
學習資料倉庫之構建
資料庫有三級模型的概念,在這裡,資料倉庫也是有著三級模型並且是有著相似的思路。
1.概念模型
“資訊世界”中的資訊結構,也常常借用關係資料庫設計中的E-R方法,不過在資料倉庫的設計是以主題替代實體。
根據業務的範圍和使用來劃分主題
劃分的方法是首先要確定系統邊界,包括瞭解決策者需求(關注點),需求型別。通過對業務系統的詳細說明,確定資料覆蓋範圍,對資料進行梳理,列出資料主題詳細的清單,瞭解源資料狀況。
對每個資料主題都作出詳細的解釋,然後經過歸納、分類,整理成各個資料主題域,確定系統包含的主題。列出每個資料主題域包含哪些部分,並對每個資料主題域作出詳細的解釋,最後劃分成主題域概念模型。

2.邏輯模型
邏輯模型的設計是資料倉庫實施中最重要的一步,因為它直接反映了資料分析部門的實際需求和業務規則,同時對物理模型的設計和實現具有指導作用。它的特點就是通過實體和實體之間的關係勾勒出整個企業的資料藍圖和規劃。邏輯模型一般遵循第三正規化,與概念模型不同,它主要關注細節性的業務規則,同時需要解決每個主題包含哪些概念範疇和跨主題域的繼承和共享的問題。
根據需求列出需要分析的主題,需求目標緯度指標,緯度層次分析的指標,分析的方法、資料來源等
對於一些緯度存在層次問題,比如說產品存在產品的類別,產品的子類別以及具體的產品
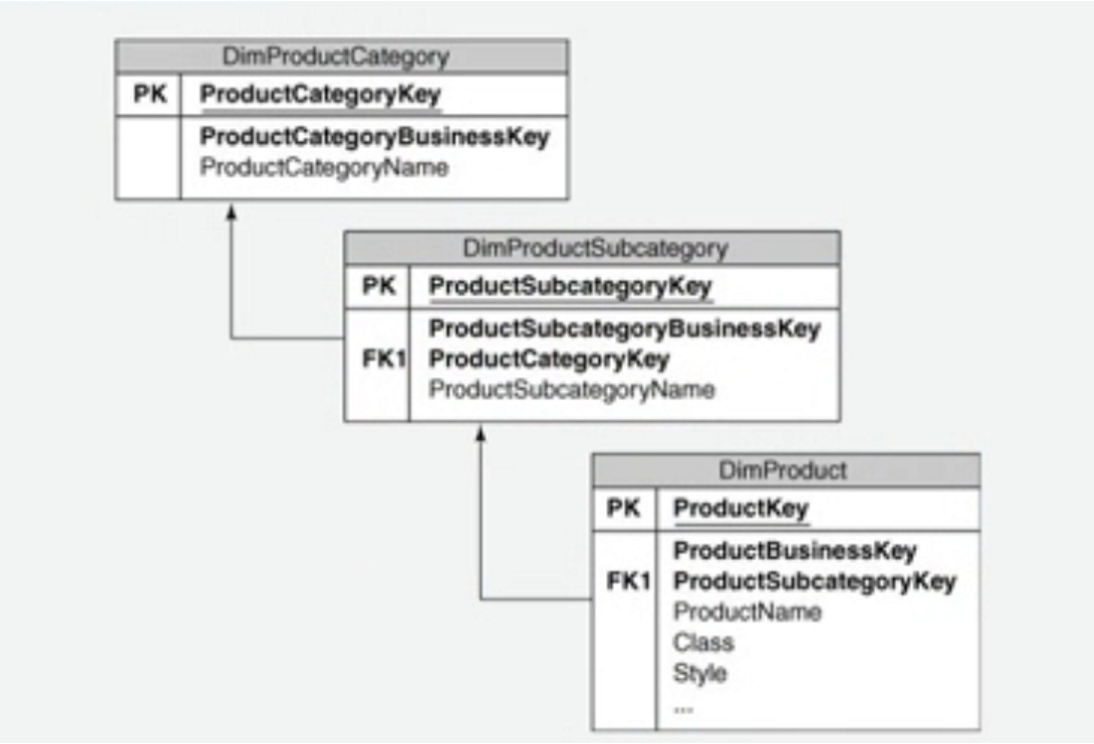
在邏輯模型設計中需要考慮粒度層次的劃分。資料倉庫的粒度層次劃分直接影響了資料倉庫模型的設計,通常細粒度的資料模型直接從企業模型選取實體作為邏輯模型的實體,而粗粒度的資料模型需要經過彙總計算得到相應的實體。粒度決定企業資料倉庫的實現方式、效能、靈活性和資料倉庫的資料量。
粒度指的是描述資料的綜合程度。粒度規定了資料倉庫潛在的能力和靈活性,如果沒有粒度級別的變化,資料倉庫將不能回答需要低於所採用細節級的問題。同時,粒度級別是資料庫規模的主要決定因素之一,對操作的開銷及效能都有顯著影響。
資料粒度越小,資訊越細,資料量越大;顆粒粒度越大就忽略了眾多的細節,資料量越小。
3.物理模型
將邏輯模型轉變為物理模型包括以下幾個步驟:
(1)實體名(Entity) 轉變為表名(Table)。
(2)屬性名(Attribute) 轉換為列名(Column) ,確定列的屬性(Property) 。
(3)確定表之間連線主鍵和外來鍵屬性或屬性組。
在物理模型設計中同時要考慮資料的儲存結構、存取時間、儲存空間利用率、維護代價等。根據資料的重要程度、使用頻率和響應時間將資料分類,不同類資料分別存放在不同儲存裝置中,重要性高、經常存取並對反應時間要求高的資料存放在高速儲存裝置上:存取頻率低或對存取響應時間要求低的資料可以存放在低速儲存裝置上。根據資料量設定儲存塊、緩衝區大小和個數。
兩大類物理模型
資料倉庫的的資料模型相對資料庫更簡單一些,根據事實表和維度表的關係,主要有星形結構模型和雪花型結構模型兩種。
當所有維表都直接連線到“事實表”上時,整個圖解就像星星一樣,故將該模型稱為星型模型。
星型架構是一種非規範化的結構,多維資料集的每一個維度都直接與事實表相連線,所以資料有一定的冗餘,如在商店維度表中,存在省A的城市B以及省A的城市C兩條記錄,那麼省A的資訊分別儲存了兩次,即存在冗餘。
雪花型架構相對於星形架構的優點是,能夠直接利用現有的資料庫建模工具進行建模,提高工作效率;以後對維度表的變更會更加靈活,而星形結構會牽涉到大量的資料更新:由於不存在資料冗餘,因此資料的裝載速度會更快。雪花型架構通過去除了資料冗餘,通過最大限度地減少資料儲存量以及聯合較小的維表來改善查詢性