
理解LSTM網路--Understanding LSTM Networks(翻譯一篇colah's blog)
colah的一篇講解LSTM比較好的文章,翻譯過來一起學習,原文地址:http://colah.github.io/posts/2015-08-Understanding-LSTMs/ ,Posted on August 27, 2015。
Recurrent Neural Networks
人類思維具有連貫性。當你看這篇文章時,根據你對前面詞語的理解,你可以明白當前詞語的意義。即是由前面的內容可以幫助理解後續的內容,體現了思維的連續性。
傳統的神經網路(RNN之前的網路)在解決任務時,不能做到像人類思維一樣的具有連續性,這成為它的一個主要不足。比如你想對電影不同時刻發生的故事情節進行事件的分類,就無法利用傳統的神經網路,根據電影中前面時刻發生的劇情去推理後續的情節。RNN可以解決此類與連續性有關的問題,它們具有迴圈結構的網路,可以使資訊在其中持續儲存。
 |
| RNN具有迴圈結構 |
上圖中的神經網路結構A,接收輸入Xt ,輸出ht 。A具有的迴圈結構使得資訊可以從上一個時間步(timestep,t)傳到下一時間步(t+1)。帶有箭頭的迴圈網路A看起來很複雜,把迴圈結構展開之後就會比較清晰,從下圖的展開結構可以看出迴圈網路與普通網路的差別也沒有那麼大。迴圈神經網路RNN可以看成是同一個網路的複製了幾份而已,然後再把這複製的幾個網路按照先後順序排列起來,使得前一個網路的輸出剛好作為下一個網路的輸入。
|
RNN的展開示意圖 |
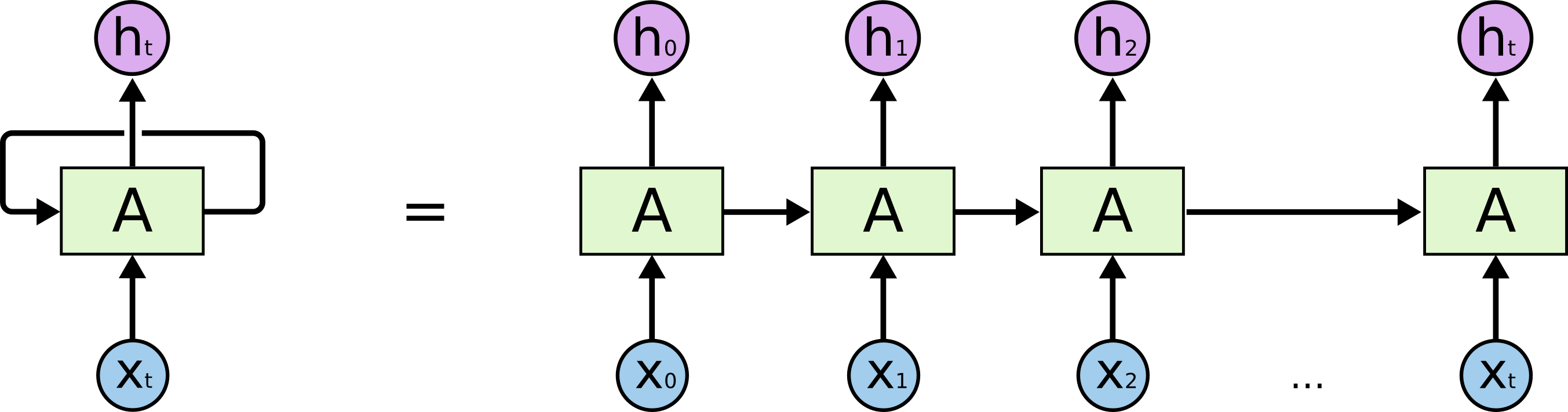
這種類似鏈式的性質表明RNN與序列資料和列表資料有自然地聯絡,這種結構是神經網路利用序列資料的天然結構。事實也是如此。過去幾年裡,RNN成功應用於各種問題中:語音識別,語言模型,(機器)翻譯,給影象加說明文字等等。Andrej Karpathy的blog討論了RNN的各種神奇的效果:The Unreasonable Effectiveness of Recurrent Neural Networks。RNN的成功運用得益於一種特殊的迴圈神經網路結構:LSTM。在迴圈神經網路的運用領域,幾乎所有的令人激動的成果都是基於LSTM做出來的,它遠比標準的RNN結構要好得多。本文接下來就是要討論這些LSTM結構。
長期依賴的問題(The Problem of Long-Term Dependencies)
RNN中的一個引人注意的想法就是它們也許能夠將當前的問題與以前的資訊聯絡起來,比如利用電影中前面一些幀的內容也許能夠幫助理解後面的電影內容。RNN能否解決這個資訊長期依賴的問題,取決於具體的情況。
有時我們只需要查詢最近的資訊來解決當前的問題,比如一個語言模型基於前面的幾個詞來預測下一個單詞,我們要預測一句話的最後一個詞 " the clouds are in the sky ",僅憑sky之前的詞,不需要其他更多的資訊即可預測到 sky,這種情況下預測位置與相關資訊的距離很近,RNN能夠學會利用這種之前的資訊。
 |
但是還有另外的一些情況RNN無法處理。比如要預測一大段話中最後一個詞" I grew up in France.... I speak fluent French. "。最近的資訊暗示最後一個詞可能是一種語言,但是如果要確定是 French 就得需要遠處的France這個上下文的資訊。這種情況,France與French距離可能會比較的遠,RNN就無法學會將這些資訊關聯起來。
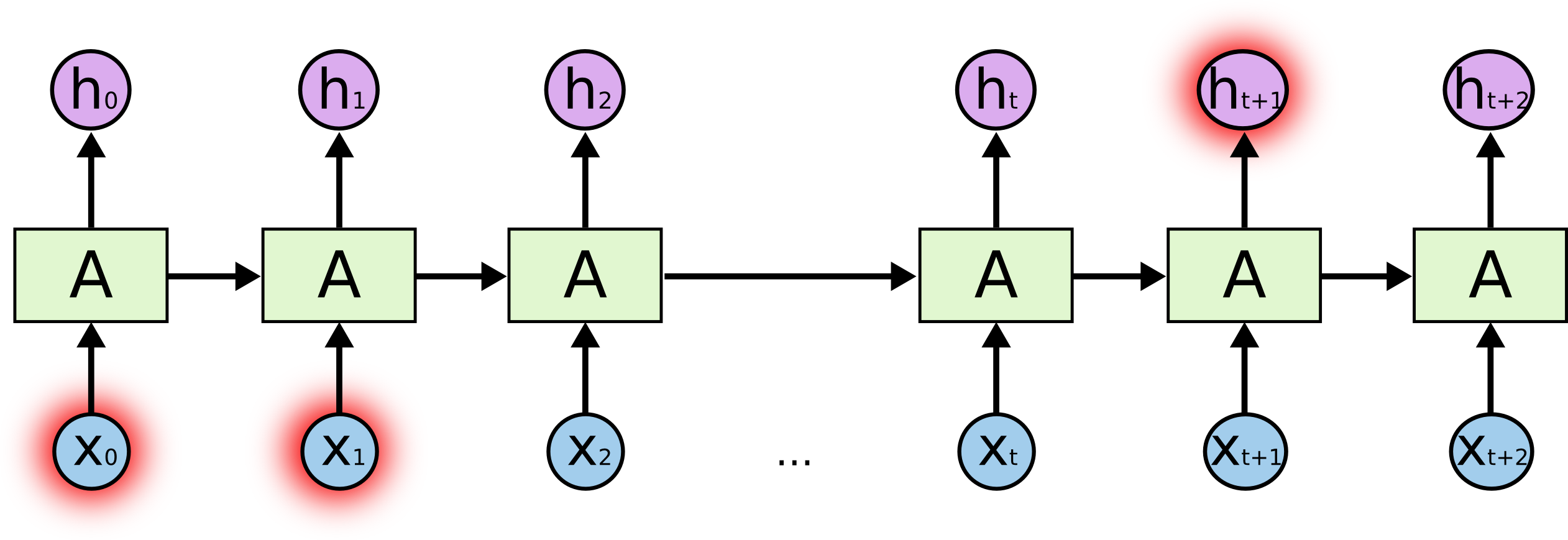 |
理論上RNN是可以處理這種“長期依賴”問題的,人們可以手工的仔細選擇RNN的引數來解決小問題,但是實際中RNN還是無法學到“長期依賴”的解決方法, Hochreiter (1991) [German] 和 Bengio, et al. (1994) 深入研究過RNN無法工作的一些主要原因。LSTM沒有這樣的問題。
LSTM
LSTM(Long Short Term Memory)網路是一種特殊的RNN網路,能夠解決“長期依賴”(long-tern dependencies)的問題,由Hochreiter & Schmidhuber (1997)提出的,它在許多問題的表現效果都很好,至今也在廣泛應用。
LSTM被明確的設計為可以解決“長期依賴”問題,所以能夠記住長期的資訊是它們的預設一種屬性。
在標準RNN結構中,迴圈的網路模組中結構比較簡單,比如僅有一層tanh層。
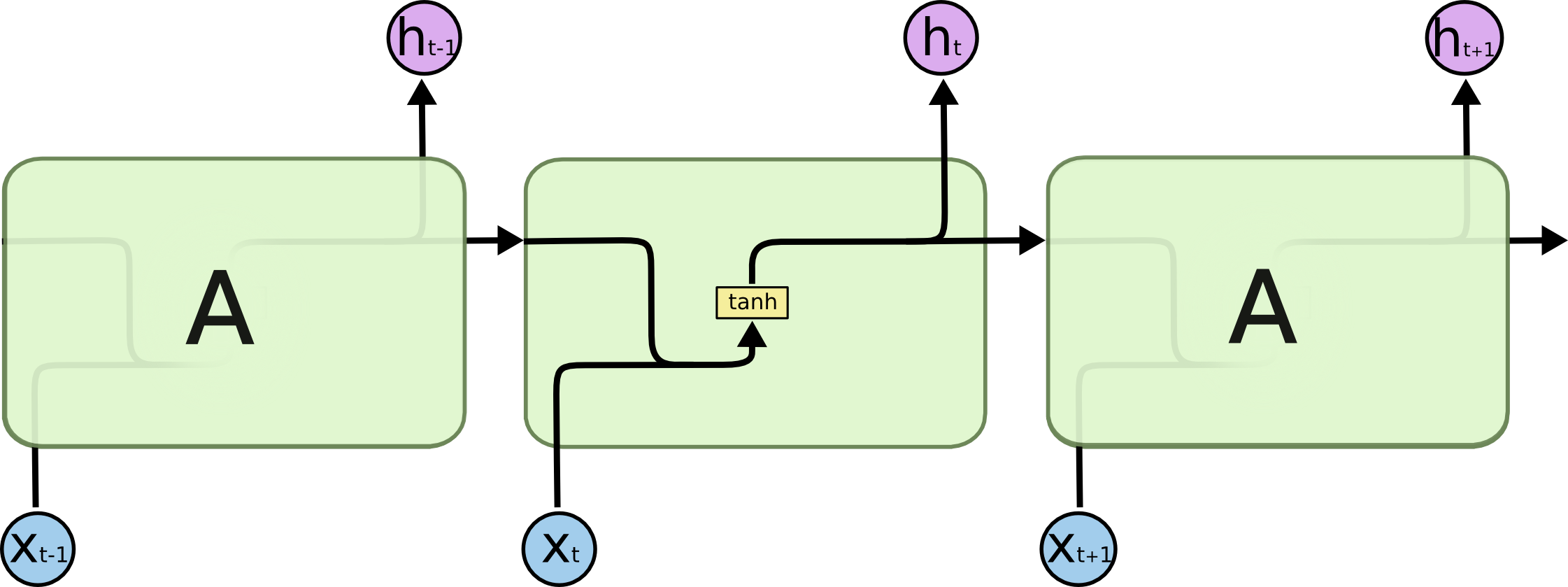
|
LSTM也有與RNN相似的迴圈結構,但是迴圈模組中不再是簡單的網路,而是比較複雜的網路單元。LSTM的迴圈模組主要有4個單元,以比較複雜的方式進行連線。
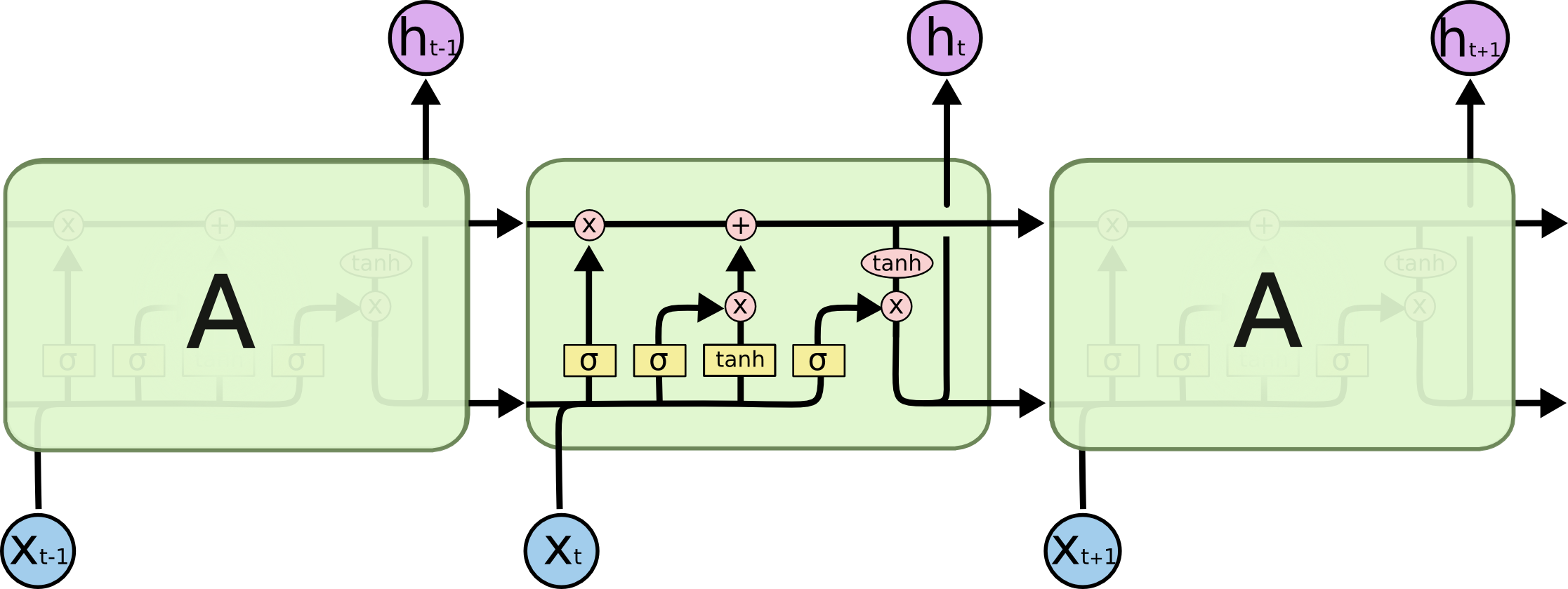
|
先提前熟悉一下將要用到的標記,下面會一步一步的講解LSTM。
 |
LSTM的主要思想(The Core Idea Behind LSTMs)
每個LSTM的重複結構稱之為一個細胞(cell),在LSTM中最關鍵的就是細胞的狀態,下圖中貫穿的那條橫線所表示的就是細胞狀態。
 |
LSTM能夠給細胞狀態增加或者刪除資訊,是由一種叫做“門”的結構來控制的,門主要起到開關的作用,它可以選擇性的讓資訊通過,門是由一個sigmoid層與一個點乘操作組成的。
|
門的組成結構 |

sigmoid層輸出的是0-1之間的數字,表示著每個成分能夠通過門的比例,對應位數字為0表示不通過,數字1表示全通過。比如一個資訊表示為向量[1, 2, 3, 4],sigmoid層的輸出為[0.3, 0.5, 0.2, 0.4],那麼資訊通過此門後執行點乘操作,結果為[1, 2, 3, 4] .* [0.3, 0.5, 0.2, 0.4] = [0.3, 1.0, 0.6, 1.6]。
LSTM共有3種門,通過這3種門控制與保護細胞狀態。
逐步詳解LSTM(Step-by-Step LSTM Walk Through)
第一步是LSTM決定哪些資訊需要從細胞狀態中丟棄,由“遺忘門”(sigmoid層)來決定丟棄哪些資訊。遺忘門接收上一時刻的輸出ht-1 與這一時刻的輸入xt,然後輸出遺忘矩陣f,決定上一時刻的細胞狀態Ct-1 的資訊通過情況。
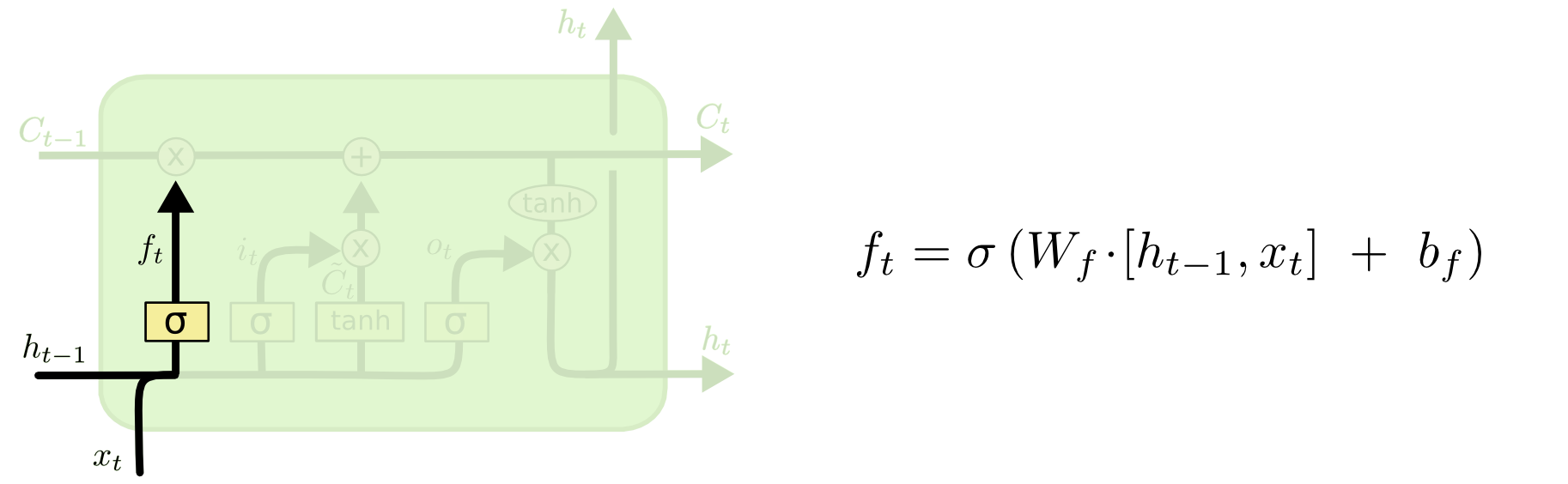
遺忘門
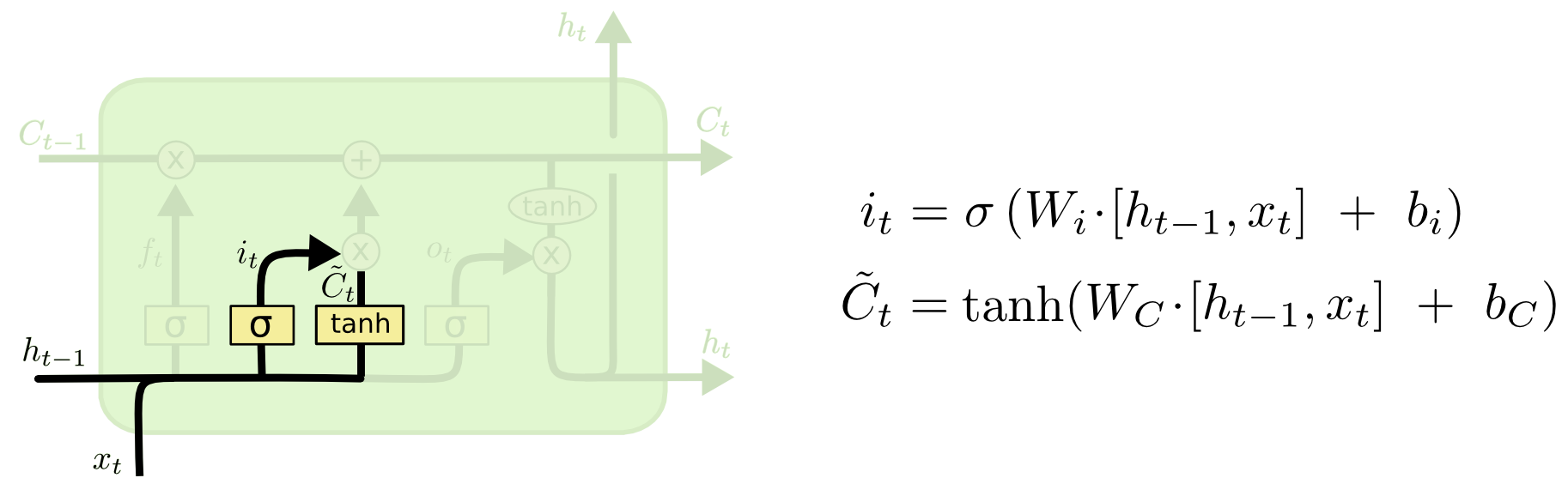
第二步是決定從新的資訊中儲存哪些資訊到細胞狀態中去。首先輸入門(也是sigmoid層)接收ht-1 與xt,產生決定我們要更新哪些數字。接下來一個tanh層產生候選狀態值 \tilde{C}_t 。再聯合待更新的數值與候選狀態值,對舊的狀態Ct-1 進行更新。如下圖,
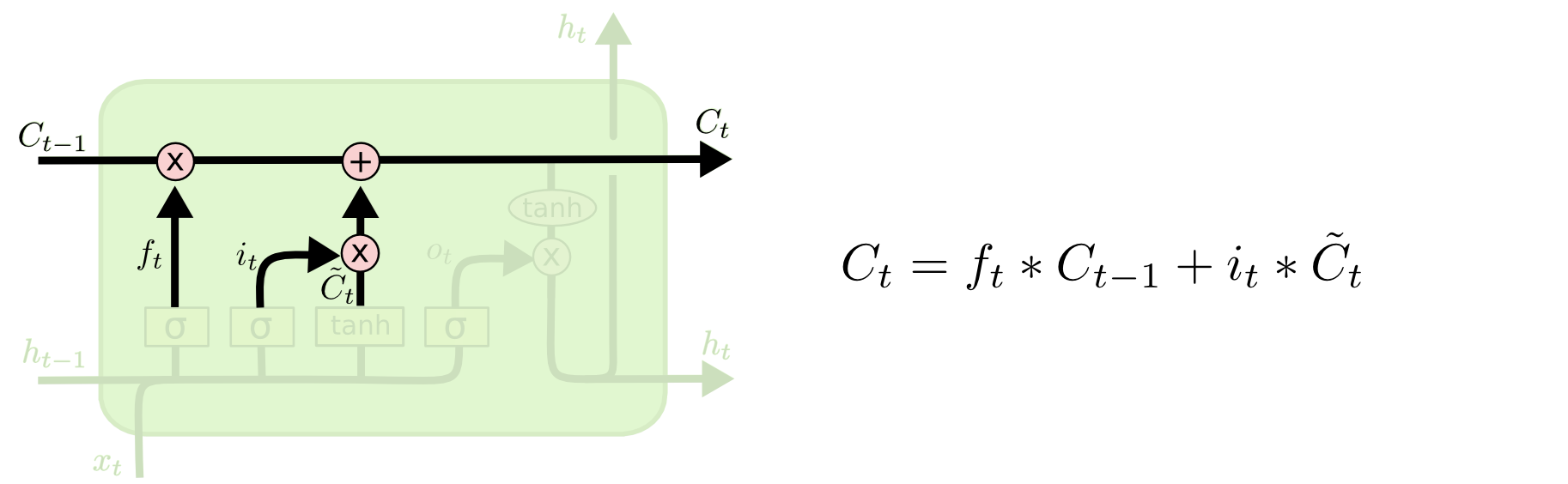
接著是更新舊的狀態,如下圖,ft 是遺忘矩陣, Ct-1是上一時刻的狀態(舊狀態),it 是決定要更新哪些數字,~Ct 是候選狀態。
最後一步是決定輸出哪些資訊。首先利用輸出門(sigmoid層)產生一個輸出矩陣Ot,決定輸出當前狀態Ct的哪些部分。接著狀態Ct通過tanh層之後與Ot相乘,成為輸出的內容ht 。如下圖。

LSTM的變種
目前討論的都是普通的LSTM,並非所有的LSTM網路結構都是這樣的。
Gers & Schmidhuber (2000) 提出了一個比較流行的LSTM模型,加入了“peephole connections”,也就是增加了細胞狀態與3個控制門的直接連線。如下圖,
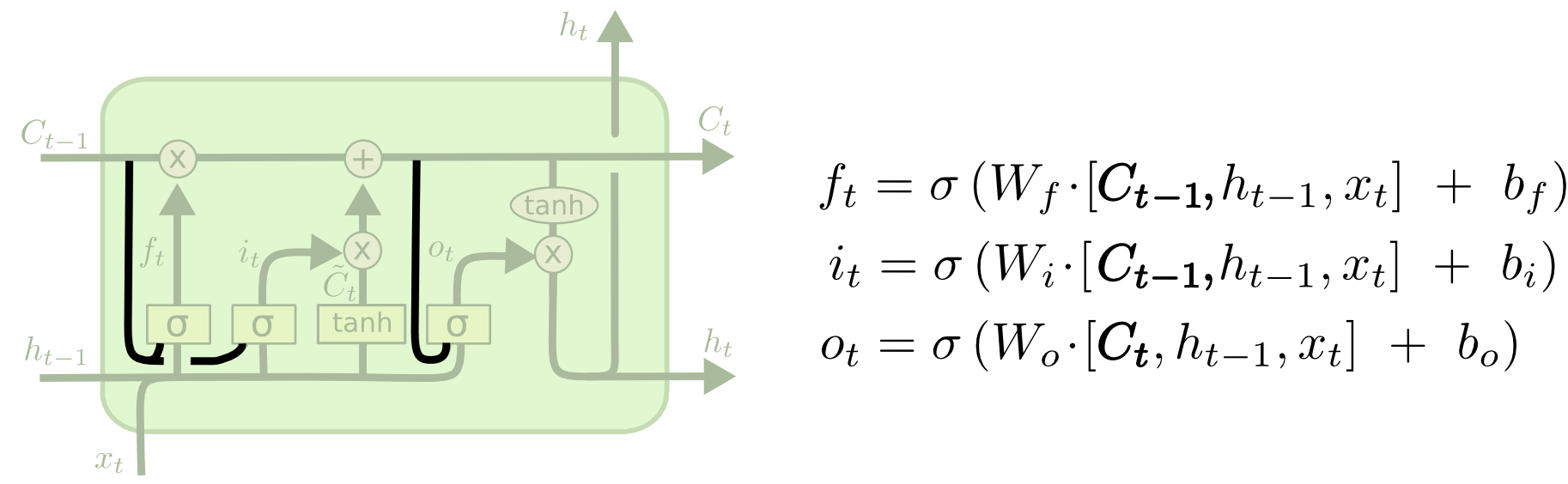 |
另一個LSTM變種模型是利用耦合的遺忘門與輸入門。遺忘門決定哪些狀態需要遺忘,輸入門決定哪些輸入資訊加入新的狀態,將這個兩個分離的過程聯合起來,共同做決定。只在要輸入新狀態的部分對舊的狀態進行丟棄,或者只在被遺忘的狀態部分輸入新的狀態。見下圖,
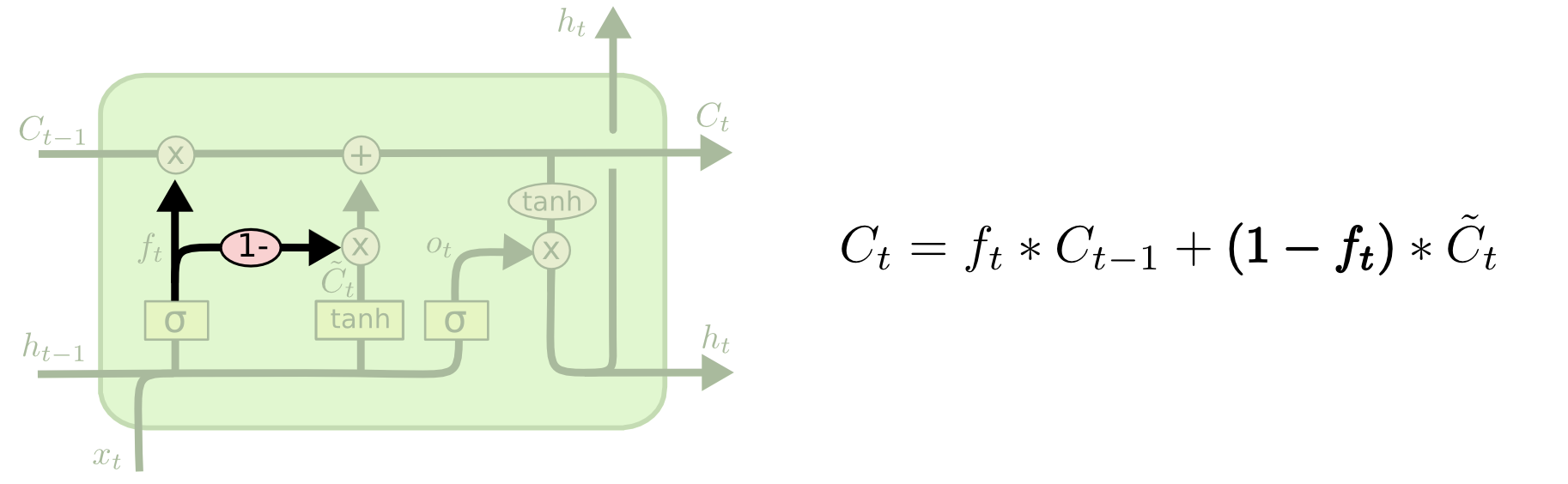 |
另一個更加動態的LST是由 Cho, et al. (2014) 提出的GRU(Gated Recurrent Unit),GRU將遺忘門與輸入門整合成一個單獨的更新門,還整合了細胞狀態與隱藏狀態等,結果是GRU比標準的LSTM模型更加的簡單。
 |
還有其他的一些變種如Yao, et al. (2015) 提出的Depth Gated RNNs。還有采用其他方法解決長期依賴問題的方案如 Koutnik, et al. (2014) 提出的 Clockwork RNNs。
Greff, et al. (2015) 對比了這些變種發現它們都是一樣的,其中的差別並沒有太多的影響。 Jozefowicz, et al. (2015) 測試了測試了成千上萬的RNN結果,發現有些RNN在某些特定任務上表現比LSTM要好。
結論
LSTM在絕大多數任務上的表現確實比RNN要好。LSTM是一個很大的進步,但是另外一個大的進步是什麼呢?研究人員的一個共識就是注意力機制(Attention),注意力機制就是讓RNN在每一步的訓練都從大的資訊集合中挑選需要的資訊,類似於注意力集中在某一部分的資訊上面。使用注意力機制有很多令人興奮的成果出來,還有更多的成果即將出現。
注意力機制不是RNN領域唯一的,還有Kalchbrenner, et al. (2015) 的Grid LSTMs,還有 Gregor, et al. (2015), Chung, et al. (2015), or Bayer & Osendorfer (2015) 等人在生成式模型方面利用RNN。
致謝
省略...