
【從今天開始好好學資料結構03】連結串列
目錄
今天我們來聊聊“連結串列(Linked list)”這個資料結構。
在我們上一章中【從今天開始好好學資料結構02】棧與佇列棧與佇列底層都是採用順序儲存的這種方式的,而今天要聊的連結串列則是採用鏈式儲存,連結串列可以說是繼陣列之後第二種使用得最廣泛的通用資料結構了,可見其重要性!
相比陣列,連結串列是一種稍微複雜一點的資料結構。對於初學者來說,掌握起來也要比陣列稍難一些。這兩個非常基礎、非常常用的資料結構,我們常常將會放到一塊兒來比較。所以我們先來看,這兩者有什麼區別。陣列需要一塊連續的記憶體空間來儲存,對記憶體的要求比較高。而連結串列恰恰相反,它並不需要一塊連續的記憶體空間,它通過“指標”將一組零散的記憶體塊串聯起來使用,連結串列結構五花八門,今天我重點給你介紹三種最常見的連結串列結構,它們分別是:單鏈表、雙向連結串列和迴圈連結串列。
連結串列通過指標將一組零散的記憶體塊串聯在一起。其中,我們把記憶體塊稱為連結串列的“結點”。為了將所有的結點串起來,每個連結串列的結點除了儲存資料之外,還需要記錄鏈上的下一個結點的地址。而尾結點特殊的地方是:指標不是指向下一個結點,而是指向一個空地址NULL,表示這是連結串列上最後一個結點。
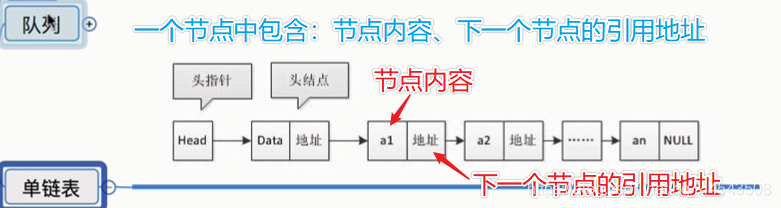
@
單鏈表
package demo2; //一個節點 public class Node { //節點內容 int data; //下一個節點 Node next; public Node(int data) { this.data=data; } //為節點追回節點 public Node append(Node node) { //當前節點 Node currentNode = this; //迴圈向後找 while(true) { //取出下一個節點 Node nextNode = currentNode.next; //如果下一個節點為null,當前節點已經是最後一個節點 if(nextNode==null) { break; } //賦給當前節點 currentNode = nextNode; } //把需要追回的節點追加為找到的當前節點的下一個節點 currentNode.next=node; return this; } //插入一個節點做為當前節點的下一個節點 public void after(Node node) { //取出下一個節點,作為下下一個節點 Node nextNext = next; //把新節點作為當前節點的下一個節點 this.next=node; //把下下一個節點設定為新節點的下一個節點 node.next=nextNext; } //顯示所有節點資訊 public void show() { Node currentNode = this; while(true) { System.out.print(currentNode.data+" "); //取出下一個節點 currentNode=currentNode.next; //如果是最後一個節點 if(currentNode==null) { break; } } System.out.println(); } //刪除下一個節點 public void removeNext() { //取出下下一個節點 Node newNext = next.next; //把下下一個節點設定為當前節點的下一個節點。 this.next=newNext; } //獲取下一個節點 public Node next() { return this.next; } //獲取節點中的資料 public int getData() { return this.data; } //當前節點是否是最後一個節點 public boolean isLast() { return next==null; } }
單鏈表測試類
package demo2.test; import demo2.Node; public class TestNode { public static void main(String[] args) { //建立節點 Node n1 = new Node(1); Node n2 = new Node(2); Node n3 = new Node(3); //追加節點 n1.append(n2).append(n3).append(new Node(4)); //取出下一個節點的資料 // System.out.println(n1.next().next().next().getData()); //判斷節點是否為最後一個節點 // System.out.println(n1.isLast()); // System.out.println(n1.next().next().next().isLast()); //顯示所有節點內容 n1.show(); //刪除一個節點 // n1.next().removeNext(); //顯示所有節點內容 // n1.show(); //插入一個新節點 Node node = new Node(5); n1.next().after(node); n1.show(); } }
連結串列要想隨機訪問第k個元素,就沒有陣列那麼高效了。因為連結串列中的資料並非連續儲存的,所以無法像陣列那樣,根據首地址和下標,通過定址公式就能直接計算出對應的記憶體地址,而是需要根據指標一個結點一個結點地依次遍歷,直到找到相應的結點。
你可以把連結串列想象成一個隊伍,隊伍中的每個人都只知道自己後面的人是誰,所以當我們希望知道排在第k位的人是誰的時候,我們就需要從第一個人開始,一個一個地往下數。所以,連結串列隨機訪問的效能沒有陣列好,需要O(n)的時間複雜度。
雙向連結串列
接下來我們再來看一個稍微複雜的,在實際的軟體開發中,也更加常用的連結串列結構:雙向連結串列。單向連結串列只有一個方向,結點只有一個後繼指標next指向後面的結點。而雙向連結串列,顧名思義,它支援兩個方向,每個結點不止有一個後繼指標next指向後面的結點,還有一個前驅指標prev指向前面的結點。
public class DoubleNode {
//上一個節點
DoubleNode pre=this;
//下一個節點
DoubleNode next=this;
//節點資料
int data;
public DoubleNode(int data) {
this.data=data;
}
//增節點
public void after(DoubleNode node) {
//原來的下一個節點
DoubleNode nextNext = next;
//把新節點做為當前節點的下一個節點
this.next=node;
//把當前節點做新節點的前一個節點
node.pre=this;
//讓原來的下一個節點作新節點的下一個節點
node.next=nextNext;
//讓原來的下一個節點的上一個節點為新節點
nextNext.pre=node;
}
//下一個節點
public DoubleNode next() {
return this.next;
}
//上一個節點
public DoubleNode pre() {
return this.pre;
}
//獲取資料
public int getData() {
return this.data;
}
}
雙向連結串列測試
import demo2.DoubleNode;
public class TestDoubleNode {
public static void main(String[] args) {
//建立節點
DoubleNode n1 = new DoubleNode(1);
DoubleNode n2 = new DoubleNode(2);
DoubleNode n3 = new DoubleNode(3);
//追加節點
n1.after(n2);
n2.after(n3);
//檢視上一個,自己,下一個節點的內容
System.out.println(n2.pre().getData());
System.out.println(n2.getData());
System.out.println(n2.next().getData());
System.out.println(n3.next().getData());
System.out.println(n1.pre().getData());
}
}
單鏈表VS雙向連結串列
如果我們希望在連結串列的某個指定結點前面插入一個結點或者刪除操作,雙向連結串列比單鏈表有很大的優勢。雙向連結串列可以在O(1)時間複雜度搞定,而單向連結串列需要O(n)的時間複雜度,除了插入、刪除操作有優勢之外,對於一個有序連結串列,雙向連結串列的按值查詢的效率也要比單鏈表高一些。因為,我們可以記錄上次查詢的位置p,每次查詢時,根據要查詢的值與p的大小關係,決定是往前還是往後查詢,所以平均只需要查詢一半的資料。
現在,你有沒有覺得雙向連結串列要比單鏈表更加高效呢?這就是為什麼在實際的軟體開發中,雙向連結串列儘管比較費記憶體,但還是比單鏈表的應用更加廣泛的原因。如果你熟悉Java語言,你肯定用過LinkedHashMap這個容器。如果你深入研究LinkedHashMap的實現原理,就會發現其中就用到了雙向連結串列這種資料結構。實際上,這裡有一個更加重要的知識點需要你掌握,那就是用空間換時間的設計思想。當記憶體空間充足的時候,如果我們更加追求程式碼的執行速度,我們就可以選擇空間複雜度相對較高、但時間複雜度相對很低的演算法或者資料結構。相反,如果記憶體比較緊缺,比如程式碼跑在手機或者微控制器上,這個時候,就要反過來用時間換空間的設計思路。
迴圈連結串列
迴圈連結串列是一種特殊的單鏈表。實際上,迴圈連結串列也很簡單。它跟單鏈表唯一的區別就在尾結點。我們知道,單鏈表的尾結點指標指向空地址,表示這就是最後的結點了。而迴圈連結串列的尾結點指標是指向連結串列的頭結點。和單鏈表相比,迴圈連結串列的優點是從鏈尾到鏈頭比較方便。當要處理的資料具有環型結構特點時,就特別適合採用迴圈連結串列。比如著名的約瑟夫問題。儘管用單鏈表也可以實現,但是用迴圈連結串列實現的話,程式碼就會簡潔很多。
package demo2;
//一個節點
public class LoopNode {
//節點內容
int data;
//下一個節點
LoopNode next=this;
public LoopNode(int data) {
this.data=data;
}
//插入一個節點做為當前節點的下一個節點
public void after(LoopNode node) {
//取出下一個節點,作為下下一個節點
LoopNode nextNext = next;
//把新節點作為當前節點的下一個節點
this.next=node;
//把下下一個節點設定為新節點的下一個節點
node.next=nextNext;
}
//刪除下一個節點
public void removeNext() {
//取出下下一個節點
LoopNode newNext = next.next;
//把下下一個節點設定為當前節點的下一個節點。
this.next=newNext;
}
//獲取下一個節點
public LoopNode next() {
return this.next;
}
//獲取節點中的資料
public int getData() {
return this.data;
}
}
迴圈連結串列測試
package demo2.test;
import demo2.LoopNode;
public class TestLoopNode {
public static void main(String[] args) {
LoopNode n1 = new LoopNode(1);
LoopNode n2 = new LoopNode(2);
LoopNode n3 = new LoopNode(3);
LoopNode n4 = new LoopNode(4);
//增加節點
n1.after(n2);
n2.after(n3);
n3.after(n4);
System.out.println(n1.next().getData());
System.out.println(n2.next().getData());
System.out.println(n3.next().getData());
System.out.println(n4.next().getData());
}
}
最後,我們再對比一下陣列,陣列的缺點是大小固定,一經宣告就要佔用整塊連續記憶體空間。如果宣告的陣列過大,系統可能沒有足夠的連續記憶體空間分配給它,導致“記憶體不足(out of memory)”。如果宣告的陣列過小,則可能出現不夠用的情況。這時只能再申請一個更大的記憶體空間,把原陣列拷貝進去,非常費時。連結串列本身沒有大小的限制,天然地支援動態擴容,我覺得這也是它與陣列最大的區別。
你可能會說,我們Java中的ArrayList容器,也可以支援動態擴容啊?事實上當我們往支援動態擴容的陣列中插入一個數據時,如果陣列中沒有空閒空間了,就會申請一個更大的空間,將資料拷貝過去,而資料拷貝的操作是非常耗時的。
我舉一個稍微極端的例子。如果我們用ArrayList儲存了了1GB大小的資料,這個時候已經沒有空閒空間了,當我們再插入資料的時候,ArrayList會申請一個1.5GB大小的儲存空間,並且把原來那1GB的資料拷貝到新申請的空間上。聽起來是不是就很耗時?
除此之外,如果你的程式碼對記憶體的使用非常苛刻,那陣列就更適合你。因為連結串列中的每個結點都需要消耗額外的儲存空間去儲存一份指向下一個結點的指標,所以記憶體消耗會翻倍。而且,對連結串列進行頻繁的插入、刪除操作,還會導致頻繁的記憶體申請和釋放,容易造成記憶體碎片,如果是Java語言,就有可能會導致頻繁的GC(Garbage Collection,垃圾回收)。
所以,在我們實際的開發中,針對不同型別的專案,要根據具體情況,權衡究竟是選擇陣列還是連結串列!
如果本文對你有一點點幫助,那麼請點個讚唄,謝謝~
最後,若有不足或者不正之處,歡迎指正批評,感激不盡!如果有疑問歡迎留言,絕對第一時間回覆!
歡迎各位關注我的公眾號,一起探討技術,嚮往技術,追求技術,說好了來了就是盆友喔...

相關推薦
【從今天開始好好學資料結構03】連結串列
目錄 今天我們來聊聊“連結串列(Linked list)”這個資料結構。 在我們上一章中【從今天開始好好學資料結構02】棧與佇列棧與佇列底層都是採用順序儲存的這種方式的,而今天要聊的連結串列則是採用鏈式儲存,連結串列可以說是繼陣列之後第二種使用得最廣泛的通用資
【從今天開始好好學資料結構01】陣列
面試的時候,常常會問陣列和連結串列的區別,很多人都回答說,“連結串列適合插入、刪除,時間複雜度O(1);陣列適合查詢,查詢時間複雜度為O(1)”。實際上,這種表述是不準確的。陣列是適合查詢操作,但是查詢的時間複雜度並不為O(1)。即便是排好序的陣列,你用二分查詢,時間複雜度也是O(logn)。所以,正確的表述
【從今天開始好好學資料結構02】棧與佇列
目錄 1、理解棧與佇列 2、用程式碼談談棧 3、用程式碼談談佇列 我們今天主要來談談“棧”以及佇列這兩種資料結構。 回顧一下上一章中【資料結構01】陣列中,在陣列中只要知道資料的下標,便可通過順
【從今天開始好好學資料結構04】程式設計師你心中就沒點“樹”嗎?
目錄 樹(Tree) 二叉樹(Binary Tree) 前面我們講的都是線性表結構,棧、佇列等等。今天我們講一種非線性表結構,樹。樹這種資料結構比線性表的資料結構要複雜得多,內容也比較多,首先我們先從樹(Tre
資料結構03--靜態連結串列
靜態連結串列 靜態連結串列: 對靜態連結串列進行初始化相當於初始化陣列: Status InitList(StaticLinkList space) { int i; for( i=0; i<MAXSIZE-1;i++) space[i].cur = i+1; s
從今天開始學習資料結構(c++/c)---連結串列
先實現這麼多功能,後續再填程式碼(本人一菜渣,c式鬧著玩程式設計如下): #include <iostream> using namespace std; struct Node{ int value; Node *next;
【從零開始/親測國內外均可】基於阿里雲Ubuntu的kubernetes(k8s)主從節點分散式叢集搭建——分步詳細攻略v1.11.3【準備工作篇】
從零開始搭建k8s叢集——香港節點無牆篇【大陸節點有牆的安裝方法我會在每一步操作的時候提醒大家的注意,並告訴大家如何操作】 由於容器技術的火爆,現在使用K8s開展服務變得越來越廣泛了。 本攻略是基於阿里雲主機搭建的一個單主節點和單從節點的最簡k8s分散式叢集。 為了製作
【從零開始學架構-李運華】07|低成本、安全、規模
低成本 高效能和高可用架構通常都是增加伺服器來滿足要求,但低成本正相反,當然也不是首要目標。 往往“創新”才能達到低成本的目標!! 技術創新: NoSQL(Memcache、Redis)等是為了解決關係型資料庫無法應對高併發帶來的訪問壓力。
【從零開始學架構-李運華】03|架構設計的目的
架構設計的誤區 系統不一定需要架構設計; 架構設計不一定能提升開發效率; 好的架構設計能促進業務發展; 不是所有系統都需要架構設計; 等等…… 架構設計的真正目的 為了解決軟體複雜度帶來的問題 如何下手架構設計?
【從零開始學架構-李運華】10|架構設計流程:識別複雜度
架構設計第一步:識別複雜度 架構設計的本質目的是為了解決系統複雜性,所以要先了解。 【例】一個系統的複雜度來源於業務邏輯複雜,功能耦合度嚴重,架構師設計TPS達到50000/s的高效能架構沒有意義。 出現問題主要為了滿足“高可用”“高效能”“可擴充套件”三
【從零開始學架構-李運華】06|複雜地來源:可擴充套件性
可擴充套件性指系統為了應對將來需求的變化而提供的一種擴充套件能力,新需求出現時系統不需要或者僅需要少量修改就可以支援,無需整個系統重構或者重建。 面向物件就是為了解決可擴充套件性,後來的設計模式更是將可擴充套件性做到了極致。 具備良好擴充套件性的
字串資料結構實現(連結串列方式)
相較於陣列方式的實現,C語言我採用了單鏈表的方式實現,C++採用了雙鏈表的方式。毫無疑問,雙鏈表的效率肯定是要遠高於單鏈表的。這次支援中文字元的操作,這個實現的思路是,在節點類中新增兩個成員變數,一個用來存放char字元,一個用來存放wchar_t字元。關於兩者的相互轉換及輸出請參考 C語言
SDUTOJ-2054 資料結構實驗之連結串列九:雙向連結串列
題目連結 #include <iostream> #include <cstdlib> using namespace std; typedef int ElementType; typedef struct node { ElementType
SDUTOJ-3331 資料結構實驗之連結串列八:Farey序列
連結串列節點插入練習題 題目連結 #include <stdio.h> #include <cstdlib> using namespace std; typedef int ElementType; typedef struct node { Elemen
資料結構-單向連結串列
package com.mzs.demo5; public class Node { private int data; private Node next; public Node(int data) { this.data = data; } public void
java版資料結構與演算法—連結串列實現佇列
package com.zoujc.QueueLink; /** * 連結串列實現佇列 */ class FirstLastList { private Link first; private Link last; public FirstLastList(){
java版資料結構與演算法—連結串列實現棧
package com.zoujc; /** * 用連結串列實現棧 */ class MyLinkStack { private Link first; public MyLinkStack(){ first = null; } //判空
JS資料結構和演算法 --- 連結串列
概念:性質類似於陣列,是計算機的一種儲存結構。連結串列由一系列結點組成,每個結點裡包含了本結點的資料域和指向下一個結點的指標(裡面儲存著下一個結點)。 作用:按一定順序儲存資料,允許在任意位置插入和刪除結點。 分類:雙向連結串列、迴圈連結串列 應用場景:對線性表的長度或者規模難
嚴蔚敏版資料結構——佇列(連結串列實現)
佇列有兩種表示方式,我們再看連結串列實現: 個人感覺佇列也就是連結串列的一種特殊表,如果前面的連結串列知識通關了這裡隨便看看記住佇列的遊戲規則就行了。還是和前面一樣,先要有頭結點,總體來說就是單鏈表的插刪。 這裡與順序佇列不同的是不需要判斷佇列是不是滿了,連結串列最大的特點是動態分配節點空間
資料結構實驗之連結串列一:順序建立連結串列(SDUT 2116)
Problem Description 輸入N個整數,按照輸入的順序建立單鏈表儲存,並遍歷所建立的單鏈表,輸出這些資料。 Input 第一行輸入整數的個數N; 第二行依次輸入每個整數。 Outp