AB實驗的高階玩法系列2 - 更敏感的AB實驗, CUPED!
背景
AB實驗可謂是網際網路公司進行產品迭代增加使用者粘性的大殺器。但人們對AB實驗的應用往往只停留在開實驗算P值,然後let it go。。。let it go 。。。
讓我們把AB實驗的結果簡單的拆解成兩個方面:
\[P(實驗結果顯著) = P(統計檢驗顯著|實驗有效)× P(實驗有效)\]
如果你的產品改進方案本來就沒啥效果當然怎麼開實驗都沒用,但如果方案有效,請不要讓 statictical Hack 浪費一個優秀的idea
如果預期實驗效果比較小,有哪些基礎操作來增加實驗顯著性呢?
通常情況下為了增加一個AB實驗的顯著性,有兩種常見做法:增加流量或者增長實驗時間。但對一些可能對使用者體驗產生負面影響或者成本較高的實驗來說,上述兩種方法都略顯粗糙。
對於成熟的產品來說大多數的改動帶來的提升可能都是微小的!
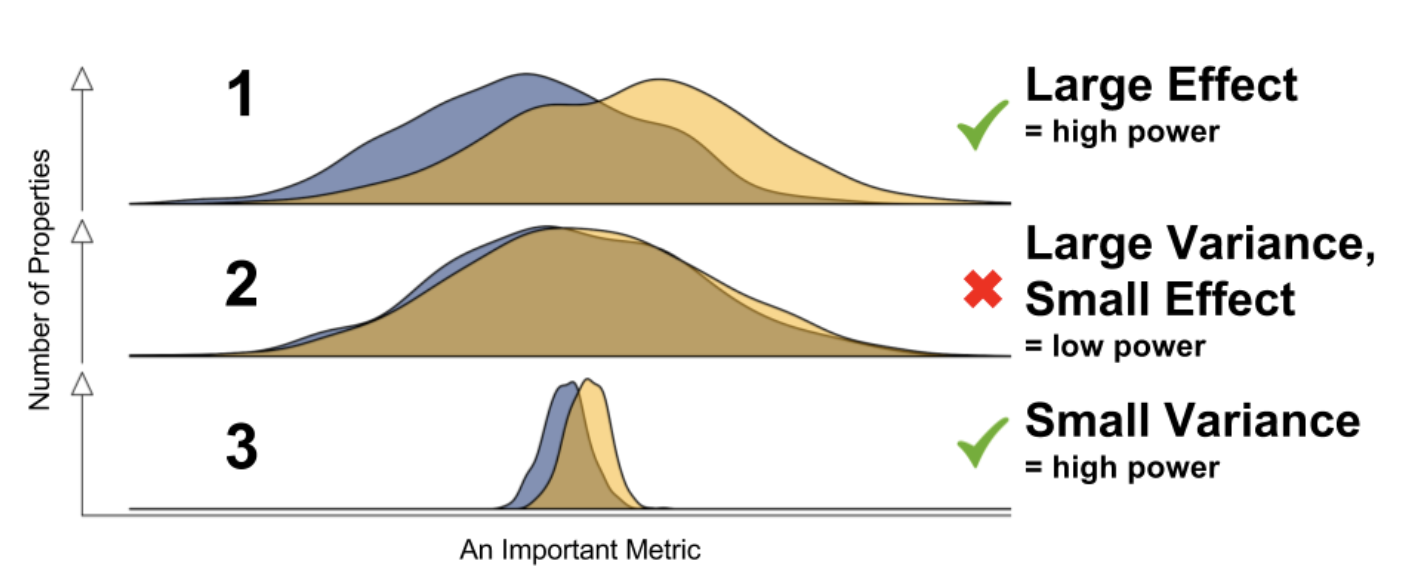
在資料為王的今天,我們難道不應該採用更精細化的方法來解決問題麼?無論是延長實驗時間還是增加流量一方面都是為了增加樣本量,因為樣本越多,方差越小,p值越顯著,越容易檢測出一些微小的改進。
因此如果能合理的通過統計方法降低方差,就可能更快,更小成本的檢測到微小的效果提升
CUPED(Controlled-experiment Using Pre-Experiment Data)應運而生。 下面我會簡單總結一下論文的核心方法,還有幾個Bing, Netflix 以及Booking的應用案例。
論文
Deng A, Xu Y, Kohavi R, Walker T. Improving the Sensitivity of Online Controlled Experiments by Utilizing Pre-experiment Data. Proceedings of the Sixth ACM International Conference on Web Search and Data Mining. New York, NY, USA: ACM; 2013. pp. 123–132. Paper連結
核心方法總結
論文的核心在於通過實驗前資料對實驗核心指標進行修正,在保證無偏的情況下,得到方差更低, 更敏感的新指標,再對新指標進行統計檢驗(p值)。
這種方法的合理性在於,實驗前核心指標的方差是已知的,且和實驗本身無關的,因此合理的移除指標本身的方差不會影響估計效果。
作者給出了stratification和Covariate兩種方式來修正指標,同時給出了在實際應用中可能碰到的一些問題以及解決方法.
stratifiaction
這種方式針對離散變數,一句話概括就是分組算指標。如果已知實驗核心指標的方差很大,那麼可以把樣本分成K組,然後分組估計指標。這樣分組估計的指標只保留了組內方差,從而剔除了組間方差。
\[
\begin{align}
k &= {1,2,...,K} \\
\hat{Y}_{strat} &= \sum_{k=1}^{K} w_k * (\frac{1}{n_k}*\sum_{x_i \in k} Y_i )\\
Var(\hat{Y}) &= Var_{\text{within_strat}} + Var_{\text{between_strat}}\\
&=\sum_{k=1}^K\frac{w_k}{n} \sigma_k^2 + \sum_{k=1}^K\frac{w_k}{n} (\mu_k - \mu)^2\\
&>=\sum_{k=1}^K\frac{w_k}{n} \sigma_k^2 = Var(\hat{Y}_{strat})
\end{align}
\]
Covariate
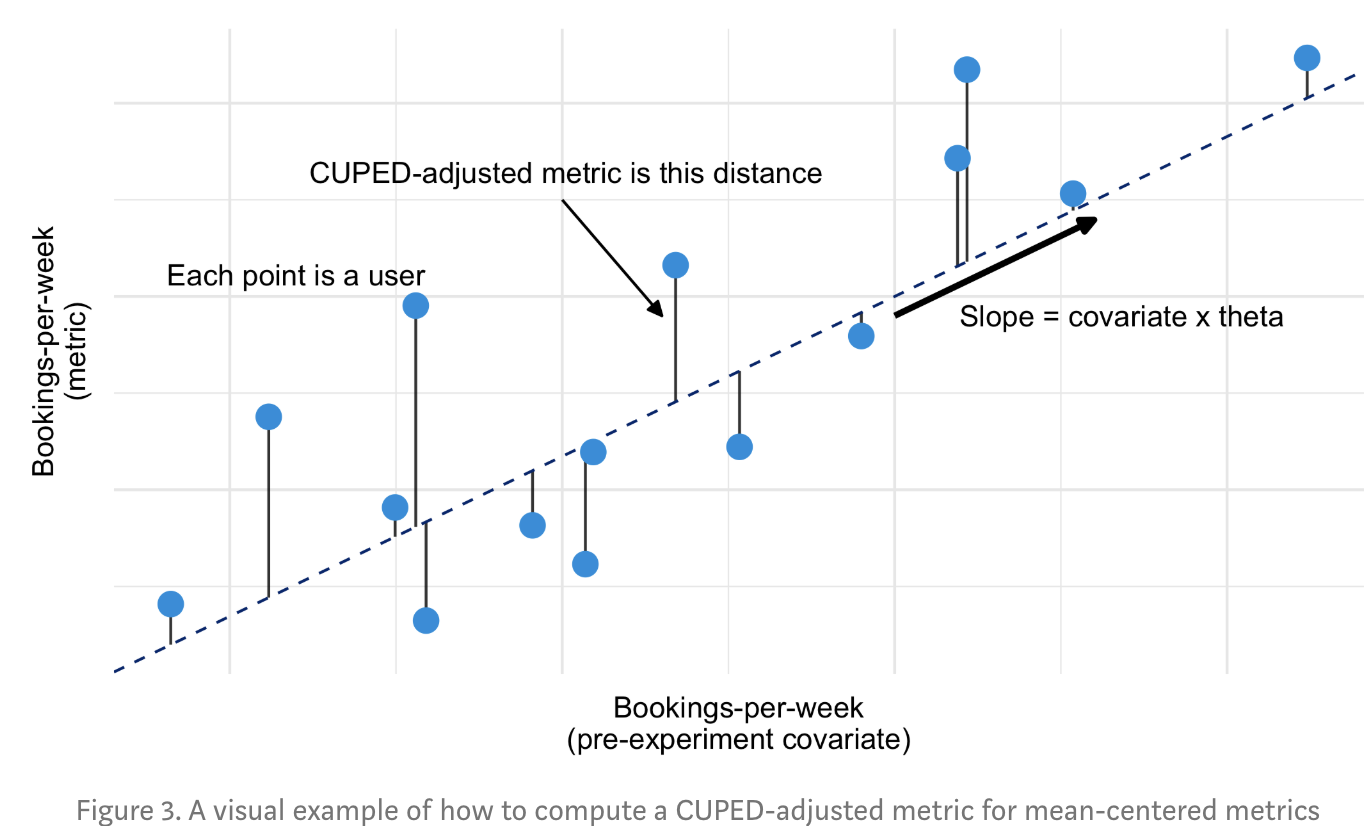
Covariate適用於連續變數。需要尋找和實驗核心指標(Y)存在高相關性的另一連續特徵(X),然後用該特徵調整實驗後的核心指標。X和Y相關性越高方差下降幅度越大。因此往往可以直接選擇實驗前的核心指標作為特徵。只要保證特徵未受到實驗影響,在隨機AB分組的條件下用該指標調整後的核心指標依舊是無偏的。
\[ \begin{align} Y_i^{cov} &= Y_i - \theta(X_i - E(x))\\ \hat{Y}_{cov} &= \hat{Y} - \theta(\bar{x} - E(x))\\ \theta &= cov(X,Y)/cov(X)\\ Var(\hat{Y}_{cov}) & = Var(\hat{Y}) * (1-\theta^2) \end{align} \]
stratification和Covariate其實是相同的原理,從兩個角度來看:
- 從迴歸預測的角度,實驗核心指標是Y,降低Y的方差就是尋找和Y相關的自變數X來解釋Y中資訊的過程(提升\(R^2\)),X可以是連續也可以是離散的
- 從投資組合的角度,Y是組合中的一項資產,想要降低交易Y的風險(方差),就要做空和Y相關的X資產來對衝風險,相關性越高對衝效果越好
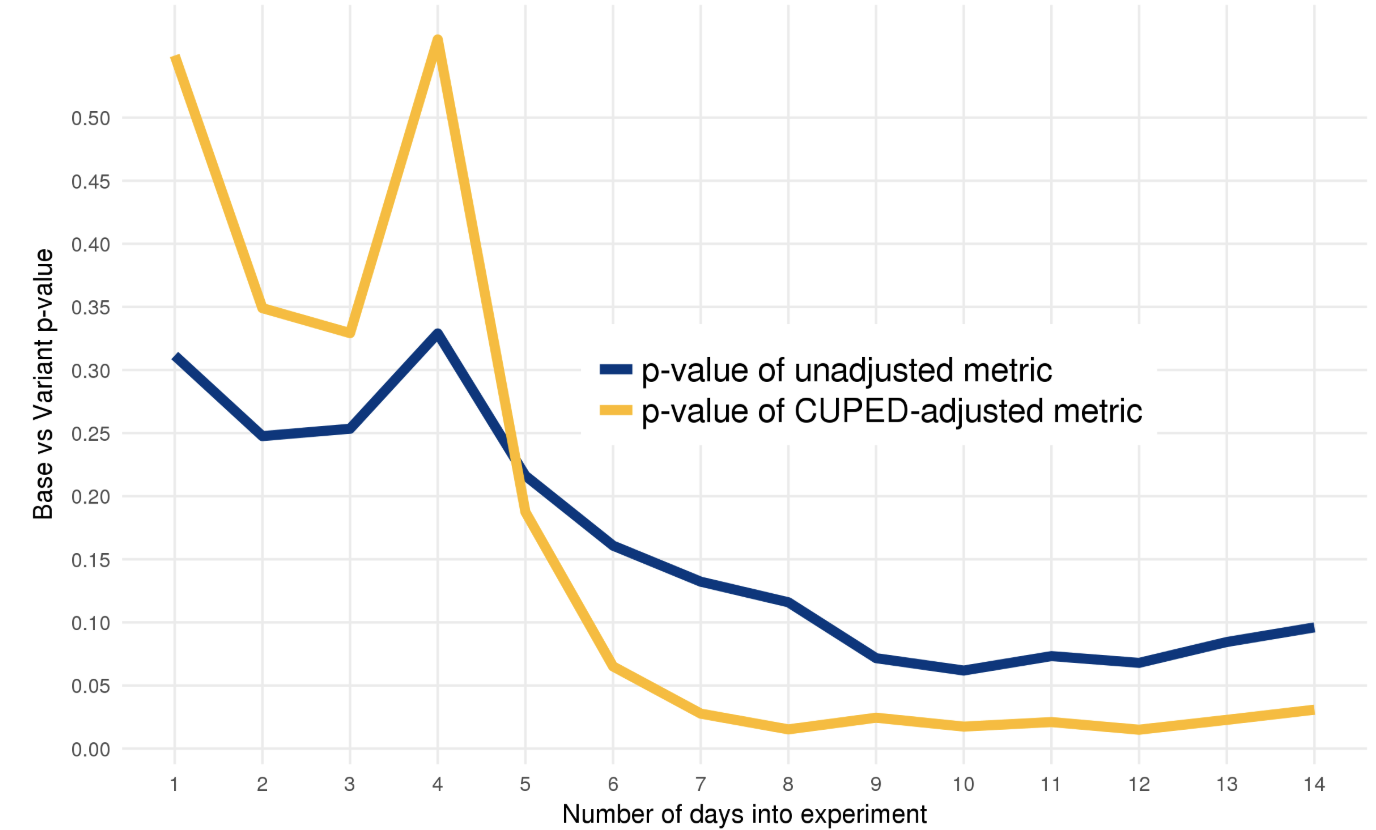
下圖摘自Booking的案例,他們的核心指標是每週的房間預定量,Covariate是實驗前的每週房間預定量,部落格連結在案例分享裡。
實戰攻略
covariate的選擇
這裡的選擇包括兩個方面,特徵的選擇和計算特徵的pre-experiment時間長度的選擇。
核心指標在per-experiment的估計通常是很好的covariate的選擇,且估計covariate選擇的時間段相對越長效果越好。時間越長covariate的覆蓋量越大,且受到短期波動的影響越小估計更穩定。
沒有pre-experiment資料怎麼辦
這個現象在網際網路中很常見,新使用者或者很久不活躍的使用者都會面臨沒有近期行為特徵的問題。作者認為可以結合stratification方法對有/無covariate的使用者進一步打上標籤。或者其實不僅侷限於pre-experiment特徵,只要保證特徵不受到實驗影響post-experiment特徵也是可以的。
而在Booking的案例中,作者選擇對這部分樣本不作處理,因為通常缺失值是用樣本均值來填充,在上述式子中就等於是不做處理。
Attention
Covariate選擇的核心是\(E(X^{treatment}) = E(X^{control})\),這一點不論你選擇什麼特徵, 是pre-experiment還是post-experiment都要保證。
當然也有用CUPED來矯正實驗組對照組差異的,但這個內容不在這裡討論。
應用案例
Bing 載入時間對使用者點選率的影響
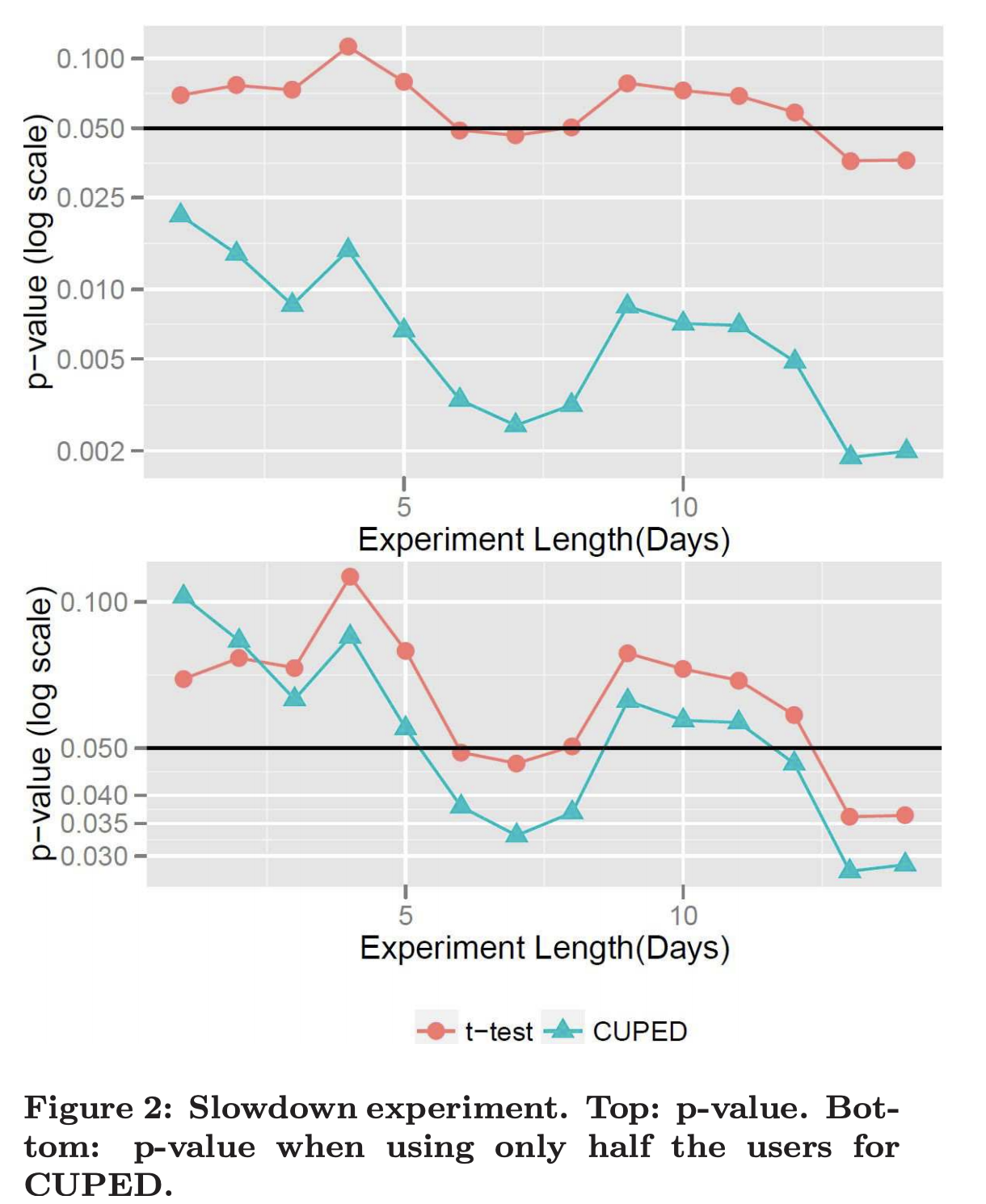
論文中作者在實際AB實驗中檢驗了CUPED的效果。Bing實驗檢測檢測載入時間對使用者點選率的影響。 一個原本執行兩週只有個別天顯著的實驗在用CUPED調整後在第一天就顯著,當把CUPED估計用的樣本減少一半後顯著性依舊超過直接使用T-test.
Netflix 多種方法的實際效果對比
Huizhi Xie,Juliette Aurisset.Improving the Sensitivity of Online Controlled Experiments: Case Studies at Netflix
Netflix嘗試了一種新的stratification, 上述論文中的stratification被稱作post-stratification因為它只在估計實驗效果時用到分組,這時用pre-experiment估計的分組概率會和隨機AB分組得到的實驗中的分組概率存在一定差異,所以Netflix嘗試在實驗前就進行分層分組。通過多個實驗結果,Netflix得到以下結論:
- 大樣本下,post-strat在實際中更靈活和pre-strat表現相當
- 能否成功找到和實驗核心指標相關的covariate是成功的關鍵
Booking.com 新日曆互動對使用者影響
How Booking.com increases the power of online experiments with CUPED
實驗效果對比如下,CUPED用更少的樣本更短的時間得到了顯著的結果。瞭解細節請戳上面的部落格,作者講的非常通俗易懂。