
基於曝光融合框架的對比度增強演算法
目錄
- 摘要
- 1. 研究現狀
- 2. 本文方法
- 2.1 曝光融合框架
- 2.2 權重矩陣估計
- 2.3 相機響應模型
- 2.4 確定曝光率
- 3. 實驗對比
- 3.1 實驗細節
- 3.2 對比度失真
- 3.3 亮度失真
- 4. 結論
- 5. 主要參考文獻
論文題目《A New Image Contrast Enhancement Algorithm Using Exposure Fusion Framework》翻譯以及分析
摘要
低光影象不利於人眼觀察和計算機視覺演算法識別,因為它們的可見度較低。雖然已經提出了許多影象增強技術來解決這個問題。但是現有方法不可避免地存在對比度過低和過高的情況。在本文中,我們提出了一種精確的對比度增強的演算法。具體來說,我們首先使用光照估計技術為影象融合設計權重矩陣。然後,我們用相機的響應模型合成多重曝光影象。接下來,我們找到最佳的曝光率,為了合成影象在原始影象曝光不足的區域進行更好的曝光。最後,輸入影象和合成影象根據權重矩陣進行融合以獲得影象增強的結果。實驗表明,相比其他優秀的方法,我們的方法可以得到對比度和亮度失真更少的結果。
1. 研究現狀
影象增強技術廣泛用於影象處理中。一般來說,它可以使輸入影象看起來更好,並且更適合於特定演算法進行處理。對比度增強,作為一種增強技術,可以在影象中顯示曝光不足區域的資訊。目前有大量的對比度增強的技術,主要包括基於直方圖,基於Retinex和基於除霧的方法的增強技術。
彩色影象可以用三維陣列表示。最簡單的對比度增強的方法是對每個物件執行相同的處理過程。例如,最早的影象增強方法使用非線性單調函式進行灰度級對映。
考慮到不同灰度級別中元素的不均勻分佈,因此直方圖均衡化(HE)被廣泛用於改善對比度。許多直方圖均衡化的擴充套件方法將亮度儲存和對比度限制考慮進去。但是基於直方圖均衡化的方法總是會過度增強和產生不切實際的結果。在模仿在人類視覺系統中,Retinex理論也廣泛用於影象增強。通過將反射圖與光照圖分開,基於Retinex的演算法可以明顯增強細節。但是這些方法在高對比度區域容易產生偽像。近年來,一些方法應用除霧技術來增強對比度並獲得良好的主觀視覺效果。但是這些方法也可能會因為對比度過度增強而導致顏色失真。
儘管影象對比度增強方法研究了幾十年,但是好的增強效果仍然沒有很好的定義。此外,現有的弱光增強演算法也沒有提供參考如何定位過度增強和不足增強區域。我們注意到不同的影象曝光度可以作為增強演算法的參考,如圖1所示。隨著曝光度的增加,一些低曝光區域變得曝光良好。增強的結果應保持曝光良好的區域保持不變,而曝光不足的區域則增強。與此同時,增強區域的對比度應與正確曝光區域保持一致。
在本文中,我們提出了一個新的框架來幫助緩解欠/過度增強的問題。我們的框架基於相機響應模型從輸入影象合成的多張曝光影象的曝光融合。基於我們的框架,我們提出了一種增強演算法與其他幾種相比最先進的方法,可以獲得更少的對比度和亮度失真的結果。
2. 本文方法
2.1 曝光融合框架
在許多室外場景中,相機無法使所有畫素曝光良好,因為它的動態範圍是有限的。如圖1所示儘管我們可以通過增加曝光量顯示一些曝光不足的區域,與此同時曝光良好的區域可能同時曝光過度。為了讓所有畫素的影象曝光良好,我們可以融合這些影象:
\[
R^c = \sum\limits_{i=1}^{N}W_i*P_i^c
\]
其中 \(N\) 是影象數量,\(P_i\) 是曝光集合中的第 \(i\) 個影象,\(W_i\) 是第 \(i\) 個影象的權重圖,\(c\) 是三個顏色通道的索引,\(R\) 是增強後的結果。三個顏色分量是相等的,所有畫素是不均勻的:曝光良好的畫素具有較大的權重,曝光不良的畫素權重較小。權重已標準化,因此 \(\sum_{i=1}^{N}W_i=1\)。
問題是具有其他曝光設定的影象不適用於影象增強問題。幸運的是,使用不同的曝光度拍攝的照片是高度相關的。在我們的早期工作中,我們提出了相機響應模型以準確描述這些影象之間的關聯,以便我們從輸入影象生成一系列影象。兩張不同曝光度的影象的對映函式,我們稱為亮度轉換函式(BTF)。給定曝光率 \(k_i\) 和 亮度轉換函式 \(g\),我們可以對映輸入影象 \(P\) 到曝光集合中的第 \(i\) 個影象:
\[
P_i=g(P, k_i)
\]
在本文中,我們僅以一定的曝光融合輸入影象本身來降低複雜度,如圖2所示。融合影象定義為:
\[
R^c=W*P^c+(1-W)*g(P^c,k)
\]
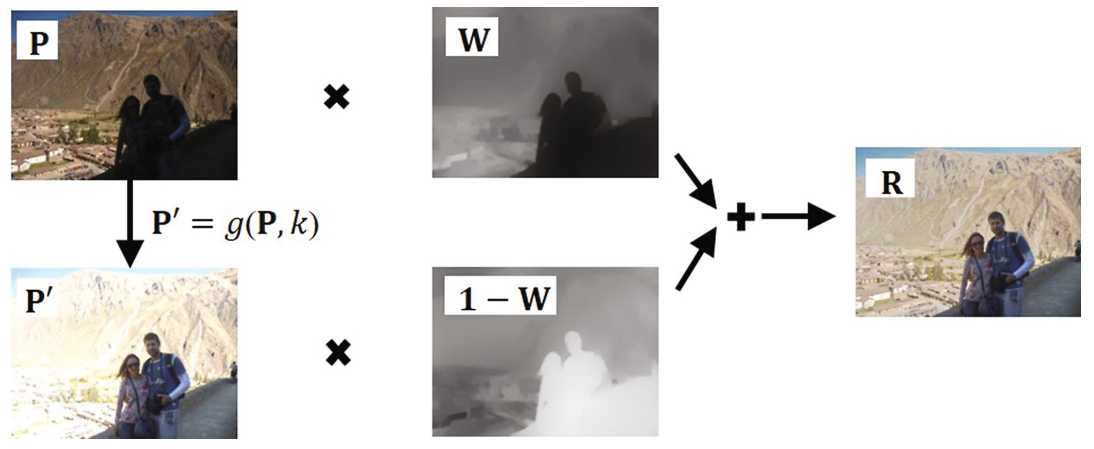
增強問題可分為三個部分:\(W, g, k\) 的三個引數的估計。在以下小節中,我們將一一解決這三個問題。
2.2 權重矩陣估計
\(W\) 是增強演算法的關鍵,其目的是增強曝光不足區域的低對比度,而保留曝光良好區域的對比度。我們需要給曝光良好的畫素分配較大的權重值,給曝光不足的畫素分配較小的權重值。直觀地來說,權重矩陣與場景光照正相關。由於高度光照區域有更大的可能性獲得更好的曝光,應分配給大的權重值以保持它們的對比度。我們計算權重矩陣為:
\[
W=T^{\mu}
\]
其中 \(T\) 是場景光照圖,\(\mu\) 是控制增強程度的引數。場景光照估計位置對映 \(T\) 通過優化的方法解決。
(1)優化問題
亮度分量可以作為場景光照的估計。我們採用亮度分量作為光照估計的初始值:
\[
L(x)=max _{c\in \{R,G,B\}}P_c(x)
\]
對於每個單獨的畫素x。理想照明在結構相似的區域具有區域性一致性。換句話說,\(T\) 應該保持有意義的影象的結構並去除紋理邊緣。在文獻[5]中,我們可以通過最優方程得到 \(T\) :
\[
\min _{\mathbf{T}}\|\mathbf{T}-\mathbf{L}\|_{2}^{2}+\lambda\|\mathbf{M} \circ \nabla \mathbf{T}\|_{1}
\]
其中 \(\|*\|_2\) 和 \(\|*\|_1\) 分別是 \(\ell_2\) 和 \(\ell_1\) 範數。一階微分濾波器 \(\nabla\) 包含水平方向梯度 \(\nabla_h\mathbf{T}\) 和垂直方向梯度 \(\nabla_v\mathbf{T}\)。\(M\) 是權重矩陣,\(\lambda\) 是係數。方程式的第一項最小化初始圖 \(\mathbf{L}\)和場景光照圖\(\mathbf{T}\),而第二項為保證 \(\mathbf{T}\) 的平滑性。
\(\mathbf{M}\) 的設計對於光照圖的細化很重要。區域性視窗中的主要邊緣比具有複雜圖案的紋理貢獻了更多的相似方向梯度。因此,包含有意義的邊緣視窗中的權重應小於僅包含一個視窗的邊緣紋理。因此,我們將權重矩陣設計為
\[
\mathbf{M}_{d}(x)=\frac{1}{\left|\sum_{y \in \omega(x)} \nabla_{d} \mathbf{L}(y)\right|+\epsilon}, \quad d \in\{h, v\}
\]
其中\(| ∗ |\) 是絕對值運算子,\(\omega(x)\) 是以畫素 \(x\) 和 \(\epsilon\) 是一個很小的常數,以避免分母為零。
(2)封閉解
為了簡化複雜度,我們將Eq.6近似為在文獻[5]中公式:
\[
\min _{\mathbf{T}} \sum_{x}\left((\mathbf{T}(x)-\mathbf{L}(x))^{2}+\lambda \sum_{d \in\{h, v\}} \frac{\mathbf{M}_{d}(x)\left(\nabla_{d} \mathbf{T}(x)\right)^{2}}{\left|\nabla_{d} \mathbf{L}(x)\right|+\epsilon}\right)
\]
可以看出,該式子現在僅涉及二次項。 令\(md\),\(l\),\(t\) 和 \(\nabla_dl\) 分別表示向量化的\(\mathbf{M}_d\),\(\mathbf{L}\),\(\mathbf{T}\) 和 \(\nabla_d \mathbf{L}\)。 然後可以通過求解以下線性函式直接獲得解
\[
\left(\mathbf{I}+\lambda \sum_{d \in\{h, v\}}\left(\mathbf{D}_{\mathbf{d}}^{\top} \operatorname{Diag}\left(\mathbf{m}_{d} \oslash\left(\left|\nabla_{d} \mathbf{l}\right|+\epsilon\right)\right) \mathbf{D}_{\mathbf{d}}\right) \mathbf{t}=1\right.
\]
其中\(\varnothing\)是按元素劃分,\(\mathbf{I}\) 是單位矩陣,運算子 \(Diag(v)\) 是用向量 \(v\) 構造對角矩陣,\(\mathbf{D}_d\) 是Toeplitz矩陣來自具有前向差異的離散梯度運算元。我們的光照圖估計方法和文獻[5]的主要區別是設計矩陣\(\mathbf{M}\) 的權重。我們採用了簡化的策略,可以產生在文獻[5]中相似的結果。基於Retinex的其他光照分解技術方法可以運用到這裡來找到權重矩陣 \(\mathbf{W}\)。
2.3 相機響應模型
在我們的早期工作中,我們提出了一個稱為Beta-Gamma的相機響應模型校正模型在文獻[[16]中。我們模型的BTF定義為:
\[
g(\mathbf{P},k)=\beta\mathbf{P^{\gamma}}=e^{b(1-k^a)\mathbf{P^{(k^a)}}}
\]
其中 \(\beta\) 和 \(\gamma\) 是該模型的兩個引數,可以通過相機引數 \(a\) ,\(b\) 和曝光率 \(k\) 計算得到。我們假設沒有任何相機資訊,並使用固定相機引數(\(a = -0.3293\) ,\(b = 1.1258\))可以適配大多數相機。
2.4 確定曝光率
在本小節中,我們找到最佳的曝光率,以便合成影象在原始影象曝光不足的區域中曝光良好。第一,我們排除曝光良好的畫素,並獲得整體上低曝光影象。我們只需提取低光照畫素為:
\[
\mathbf{Q}=\{\mathbf{P}(x)\mathbf{T}(x)<0.5\}
\]
其中 \(\mathbf{Q}\) 僅包含曝光不足的畫素。不同曝光下影象的亮度變化很大但是顏色基本相同。因此,我們在估計 \(k\) 只考慮了亮度分量。亮度分量 \(\mathbf{B}\) 定義為三個通道的幾何平均值:
\[
\mathbf{B}:=\sqrt[3]{\mathbf{Q}_r\circ\mathbf{Q}_g\circ\mathbf{Q}_b}
\]
其中\(\mathbf{Q}_r\),\(\mathbf{Q}_g\) 和 \(\mathbf{Q}_b\) 分別是輸入影象 \(\mathbf{Q}\) 的紅色,綠色和藍色通道。 我們使用幾何平均值代替其他定義(例如算術平均值和加權算術平均值),因為它具有相同的BTF所有三個顏色通道的模型引數( \(\beta\) 和 \(\gamma\)),如下所示:
\[
\begin{aligned} \mathbf{B}^{\prime} &:=\sqrt[3]{\mathbf{Q}_{r}^{\prime} \circ \mathbf{Q}_{g}^{\prime} \circ \mathbf{Q}_{b}^{\prime}} \\ &=\sqrt[3]{\left(\beta \mathbf{Q}_{r}^{\gamma}\right) \circ\left(\beta \mathbf{Q}_{g}^{\gamma}\right) \circ\left(\beta \mathbf{Q}_{b}^{\gamma}\right)}=\beta(\sqrt[3]{\mathbf{Q}_{r} \circ \mathbf{Q}_{g} \circ \mathbf{Q}_{b}})^{\gamma} \\ &=\beta \mathbf{B}^{\gamma} \end{aligned}
\]
曝光良好的影象的可見度高於曝光不足的影象,它可以為人類提供更豐富的資訊。因此,最優的 \(k\) 應該提供最多的資訊。為了衡量資訊的數量,我們使用影象熵來定義:
\[
\mathcal{H}(\mathbf{B})=-\sum_{i=1}^{N} p_{i} \cdot \log _{2} p_{i}
\]
其中 \(p_i\) 是B的直方圖的第i個bin,用於計算資料數量在 \([\frac{i}{N},\frac{i=1}{N}]\),N是bin數( \(N\) 通常設定為256)。最後,通過最大化影象增強的亮度熵來計算最佳 \(k\) 值:
\[
\hat{k}=\underset{k}{\operatorname{argmax}} \mathcal{H}(g(\mathbf{B}, k))
\]
最優的 \(k\) 值可以通過一維最小化求解。為了改善計算效率,我們在優化 \(k\) 時將輸入影象的大小調整為 \(50 \times 50\)。
3. 實驗對比
為了評估我們方法的效能,我們在公開資料集與幾種最新技術(AMSR [9],LIME [5],Dong [4]和NPE [14])進行比較。這五個公共資料集分別為:VV,LIME-data [5],NPE [14](NPEdata,NPE-ex1,NPE-ex2和NPE-ex3),MEF [10]和IUS [8]。 MEF和IUS是多重曝光資料集,我們從每個多重曝光中選擇一個弱光影象進行評估。
3.1 實驗細節
在我們的演算法中,\(\mu\) 是控制整體增強程度的引數。當\(\mu = 0\)時,所得 \(\mathbf{R}\) 等於 \(\mathbf{P}\),即沒有增強效果。 當時,曝光不足畫素和曝光良好畫素均被增強。 當 \(\mu> 1\) 時,畫素可能會飽和,從而導致 \(R\) 遭受細節損失。 為了更好的增強,同時保留曝光良好的區域,我們將 \(\mu\) 設定為1/2。
為了保持比較的公平性,我們增強演算法的引數在所有實驗中都是固定的:\(\lambda = 1\),\(\epsilon=0.001\) ,\(\mu= 1/2\),和區域性視窗\(\omega(x)\)的大小為5。我們演算法中最耗時的部分是光照圖的優化。 我們採用多解析度共軛梯度 \((\mathbf{O}(N))\) 來有效地求解它。 為了進一步加快我們的演算法,我們通過對輸入影象進行下采樣方法解決 \(\mathbf{T}\),然後將生成的 \(\mathbf{T}\) 向上取樣到原始大小。 如果我們向下取樣一次,增強結果中沒有視覺差異,但是計算效率大大提高了。
3.2 對比度失真
如前所述,僅曝光度不同的影象可用作參考來評估增強結果準確性。 DRIM(動態範圍獨立指標)[1]可以測量影象對比度的失真,而無需考慮影象亮度變化。 我們用它來視覺化對比增強結果與參考影象之間的差異。
如圖3所示,該方法得到失真最小的結果。 Dong的結果出現嚴重的對比度失真。 儘管AMSR可以恢復細節,但對比度明顯下降使結果看起來暗淡和虛幻。 相比之下,LIME的結果看起來像有點生動,但它們會導致放大不可見的對比度。 圖5顯示更多示例在視覺上進行比較。

3.3 亮度失真
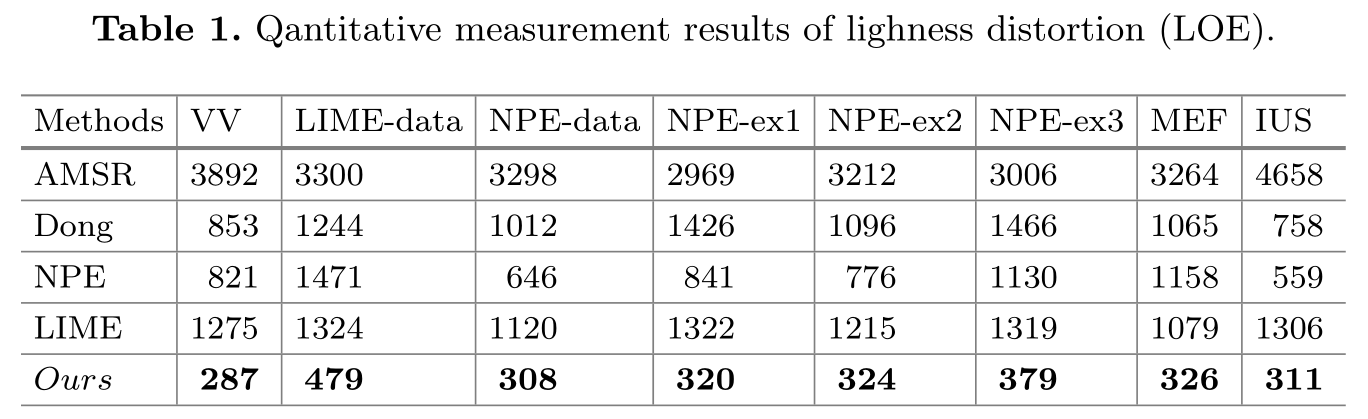
我們用我們使用亮度等級誤差(LOE)客觀地衡量增強結果的亮度失真。 LOE定義為:
\[
LOE=\frac{1}{m}\sum_{x=1}^{m}RD(x)
\]
對於畫素 \(x\), 其中 \(RD(x)\) 是原始影象 \(P\) 和增強後\(P^{'}\) 之間的相對亮度階差,其定義如下:
\[
RD(x)=\sum_{y=1}^{m} U(\mathbf{L}(x), \mathbf{L}(y)) \oplus U\left(\mathbf{L}^{\prime}(x), \mathbf{L}^{\prime}(y)\right)
\]
其中 \(m\) 是畫素數量,\(\oplus\) 表示異或運算子,\(\mathbf{L}(x)\),\(\mathbf{L}^{\prime}(x)\) 分別是輸入影象和增強後位置 \(x\) 處的亮度分量。 如果 \(p>= q\),函式 \(U(p,q)\) 返回1,其他情況為0。
正如[5,14]中所建議的那樣,下采樣用於計算LOE降低複雜度。 由於RD將隨著畫素數量m的增加而增加,我們注意到LOE隨著圖片下采樣為不同尺寸而變化。 因此,我們將所有影象下采樣到固定大小。 具體來說,我們均勻收集100行和列,以形成 \(100\times100\) 的下采樣影象。如表1所示,我們的演算法在所有資料集中均優於其他演算法。 這個意味著我們的演算法可以很好地保持影象的自然性。 我們也提供了圖4中兩種情況的亮度失真的視覺化,從中我們可以發現我們的結果具有最小的亮度失真。AMSR的結果失去了全域性的亮度等級,並具有最大的亮度失真。儘管LIME的結果在視覺上令人愉悅,但它們也存在亮度不足的失真。 Dong和NPE的結果只能在曝光良好的區域保留亮度順序。


4. 結論
在本文中,我們提出了曝光融合框架和增強演算法提供精確的對比度增強的演算法。 基於我們的框架,我們解決了三個問題:(1)我們借鑑了光照估算技術獲得影象融合的權重矩陣。(2)通過相機響應模型來合成多重曝光影象。(3)我們找到了最好的曝光率,使合成影象在原始影象曝光不足的區域曝光良好。 最終的增強結果是通過融合根據權重矩陣對輸入影象和合成影象進行處理。實驗結果表明我們方法相比現階段最先進的方案的有效性。
可以在我們的專案網站上找到更多測試結果:https://baidut.github.io/OpenCE/caip2017.html。
5. 主要參考文獻
- Aydin, T.O., Mantiuk, R., Myszkowski, K., Seidel, H.P.: Dynamic range independent image quality assessment. ACM Trans. Graph. (TOG) 27(3), 69 (2008)
- Beghdadi, A., Le Negrate, A.: Contrast enhancement technique based on local detection of edges. Comput. Vis. Graph. Image Process. 46(2), 162–174 (1989)
- Chen, S.D., Ramli, A.R.: Minimum mean brightness error bi-histogram equalization in contrast enhancement. IEEE Trans. Consum. Electron. 49(4), 1310–1319(2003)
- Dong, X., Wang, G., Pang, Y., Li, W., Wen, J., Meng, W., Lu, Y.: Fast efficient algorithm for enhancement of low lighting video. In: 2011 IEEE International Conference on Multimedia and Expo, pp. 1–6. IEEE (2011)
- Guo, X.: Lime: a method for low-light image enhancement. In: Proceedings of the 2016 ACM on Multimedia Conference, pp. 87–91. ACM (2016)
- Ibrahim, H., Kong, N.S.P.: Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53(4), 1752–1758 (2007)
- Jobson, D.J., Rahman, Z., Woodell, G.A.: A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 6(7), 965–976 (1997)
- Karaduzovic-Hadziabdic, K., Telalovic, J.H., Mantiuk, R.: Subjective and objective evaluation of multi-exposure high dynamic range image deghosting methods (2016)
- Lee, C.H., Shih, J.L., Lien, C.C., Han, C.C.: Adaptive multiscale retinex for image contrast enhancement. In: 2013 International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), pp. 43–50. IEEE (2013)
- Ma, K., Zeng, K., Wang, Z.: Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 24(11), 3345–3356 (2015)
- Peli, E.: Contrast in complex images. JOSA A 7(10), 2032–2040 (1990)
- Reza, A.M.: Realization of the contrast limited adaptive histogram equalization (clahe) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 38(1), 35–44 (2004)
- Wang, C., Ye, Z.: Brightness preserving histogram equalization with maximum entropy: a variational perspective. IEEE Trans. Consum. Electron. 51(4), 1326– 1334 (2005)
- Wang, S., Zheng, J., Hu, H.M., Li, B.: Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 22(9), 3538–3548 (2013)
- Xu, L., Yan, Q., Xia, Y., Jia, J.: Structure extraction from texture via relative total variation. ACM Trans. Graph. (TOG) 31(6), 139 (2012)
- Ying, Z., Li, G., Ren, Y., Wang, R., Wang, W.: A new low-light image enhancement algorithm using camera response model, manuscript submitted for publication (2017)