
【實戰】 elasticsearch 寫入速度提升的案例分享
- 文章首發投稿至InfoQ,【俠夢的開發筆記】公眾號,歡迎關注
- https://www.infoq.cn/article/t7b52mbzxqkwrrdpVqD2
基本配置
- 基本配置,5臺配置為 24C 125G 17T 的主機,每臺主機上搭建了一個elasticsearch節點。
採用的elasticsearch叢集版本為7.1.1。管理工具包括kibana和cerebro。
應用案例
- 資料來源為kafka的三個topic,主要用於實時日誌資料的儲存和檢索,由於實時性要求,所以需要將資料快速的寫入到es中。
這裡就分別稱它們為TopicA、TopicB、TopicC吧。由於是調優寫入,所以對源資料的一些基本的指標需要作出一個詳細的梳理,便於後續分析。以下為三個topic的資料產生情況:
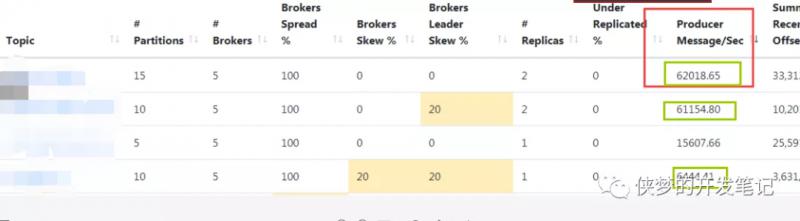
規劃
| Topic | 報文大小 | 資料量預估(天) | es索引分片數規劃 |
|---|---|---|---|
| topicA | 900b | 2T | 30個主分片 |
| topicB | 800b | 400G | 10個主分片 |
| topicC | 750b | 300G | 10個主分片 |
問題重現
- 未做任何配置的情況下,分別使用java和logstash進行資料抽取,發現效率都不高,具體問題表現在:
- 1、kafka資料積壓嚴重,消費跟不上生產的速度。
- 2、elasticsearch叢集負載很高,大量寫入被拒絕。
- 3、java程式頻繁丟擲RejectionException異常。
- 4、主機cpu異常的高。
作業系統層面及JVM的配置調整這裡不再闡述,有很多關於此類的文章可以參考。
我們分模組對各個部分進行調整,具體細節如下:
寫入程式優化
從定數到定量
- 使用的java程式中,我們將固定條數插入改為固定大小插入,由於使用的es版本較高,直接替換成了官方推薦的BulkProcessor方式。具體指定屬性如下:
# 每2w條執行一次bulk插入
bulkActions: 20000
# 資料量達到15M後執行bulk插入
bulkSizeMb: 15
# 無論資料量多少,間隔20s執行一次bulk
flushInterval: 20
# 允許併發的bulk請求數
concurrentRequests: 10- 這裡的具體配置值,可以根據觀察叢集狀態,來逐步增加。對於高版本的es,可以通過x-pack的監控頁面觀察索引速度進行相應調整,如果es版本較低,可以使用推薦的rest api進行邏輯封裝。
在低版本的es中,統計寫入速度的思路是:寫一個程式定時檢查索引的資料量,來計算。如果使用python,就兩行程式碼就能獲取索引的資料總量。
call_list = es.indices.stats(index=index)
total = call_list['indices'][index]['total']['indexing']['index_total']。也可以隔幾分鐘用CURL來粗略統計單個索引的資料量大小。命令如下:
查詢索引文件總量
curl -XGET -uname:pwd
'http://esip:port/_cat/count/index-name?v&format=json&pretty'###### 啟動多個程序
- 由於Bulkprocess是執行緒安全的,所以我們可以使用多執行緒的方式來共享一個批處理器。更好的消費方式是,啟動多個消費程式程序,將其部署在不同的主機上,讓多個程序中開啟的多執行緒總數和topic的分割槽數相等,並且將他們設定為同一個消費組。每一個程序包含一個bulkprocess,可以提高消費和批量寫入能力。同時可以避免單點問題,假如一個消費者程序掛掉,則kafka叢集會重新平衡分割槽的消費者。少了消費者只是會影響消費速度,並不影響資料的處理。
###### “壓測”,提升批量插入條數
- 通過對各個監控指標的觀察,來判斷是否能繼續提高寫入條數或增加執行緒數,從而達到最大吞吐量。
###### 一、觀察叢集負載Load Average值
- 負載值,一定程度上代表了CPU的繁忙程度,那我們如何來解讀elasticsearch 監控頁面的的負載值呢?如下是一個三個節點的叢集,從左側cerebo提供的介面來看,load值標紅,表明es的負載可能有點高了,那麼這個具體達到什麼值會顯示紅色呢,讓我們一起來研究研究。
- 先從主機層面說起,linux下提供了一個uptime命令來觀察主機的負載
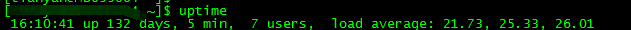
- 其中load average的三個值,分別代表主機在1分鐘、5分鐘、15分鐘內的一個負載情況。有人可能會疑惑,26.01是代表主機的負載在26%的意思嗎,從我們跑的es叢集情況來看,這顯然不是負載很低的表現。其實啊,在單個cpu的情況下,這個值是可以看做一個百分比的,比如負載為0.05,表明目前系統的負荷為5%。但我們的伺服器一般都是多個處理器,每個處理器內部會包含多個cpu核心,所以這裡負載顯示的值,是和cpu的核心數有關的,如果非要用百分比來表示系統負荷的話,可以用具體的負載值 除以 伺服器的總核心數,觀察是否大於1。總核心數檢視的命令為:
cat /proc/cpuinfo |grep -c 'model name'- 這臺主機顯示為24,從26的負載來看,目前處理的任務需要排隊了,這就是為什麼負載標紅的原因。同時,這裡列舉一下,如何檢視CPU情況
總邏輯CPU數 = 物理CPU個數 X 每顆物理CPU的核數 X 超執行緒數
# 物理CPU個數(我們的伺服器是2個)
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 檢視每個物理CPU中core的個數(就是核數)(6核)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 檢視邏輯CPU的個數
cat /proc/cpuinfo| grep "processor"| wc -l
(顯示24,不等於上面的cpu個數 * 每個cpu的核數,說明是開啟了超執行緒)###### 二、觀察叢集在 "忙什麼"
- 通過tasks api可以直觀的 觀察到叢集在忙什麼?,包括父級任務,任務的持續時間等指標。命令如下:
curl -u username:pwd ip:port/_cat/tasks/?v | more
- 上面是我把副本設定為0後截的圖。理論上還應該有一個bulk[s][r] 操作。可以看到目前寫入很耗時,正常情況一批bulk操作應該是毫秒級的,這也從側面說明了es的負載很高。
從task_id、parent_task_id可以看出,一個bulk操作下面分為寫主分片的動作 和寫副本的動作。其中:
indices:data/write/bulk[s][p]:s表示分片,p表示主分片。
indices:data/write/bulk[s][r]:s表示分片,r表示副本。
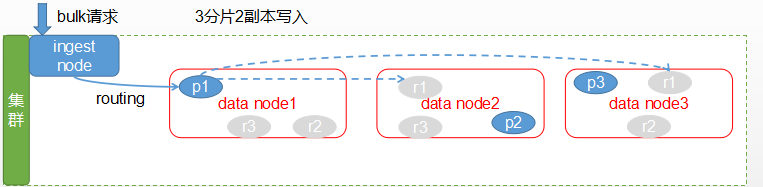
簡易的寫入流程
- 如下是bulk請求的簡易寫入流程,我們知道客戶端會選擇一個節點發送請求,這個節點被之稱為協調節點,也叫客戶端節點,但是在執行之前,如果定義了預處理的pipline操作(比如寫入前將key值轉換,或者增加時間戳等),則此寫操作會被攔截並進行對應邏輯處理。
- 從圖中可以看出,寫入操作會現根據路由出來的規則,決定傳送資料到那個分片上去,預設情況下,是通過資料的文件id來進行路由的,這能保證資料平均分配到各個節點上去,也可以自定義路由規則,具體定義方式我們在下面會講到。
- 接著,請求傳送到了主分片上,主分片執行成功後,會將請求再轉發給相應的副本分片,在副本分片上執行成功後,這個請求才算是執行完畢,然後將執行結果返回給客戶端。
- 可以看出多副本在寫多讀少的場景下,十分的消耗效能,近似的,多了幾個副本就相當於重複寫了幾份資料。如果不考慮資料容災,則可以適當的降低副本數量,或者去掉副本,提高寫入速度。
在我們的叢集裡面並沒有用到ingest角色型別的節點,這裡提出來說也是為了便於大家更好理解各個節點的角色分工。
- 通過ES提供的API觀察各個節點的熱執行緒,api結果會顯示出佔用cpu高的執行緒,這也是我們可以優化的地方。大量寫入場景下,這裡一般大多數會顯示:Lucene Merge Thread 或者[write],查詢命令為:GET /_nodes/hot_threads
三、觀察叢集執行緒池狀態
- 避免大量寫入被拒絕,可以通過觀察elasticsearch後臺日誌或是通過使用Thread pool Api來觀察內部執行緒池的使用情況,以及相應使用的佇列大小,判斷是否還可以繼續調整寫入配置引數。
curl -uusername:pwd-XGET "http://esip:port/_cat/thread_pool?v" | grep write寫入負載高的情況下,可能會出現大量拒絕,如下:
| node-name | name | active | queue |
|---|---|---|---|
| node-3 | write | 4 | 0 |
| node-1 | write | 3 | 2 |
| node-2 | write | 9 | 1 |
主機部分
每個目錄掛載不同的磁碟
- 在data目錄下,我們分出了10個子目錄,分別掛載到不同的硬碟上去。這相當於做了raid0。能大大的提高寫入速度。
###### 配置多個path.data
- 由於在前面我們將10個目錄分別掛載到不同的硬碟上去,所以在elasticsearch.yml的path.data屬性中,我們配置多個路徑,讓資料能高效的寫入不同的目錄(硬碟),需要注意的是,如果只有一個索引,它的分片在某個節點的儲存目錄是固定的。所以這個特性,也只有在存在多個索引的情況下,能發揮出它的作用。
###### 一個主機啟動兩個節點
- es例項分配記憶體不會超過32G,對於主機數量固定的我們,如果125G的機器只放一個es節點,實屬有點浪費,所以考慮在主機上啟動兩個es節點例項。
配置上需要注意關注以下幾點:
- 1、http的埠、節點間通訊的trasport埠設定。
- 2、節點的角色分配。
- 3、腦裂配置對應修改。
- 4、path.data屬性修改(重要)
- 5、path.logs屬性修改。
###### 修改path.data配置,使同一主機兩個節點均分硬碟
- 這裡著重說一下第4點,同一個主機啟動兩個例項後,我們將path.data配置從原來的10個目錄改為了各自配置5個不同目錄。
path.data: /data01/esdata,/data02/esdata,/data03/esdata
,/data04/esdata,/data05/esdata- 一方面是 能夠控制分片的分配,避免太多分片分配到一臺主機上的其中一個節點上。另一方面是避免兩個es程序對同一磁碟進行寫入。隨機寫造成的磁頭非常頻繁的大面積移動肯定比單程序的順序寫入慢,這也是我們提高寫入速度的初衷。
###### 更換ssd
- ssd能成倍的提高寫入速度,如果使用ssd,可能就不會折騰這篇文章出來了。
elasticsearch部分
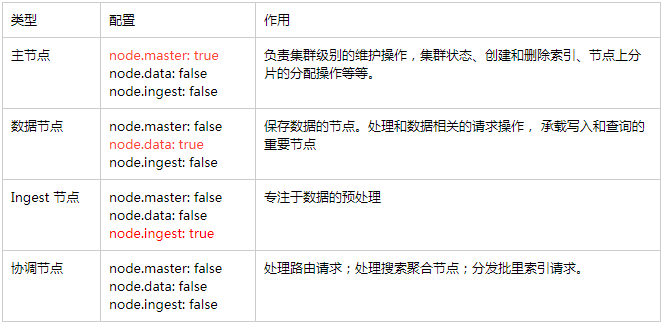
節點角色的設定
- elasticsearch提供幾種型別的節點角色設定,需要在elasticsearch.yml配置中指定。
型別。
###### 指定索引模板
可以根據需要修改,具體配置含義不再細說。
{
"order": 0,
"index_patterns": [
"topicA*"
],
"settings": {
"index": {
"refresh_interval": "40s",
"number_of_shards": "30",
"translog": {
"flush_threshold_size": "1024mb",
"sync_interval": "120s",
"durability": "async"
},
"number_of_replicas": "0",
"merge": {
"scheduler": {
"max_thread_count": "1"
}
}
}
},
"mappings": {
},
"aliases": {}
}計算分片數
- 需要注意分片數量最好設定為節點數的整數倍,保證每一個主機的負載是差不多一樣的,特別如果是一個主機部署多個例項的情況,更要注意這一點,否則可能遇到其他主機負載正常,就某個主機負載特別高的情況。
一般我們根據每天的資料量來計算分片,保持每個分片的大小在50G以下比較合理。如果還不能滿足要求,那麼可能需要在索引層面通過拆分更多的索引或者通過別名+按小時 建立索引的方式來實現了。
控制分片均分在各個主機上
- 以TopicA資料的一個索引為例,共30個分片,在10個節點上分配,應該每個節點分配3個分片,一個主機上一共有6個分片才算是均衡。如果分配不是這樣,可以使用cerebo或者通過命令列進行分片遷移。

curl -X POST "localhost:9200/_cluster/reroute?pretty" -H 'Content-Type: application/json' -d'
{
"commands" : [
{
"move" : {
"index" : "test", "shard" : 0,
"from_node" : "node1", "to_node" : "node2"
}
}
]
}配置索引緩衝區
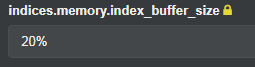
- 即是指定 indices.memory.index_buffer_size的大小,這個是一個靜態變數,需要修改配置檔案,重啟後才能生效。
參考的計算公式:indices.memory.index_buffer_size / shards_count > 512MB(超過這個值索引效能並不會有太明顯提高)
shards_count為一個節點上面的分片數量,可以配置具體指或者一個佔用Es記憶體總值的百分比。這裡我們修改成了20%(預設10%)。
路由分片
- 可以使用elasticsearch提供的routing特性,將資料按一定規則計算後(內部採用hash演算法,把相同hash值的文件放入同一個分片中),預設情況下是使用DocId來計算,寫入到分片,查詢時指定routing查詢,則可以提高查詢速度,避免了掃描過多的分片帶來的效能開銷。首先,在建立索引模板的時候,需要在mappings中增加配置,要求匹配到此索引模板的索引,必須配置routing:
"_routing": {
"required": true
}第二步、為BulkPorcess建立IndexRequest時,通過routing(java.lang.String routing) 方法指定參與計算hash的值。
注意這裡是具體的值,而不是欄位名稱。
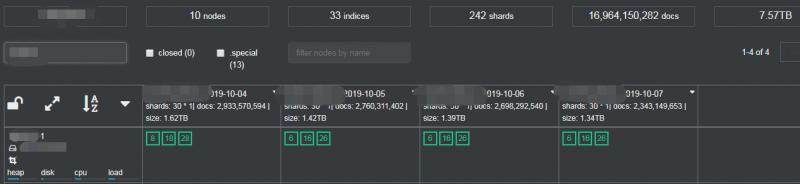
經過如上的調優配置,三個Topic資料都能正常寫入,叢集文件總數在170億,33個索引,每個索引保留4天,242個分片,整體負載不高。
踩過的坑
1、節點角色的設定方面
- 如果叢集中節點數量不多,並且不需要對資料進行預處理,那麼其實可以放棄使用Ingest型別的節點。預設情況下所有的節點的預設設定都為true。所以我們手動將主節點和資料節點做如下設定
node.ingest: false
但是需要注意一點,x-pack監控用到了這種型別的節點。會如下錯誤:
failed to flush export bulks 、no ingest node
解決辦法是,開啟這個屬性配置,或者elasticsearch.yml中指定:
xpack.monitoring.exporters.my_local: type:
xpack.monitoring.exporters.local use_ingest: false
2、elasticsearch 執行緒池相關配置引數改變
- 從5.0版本以後,禁止了修改各個模組執行緒池的型別,執行緒池相關配置的字首從threadpool 變成了thread_pool.並且執行緒池相關配置級別上升至節點級配置,禁止通過使用API修改,因為場景是寫多讀少,所以我們只是增加了寫佇列的大小,配置為: thread_pool.write.queue_size: 1000。
只能通過修改配置檔案的方式修改。
3、單臺主機負載過高
- 同一個主機兩個節點都是資料節點,並且分片分配不均勻,導致這個主機CPU使用率在98%左右,後面通過遷移分片的方式將負載降低。
4、使用自定義的routing規則後帶來的寫熱點問題
- 比如按省份分的資料, 省份為北京的資料過多,西藏的資料很少,可能會帶來寫熱點問題。所以合理的路由分配同樣很重要。
5、資料時區差8小時問題
- 將業務時間轉換為帶時區的字串。yyyy-MM-dd'T'HH:mm:ss.SSSZ
參考文章:
http://kane-xie.github.io/2017/09/09/2017-09-09_Elasticsearch%E5%86%99%E5%85%A5%E9%80%9F%E5%BA%A6%E4%BC%98%E5%8C%96/
https://www.elastic.co/guide/en/elasticsearch/reference/5.0/breaking_50_settings_changes.html
https://elasticsearch.cn/question/1915
https://juejin.im/entry/5d0f17cce51d454d544abf7f
歡迎來公眾號【俠夢的開發筆記】 一起交流進步