
mysql執行過程以及順序
前言:mysql在我們的開發中基本每天都要面對的,作為開發中的資料的來源,mysql承擔者儲存資料和讀寫資料的職責。因為學習和了解mysql是至關重要的,那麼當我們在客戶端發起一個sql到出現詳細的查詢資料,這其中究竟經歷了什麼樣的過程?mysql服務端是如何處理請求的,又是如何執行sql語句的?本篇部落格將來探討這個問題:
本篇部落格的目錄
一:mysql執行過程
二:mysql執行過程中的狀態
三:mysql執行的順序
四:總結
一:mysql執行過程
mysql整體的執行過程如下圖所示:
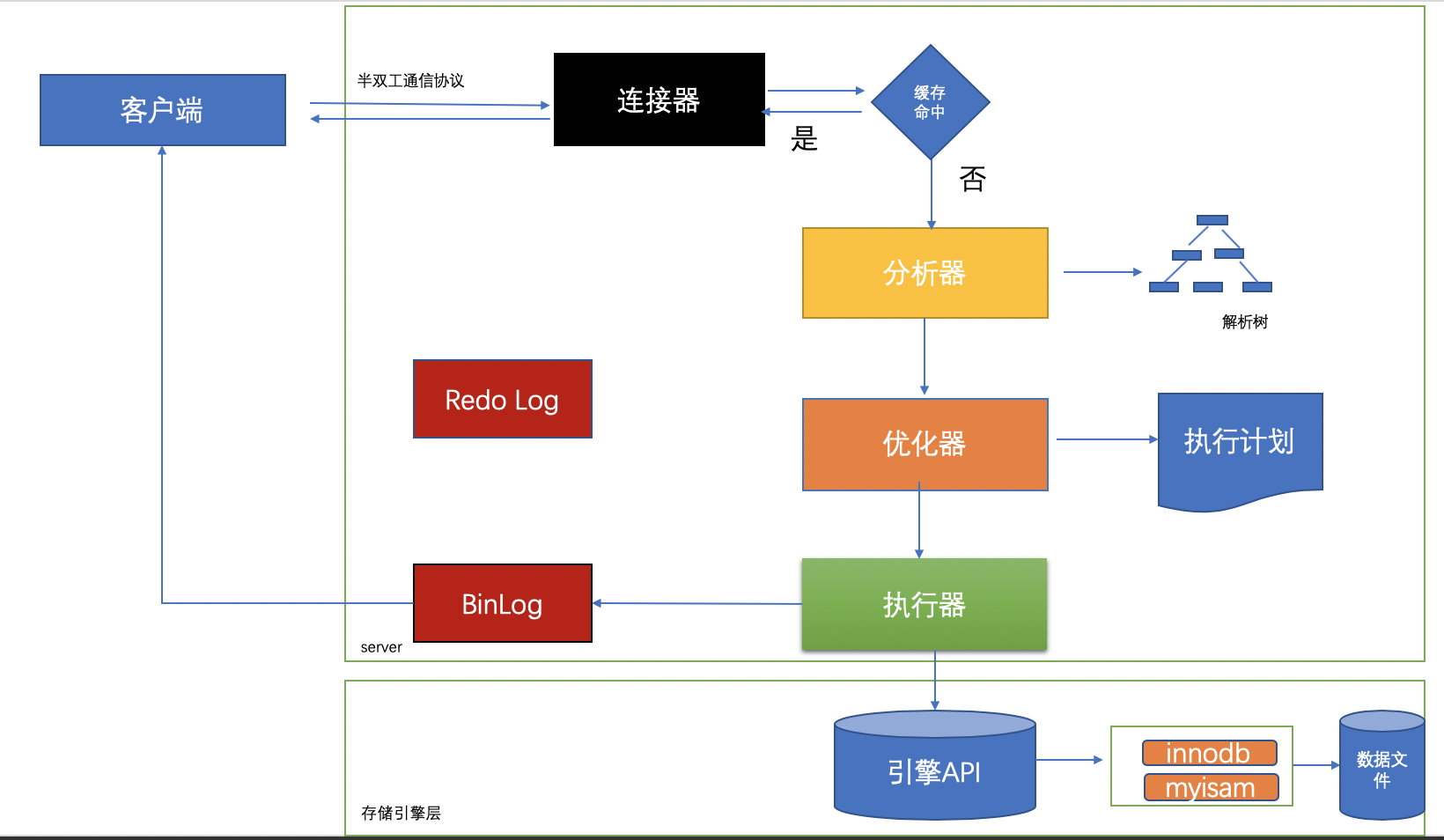
1.1:聯結器
聯結器的主要職責就是:
①負責與客戶端的通訊,是半雙工模式,這就意味著某一固定時刻只能由客戶端向伺服器請求或者伺服器向客戶端傳送資料,而不能同時進行,其中mysql在與客戶端連線TC/IP的
②驗證請求使用者的賬戶和密碼是否正確,如果賬戶和密碼錯誤,會報錯:Access denied for user 'root'@'localhost' (using password: YES)
③如果使用者的賬戶和密碼驗證通過,會在mysql自帶的許可權表中查詢當前使用者的許可權:
mysql中存在4個控制權限的表,分別為user表,db表,tables_priv表,columns_priv表,mysql許可權表的驗證過程為:
1:User表:存放使用者賬戶資訊以及全域性級別(所有資料庫)許可權,決定了來自哪些主機的哪些使用者可以訪問資料庫例項
Db表:存放資料庫級別的許可權,決定了來自哪些主機的哪些使用者可以訪問此資料庫
Tables_priv表:存放表級別的許可權
Columns_priv表:
存放列級別的許可權,決定了來自哪些主機的哪些使用者可以訪問資料庫表的這個欄位 Procs_priv表:
存放儲存過程和函式級別的許可權
2:先從user表中的Host,User,Password這3個欄位中判斷連線的ip、使用者名稱、密碼是否存在,存在則通過驗證。
3:通過身份認證後,進行許可權分配,按照user,db,tables_priv,columns_priv的順序進行驗證。即先檢查全域性許可權表user,如果user中對應的許可權為Y,則此使用者對所有資料庫的許可權都為Y,將不再檢查db, tables_priv,columns_priv;如果為N,則到db表中檢查此使用者對應的具體資料庫,並得到db中為Y的許可權;如果db中為N,則檢查tables_priv中此資料庫對應的具體表,取得表中的許可權Y,以此類推
4:如果在任何一個過程中許可權驗證不通過,都會報錯
1.2:快取
mysql的快取主要的作用是為了提升查詢的效率,快取以key和value的雜湊表形式儲存,key是具體的sql語句,value是結果的集合。如果無法命中快取,就繼續走到分析器的的一步,如果命中快取就直接返回給客戶端 。不過需要注意的是在mysql的8.0版本以後,快取被官方刪除掉了。之所以刪除掉,是因為查詢快取的失效非常頻繁,如果在一個寫多讀少的環境中,快取會頻繁的新增和失效。對於某些更新壓力大的資料庫來說,查詢快取的命中率會非常低,mysql為了維護快取可能會出現一定的伸縮性的問題,目前在5.6的版本中已經預設關閉了,比較推薦的一種做法是將快取放在客戶端,效能大概會提升5倍左右
1.3:分析器
分析器的主要作用是將客戶端發過來的sql語句進行分析,這將包括預處理與解析過程,在這個階段會解析sql語句的語義,並進行關鍵詞和非關鍵詞進行提取、解析,並組成一個解析樹。具體的關鍵詞包括不限定於以下:select/update/delete/or/in/where/group by/having/count/limit等.如果分析到語法錯誤,會直接給客戶端丟擲異常:ERROR:You have an error in your SQL syntax.
比如:select * from user where userId =1234;
在分析器中就通過語義規則器將select from where這些關鍵詞提取和匹配出來,mysql會自動判斷關鍵詞和非關鍵詞,將使用者的匹配欄位和自定義語句識別出來。這個階段也會做一些校驗:比如校驗當前資料庫是否存在user表,同時假如User表中不存在userId這個欄位同樣會報錯:unknown column in field list.
1.4:優化器
能夠進入到優化器階段表示sql是符合mysql的標準語義規則的並且可以執行的,此階段主要是進行sql語句的優化,會根據執行計劃進行最優的選擇,匹配合適的索引,選擇最佳的執行方案。比如一個典型的例子是這樣的:
表T,對A、B、C列建立聯合索引,在進行查詢的時候,當sql查詢到的結果是:select xx where B=x and A=x and C=x.很多人會以為是用不到索引的,但其實會用到,雖然索引必須符合最左原則才能使用,但是本質上,優化器會自動將這條sql優化為:where A=x and B=x and C=X,這種優化會為了底層能夠匹配到索引,同時在這個階段是自動按照執行計劃進行預處理,mysql會計算各個執行方法的最佳時間,最終確定一條執行的sql交給最後的執行器
1.5:執行器
在執行器的階段,此時會呼叫儲存引擎的API,API會呼叫儲存引擎,主要有一下儲存的引擎,不過常用的還是myisam和innodb:

引擎以前的名字叫做:表處理器(其實這個名字我覺得更能表達它存在的意義)負責對具體的資料檔案進行操作,對sql的語義比如select或者update進行分析,執行具體的操作。在執行完以後會將具體的操作記錄到binlog中,需要注意的一點是:select不會記錄到binlog中,只有update/delete/insert才會記錄到binlog中。而update會採用兩階段提交的方式,記錄都redolog中
二:執行的狀態
可以通過命令:show full processlist,展示所有的處理程序,主要包含了以下的狀態,表示伺服器處理客戶端的狀態,狀態包含了從客戶端發起請求到後臺伺服器處理的過程,包括加鎖的過程、統計儲存引擎的資訊,排序資料、搜尋中間表、傳送資料等。囊括了所有的mysql的所有狀態,其中具體的含義如下圖:

三:sql的執行順序
事實上,sql並不是按照我們的書寫順序來從前往後、左往右依次執行的,它是按照固定的順序解析的,主要的作用就是從上一個階段的執行返回結果來提供給下一階段使用,sql在執行的過程中會有不同的臨時中間表,一般是按照如下順序:

例子: select distinct s.id from T t join S s on t.id=s.id where t.name="Yrion" group by t.mobile having count(*)>2 order by s.create_time limit 5;
3.1:from
第一步就是選擇出from關鍵詞後面跟的表,這也是sql執行的第一步:表示要從資料庫中執行哪張表。
例項說明:在這個例子中就是首先從資料庫中找到表T
3.2:join on
join是表示要關聯的表,on是連線的條件。通過from和join on選擇出需要執行的資料庫表T和S,產生笛卡爾積,生成T和S合併的臨時中間表Temp1。on:確定表的繫結關係,通過on產生臨時中間表Temp2.
例項說明:找到表S,生成臨時中間表Temp1,然後找到表T的id和S的id相同的部分組成成表Temp2,Temp2裡面包含著T和Sid相等的所有資料
3.3:where
where表示篩選,根據where後面的條件進行過濾,按照指定的欄位的值(如果有and連線符會進行聯合篩選)從臨時中間表Temp2中篩選需要的資料,注意如果在此階段找不到資料,會直接返回客戶端,不會往下進行.這個過程會生成一個臨時中間表Temp3。注意在where中不可以使用聚合函式,聚合函式主要是(min\max\count\sum等函式)
例項說明:在temp2臨時表集合中找到T表的name="Yrion"的資料,找到資料後會成臨時中間表Temp3,temp3裡包含name列為"Yrion"的所有表資料
3.4:group by
group by是進行分組,對where條件過濾後的臨時表Temp3按照固定的欄位進行分組,產生臨時中間表Temp4,這個過程只是資料的順序發生改變,而資料總量不會變化,表中的資料以組的形式存在
例項說明:在temp3表資料中對mobile進行分組,查找出mobile一樣的資料,然後放到一起,產生temp4臨時表。
3.5:Having
對臨時中間表Temp4進行聚合,這裡可以為count等計數,然後產生中間表Temp5,在此階段可以使用select中的別名
例項說明:在temp4臨時表中找出條數大於2的資料,如果小於2直接被捨棄掉,然後生成臨時中間表temp5
3.6:select
對分組聚合完的表挑選出需要查詢的資料,如果為*會解析為所有資料,此時會產生中間表Temp6
例項說明:在此階段就是對temp5臨時聚合表中S表中的id進行篩選產生Temp6,此時temp6就只包含有s表的id列資料,並且name="Yrion",通過mobile分組數量大於2的資料
3.7:Distinct
distinct對所有的資料進行去重,此時如果有min、max函式會執行欄位函式計算,然後產生臨時表Temp7
例項說明:此階段對temp5中的資料進行去重,引擎API會呼叫去重函式進行資料的過濾,最終只保留id第一次出現的那條資料,然後產生臨時中間表temp7
3.8:order by
會根據Temp7進行順序排列或者逆序排列,然後插入臨時中間表Temp8,這個過程比較耗費資源
例項說明:這段會將所有temp7臨時表中的資料按照建立時間(create_time)進行排序,這個過程也不會有列或者行損失
3.9:limit
limit對中間表Temp8進行分頁,產生臨時中間表Temp9,返回給客戶端。
例項說明:在temp7中排好序的資料,然後取前五條插入到Temp9這個臨時表中,最終返回給客戶端
ps:實際上這個過程也並不是絕對這樣的,中間mysql會有部分的優化以達到最佳的優化效果,比如在select篩選出找到的資料集
四:總結
本篇部落格總結了mysql的執行過程,以及sql的執行順序,理解這些有助於我們對sql語句進行優化,以及明白mysql中的sql語句從寫出來到最終執行的軌跡,有助於我們對sql有比較深入和細緻的理解,提高我們的資料庫理解能力。同時,對於複雜sql的執行過程、編寫都會有一定程度的意義。
&n