
paper sharing :學習特徵演化的資料流
特徵演化的資料流
資料流學習是近年來機器學習與資料探勘領域的一個熱門的研究方向,資料流的場景和靜態資料集的場景最大的一個特點就是資料會發生演化,關於演化資料流的研究大多集中於概念漂移檢測(有監督學習),概念/聚類演化分析(無監督學習),然而,人們往往忽略了一個經常出現的演化場景:特徵演化。大多數研究都考慮資料流的特徵空間是固定的,然而,在很多場景下這一假設並不成立:例如,當有限壽命感測器收集的資料被新的感測器替代時,這些感測器對應的特徵將發生變化。
今天要分享的文章出自周志華的實驗室《Learning with Feature Evolvable Streams》(NIPS 2017),它提出了一個新的場景,即在資料流中會有特徵消亡也會有新特徵出現。當出現新的特徵空間時,我們並不直接拋棄之前學到的模型並在新的資料上重新建立模型,而是嘗試恢復消失的特徵來提升模型的表現。具體來說,通過從恢復的特徵和新的特徵空間中分別學習兩個模型。為了從恢復的特徵中獲得提升,論文中提出了兩種整合策略:第一種方法是合併兩個模型的預測結果;第二種是選擇最佳的預測模型。下面我們具體來理解特徵演化資料流以及論文中提出的一些有趣的方法吧~
paper link:https://papers.nips.cc/paper/6740-learning-with-feature-evolvable-streams.pdf
 什麼是特徵演化資料流?
什麼是特徵演化資料流?

在很多現實的任務中,資料都是源源不斷收集的,關於資料流學習的研究近年來受到越來越多的關注,雖然已經有很多有效的演算法針對特定的場景對資料流進行挖掘,但是它們都基於一個假設就是資料流中資料的特徵空間是穩定的。不幸的是,這一假設在很多場景下都不滿足。針對特徵演化的場景,最直接的想法就是利用新的特徵空間的資料學習一個新的模型,但是這一方法有很多問題:首先,當新的特徵剛出現的時候,只有很少的資料樣本來描述這些資訊,訓練樣本並不足夠去學習一個新的模型;其次,包含消失特徵的舊模型被直接丟棄了,其中可能包含對當前資料有用的資訊。論文中定義了一種特徵演化資料流的場景:一般情況下,特徵不會任意改變,而在一些重疊時期,新特徵和舊特徵都存在,如下圖所示:
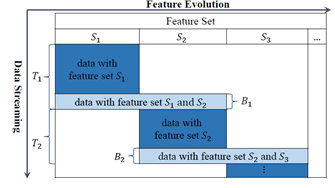
其中,T1階段,原始特徵集都是有效的,B1階段出現了新的特徵集,T2階段原始特徵集消失,只有新的特徵集。
論文提出的方法是通過使用重疊(B1)階段來發現新舊特徵之間的關係,嘗試學習新特徵到舊特徵的一個對映,這樣就可以通過重構舊特徵並使用舊模型對新資料進行預測
問題描述
論文中著重解決的是分類和迴歸任務,在每一輪學習過程中,對每一個例項進行預測,結合它的真實標籤會得到一個loss(反映預測和真實標籤的差異),我們將上面提到的T1+B1+T的過程稱為一個週期,每個週期中只包含兩個特徵空間,所以,之後的研究主要關注一個週期內的模型的學習,而且,我們假設一個週期內的舊特徵會同時消失。定義Ω1和Ω2分別表示兩個特徵空間S1和S2上的線性模型,並定義對映
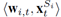 ,
,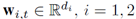 。損失函式是凸的,最直接的方式是使用線上梯度下降來求解w,但是在資料流上不適用。
。損失函式是凸的,最直接的方式是使用線上梯度下降來求解w,但是在資料流上不適用。
方法介紹
上文提到的基本演算法的主要限制是在第1,…T1輪學習的模型在T1+1,…T1+T2時候被忽略了,這是因為T1之後資料的特徵空間改變了,我們無法直接應用原來的模型。為了解決這一問題,我們假設新舊特徵空間之間有一種特定的關係: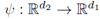 ,我們嘗試通過重疊階段B1來學習這種關係。學習兩組特徵之間的關係的方法很多,如多元迴歸,資料流多標籤學習等。但是在當前的場景下,由於重疊階段特別短,學習一個複雜的關係模型是不現實的。所以我們採用線性對映來近似。定義線性對映的係數矩陣為M,那麼在B1階段,M的估計可以基於如下的目標方程:
,我們嘗試通過重疊階段B1來學習這種關係。學習兩組特徵之間的關係的方法很多,如多元迴歸,資料流多標籤學習等。但是在當前的場景下,由於重疊階段特別短,學習一個複雜的關係模型是不現實的。所以我們採用線性對映來近似。定義線性對映的係數矩陣為M,那麼在B1階段,M的估計可以基於如下的目標方程:
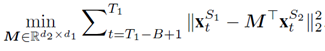
M的最優解可以解得:
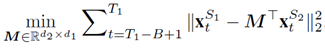
然後,當我觀測到S2空間得資料,就可以通過M將其轉化到S1空間,並應用舊模型對其進行預測。
除了學習這個關係對映之外,我們得演算法主要包括兩個部分:
-
在T1-B1+1,…T1階段,我們學習兩個特徵空間之間得關係;
-
在T1之後,我們使用新特徵空間的資料轉化後的原特徵空間資料,持續更新舊模型以提升它的預測效果,然後整合兩個模型進行預測。
預測結果整合
論文中提出兩種整合方法,第一種是加權組合,即將兩個模型的預測結果求加權平均,權重是基於exponential of the cumulative loss。
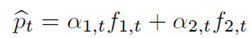
其中

這種權重的更新規則表明,如果上一輪模型的損失較大,下一輪模型的權值將以指數速度下降,這是合理的,可以得到很好的理論結果。
第二種整合方法是動態選擇。
上面提到的組合的方法結合了幾個模型來提升整體效能,通常來說,組合多個分類器的表現會比單分類器的效果要好,但是,這基於一個重要的假設就是每個基分類器的表現不能太差(如,在Adaboost中,基分類器的預測精度不應低於0.5)。然而在這個問題中,由於新特徵空間剛出現的時候訓練集較小,訓練的模型不好,因此可能並不適合用組合的方法來預測,相反,用動態選擇最優模型的方法反而能獲得好的效果。

有趣的靈魂在等你 長按二維碼
長按二維碼