
Apache Flink : Checkpoint 原理剖析與應用實踐
Checkpoint 與 state 的關係
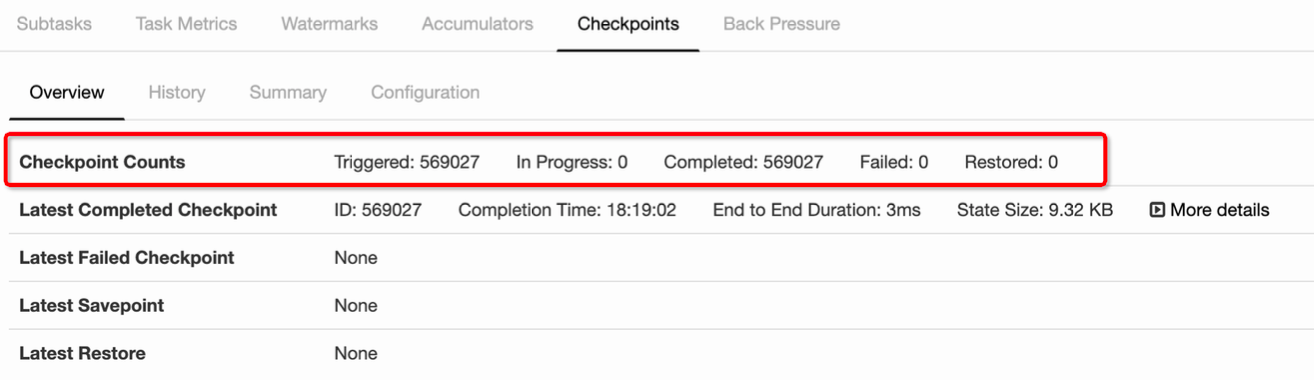
Checkpoint 是從 source 觸發到下游所有節點完成的一次全域性操作。下圖可以有一個對 Checkpoint 的直觀感受,紅框裡面可以看到一共觸發了 569K 次 Checkpoint,然後全部都成功完成,沒有 fail 的。
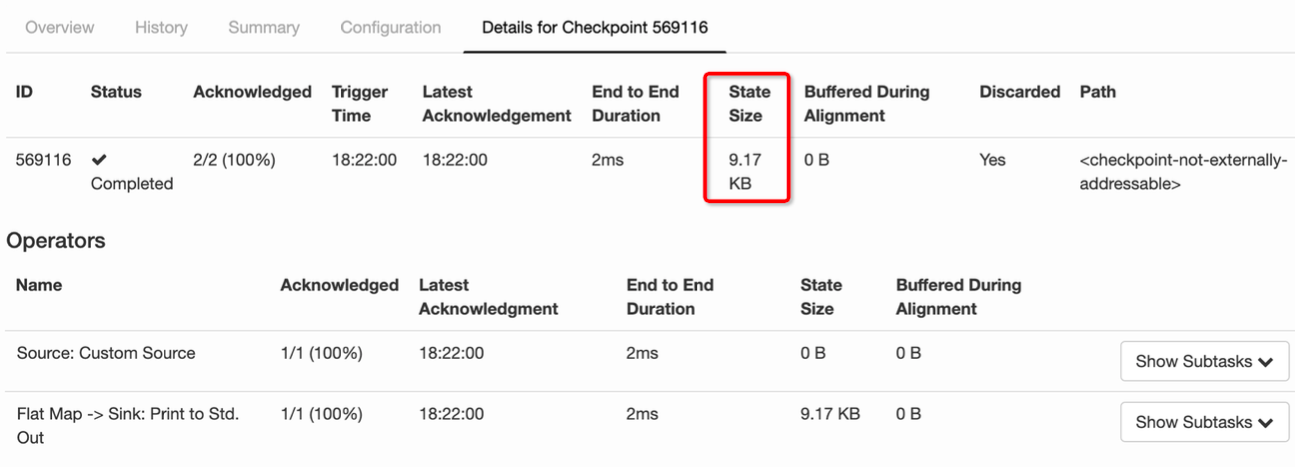
state 其實就是 Checkpoint 所做的主要持久化備份的主要資料,看下圖的具體資料統計,其 state 也就 9kb 大小 。
什麼是 state
我們接下來看什麼是 state。先看一個非常經典的 word count 程式碼,這段程式碼會去監控本地的 9000 埠的資料並對網路埠輸入進行詞頻統計,我們本地行動 netcat,然後在終端輸入 hello world,執行程式會輸出什麼?
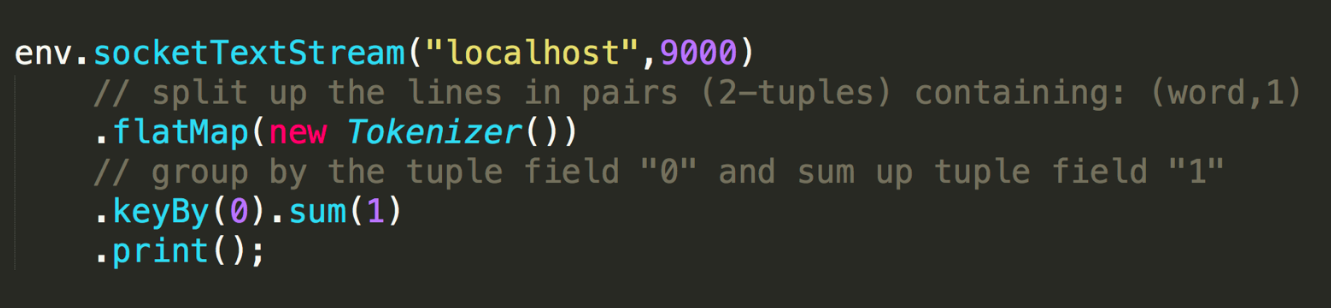
答案很明顯,(hello, 1) 和 (word,1)
那麼問題來了,如果再次在終端輸入 hello world,程式會輸入什麼?
答案其實也很明顯,(hello, 2) 和 (world, 2)。為什麼 Flink 知道之前已經處理過一次 hello world,這就是 state 發揮作用了,這裡是被稱為 keyed state 儲存了之前需要統計的資料,所以幫助 Flink 知道 hello 和 world 分別出現過一次。
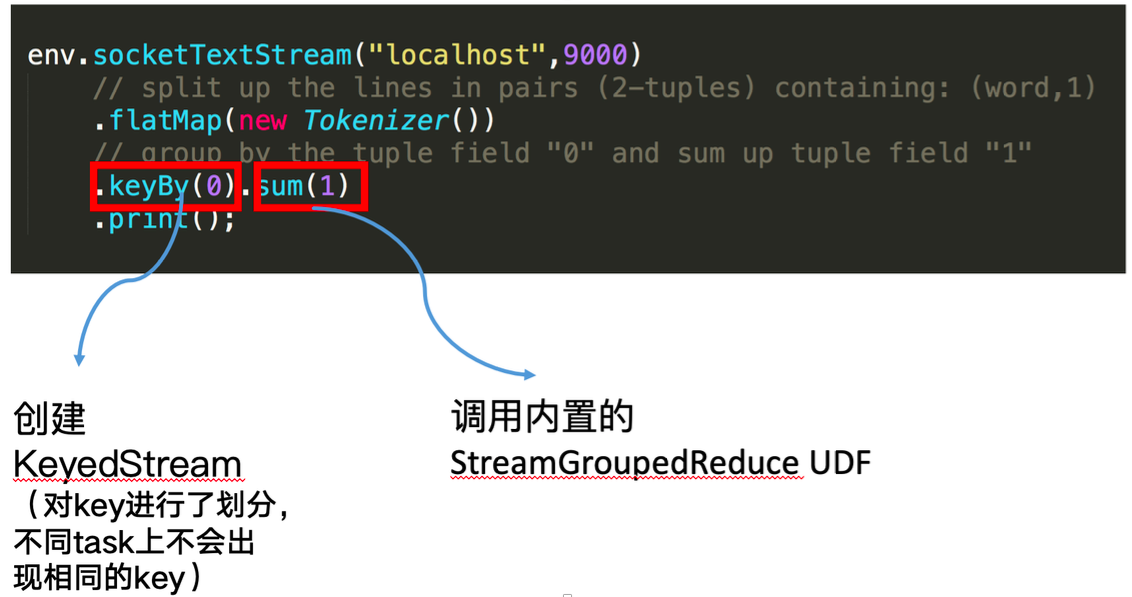
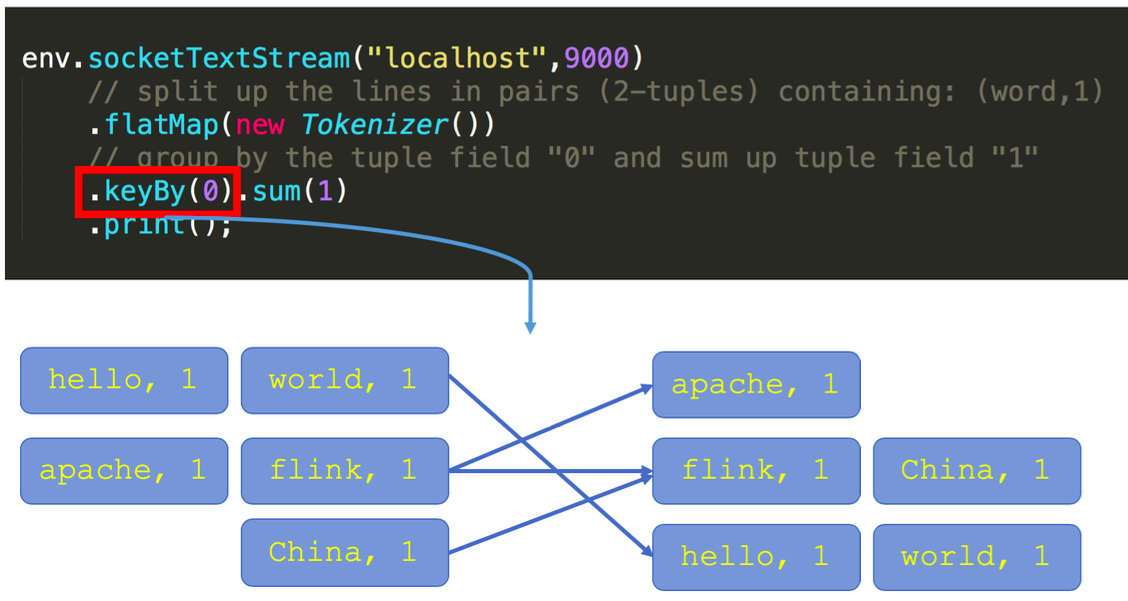
回顧一下剛才這段 word count 程式碼。keyby 介面的呼叫會建立 keyed stream 對 key 進行劃分,這是使用 keyed state 的前提。在此之後,sum 方法會呼叫內建的 StreamGroupedReduce 實現。
什麼是 keyed state
對於 keyed state,有兩個特點:
- 只能應用於 KeyedStream 的函式與操作中,例如 Keyed UDF, window state
- keyed state 是已經分割槽 / 劃分好的,每一個 key 只能屬於某一個 keyed state
對於如何理解已經分割槽的概念,我們需要看一下 keyby 的語義,大家可以看到下圖左邊有三個併發,右邊也是三個併發,左邊的詞進來之後,通過 keyby 會進行相應的分發。例如對於 hello word,hello 這個詞通過 hash 運算永遠只會到右下方併發的 task 上面去。
什麼是 operator state
- 又稱為 non-keyed state,每一個 operator state 都僅與一個 operator 的例項繫結。
- 常見的 operator state 是 source state,例如記錄當前 source 的 offset
再看一段使用 operator state 的 word count 程式碼:
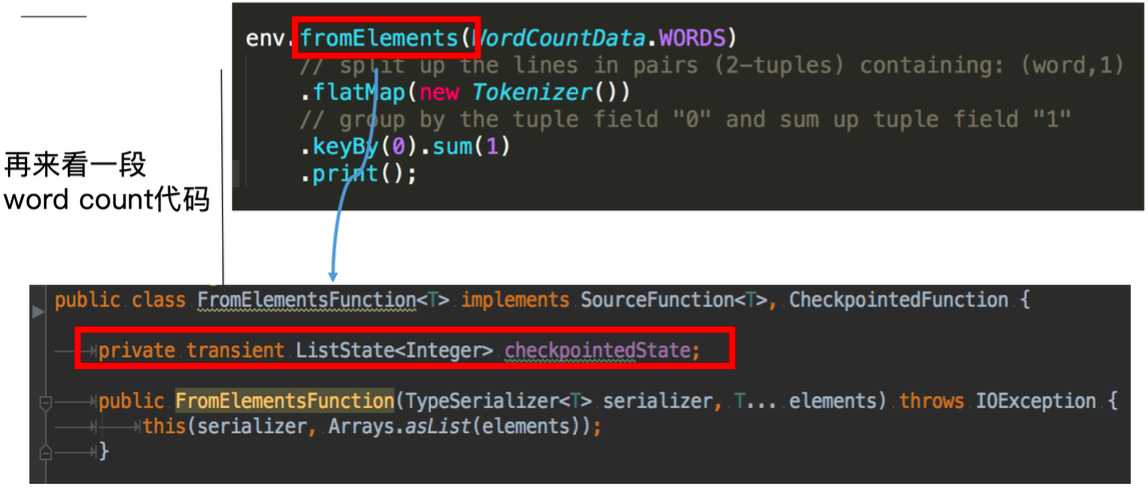
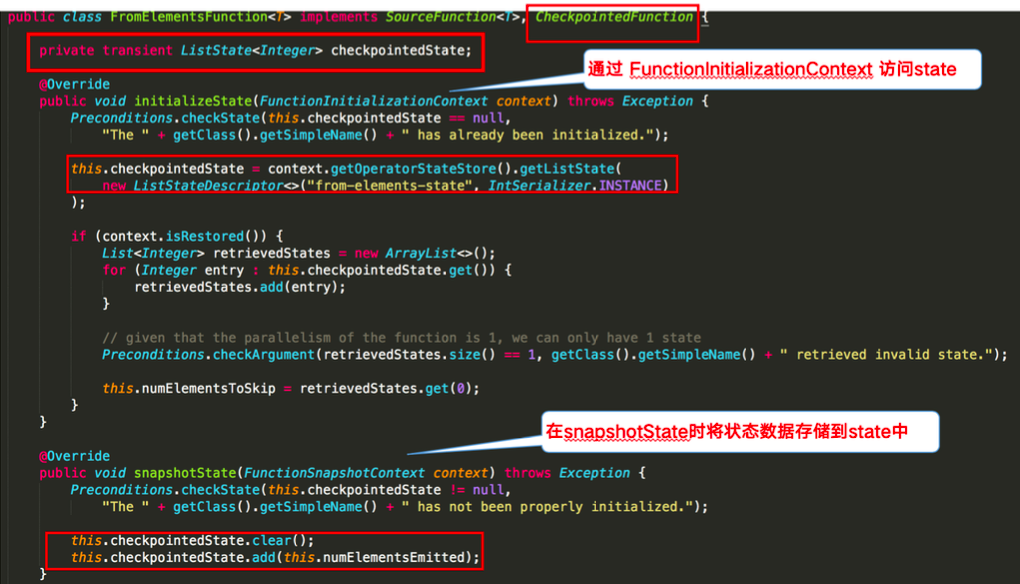
這裡的fromElements會呼叫FromElementsFunction的類,其中就使用了型別為 list state 的 operator state。根據 state 型別做一個分類如下圖:
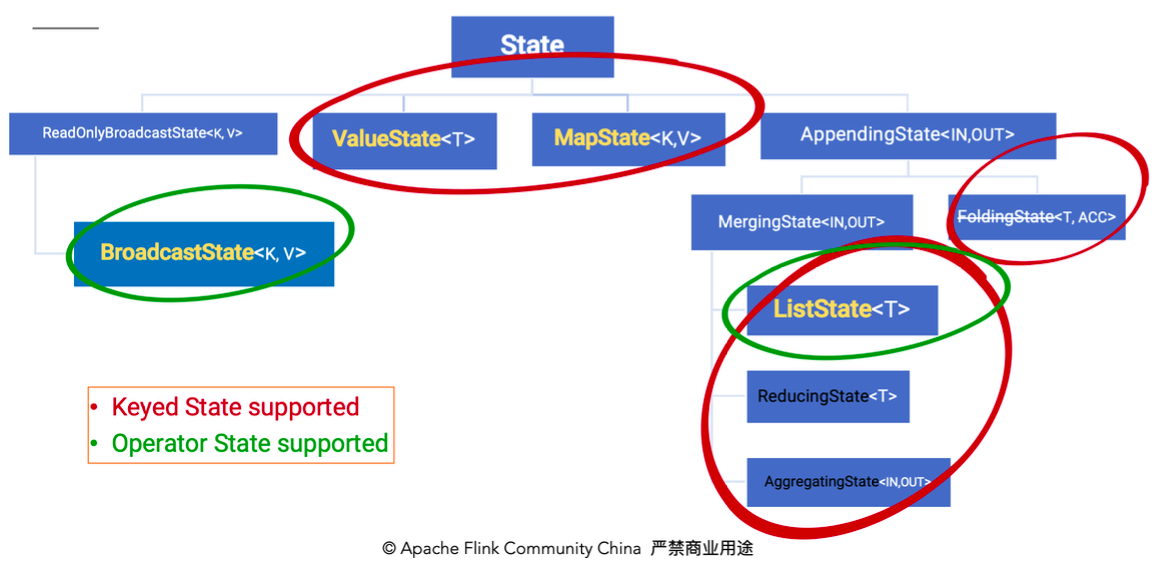
除了從這種分類的角度,還有一種分類的角度是從 Flink 是否直接接管:
- Managed State:由 Flink 管理的 state,剛才舉例的所有 state 均是 managed state
- Raw State:Flink 僅提供 stream 可以進行儲存資料,對 Flink 而言 raw state 只是一些 bytes
在實際生產中,都只推薦使用 managed state,本文將圍繞該話題進行討論。
如何在 Flink 中使用 state
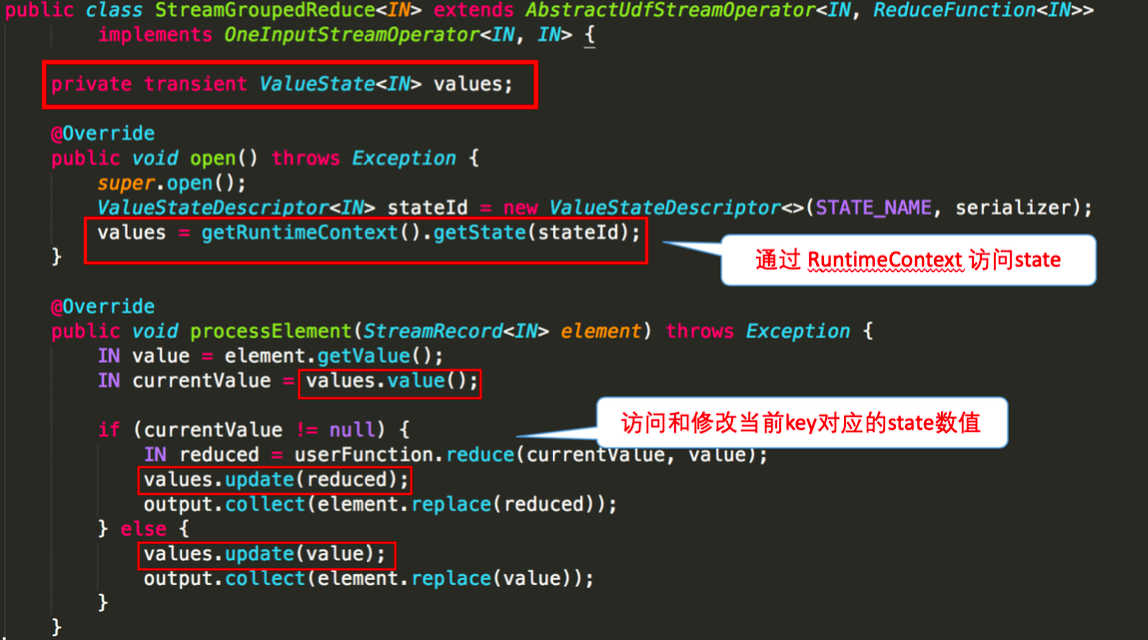
下圖就前文 word count 的 sum 所使用的StreamGroupedReduce類為例講解了如何在程式碼中使用 keyed state:
下圖則對 word count 示例中的FromElementsFunction類進行詳解並分享如何在程式碼中使用 operator state:
Checkpoint 的執行機制
在介紹 Checkpoint 的執行機制前,我們需要了解一下 state 的儲存,因為 state 是 Checkpoint 進行持久化備份的主要角色。
Statebackend 的分類
下圖闡釋了目前 Flink 內建的三類 state backend,其中MemoryStateBackend和FsStateBackend在執行時都是儲存在 java heap 中的,只有在執行 Checkpoint 時,FsStateBackend才會將資料以檔案格式持久化到遠端儲存上。而RocksDBStateBackend則借用了 RocksDB(記憶體磁碟混合的 LSM DB)對 state 進行儲存。

對於HeapKeyedStateBackend,有兩種實現:
- 支援非同步 Checkpoint(預設):儲存格式 CopyOnWriteStateMap
- 僅支援同步 Checkpoint:儲存格式 NestedStateMap
特別在 MemoryStateBackend 內使用HeapKeyedStateBackend時,Checkpoint 序列化資料階段預設有最大 5 MB 資料的限制
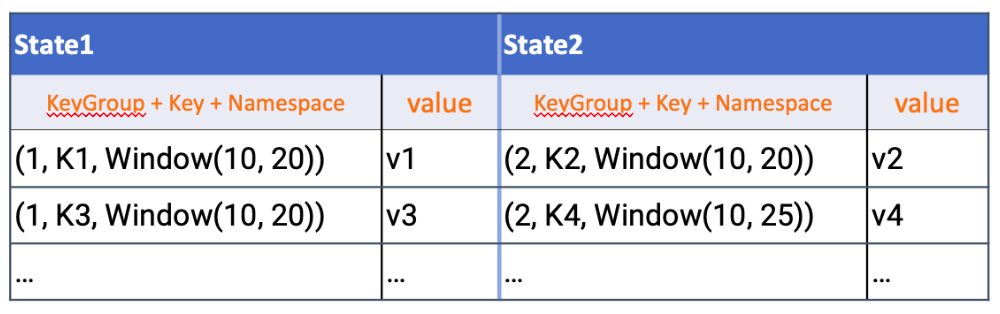
對於RocksDBKeyedStateBackend,每個 state 都儲存在一個單獨的 column family 內,其中 keyGroup,Key 和 Namespace 進行序列化儲存在 DB 作為 key。
Checkpoint 執行機制詳解
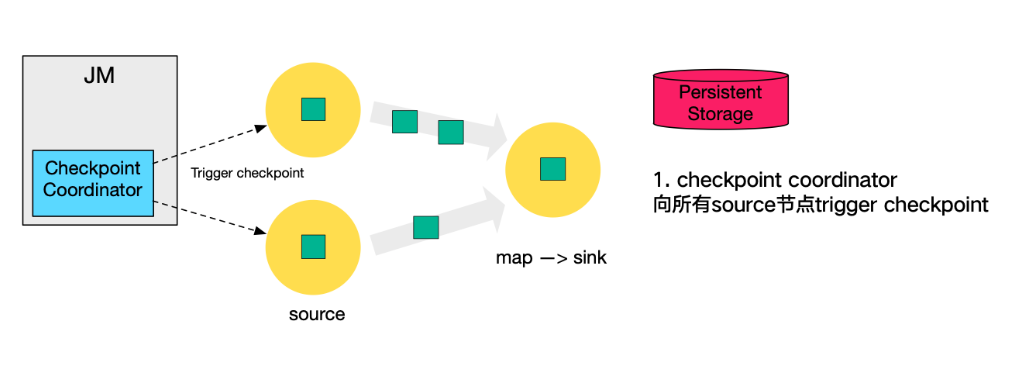
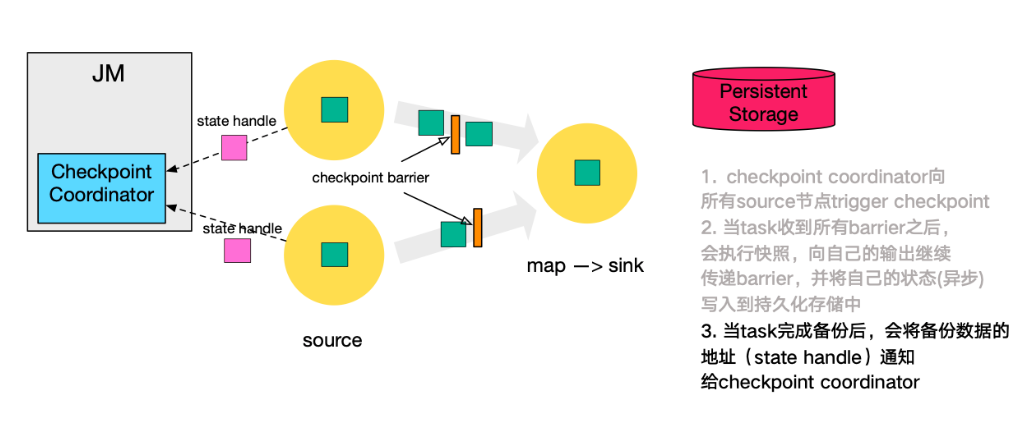
本小節將對 Checkpoint 的執行流程逐步拆解進行講解,下圖左側是 Checkpoint Coordinator,是整個 Checkpoint 的發起者,中間是由兩個 source,一個 sink 組成的 Flink 作業,最右側的是持久化儲存,在大部分使用者場景中對應 HDFS。
- 第一步,Checkpoint Coordinator 向所有 source 節點 trigger Checkpoint;。
- 第二步,source 節點向下遊廣播 barrier,這個 barrier 就是實現 Chandy-Lamport 分散式快照演算法的核心,下游的 task 只有收到所有 input 的 barrier 才會執行相應的 Checkpoint。
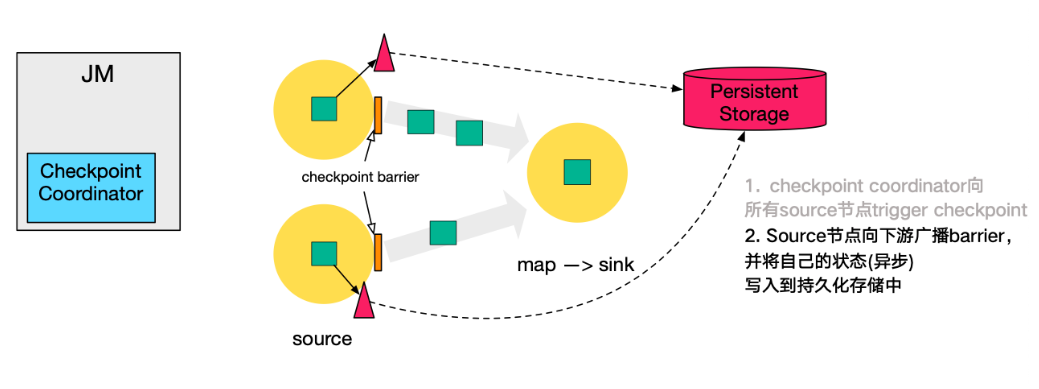
- 第三步,當 task 完成 state 備份後,會將備份資料的地址(state handle)通知給 Checkpoint coordinator。
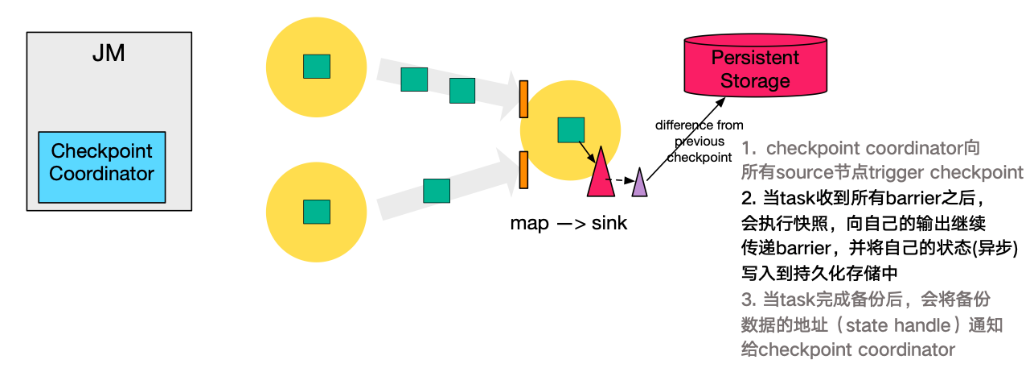
- 第四步,下游的 sink 節點收集齊上游兩個 input 的 barrier 之後,會執行本地快照,這裡特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 會全量刷資料到磁碟上(紅色大三角表示),然後 Flink 框架會從中選擇沒有上傳的檔案進行持久化備份(紫色小三角)。
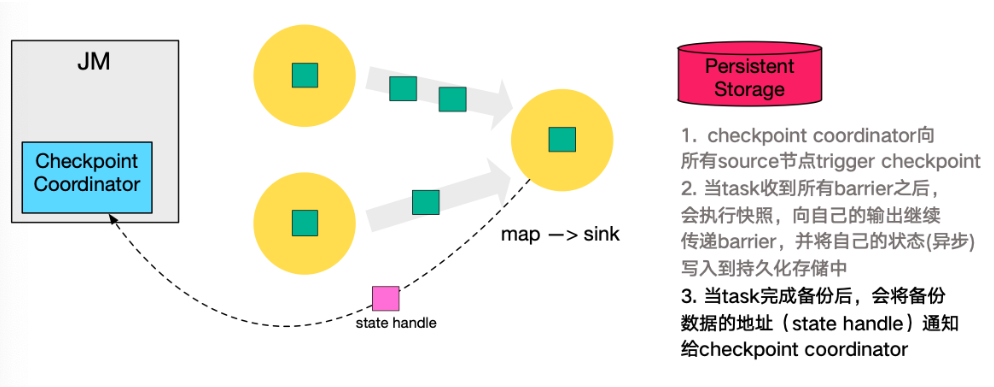
- 同樣的,sink 節點在完成自己的 Checkpoint 之後,會將 state handle 返回通知 Coordinator。
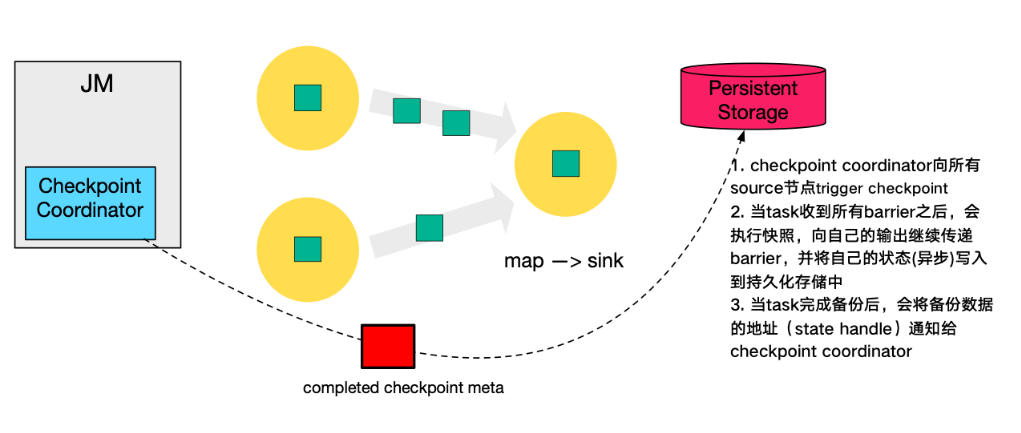
- 最後,當 Checkpoint coordinator 收集齊所有 task 的 state handle,就認為這一次的 Checkpoint 全域性完成了,向持久化儲存中再備份一個 Checkpoint meta 檔案。
Checkpoint 的 EXACTLY_ONCE 語義
為了實現 EXACTLY ONCE 語義,Flink 通過一個 input buffer 將在對齊階段收到的資料快取起來,等對齊完成之後再進行處理。而對於 AT LEAST ONCE 語義,無需快取收集到的資料,會對後續直接處理,所以導致 restore 時,資料可能會被多次處理。下圖是官網文件裡面就 Checkpoint align 的示意圖:
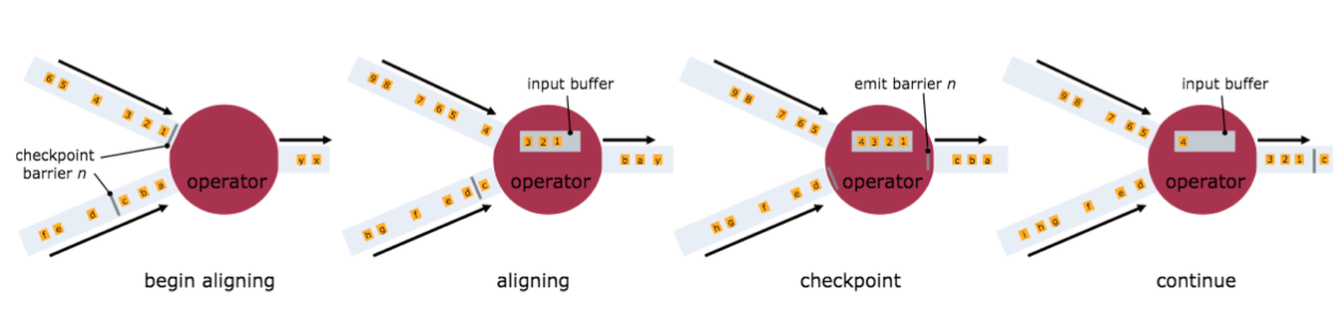
需要特別注意的是,Flink 的 Checkpoint 機制只能保證 Flink 的計算過程可以做到 EXACTLY ONCE,端到端的 EXACTLY ONCE 需要 source 和 sink 支援。
Savepoint 與 Checkpoint 的區別
作業恢復時,二者均可以使用,主要區別如下:
| Savepoint | Externalized |
|---|---|
| 使用者通過命令觸發,由使用者管理其建立與刪除 | Checkpoint 完成時,在使用者給定的外部持久化儲存儲存 |
| 標準化格式儲存,允許作業升級或者配置變更 | 當作業 FAILED(或者 CANCELED)時,外部儲存的 Checkpoint 會保留下來 |
| 使用者在恢復時需要提供用於恢復作業狀態的 savepoint 路徑 | 使用者在恢復時需要提供用於恢復的作業狀態的 Checkpoint 路徑 |
本文為雲棲社群原創內容,未經