
redis之管道
Redis 的訊息互動
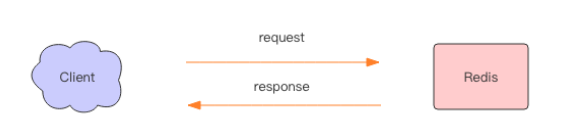
當我們使用客戶端對 Redis 進行一次操作時,如下圖所示,客戶端將請求傳送給服務
器,伺服器處理完畢後,再將響應回覆給客戶端。這要花費一個網路資料包來回的時間。
如果連續執行多條指令,那就會花費多個網路資料包來回的時間。如下圖所示。

回到客戶端程式碼層面,客戶端是經歷了寫-讀-寫-讀四個操作才完整地執行了兩條指令。

現在如果我們調整讀寫順序,改成寫—寫-讀-讀,這兩個指令同樣可以正常完成。

兩個連續的寫操作和兩個連續的讀操作總共只會花費一次網路來回,就好比連續的 write
操作合併了,連續的 read 操作也合併了一樣。

這便是管道操作的本質,伺服器根本沒有任何區別對待,還是收到一條訊息,執行一條
訊息,回覆一條訊息的正常的流程。客戶端通過對管道中的指令列表改變讀寫順序就可以大
幅節省 IO 時間。管道中指令越多,效果越好。
管道壓力測試
接下來我們實踐一下管道的力量。
Redis 自帶了一個壓力測試工具 redis-benchmark,使用這個工具就可以進行管道測試。
首先我們對一個普通的 set 指令進行壓測,QPS 大約 5w/s。
> redis-benchmark -t set -q
SET: 51975.05 requests per second
我們加入管道選項-P 引數,它表示單個管道內並行的請求數量,看下面 P=2,QPS 達到
了 9w/s。
> redis-benchmark -t set -P 2 -q
SET: 91240.88 requests per second
再看看 P=3,QPS 達到了 10w/s。
SET: 102354.15 requests per second
但如果再繼續提升 P 引數,發現 QPS 已經上不去了。這是為什麼呢?
因為這裡 CPU 處理能力已經達到了瓶頸,Redis 的單執行緒 CPU 已經飆到了 100%,所
以無法再繼續提升了。
深入理解管道本質
接下來我們深入分析一個請求互動的流程,真實的情況是它很複雜,因為要經過網路協
議棧,這個就得深入核心了。
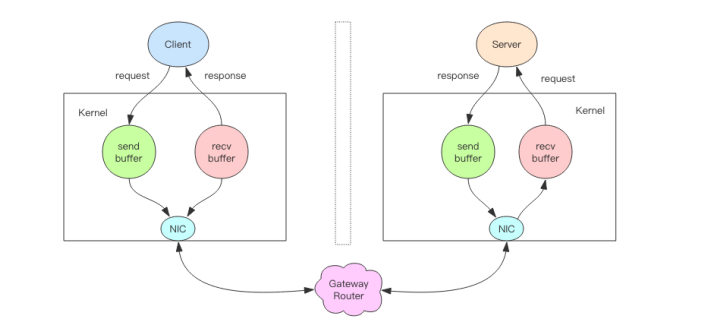
上圖就是一個完整的請求互動流程圖。我用文字來仔細描述一遍:
1、客戶端程序呼叫 write 將訊息寫到作業系統核心為套接字分配的傳送緩衝 send
buffer。
2、客戶端作業系統核心將傳送緩衝的內容傳送到網絡卡,網絡卡硬體將資料通過「網際路
由」送到伺服器的網絡卡。
3、伺服器作業系統核心將網絡卡的資料放到核心為套接字分配的接收緩衝 recv buffer。
4、伺服器程序呼叫 read 從接收緩衝中取出訊息進行處理。
5、伺服器程序呼叫 write 將響應訊息寫到核心為套接字分配的傳送緩衝 send buffer。
6、伺服器作業系統核心將傳送緩衝的內容傳送到網絡卡,網絡卡硬體將資料通過「網際路
由」送到客戶端的網絡卡。
7、客戶端作業系統核心將網絡卡的資料放到核心為套接字分配的接收緩衝 recv buffer。
8、客戶端程序呼叫 read 從接收緩衝中取出訊息返回給上層業務邏輯進行處理。
9、結束。
其中步驟 5~8 和 1~4 是一樣的,只不過方向是反過來的,一個是請求,一個是響應。
我們開始以為 write 操作是要等到對方收到訊息才會返回,但實際上不是這樣的。write
操作只負責將資料寫到本地作業系統核心的傳送緩衝然後就返回了。剩下的事交給作業系統
核心非同步將資料送到目標機器。但是如果傳送緩衝滿了,那麼就需要等待緩衝空出空閒空間
來,這個就是寫操作 IO 操作的真正耗時。
我們開始以為 read 操作是從目標機器拉取資料,但實際上不是這樣的。read 操作只負
責將資料從本地作業系統核心的接收緩衝中取出來就了事了。但是如果緩衝是空的,那麼就
需要等待資料到來,這個就是讀操作 IO 操作的真正耗時。
所以對於 value = redis.get(key)這樣一個簡單的請求來說,write 操作幾乎沒有耗時,直接
寫到傳送緩衝就返回,而 read 就會比較耗時了,因為它要等待訊息經過網路路由到目標機器
處理後的響應訊息,再回送到當前的核心讀緩衝才可以返回。這才是一個網路來回的真正開
銷。
而對於管道來說,連續的 write 操作根本就沒有耗時,之後第一個 read 操作會等待一個
網路的來回開銷,然後所有的響應訊息就都已經回送到核心的讀緩衝了,後續的 read 操作
直接就可以從緩衝拿到結果,瞬間就返回