
JindoFS:雲原生的大資料計算儲存分離方案
JindoFS:雲原生的大資料計算儲存分離方案
JindoFS 之前
在 JindoFS 之前,雲上客戶主要使用 HDFS 和 OSS/S3 作為大資料儲存。HDFS 是 Hadoop 原生的儲存系統,10 年來,HDFS 已經成為大資料生態的儲存標準,但是我們也可以看到 HDFS 雖然不斷優化,但是 JVM 的瓶頸也始終無法突破,社群後來重新設計了 OZone。OSS/S3 作為雲上物件儲存的代表,也在大資料生態進行了適配,但是由於物件儲存設計上的特點,元資料相關操作無法達到 HDFS 一樣的效率;物件儲存給客戶的頻寬不斷增加,但是也是有限的,一些時候較難完全滿足使用者大資料使用上的需求。
Jindo 的由來
EMR Jindo 是阿里雲基於 Apache Spark / Apache Hadoop 在雲上定製的分散式計算和儲存引擎。Jindo 原是內部的研發代號,取自筋斗(雲)的諧音,EMR Jindo 在開源基礎上做了大量優化和擴充套件,深度整合和連線了眾多阿里雲基礎服務。阿里雲 EMR (E-MapReduce) 在 TPC 官方提交的 TPCDS 成績,也是使用 Jindo 提交的。
http://www.tpc.org/tpcds/results/tpcds_perf_results.asp?resulttype=all
JindoFS
EMR Jindo 有計算和儲存兩大部分,儲存的部分叫 JindoFS。JindoFS 是阿里雲針對雲上儲存定製的自研大資料儲存服務,完全相容 Hadoop 檔案系統介面,給客戶帶來更加靈活、高效的計算儲存方案,目前已驗證支援阿里雲 EMR 中所有的計算服務和引擎:Spark、Flink、Hive、MapReduce、Presto、Impala 等。Jindo FS 有兩種使用模式,塊儲存模式和快取模式。下面我們來分析下,JindoFS 是如何來解決大資料上的儲存問題的。
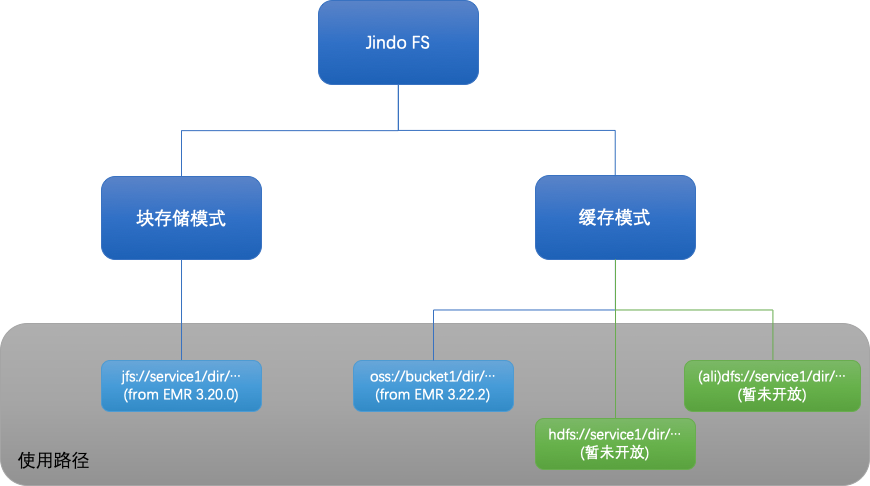
塊儲存模式
計算和儲存分離是業界的趨勢,OSS 這樣的雲上儲存能力是無限大的,成本上非常有優勢,如何利用 OSS 提供的無限儲存能力,同時又高效地操作檔案系統的元資料。JindoFS 塊儲存模式提供了一套完整的雲原生解決方案。

JindoFS 的塊儲存模式,在元資料上使用 JindoNameService 服務管理 Jindo 檔案系統元資料,元資料操作的效能和體驗上可以對標 HDFS NameNode。同時,JindoStorageService 保障了資料可以始終有一份存在 OSS 上,即使資料節點被釋放,資料也可以隨時從 OSS 上拉取,成本上也可以做到更加靈活。
JindoFS 的塊儲存模式,也支援多種儲存策略,比如,本地存兩份,OSS上存一份;本地存兩份,OSS上不儲存;本地不存,OSS上存一份等等。使用者可以充分利用不同的儲存策略根據業務或者資料冷熱進行使用。
塊儲存使用了全新的 jfs:// 格式,原始 HDFS/OSS 資料通過 distcp 方式即可完成資料匯入,同時,JindoFS 提供了 SDK,在 EMR 叢集外部,使用者也可以讀寫 Jindo FS。
快取模式
快取模式,正如“快取”本身的含義,通過快取的方式,在本地叢集基於 JindoFS 的儲存能力構建了一個分散式快取服務,遠端的資料可以儲存在本地叢集,使遠端資料變成“本地化”。簡單地描述 JindoFS 快取模式解決的問題
就是“OSS / 遠端HDFS 已經有了大量資料,每次讀資料的時候網路頻寬經常被打滿,Jindo FS 就可以通過快取模式優化網路頻寬的限制。”
“原來的檔案路徑是 oss://bucket1/file1 或 hdfs://namenode/file2,不想改作業的路徑可以嗎?”。是的,不需要修改。EMR 對 OSS 進行了適配(後續會支援遠端 HDFS 的場景),可以通過配置的方式使用快取模式。快取對於上層的作業做到了完全無感。
但是快取模式也不是萬能的,為了保證多端資料一致性,rename 這種操作一定要同步重新整理到遠端的 OSS / HDFS,特別是 OSS 的Rename 操作比較耗時,快取模式對 rename這種檔案元資料操作暫時不能優化。
總結
在 2019 年的雲棲大會上,EMR Jindo 的技術儲存分離方案得到很大的關注,後續我們也會在雲棲社群和釘釘群分享更多的 Jindo 技術乾貨,歡迎有興趣的同學加入 《Apache Spark技術交流社群》進行交流和技術分享。
本文為雲棲社群原創內容,未經