Leader的訊息:
1 .PING訊息: 心跳訊息;
2 .PROPOSAL訊息:Leader發起的提案,要求Follower投票;
3 .COMMIT訊息:伺服器端最新一次提案的資訊;
4 .UPTODATE訊息:表明同步完成;
5 .REVALIDATE訊息:根據Leader的REVALIDATE結果,關閉待revalidate的session還是允許其接受訊息;
6 .SYNC訊息:返回SYNC結果到客戶端,這個訊息最初由客戶端發起,用來強制得到最新的更新。
Paxos 演算法概述(ZAB 協議)
Paxos 演算法是萊斯利•蘭伯特(英語:Leslie Lamport)於 1990 年提出的一種基於訊息傳遞且 具有高度容錯特性的一致性演算法。
分散式系統中的節點通訊存在兩種模型:共享記憶體(Shared memory)和訊息傳遞(Messages passing)
Paxos 演算法使用一個希臘故事來描述,在 Paxos 中,存在三種角色,分別為
Proposer(提議者,用來發出提案 proposal)
Acceptor(接受者,可以接受或拒絕提案)
Learner(學習者,學習被選定的提案,當提案被超過半數的 Acceptor 接受後為被批准)
下面更精確的定義 Paxos 要解決的問題:
1、決議(value)只有在被 proposer 提出後才能被批准
2、在一次 Paxos 演算法的執行例項中,只批准(chose)一個 value
3、learner 只能獲得被批准(chosen)的 value
ZooKeeper 的選舉演算法有兩種:一種是基於 Basic Paxos(Google Chubby 採用)實現的,另外 一種是基於 Fast Paxos(ZooKeeper 採用)演算法實現的。系統預設的選舉演算法為 Fast Paxos。 並且 ZooKeeper 在 3.4.0 版本後只保留了 FastLeaderElection 演算法。
ZooKeeper 的核心是原子廣播,這個機制保證了各個 Server 之間的同步。實現這個機制的協 議叫做 ZAB 協議(Zookeeper Atomic BrodCast)。 ZAB 協議有兩種模式,它們分別是崩潰恢復模式(選主)和原子廣播模式(同步)。
1、當服務啟動或者在領導者崩潰後,ZAB 就進入了恢復模式,當領導者被選舉出來,且大 多數 Server 完成了和 leader 的狀態同步以後,恢復模式就結束了。狀態同步保證了 leader 和 follower 之間具有相同的系統狀態。
2、當 ZooKeeper 叢集選舉出 leader 同步完狀態退出恢復模式之後,便進入了原子廣播模式。 所有的寫請求都被轉發給 leader,再由 leader 將更新 proposal 廣播給 follower
為了保證事務的順序一致性,zookeeper 採用了遞增的事務 id 號(zxid)來標識事務。所有 的提議(proposal)都在被提出的時候加上了 zxid。實現中 zxid 是一個 64 位的數字,它高 32 位是 epoch 用來標識 leader 關係是否改變,每次一個 leader 被選出來,它都會有一個新 的 epoch,標識當前屬於那個 leader 的統治時期。低 32 位用於遞增計數。
這裡給大家介紹以下 Basic Paxos 流程:
1、選舉執行緒由當前 Server 發起選舉的執行緒擔任,其主要功能是對投票結果進行統計,並選 出推薦的 Server
2、選舉執行緒首先向所有 Server 發起一次詢問(包括自己)
3、選舉執行緒收到回覆後,驗證是否是自己發起的詢問(驗證 zxid 是否一致),然後獲取對方 的 serverid(myid),並存儲到當前詢問物件列表中,最後獲取對方提議的 leader 相關資訊 (serverid,zxid),並將這些資訊儲存到當次選舉的投票記錄表中
4、收到所有 Server 回覆以後,就計算出 id 最大的那個 Server,並將這個 Server 相關資訊設 置成下一次要投票的 Server
5、執行緒將當前 id 最大的 Server 設定為當前 Server 要推薦的 Leader,如果此時獲勝的 Server 獲得 n/2 + 1 的 Server 票數, 設定當前推薦的 leader 為獲勝的 Server,將根據獲勝的 Server 相關資訊設定自己的狀態,否則,繼續這個過程,直到 leader 被選舉出來。
通過流程分析我們可以得出:要使 Leader 獲得多數 Server 的支援,則 Server 總數必須是奇 數 2n+1,且存活的 Server 的數目不得少於 n+1。 每個 Server 啟動後都會重複以上流程。在恢復模式下,如果是剛從崩潰狀態恢復的或者剛 啟動的 server 還會從磁碟快照中恢復資料和會話資訊,zk 會記錄事務日誌並定期進行快照, 方便在恢復時進行狀態恢復。 Fast Paxos 流程是在選舉過程中,某 Server 首先向所有 Server 提議自己要成為 leader,當其 它 Server 收到提議以後,解決 epoch 和 zxid 的衝突,並接受對方的提議,然後向對方傳送 接受提議完成的訊息,重複這個流程,最後一定能選舉出 Leader
ZooKeeper 的選主機制
選擇機制中的概念
伺服器ID
比如有三臺伺服器,編號分別是1,2,3。
編號越大在選擇演算法中的權重越大。
資料ID
伺服器中存放的最大資料ID.
值越大說明資料越新,在選舉演算法中資料越新權重越大。
邏輯時鐘
或者叫投票的次數,同一輪投票過程中的邏輯時鐘值是相同的。每投完一次票這個資料就會增加,然後與接收到的其它伺服器返回的投票資訊中的數值相比,根據不同的值做出不同的判斷。
選舉狀態
- LOOKING,競選狀態。
- FOLLOWING,隨從狀態,同步leader狀態,參與投票。
- OBSERVING,觀察狀態,同步leader狀態,不參與投票。
- LEADING,領導者狀態。
選舉訊息內容
在投票完成後,需要將投票資訊傳送給叢集中的所有伺服器,它包含如下內容。
- 伺服器ID
- 資料ID
- 邏輯時鐘
- 選舉狀態
選舉流程圖
因為每個伺服器都是獨立的,在啟動時均從初始狀態開始參與選舉,下面是簡易流程圖。
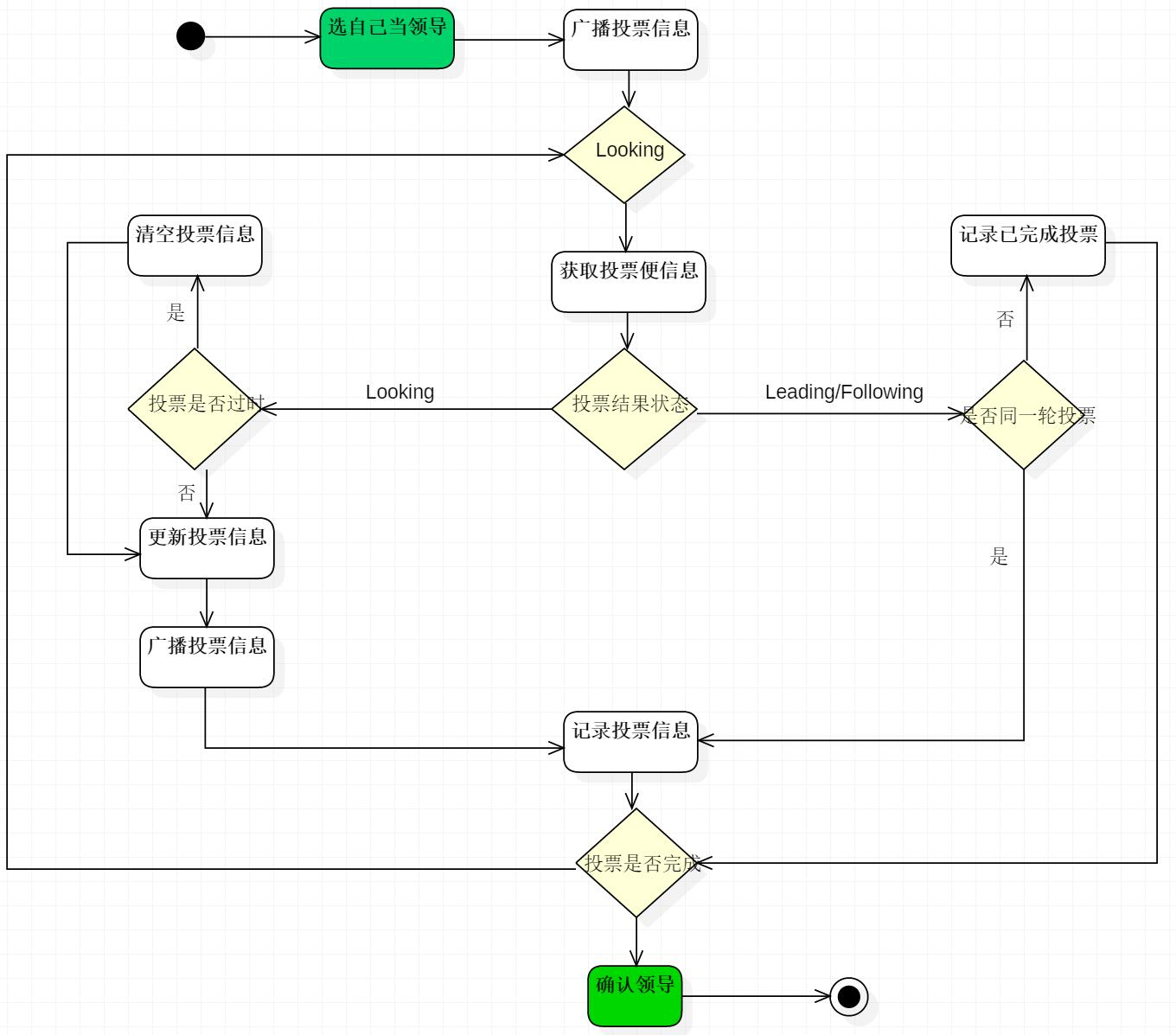
ZooKeeper 的全新叢集選主
以一個簡單的例子來說明整個選舉的過程:假設有五臺伺服器組成的 zookeeper 叢集,它們 的 serverid 從 1-5,同時它們都是最新啟動的,也就是沒有歷史資料,在存放資料量這一點 上,都是一樣的。假設這些伺服器依序啟動,來看看會發生什麼
1、伺服器 1 啟動,此時只有它一臺伺服器啟動了,它發出去的報沒有任何響應,所以它的 選舉狀態一直是 LOOKING 狀態
2、伺服器 2 啟動,它與最開始啟動的伺服器 1 進行通訊,互相交換自己的選舉結果,由於 兩者都沒有歷史資料,所以 id 值較大的伺服器 2 勝出,但是由於沒有達到超過半數以上的伺服器都同意選舉它(這個例子中的半數以上是 3),所以伺服器 1、2 還是繼續保持 LOOKING 狀態
3、伺服器 3 啟動,根據前面的理論分析,伺服器 3 成為伺服器 1,2,3 中的老大,而與上面不 同的是,此時有三臺伺服器(超過半數)選舉了它,所以它成為了這次選舉的 leader
4、伺服器 4 啟動,根據前面的分析,理論上伺服器 4 應該是伺服器 1,2,3,4 中最大的,但是 由於前面已經有半數以上的伺服器選舉了伺服器 3,所以它只能接收當小弟的命了
5、伺服器 5 啟動,同 4 一樣,當小弟
ZooKeeper 的非全新叢集選主
那麼,初始化的時候,是按照上述的說明進行選舉的,但是當 zookeeper 運行了一段時間之 後,有機器 down 掉,重新選舉時,選舉過程就相對複雜了。
需要加入資料 version、serverid 和邏輯時鐘。
資料 version:資料新的 version 就大,資料每次更新都會更新 version
server id:就是我們配置的 myid 中的值,每個機器一個
邏輯時鐘:這個值從 0 開始遞增,每次選舉對應一個值,也就是說:如果在同一次選舉中, 那麼這個值應該是一致的;邏輯時鐘值越大,說明這一次選舉 leader 的程序更新,也就是 每次選舉擁有一個 zxid,投票結果只取 zxid 最新的
選舉的標準就變成:
1、邏輯時鐘小的選舉結果被忽略,重新投票
2、統一邏輯時鐘後,資料 version 大的勝出
3、資料 version 相同的情況下,server id 大的勝出
根據這個