
小白學 Python 爬蟲(7):HTTP 基礎

人生苦短,我用 Python
前文傳送門:
小白學 Python 爬蟲(1):開篇
小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝
小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門
小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門
小白學 Python 爬蟲(5):前置準備(四)資料庫基礎
小白學 Python 爬蟲(6):前置準備(五)爬蟲框架的安裝
網路的起源
這個其實是一個冷知識,各位同學可以猜測一下計算機網路的起源是在哪裡。
矽谷?大學?實驗室?有點接近了,但還不夠準確。
準確的答案是在美蘇冷戰背景下的美國國防部 。
對的,你沒看錯,是美國軍方 ,最先進的技術總是先應用於軍事領域,隨著時間的推移才會慢慢的民用化。
1968年,在美國國防部高階計劃局的領導下,阿帕網( ARPANET )誕生了。
ARPANET只有四個節點,連線起加利福尼亞州大學洛杉磯分校、加州大學聖巴巴拉分校、斯坦福大學、猶他州大學這四所學校的大型計算機。
阿帕網 ,是全球公認的計算機網路的始祖。

URI 、 URL 和 URN
爬蟲是一個模擬瀏覽器進行 HTTP 請求的過程。這就需要我們瞭解從瀏覽器輸入 URL 到獲取到網頁中間究竟發生了什麼。
先介紹一組概念, URI 和 URL :
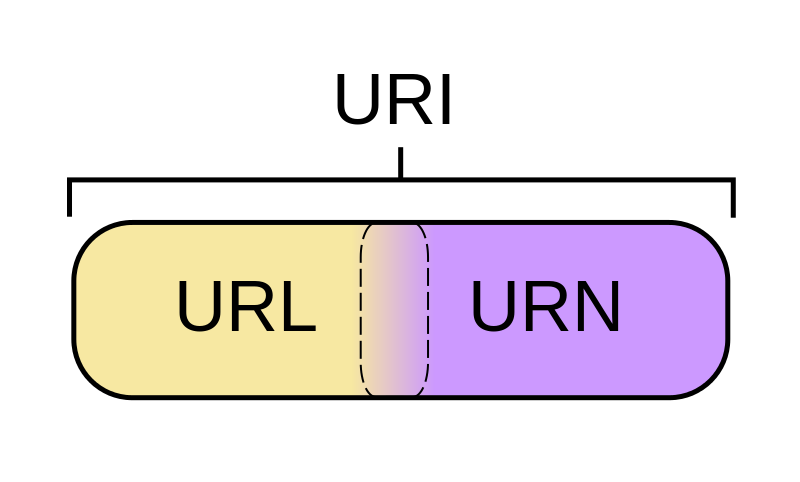
- URI = Universal Resource Identifier 統一資源標誌符,用來標識抽象或物理資源的一個緊湊字串。
- URL = Universal Resource Locator 統一資源定位符,一種定位資源的主要訪問機制的字串,一個標準的URL必須包括:protocol、host、port、path、parameter、anchor。
- URN = Universal Resource Name 統一資源名稱,通過特定名稱空間中的唯一名稱或ID來標識資源。
沒看懂是吧,沒事兒,不需要懂,瞭解一下就好了,我們來舉例子。
比如上面這張圖片的地址:https://cdn.geekdigging.com/python-spider/uri-url-urn.png ,它是一個 URL 同時也是一個 URI , URL 是 URI 的子集,也就是說每個 URL 都是 URI ,但不是每個 URI 都是 URL ,因為 URI 還包括一個子類叫 URN 。在目前的網路中 URN 的使用非常少,所以幾乎所有的 URI 都是 URL ,一般的網頁連結我們既可以稱為 URL ,也可以稱為 URI ,完全看個人喜好。
超文字
什麼是超文字?
超文字是指可以連結到另一個文件或文字的單詞,短語或大塊文字。超文字涵蓋了文字超連結和圖形超連結。
我們在瀏覽器中訪問的網頁是由 HTML 編寫而成,而 HTML 則被稱作為“超文字標記語言”。在 HTML 程式碼中,包含了一系列的標籤,包括圖片等的超連結。
我們來看一下一個真實的網站的原始碼是怎麼樣的,在 Chrome 瀏覽器中,使用 F12 開啟開發者工具。
HTTP 和 HTTPS
什麼是 HTTP ?
超文字傳輸協議,是一個基於請求與響應,無狀態的,應用層的協議,常基於TCP/IP協議傳輸資料,網際網路上應用最為廣泛的一種網路協議,所有的WWW檔案都必須遵守這個標準。設計HTTP的初衷是為了提供一種釋出和接收HTML頁面的方法。
什麼是HTTPS?
《圖解HTTP》這本書中曾提過HTTPS是身披SSL外殼的HTTP。HTTPS是一種通過計算機網路進行安全通訊的傳輸協議,經由HTTP進行通訊,利用SSL/TLS建立全通道,加密資料包。HTTPS使用的主要目的是提供對網站伺服器的身份認證,同時保護交換資料的隱私與完整性。
PS:TLS是傳輸層加密協議,前身是SSL協議,由網景公司1995年釋出,有時候兩者不區分。
現在越來越多的網站和App都已經向HTTPS方向發展,例如:
- 蘋果公司強制所有iOS App在2017年1月1日前全部改為使用HTTPS加密,否則App就無法在應用商店上架;
- 谷歌從2017年1月推出的Chrome 56開始,對未進行HTTPS加密的網址連結亮出風險提示,即在位址列的顯著位置提醒使用者“此網頁不安全”;
- 騰訊微信小程式的官方需求文件要求後臺使用HTTPS請求進行網路通訊,不滿足條件的域名和協議無法請求。
HTTP協議
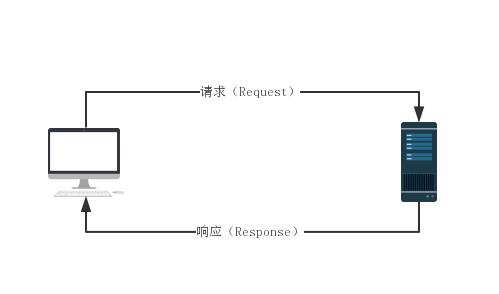
HTTP 協議本身是非常簡單的。它規定,只能由客戶端主動發起請求,伺服器接收請求處理後返回響應結果,同時 HTTP 是一種無狀態的協議,協議本身不記錄客戶端的歷史請求記錄。
為了比較直觀的展示這個過程,我們依然開啟 Chrome 瀏覽器,按 F12 開啟開發者模式。
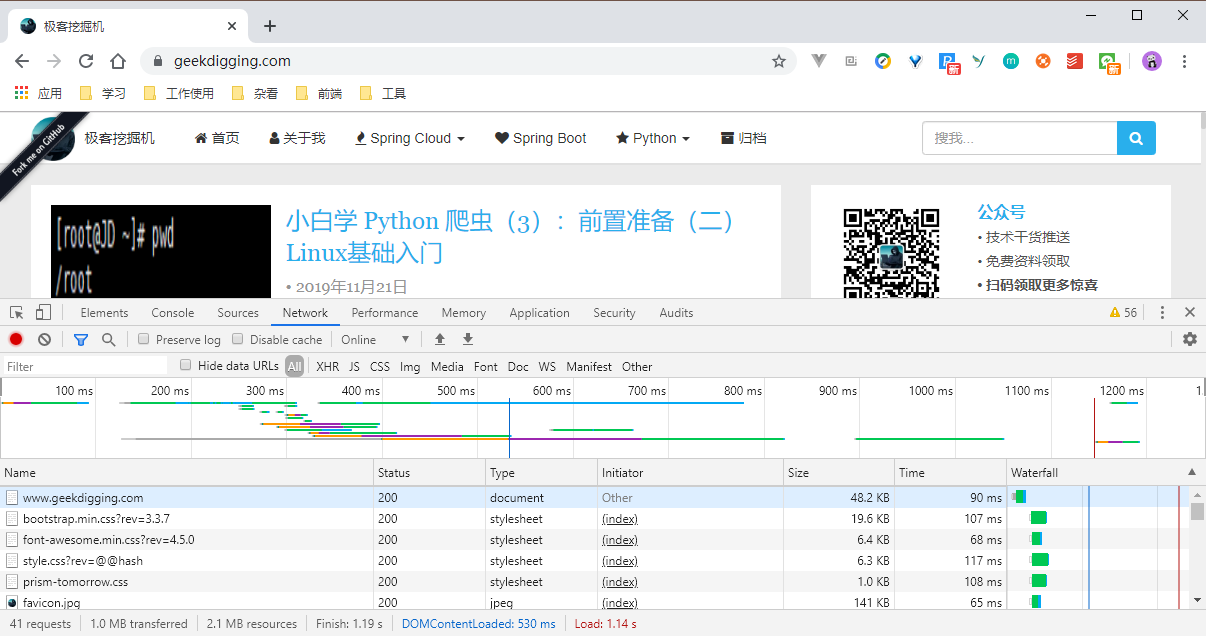
看第一行,www.geekdigging.com 那一行:
- Name:請求的名稱。
- Status:狀態碼, 200 代表正常響應。
- Type:文旦型別,這裡我們是請求了一個 HTML 文件。
- Initiator:請求源。用來標記請求是由哪個物件或程序發起的。
- Size:資源大小,這個標識了我們請求的資源的大小。
- Time:消耗的時間,單位是 ms 。
- Watefall:網路請求的視覺化瀑布流。
我們點選一下那一行,可以看到更加詳細的內容:
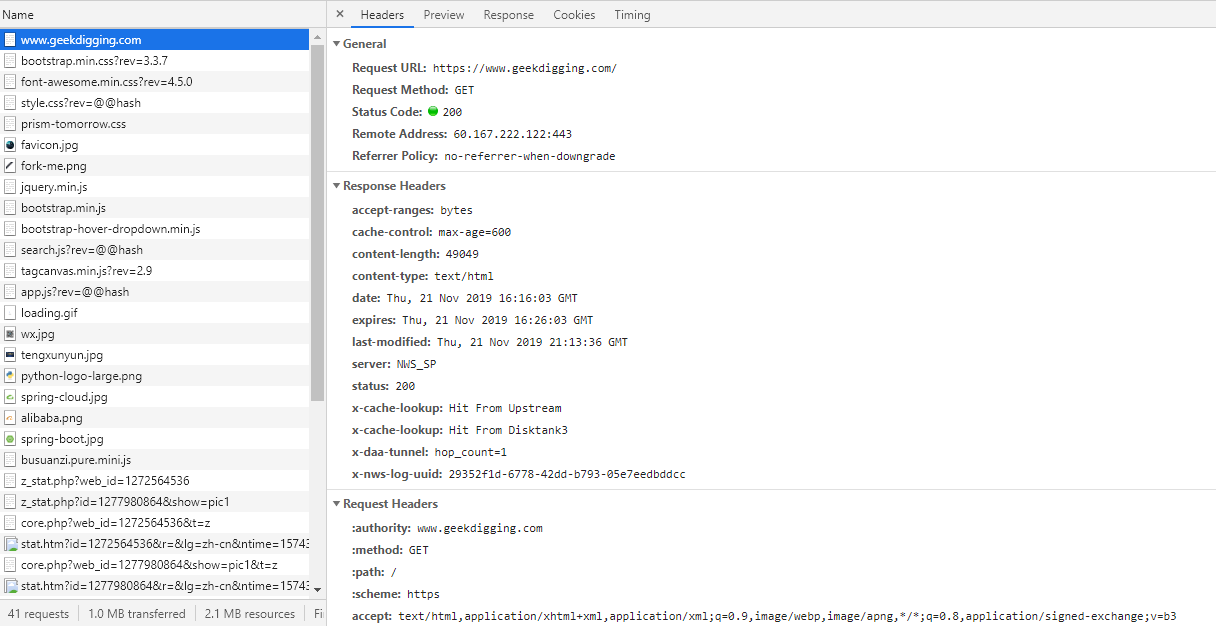
包含了 Header 頭資訊, Preview (Response Preview) 響應資訊預覽, Response 響應具體的 HTML 程式碼, Cookies ,Timing 整個請求週期耗時。
General部分: Request URL 為請求的URL, Request Method 為請求的方法, Status Code 為響應狀態碼, Remote Address 為遠端伺服器的地址和埠, Referrer Policy 為Referrer判別策略。
Request 請求
一個HTTP請求報文由請求行(request line)、請求頭部(headers)、空行(blank line)和請求資料(request body)4個部分組成。

請求行
分為三個部分:請求方法、請求地址URL和HTTP協議版本,它們之間用空格分割。
例如,GET /index.html HTTP/1.1。
HTTP/1.1 定義的請求方法有8種:
- GET :請求頁面,並返回頁面內容。
- POST :大多用於提交表單或上傳檔案,資料包含在請求體中。
- PUT :從客戶端向伺服器傳送的資料取代指定文件中的內容。
- DELETE :請求伺服器刪除指定的頁面。
- PATCH :是對 PUT 方法的補充,用來對已知資源進行區域性更新 。
- HEAD:類似於 GET 請求,只不過返回的響應中沒有具體的內容,用於獲取報頭。
- OPTIONS:允許客戶端檢視伺服器的效能。
- TRACE:回顯伺服器收到的請求,主要用於測試或診斷。
- CONNECT :HTTP/1.1 協議中預留給能夠將連線改為管道方式的代理伺服器。
常用的有 GET 和 POST 。
GET
在瀏覽器中直接輸入URL並回車,這就發起了一個 GET 請求,請求的引數會直接包含在 URL 裡,請求引數和對應的值附加在URL後面,利用一個問號 ? 代表URL的結尾與請求引數的開始,傳遞引數長度受限制。由於不同的瀏覽器對地址的字元限制也有所不同,一般最多隻能識別1024個字元,所以如果需要傳送大量資料的時候,也不適合使用GET方式。
POST
允許客戶端給伺服器提供資訊較多。POST方法將請求引數封裝在HTTP請求資料中,以名稱/值的形式出現,可以傳輸大量資料,這樣POST方式對傳送的資料大小沒有限制,而且也不會顯示在URL中。
請求頭
因為請求行所攜帶的資訊量非常有限,以至於客戶端還有很多想向伺服器要說的事情不得不放在請求首部(Header),請求首部用於給伺服器提供一些額外的資訊,比如 User-Agent 用來表明客戶端的身份,讓伺服器知道你是來自瀏覽器的請求還是爬蟲,是來自 Chrome 瀏覽器還是 FireFox。HTTP/1.1 規定了47種首部欄位型別。 HTTP 首部欄位的格式很像 Python 中的字典型別,由鍵值對組成,中間用冒號隔開。
下面簡要說明一些常用的頭資訊。
- Accept:請求報頭域,用於指定客戶端可接受哪些型別的資訊。
- Accept-Language:指定客戶端可接受的語言型別。
- Accept-Encoding:指定客戶端可接受的內容編碼。
Host:用於指定請求資源的主機IP和埠號,其內容為請求URL的原始伺服器或閘道器的位置。從HTTP 1.1版本開始,請求必須包含此內容。 - Cookie:也常用複數形式 Cookies,這是網站為了辨別使用者進行會話跟蹤而儲存在使用者本地的資料。它的主要功能是維持當前訪問會話。例如,我們輸入使用者名稱和密碼成功登入某個網站後,伺服器會用會話儲存登入狀態資訊,後面我們每次重新整理或請求該站點的其他頁面時,會發現都是登入狀態,這就是Cookies的功勞。Cookies裡有資訊標識了我們所對應的伺服器的會話,每次瀏覽器在請求該站點的頁面時,都會在請求頭中加上Cookies並將其傳送給伺服器,伺服器通過Cookies識別出是我們自己,並且查出當前狀態是登入狀態,所以返回結果就是登入之後才能看到的網頁內容。
- Referer:此內容用來標識這個請求是從哪個頁面發過來的,伺服器可以拿到這一資訊並做相應的處理,如作來源統計、防盜鏈處理等。
- User-Agent:簡稱UA,它是一個特殊的字串頭,可以使伺服器識別客戶使用的作業系統及版本、瀏覽器及版本等資訊。在做爬蟲時加上此資訊,可以偽裝為瀏覽器;如果不加,很可能會被識別出為爬蟲。
- Content-Type:也叫網際網路媒體型別(Internet Media Type)或者MIME型別,在HTTP協議訊息頭中,它用來表示具體請求中的媒體型別資訊。例如,text/html代表HTML格式,image/gif代表GIF圖片,application/json代表JSON型別,更多對應關係可以檢視此對照表:http://tool.oschina.net/commons。
請求資料
請求體一般承載的內容是POST請求中的表單資料,而對於GET請求,請求體則為空。
注意這裡提交資料的方式和請求頭設定的 Content-Type 息息相關。
Response 響應
服務端接收請求並處理後,返回響應內容給客戶端,同樣地,響應內容也必須遵循固定的格式瀏覽器才能正確解析。HTTP 響應也由3部分組成,分別是:響應行、響應首部、響應體,與 HTTP 的請求格式是相對應的。
響應行
響應行同樣也是3部分組成,由服務端支援的 HTTP 協議版本號、狀態碼、以及對狀態碼的簡短原因描述組成。
狀態碼
響應狀態碼錶示伺服器的響應狀態,常見的如200代表伺服器正常響應,404代表頁面未找到,500代表伺服器內部發生錯誤。
響應頭
響應頭包含了伺服器對請求的應答資訊,如Content-Type、Server、Set-Cookie等。下面簡要說明一些常用的頭資訊。
- Date:標識響應產生的時間。
- Last-Modified:指定資源的最後修改時間。
- Content-Encoding:指定響應內容的編碼。
- Server:包含伺服器的資訊,比如名稱、版本號等。
- Content-Type:文件型別,指定返回的資料型別是什麼,如text/html代表返回HTML文件,application/x-javascript則代表返回JavaScript檔案,image/jpeg則代表返回圖片。
- Set-Cookie:設定Cookies。響應頭中的Set-Cookie告訴瀏覽器需要將此內容放在Cookies中,下次請求攜帶Cookies請求。
- Expires:指定響應的過期時間,可以使代理伺服器或瀏覽器將載入的內容更新到快取中。如果再次訪問時,就可以直接從快取中載入,降低伺服器負載,縮短載入時間。
響應體
最重要的當屬響應體的內容了。響應的正文資料都在響應體中,比如請求網頁時,它的響應體就是網頁的HTML程式碼;請求一張圖片時,它的響應體就是圖片的二進位制資料。
在做爬蟲時,我們主要通過響應體得到網頁的原始碼、JSON資料等,然後從中做相應內容的提取。
參考
https://blog.csdn.net/koflance/article/details/79635240
https://blog.csdn.net/xiaoming100001/article/details/81109617
https://cuiqingcai.com/5465.html
https://blog.csdn.net/ailunlee/article/details/90600