
HDFS概述(一)
1. HDFS產出的背景及定義
1.1 HDFS產生的背景
隨著資料量越來越大,在一個作業系統存不下所有的資料,那麼就分配到更多的作業系統管理的磁碟中,但是不方便管理和維護,迫切需要一種系統來管理多臺機器上的檔案,這就是分散式檔案管理系統。HDFS只是分散式檔案管理系統中的一種。
1.2 HDFS的定義
HDFS(Hadoop Distributed File System),它是一個檔案系統,用於儲存檔案,通過目錄樹來定位檔案;其次,它是分散式的,由很多伺服器聯合起來實現其功能,叢集中的伺服器有各自的角色。
HDFS的使用場景:適合一次寫入,多次讀出的場景,且不支援檔案的修改。適合用來做資料分析,並不適合用來做網盤應用。
2. HDFS的優缺點
2.1 優點:
1). 高容錯性
(1)資料自動儲存多個副本,它通過增加資料副本的樣式,提高容錯性


(2)某一個數據副本丟失以後,它可以自動恢復


2) 適合處理大資料
(1)資料規模:能夠處理規模達到GB、TB、甚至PB的級的大資料 ;
3) 可構建在廉價機器上,通過多副本機制,提高可靠性。
2.2 缺點
1)不適合低時延的資料訪問;
2)無法高效的對大量小檔案進行儲存:
(1)儲存大量小檔案的話,它會佔用NameNode大量的記憶體來儲存檔案的目錄和塊資訊;
(2)小檔案的儲存的定址時間超過了讀取時間,違反了HDFS的設計目標。
3)不支援併發的寫入、檔案隨機修改
(1)一個檔案只能有一個寫,不允許多個執行緒同時寫;
(2)僅支援資料的append(追加),不支援檔案的隨機修改


3. HDFS的組成架構
3.1 整體架構圖如下:
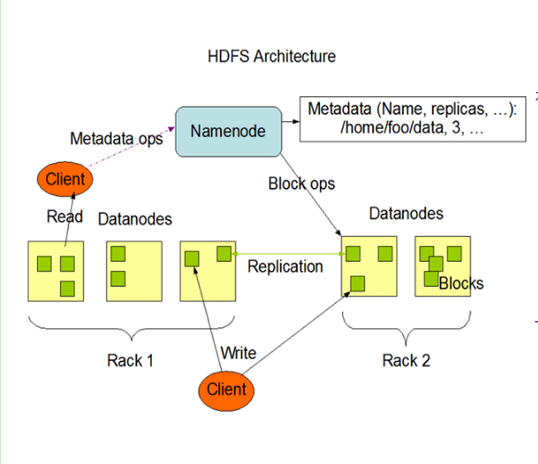

3.2 HDFS架構詳解
1)NameNode(簡稱:ND):就是master,它是一個主管人員,負責管理HDFS的相關資訊:
(1)管理HDFS的名稱空間;
(2)管理副本的策略;
(3)管理資料塊(Block)的對映資訊;
(4)處理客戶端的讀寫請求。
2)DataNode(簡稱:DN):就是slave,NameNode下達指令,DataNode執行實際的操作:
(1)儲存實際的資料塊;
(2)執行資料塊的讀/寫操作。
3)Client:客戶端,與NameNode互動的程式,職責或功能如下:
(1)檔案切分:在上傳檔案至HDFS的時候,Client會將檔案分切成一個個的Block上傳;
(2)與NameNode互動,可以獲取檔案的位置資訊(存在哪個節點上)
(3)Client可以通過一些命令來訪問HDFS,比如增刪改查操作;
(4)Client通過一些命令來管理HDFS,比如將NameNode格式化。
4)SecondaryNameNode:並非是NameNode的熱備。當NameNode掛掉的時候,它並不會立即替換NameNode並提供服務。
(1)輔助NameNode,分擔其工作量,比如定期合併FsImage和Edits(後邊會講到,這裡不用理解),並將合併後的FsImage.checkPoint推送給NameNode;
(2)在緊急情況下可以輔助恢復NameNode。
4 HDFS的檔案塊大小
1)HDFS中的檔案在物理上是按照塊(Block)儲存的,塊id大小可以通過配置引數(dfs.blocksize)來規定,預設大小在Hadoop2.x的版本中是128M,老版本的是64M。
2)塊的大小設定:檔案的定址時間應為塊檔案的傳輸時間的1%,這是比較合理的設定。
3)思考:為什麼塊的大小不能設定太小,也不能設定太大?
(1)HDFS的塊如果設定的太小,會增加定址時間,程式長時間在尋找塊的儲存位置;
(2)如果設定太大,從磁碟傳輸的時間會明顯大於定位這個塊的起始位置所需的時間。導致在處理這個塊的資料時,浪費了大量的時間在IO上。
因此,塊的大小可以根據資料量和磁碟的IO速度決定如何設定。
&n