
深入理解Kafka必知必會(2)
深入理解Kafka必知必會(1)
Kafka目前有哪些內部topic,它們都有什麼特徵?各自的作用又是什麼?
__consumer_offsets:作用是儲存 Kafka 消費者的位移資訊
__transaction_state:用來儲存事務日誌訊息
優先副本是什麼?它有什麼特殊的作用?
所謂的優先副本是指在AR集合列表中的第一個副本。
理想情況下,優先副本就是該分割槽的leader 副本,所以也可以稱之為 preferred leader。Kafka 要確保所有主題的優先副本在 Kafka 叢集中均勻分佈,這樣就保證了所有分割槽的 leader 均衡分佈。以此來促進叢集的負載均衡,這一行為也可以稱為“分割槽平衡”。
Kafka有哪幾處地方有分割槽分配的概念?簡述大致的過程及原理
- 生產者的分割槽分配是指為每條訊息指定其所要發往的分割槽。可以編寫一個具體的類實現org.apache.kafka.clients.producer.Partitioner介面。
- 消費者中的分割槽分配是指為消費者指定其可以消費訊息的分割槽。Kafka 提供了消費者客戶端引數 partition.assignment.strategy 來設定消費者與訂閱主題之間的分割槽分配策略。
- 分割槽副本的分配是指為叢集制定建立主題時的分割槽副本分配方案,即在哪個 broker 中建立哪些分割槽的副本。kafka-topics.sh 指令碼中提供了一個 replica-assignment 引數來手動指定分割槽副本的分配方案。
簡述Kafka的日誌目錄結構
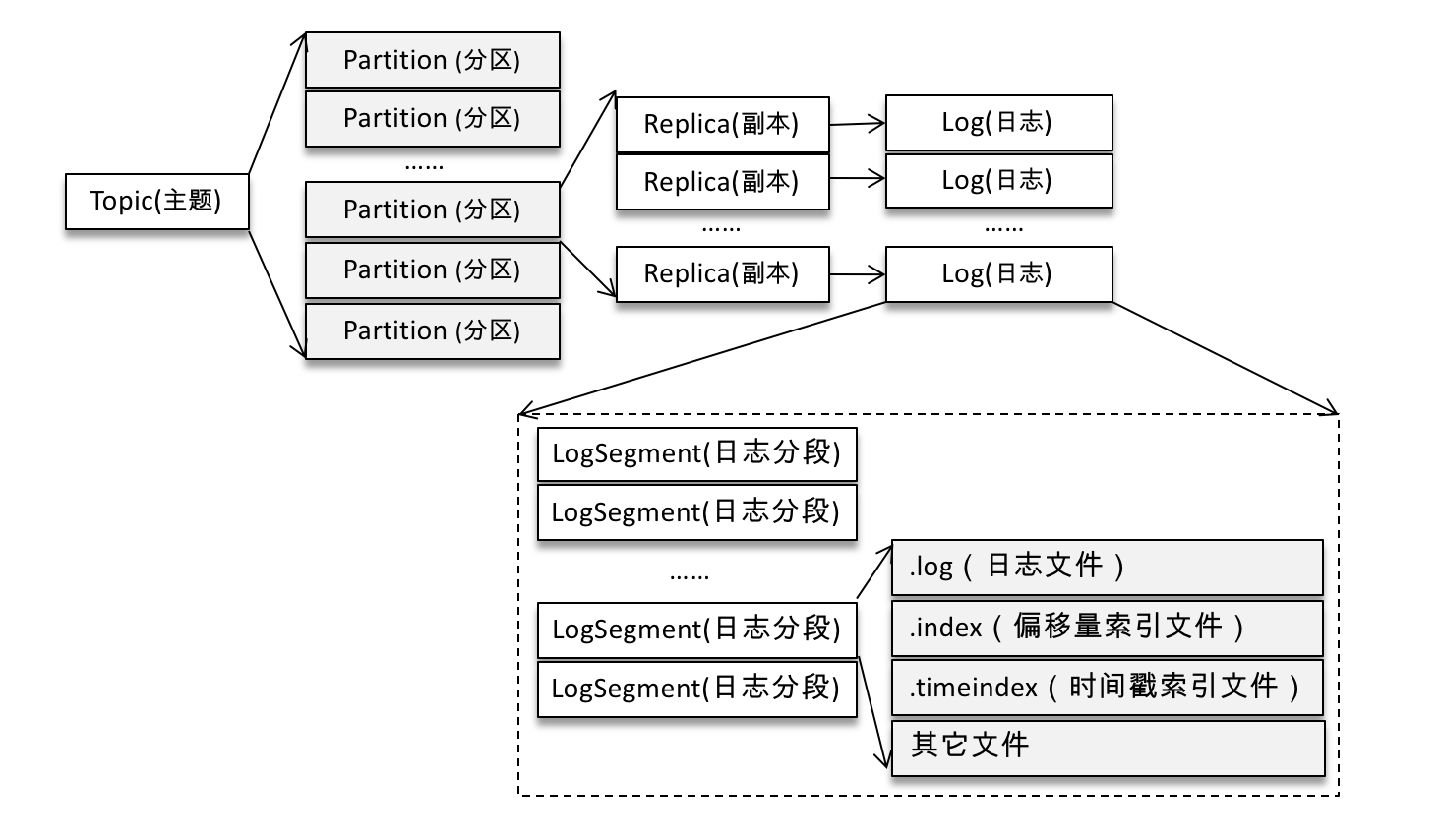
Kafka 中的訊息是以主題為基本單位進行歸類的,各個主題在邏輯上相互獨立。每個主題又可以分為一個或多個分割槽。不考慮多副本的情況,一個分割槽對應一個日誌(Log)。為了防止 Log 過大,Kafka 又引入了日誌分段(LogSegment)的概念,將 Log 切分為多個 LogSegment,相當於一個巨型檔案被平均分配為多個相對較小的檔案。
Log 和 LogSegment 也不是純粹物理意義上的概念,Log 在物理上只以資料夾的形式儲存,而每個 LogSegment 對應於磁碟上的一個日誌檔案和兩個索引檔案,以及可能的其他檔案(比如以“.txnindex”為字尾的事務索引檔案)
Kafka中有那些索引檔案?
每個日誌分段檔案對應了兩個索引檔案,主要用來提高查詢訊息的效率。
偏移量索引檔案用來建立訊息偏移量(offset)到實體地址之間的對映關係,方便快速定位訊息所在的物理檔案位置
時間戳索引檔案則根據指定的時間戳(timestamp)來查詢對應的偏移量資訊。
如果我指定了一個offset,Kafka怎麼查詢到對應的訊息?
Kafka是通過seek() 方法來指定消費的,在執行seek() 方法之前要去執行一次poll()方法,等到分配到分割槽之後會去對應的分割槽的指定位置開始消費,如果指定的位置發生了越界,那麼會根據auto.offset.reset 引數設定的情況進行消費。
如果我指定了一個timestamp,Kafka怎麼查詢到對應的訊息?
Kafka提供了一個 offsetsForTimes() 方法,通過 timestamp 來查詢與此對應的分割槽位置。offsetsForTimes() 方法的引數 timestampsToSearch 是一個 Map 型別,key 為待查詢的分割槽,而 value 為待查詢的時間戳,該方法會返回時間戳大於等於待查詢時間的第一條訊息對應的位置和時間戳,對應於 OffsetAndTimestamp 中的 offset 和 timestamp 欄位。
聊一聊你對Kafka的Log Retention的理解
日誌刪除(Log Retention):按照一定的保留策略直接刪除不符合條件的日誌分段。
我們可以通過 broker 端引數 log.cleanup.policy 來設定日誌清理策略,此引數的預設值為“delete”,即採用日誌刪除的清理策略。
基於時間
日誌刪除任務會檢查當前日誌檔案中是否有保留時間超過設定的閾值(retentionMs)來尋找可刪除的日誌分段檔案集合(deletableSegments)retentionMs 可以通過 broker 端引數 log.retention.hours、log.retention.minutes 和 log.retention.ms 來配置,其中 log.retention.ms 的優先順序最高,log.retention.minutes 次之,log.retention.hours 最低。預設情況下只配置了 log.retention.hours 引數,其值為168,故預設情況下日誌分段檔案的保留時間為7天。
刪除日誌分段時,首先會從 Log 物件中所維護日誌分段的跳躍表中移除待刪除的日誌分段,以保證沒有執行緒對這些日誌分段進行讀取操作。然後將日誌分段所對應的所有檔案新增上“.deleted”的字尾(當然也包括對應的索引檔案)。最後交由一個以“delete-file”命名的延遲任務來刪除這些以“.deleted”為字尾的檔案,這個任務的延遲執行時間可以通過 file.delete.delay.ms 引數來調配,此引數的預設值為60000,即1分鐘。- 基於日誌大小
日誌刪除任務會檢查當前日誌的大小是否超過設定的閾值(retentionSize)來尋找可刪除的日誌分段的檔案集合(deletableSegments)。
retentionSize 可以通過 broker 端引數 log.retention.bytes 來配置,預設值為-1,表示無窮大。注意 log.retention.bytes 配置的是 Log 中所有日誌檔案的總大小,而不是單個日誌分段(確切地說應該為 .log 日誌檔案)的大小。單個日誌分段的大小由 broker 端引數 log.segment.bytes 來限制,預設值為1073741824,即 1GB。
這個刪除操作和基於時間的保留策略的刪除操作相同。 基於日誌起始偏移量
基於日誌起始偏移量的保留策略的判斷依據是某日誌分段的下一個日誌分段的起始偏移量 baseOffset 是否小於等於 logStartOffset,若是,則可以刪除此日誌分段。
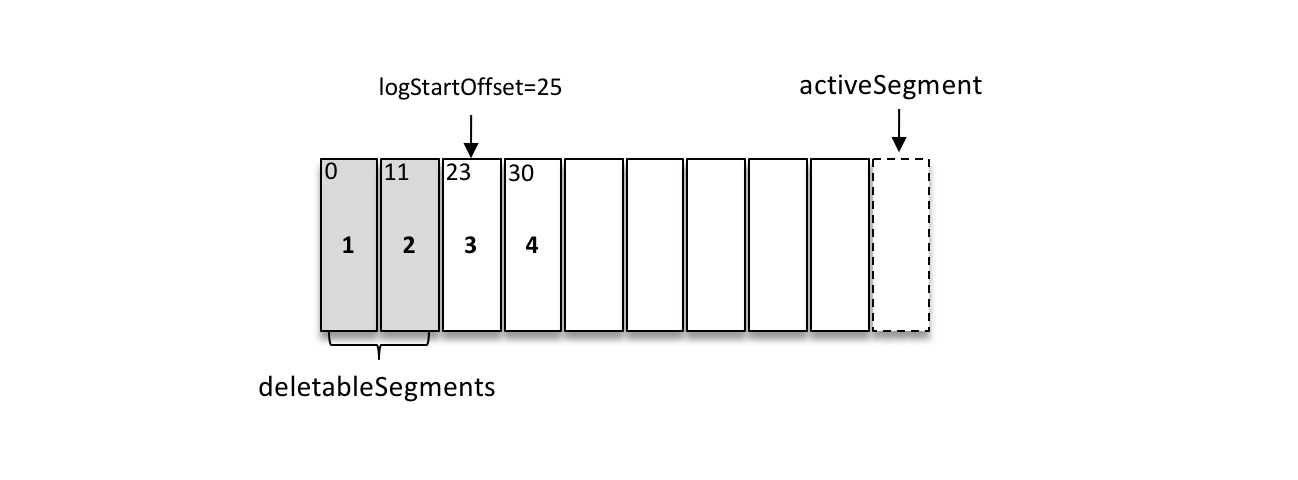
如上圖所示,假設 logStartOffset 等於25,日誌分段1的起始偏移量為0,日誌分段2的起始偏移量為11,日誌分段3的起始偏移量為23,通過如下動作收集可刪除的日誌分段的檔案集合 deletableSegments:
從頭開始遍歷每個日誌分段,日誌分段1的下一個日誌分段的起始偏移量為11,小於 logStartOffset 的大小,將日誌分段1加入 deletableSegments。
日誌分段2的下一個日誌偏移量的起始偏移量為23,也小於 logStartOffset 的大小,將日誌分段2加入 deletableSegments。
日誌分段3的下一個日誌偏移量在 logStartOffset 的右側,故從日誌分段3開始的所有日誌分段都不會加入 deletableSegments。
收集完可刪除的日誌分段的檔案集合之後的刪除操作同基於日誌大小的保留策略和基於時間的保留策略相同
聊一聊你對Kafka的Log Compaction的理解
日誌壓縮(Log Compaction):針對每個訊息的 key 進行整合,對於有相同 key 的不同 value 值,只保留最後一個版本。
如果要採用日誌壓縮的清理策略,就需要將 log.cleanup.policy 設定為“compact”,並且還需要將 log.cleaner.enable (預設值為 true)設定為 true。
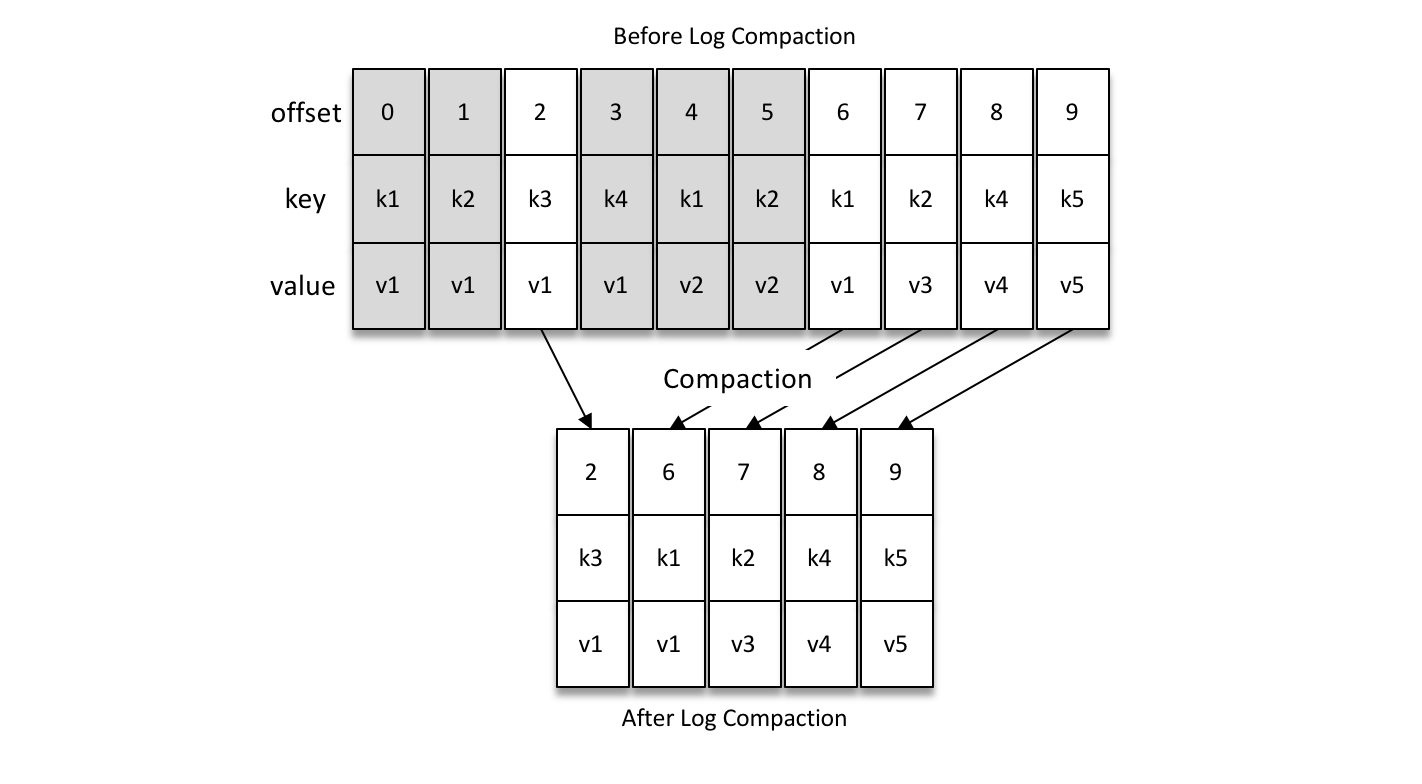
如下圖所示,Log Compaction 對於有相同 key 的不同 value 值,只保留最後一個版本。如果應用只關心 key 對應的最新 value 值,則可以開啟 Kafka 的日誌清理功能,Kafka 會定期將相同 key 的訊息進行合併,只保留最新的 value 值。
聊一聊你對Kafka底層儲存的理解
頁快取
頁快取是作業系統實現的一種主要的磁碟快取,以此用來減少對磁碟 I/O 的操作。具體來說,就是把磁碟中的資料快取到記憶體中,把對磁碟的訪問變為對記憶體的訪問。
當一個程序準備讀取磁碟上的檔案內容時,作業系統會先檢視待讀取的資料所在的頁(page)是否在頁快取(pagecache)中,如果存在(命中)則直接返回資料,從而避免了對物理磁碟的 I/O 操作;如果沒有命中,則作業系統會向磁碟發起讀取請求並將讀取的資料頁存入頁快取,之後再將資料返回給程序。
同樣,如果一個程序需要將資料寫入磁碟,那麼作業系統也會檢測資料對應的頁是否在頁快取中,如果不存在,則會先在頁快取中新增相應的頁,最後將資料寫入對應的頁。被修改過後的頁也就變成了髒頁,作業系統會在合適的時間把髒頁中的資料寫入磁碟,以保持資料的一致性。
用過 Java 的人一般都知道兩點事實:物件的記憶體開銷非常大,通常會是真實資料大小的幾倍甚至更多,空間使用率低下;Java 的垃圾回收會隨著堆內資料的增多而變得越來越慢。基於這些因素,使用檔案系統並依賴於頁快取的做法明顯要優於維護一個程序內快取或其他結構,至少我們可以省去了一份程序內部的快取消耗,同時還可以通過結構緊湊的位元組碼來替代使用物件的方式以節省更多的空間。
此外,即使 Kafka 服務重啟,頁快取還是會保持有效,然而程序內的快取卻需要重建。這樣也極大地簡化了程式碼邏輯,因為維護頁快取和檔案之間的一致性交由作業系統來負責,這樣會比程序內維護更加安全有效。
零拷貝
除了訊息順序追加、頁快取等技術,Kafka 還使用零拷貝(Zero-Copy)技術來進一步提升效能。所謂的零拷貝是指將資料直接從磁碟檔案複製到網絡卡裝置中,而不需要經由應用程式之手。零拷貝大大提高了應用程式的效能,減少了核心和使用者模式之間的上下文切換。對 Linux 作業系統而言,零拷貝技術依賴於底層的 sendfile() 方法實現。對應於 Java 語言,FileChannal.transferTo() 方法的底層實現就是 sendfile() 方法。
聊一聊Kafka的延時操作的原理
Kafka 中有多種延時操作,比如延時生產,還有延時拉取(DelayedFetch)、延時資料刪除(DelayedDeleteRecords)等。
延時操作建立之後會被加入延時操作管理器(DelayedOperationPurgatory)來做專門的處理。延時操作有可能會超時,每個延時操作管理器都會配備一個定時器(SystemTimer)來做超時管理,定時器的底層就是採用時間輪(TimingWheel)實現的。
聊一聊Kafka控制器的作用
在 Kafka 叢集中會有一個或多個 broker,其中有一個 broker 會被選舉為控制器(Kafka Controller),它負責管理整個叢集中所有分割槽和副本的狀態。當某個分割槽的 leader 副本出現故障時,由控制器負責為該分割槽選舉新的 leader 副本。當檢測到某個分割槽的 ISR 集合發生變化時,由控制器負責通知所有broker更新其元資料資訊。當使用 kafka-topics.sh 指令碼為某個 topic 增加分割槽數量時,同樣還是由控制器負責分割槽的重新分配。
Kafka的舊版Scala的消費者客戶端的設計有什麼缺陷?
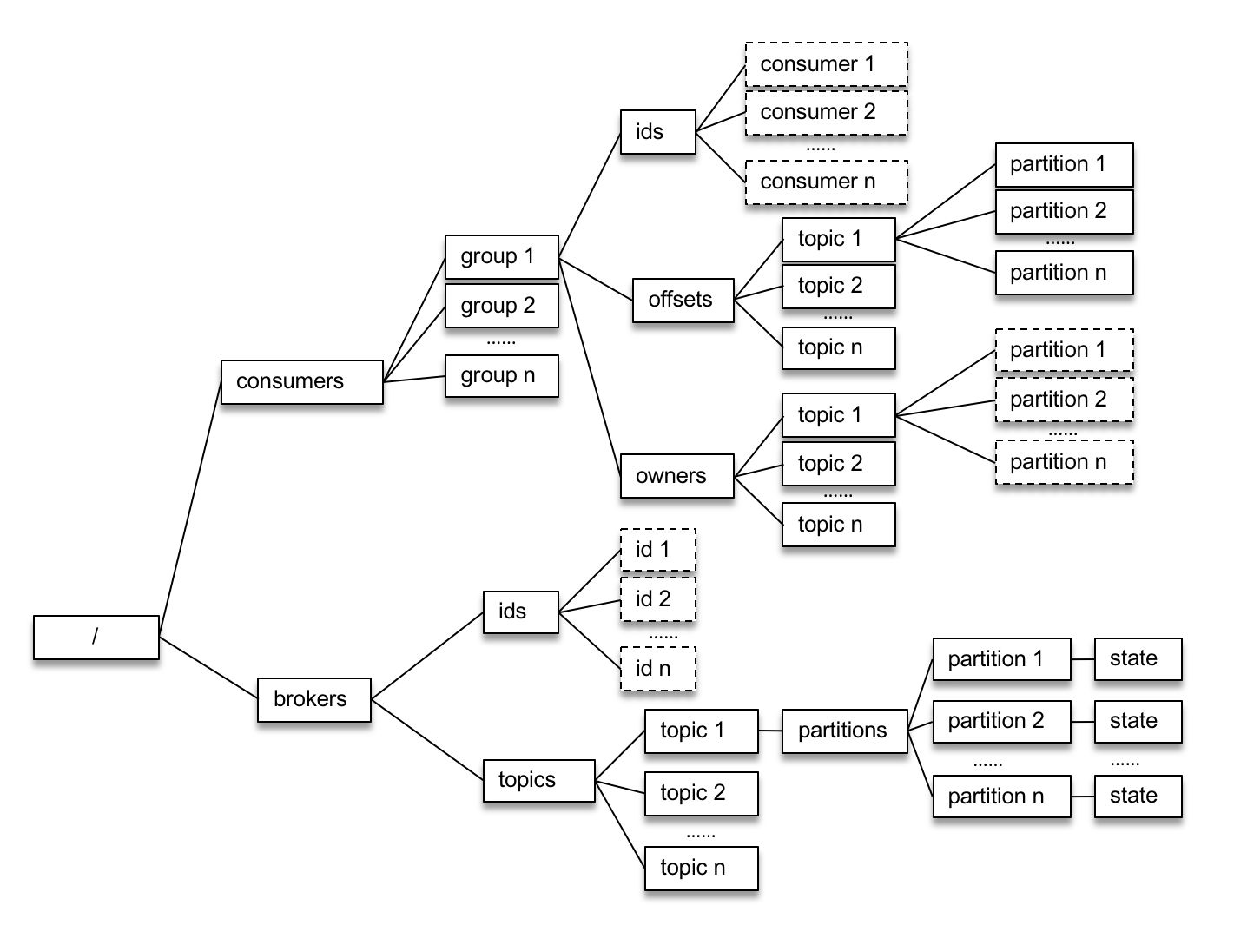
如上圖,舊版消費者客戶端每個消費組(
每個消費者在啟動時都會在 /consumers/
這種方式下每個消費者對 ZooKeeper 的相關路徑分別進行監聽,當觸發再均衡操作時,一個消費組下的所有消費者會同時進行再均衡操作,而消費者之間並不知道彼此操作的結果,這樣可能導致 Kafka 工作在一個不正確的狀態。與此同時,這種嚴重依賴於 ZooKeeper 叢集的做法還有兩個比較嚴重的問題。
- 羊群效應(Herd Effect):所謂的羊群效應是指ZooKeeper 中一個被監聽的節點變化,大量的 Watcher 通知被髮送到客戶端,導致在通知期間的其他操作延遲,也有可能發生類似死鎖的情況。
- 腦裂問題(Split Brain):消費者進行再均衡操作時每個消費者都與 ZooKeeper 進行通訊以判斷消費者或broker變化的情況,由於 ZooKeeper 本身的特性,可能導致在同一時刻各個消費者獲取的狀態不一致,這樣會導致異常問題發生。
消費再均衡的原理是什麼?(提示:消費者協調器和消費組協調器)
就目前而言,一共有如下幾種情形會觸發再均衡的操作:
- 有新的消費者加入消費組。
- 有消費者宕機下線。消費者並不一定需要真正下線,例如遇到長時間的GC、網路延遲導致消費者長時間未向 GroupCoordinator 傳送心跳等情況時,GroupCoordinator 會認為消費者已經下線。
- 有消費者主動退出消費組(傳送 LeaveGroupRequest 請求)。比如客戶端呼叫了 unsubscrible() 方法取消對某些主題的訂閱。
- 消費組所對應的 GroupCoorinator 節點發生了變更。
- 消費組內所訂閱的任一主題或者主題的分割槽數量發生變化。
GroupCoordinator 是 Kafka 服務端中用於管理消費組的元件。而消費者客戶端中的 ConsumerCoordinator 元件負責與 GroupCoordinator 進行互動。
第一階段(FIND_COORDINATOR)
消費者需要確定它所屬的消費組對應的 GroupCoordinator 所在的 broker,並建立與該 broker 相互通訊的網路連線。如果消費者已經儲存了與消費組對應的 GroupCoordinator 節點的資訊,並且與它之間的網路連線是正常的,那麼就可以進入第二階段。否則,就需要向叢集中的某個節點發送 FindCoordinatorRequest 請求來查詢對應的 GroupCoordinator,這裡的“某個節點”並非是叢集中的任意節點,而是負載最小的節點。
第二階段(JOIN_GROUP)
在成功找到消費組所對應的 GroupCoordinator 之後就進入加入消費組的階段,在此階段的消費者會向 GroupCoordinator 傳送 JoinGroupRequest 請求,並處理響應。
選舉消費組的leader
如果消費組內還沒有 leader,那麼第一個加入消費組的消費者即為消費組的 leader。如果某一時刻 leader 消費者由於某些原因退出了消費組,那麼會重新選舉一個新的 leader
選舉分割槽分配策略
- 收集各個消費者支援的所有分配策略,組成候選集 candidates。
- 每個消費者從候選集 candidates 中找出第一個自身支援的策略,為這個策略投上一票。
- 計算候選集中各個策略的選票數,選票數最多的策略即為當前消費組的分配策略。
第三階段(SYNC_GROUP)
leader 消費者根據在第二階段中選舉出來的分割槽分配策略來實施具體的分割槽分配,在此之後需要將分配的方案同步給各個消費者,通過 GroupCoordinator 這個“中間人”來負責轉發同步分配方案的。
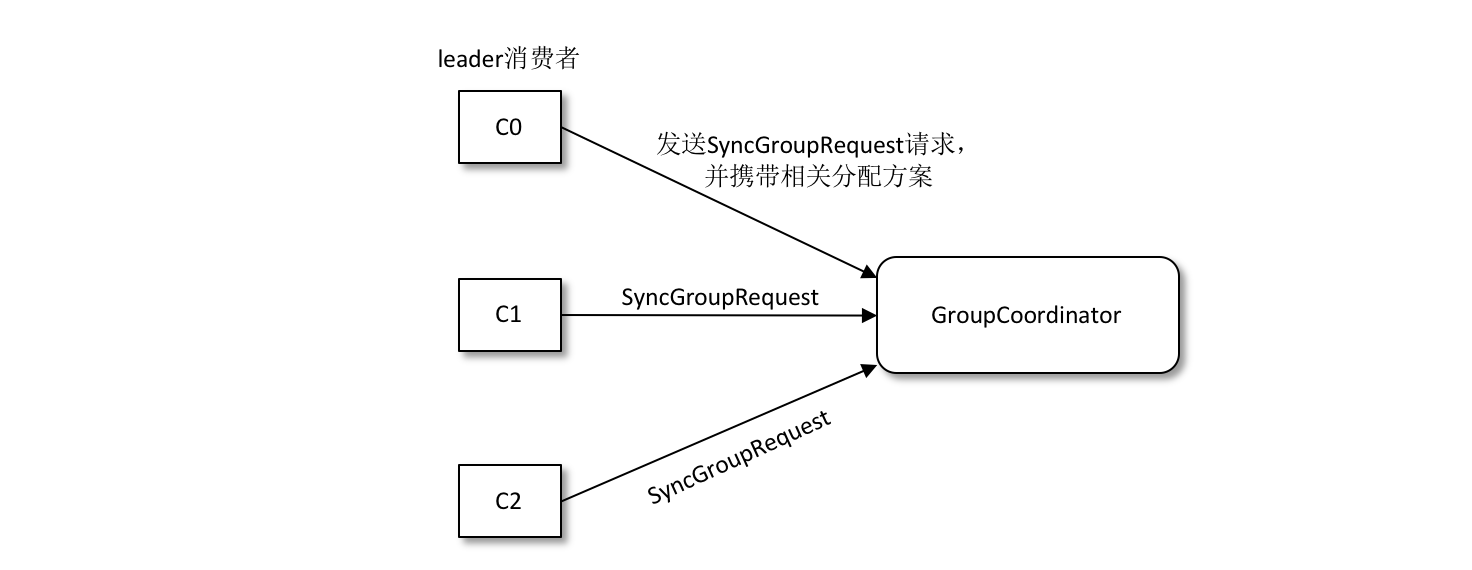
第四階段(HEARTBEAT)
進入這個階段之後,消費組中的所有消費者就會處於正常工作狀態。在正式消費之前,消費者還需要確定拉取訊息的起始位置。假設之前已經將最後的消費位移提交到了 GroupCoordinator,並且 GroupCoordinator 將其儲存到了 Kafka 內部的 __consumer_offsets 主題中,此時消費者可以通過 OffsetFetchRequest 請求獲取上次提交的消費位移並從此處繼續消費。
消費者通過向 GroupCoordinator 傳送心跳來維持它們與消費組的從屬關係,以及它們對分割槽的所有權關係。只要消費者以正常的時間間隔傳送心跳,就被認為是活躍的,說明它還在讀取分割槽中的訊息。心跳執行緒是一個獨立的執行緒,可以在輪詢訊息的空檔傳送心跳。如果消費者停止傳送心跳的時間足夠長,則整個會話就被判定為過期,GroupCoordinator 也會認為這個消費者已經死亡,就會觸發一次再均衡行為。
Kafka中的冪等是怎麼實現的?
為了實現生產者的冪等性,Kafka 為此引入了 producer id(以下簡稱 PID)和序列號(sequence number)這兩個概念。
每個新的生產者例項在初始化的時候都會被分配一個 PID,這個 PID 對使用者而言是完全透明的。對於每個 PID,訊息傳送到的每一個分割槽都有對應的序列號,這些序列號從0開始單調遞增。生產者每傳送一條訊息就會將 <PID,分割槽> 對應的序列號的值加1。
broker 端會在記憶體中為每一對 <PID,分割槽> 維護一個序列號。對於收到的每一條訊息,只有當它的序列號的值(SN_new)比 broker 端中維護的對應的序列號的值(SN_old)大1(即 SN_new = SN_old + 1)時,broker 才會接收它。如果 SN_new< SN_old + 1,那麼說明訊息被重複寫入,broker 可以直接將其丟棄。如果 SN_new> SN_old + 1,那麼說明中間有資料尚未寫入,出現了亂序,暗示可能有訊息丟失,對應的生產者會丟擲 OutOfOrderSequenceException,這個異常是一個嚴重的異常,後續的諸如 send()、beginTransaction()、commitTransaction() 等方法的呼叫都會丟擲 IllegalStateException 的異常