
Reactor和Proactor模型
一、背景
前面介紹了I/O多路複用模型,那有了I/O複用,有了epoll已經可以使伺服器併發幾十萬連線的同時,還能維持比較高的TPS,難道還不夠嗎?比如現在在使用epoll的時候一般都是起個任務,不斷的去巡檢事件,然後通知處理,而比較理想的方式是最好能以一種回撥的機制,提供一個程式設計框架,讓程式更有結構些,另一方面,如果希望每個事件通知之後,做的事情能有機會被代理到某個執行緒裡面去單獨執行,而執行緒完成的狀態又能通知回主任務,那麼"非同步"的進位制就必須被引入。所以這個章節主要介紹下"程式設計框架"。
二、Reactor模型
Reactor模式是處理併發I/O比較常見的一種模式,用於同步I/O,中心思想是將所有要處理的I/O事件註冊到一箇中心I/O多路複用器上,同時主執行緒/程序阻塞在多路複用器上;一旦有I/O事件到來或是準備就緒(檔案描述符或socket可讀、寫),多路複用器返回並將事先註冊的相應I/O事件分發到對應的處理器中。
Reactor是一種事件驅動機制,和普通函式呼叫的不同之處在於:應用程式不是主動的呼叫某個API完成處理,而是恰恰相反,Reactor逆置了事件處理流程,應用程式需要提供相應的介面並註冊到Reactor上,如果相應的事件發生,Reactor將主動呼叫應用程式註冊的介面,這些介面又稱為“回撥函式”。用“好萊塢原則”來形容Reactor再合適不過了:不要打電話給我們,我們會打電話通知你。
Reactor模式與Observer模式在某些方面極為相似:當一個主體發生改變時,所有依屬體都得到通知。不過,觀察者模式與單個事件源關聯,而反應器模式則與多個事件源關聯 。
在Reactor模式中,有5個關鍵的參與者:
- 描述符(handle):由作業系統提供的資源,用於識別每一個事件,如Socket描述符、檔案描述符、訊號的值等。在Linux中,它用一個整數來表示。事件可以來自外部,如來自客戶端的連線請求、資料等。事件也可以來自內部,如訊號、定時器事件。
- 同步事件多路分離器(event demultiplexer):事件的到來是隨機的、非同步的,無法預知程式何時收到一個客戶連線請求或收到一個訊號。所以程式要迴圈等待並處理事件,這就是事件迴圈。在事件迴圈中,等待事件一般使用I/O複用技術實現。在linux系統上一般是select、poll、epoll等系統呼叫,用來等待一個或多個事件的發生。I/O框架庫一般將各種I/O複用系統呼叫封裝成統一的介面,稱為事件多路分離器。呼叫者會被阻塞,直到分離器分離的描述符集上有事件發生。這點可以參考前面的 I/O多路複用模型。
- 事件處理器(event handler):I/O框架庫提供的事件處理器通常是由一個或多個模板函式組成的介面。這些模板函式描述了和應用程式相關的對某個事件的操作,使用者需要繼承它來實現自己的事件處理器,即具體事件處理器。因此,事件處理器中的回撥函式一般宣告為虛擬函式,以支援使用者拓展。
- 具體的事件處理器(concrete event handler):是事件處理器介面的實現。它實現了應用程式提供的某個服務。每個具體的事件處理器總和一個描述符相關。它使用描述符來識別事件、識別應用程式提供的服務。
- Reactor 管理器(reactor):定義了一些介面,用於應用程式控制事件排程,以及應用程式註冊、刪除事件處理器和相關的描述符。它是事件處理器的排程核心。 Reactor管理器使用同步事件分離器來等待事件的發生。一旦事件發生,Reactor管理器先是分離每個事件,然後排程事件處理器,最後呼叫相關的模 板函式來處理這個事件。
2.1 應用場景
- 場景:長途客車在路途上,有人上車有人下車,但是乘客總是希望能夠在客車上得到休息。
- 傳統做法:每隔一段時間(或每一個站),司機或售票員對每一個乘客詢問是否下車。
- Reactor做法:汽車是乘客訪問的主體(Reactor),乘客上車後,到售票員(acceptor)處登記,之後乘客便可以休息睡覺去了,當到達乘客所要到達的目的地時(指定的事件發生,乘客到了下車地點),售票員將其喚醒即可。
2.2 更加形象例子
這部分內容主要來自:https://blog.csdn.net/russell_tao/article/details/17452997
https://blog.csdn.net/u013074465/article/details/46276967
傳統程式設計方法
就好像是到了銀行營業廳裡,每個視窗前排了長隊,業務員們在視窗後一個個的解決客戶們的請求。一個業務員可以盡情思考著客戶A依次提出的問題,例如:
“我要買2萬XX理財產品。“
“看清楚了,5萬起售。”
“等等,查下我活期餘額。”
“餘額5萬。”
“那就買 5萬吧。”
業務員開始錄入資訊。
”對了,XX理財產品年利率8%?”
“是預期8%,最低無利息保本。“
”早不說,拜拜,我去買餘額寶。“
業務員無表情的刪著已經錄入的資訊進行事務回滾。
“下一個!”
IO複用方法
用了IO複用則是大師業務員開始挑戰極限,在超大營業廳裡給客戶們人手一個牌子,黑壓壓的客戶們都在大廳中,有問題時舉牌申請提問,大師目光敏銳點名指定某人提問,該客戶迅速得到大師的答覆後,要經過一段時間思考,查查自己的銀袋子,諮詢下LD,才能再次進行下一個提問,直到得到完整的滿意答覆退出大廳。例如:大師剛指導A填寫轉帳單的某一項,B又來申請兌換泰銖,給了B兌換單後,C又來辦理定轉活,然後D與F在爭搶有限的圓珠筆時出現了不和諧現象,被大師叫停業務,暫時等待。
這就是基於事件驅動的IO複用程式設計比起傳統1執行緒1請求的方式來,有難度的設計點了,客戶們都是上帝,既不能出錯,還不能厚此薄彼。
當沒有Reactor時,我們可能的設計方法是這樣的:大師把每個客戶的提問都記錄下來,當客戶A提問時,首先查閱A之前問過什麼做過什麼,這叫聯絡上下文,然後再根據上下文和當前提問查閱有關的銀行規章制度,有針對性的回答A,並把回答也記錄下來。當圓滿回答了A的所有問題後,刪除A的所有記錄。
2.3 在程式中
某一瞬間,伺服器共有10萬個併發連線,此時,一次IO複用介面的呼叫返回了100個活躍的連線等待處理。先根據這100個連線找出其對應的物件,這並不難,epoll的返回連線資料結構裡就有這樣的指標可以用。接著,迴圈的處理每一個連線,找出這個物件此刻的上下文狀態,再使用read、write這樣的網路IO獲取此次的操作內容,結合上下文狀態查詢此時應當選擇哪個業務方法處理,呼叫相應方法完成操作後,若請求結束,則刪除物件及其上下文。
這樣,我們就陷入了面向過程程式設計方法之中了,在面向應用、快速響應為王的移動網際網路時代,這樣做早晚得把自己玩死。我們的主程式需要關注各種不同型別的請求,在不同狀態下,對於不同的請求命令選擇不同的業務處理方法。這會導致隨著請求型別的增加,請求狀態的增加,請求命令的增加,主程式複雜度快速膨脹,導致維護越來越困難,苦逼的程式設計師再也不敢輕易接新需求、重構。
Reactor是解決上述軟體工程問題的一種途徑,它也許並不優雅,開發效率上也不是最高的,但其執行效率與面向過程的使用IO複用卻幾乎是等價的,所以,無論是nginx、memcached、redis等等這些高效能元件的代名詞,都義無反顧的一頭扎進了反應堆的懷抱中。
Reactor模式可以在軟體工程層面,將事件驅動框架分離出具體業務,將不同型別請求之間用OO的思想分離。通常,Reactor不僅使用IO複用處理網路事件驅動,還會實現定時器來處理時間事件的驅動(請求的超時處理或者定時任務的處理),就像下面的示意圖:

這幅圖有5點意思:
- 處理應用時基於OO思想,不同的型別的請求處理間是分離的。例如,A型別請求是使用者註冊請求,B型別請求是查詢使用者頭像,那麼當我們把使用者頭像新增多種解析度圖片時,更改B型別請求的程式碼處理邏輯時,完全不涉及A型別請求程式碼的修改。
- 應用處理請求的邏輯,與事件分發框架完全分離。什麼意思呢?即寫應用處理時,不用去管何時呼叫IO複用,不用去管什麼呼叫epoll_wait,去處理它返回的多個socket連線。應用程式碼中,只關心如何讀取、傳送socket上的資料,如何處理業務邏輯。事件分發框架有一個抽象的事件介面,所有的應用必須實現抽象的事件介面,通過這種抽象才把應用與框架進行分離。
- Reactor上提供註冊、移除事件方法,供應用程式碼使用,而分發事件方法,通常是迴圈的呼叫而已,是否提供給應用程式碼呼叫,還是由框架簡單粗暴的直接迴圈使用,這是框架的自由。
- IO多路複用也是一個抽象,它可以是具體的select,也可以是epoll,它們只必須提供採集到某一瞬間所有待監控連線中活躍的連線。
- 定時器也是由Reactor物件使用,它必須至少提供4個方法,包括新增、刪除定時器事件,這該由應用程式碼呼叫。最近超時時間是需要的,這會被反應堆物件使用,用於確認select或者epoll_wait執行時的阻塞超時時間,防止IO的等待影響了定時事件的處理。遍歷也是由反應堆框架使用,用於處理定時事件。
2.4 Reactor的幾種模式
參考資料:http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
在web服務中,很多都涉及基本的操作:read request、decode request、process service、encod reply、send reply等。
1 單執行緒模式
這是最簡單的Reactor單執行緒模型。Reactor執行緒是個多面手,負責多路分離套接字,Accept新連線,並分派請求到處理器鏈中。該模型適用於處理器鏈中業務處理元件能快速完成的場景。不過這種單執行緒模型不能充分利用多核資源,所以實際使用的不多。
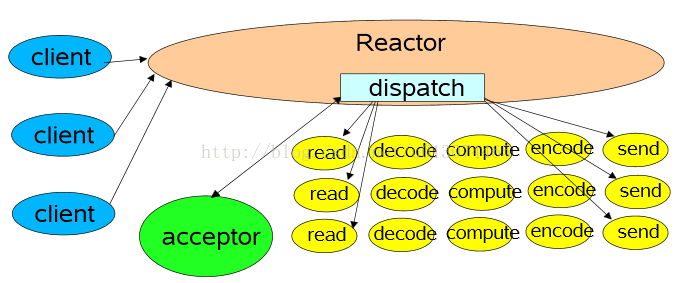
2 多執行緒模式(單Reactor)
該模型在事件處理器(Handler)鏈部分採用了多執行緒(執行緒池),也是後端程式常用的模型。

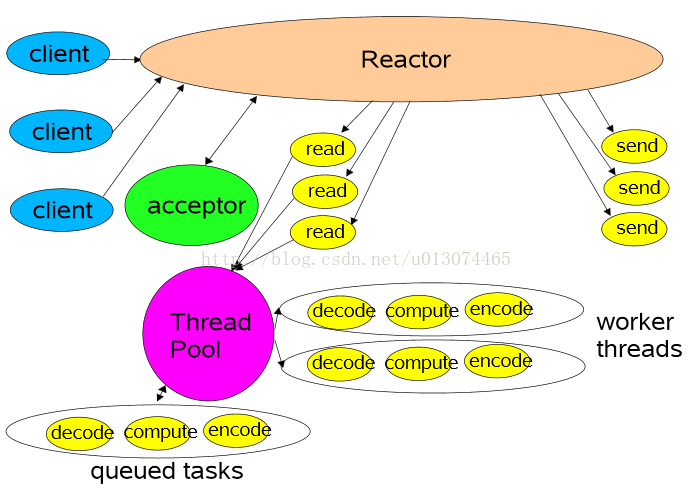
3 多執行緒模式(多個Reactor)
比起第二種模型,它是將Reactor分成兩部分,mainReactor負責監聽並accept新連線,然後將建立的socket通過多路複用器(Acceptor)分派給subReactor。subReactor負責多路分離已連線的socket,讀寫網路資料;業務處理功能,其交給worker執行緒池完成。通常,subReactor個數上可與CPU個數等同。
三、Proacotr模型
Proactor是和非同步I/O相關的。
在Reactor模式中,事件分離者等待某個事件或者可應用多個操作的狀態發生(比如檔案描述符可讀寫,或者是socket可讀寫),事件分離器就把這個事件傳給事先註冊的處理器(事件處理函式或者回調函式),由後者來做實際的讀寫操作。
在Proactor模式中,事件處理者(或者代由事件分離者發起)直接發起一個非同步讀寫操作(相當於請求),而實際的工作是由作業系統來完成的。發起時,需要提供的引數包括用於存放讀到資料的快取區,讀的資料大小,或者用於存放外發資料的快取區,以及這個請求完後的回撥函式等資訊。事件分離者得知了這個請求,它默默等待這個請求的完成,然後轉發完成事件給相應的事件處理者或者回調。
可以看出兩者的區別:Reactor是在事件發生時就通知事先註冊的事件(讀寫由處理函式完成);Proactor是在事件發生時進行非同步I/O(讀寫由OS完成),待IO完成事件分離器才排程處理器來處理。
舉個例子,將有助於理解Reactor與Proactor二者的差異,以讀操作為例(類操作類似)。
在Reactor(同步)中實現讀:
- 註冊讀就緒事件和相應的事件處理器
- 事件分離器等待事件
- 事件到來,啟用分離器,分離器呼叫事件對應的處理器。
- 事件處理器完成實際的讀操作,處理讀到的資料,註冊新的事件,然後返還控制權。
Proactor(非同步)中的讀:
- 處理器發起非同步讀操作(注意:作業系統必須支援非同步IO)。在這種情況下,處理器無視IO就緒事件,它關注的是完成事件。
- 事件分離器等待操作完成事件
- 在分離器等待過程中,作業系統利用並行的核心執行緒執行實際的讀操作,並將結果資料存入使用者自定義緩衝區,最後通知事件分離器讀操作完成。
- 事件分離器呼喚處理器。
- 事件處理器處理使用者自定義緩衝區中的資料,然後啟動一個新的非同步操作,並將控制權返回事件分離器。
四、常見的I/O程式設計框架
對比幾個常見的I/O程式設計框架:libevent,libev,libuv,aio,boost.Asio。
4.1 libevent
libevent是一個C語言寫的網路庫,官方主要支援的是類linux作業系統,最新的版本添加了對windows的IOCP的支援。在跨平臺方面主要通過select模型來進行支援。
設計模式 :libevent為Reactor模式;
層次架構:livevent在不同的作業系統下,做了多路複用模型的抽象,可以選擇使用不同的模型,通過事件函式提供服務;
可移植性 :libevent主要支援linux平臺,freebsd平臺,其他平臺下通過select模型進行支援,效率不是太高;
事件分派處理 :libevent基於註冊的事件回撥函式來實現事件分發;
涉及範圍 :libevent只提供了簡單的網路API的封裝,執行緒池,記憶體池,遞迴鎖等均需要自己實現;
執行緒排程 :libevent的執行緒排程需要自己來註冊不同的事件控制代碼;
釋出方式 :libevent為開源免費的,一般編譯為靜態庫進行使用;
開發難度 :基於libevent開發應用,相對容易,具體可以參考memcached這個開源的應用,裡面使用了 libevent這個庫。
4.2 libev
libevent/libev是兩個名字相當相近的I/O Library。既然是庫,第一反應就是對api的包裝。epoll在linux上已經存在了很久,但是linux是SysV的後代,BSD及其衍生的MAC就沒有,只有kqueue。
libev v.s libevent。既然已經有了libevent,為什麼還要發明一個輪子叫做libev?
http://www.cnblogs.com/Lifehacker/p/whats_the_difference_between_libevent_and_libev_chinese.html
http://stackoverflow.com/questions/9433864/whats-the-difference-between-libev-and-libevent
上面是libev的作者對於這個問題的回答,下面是網摘的中文翻譯:
就設計哲學來說,libev的誕生,是為了修復libevent設計上的一些錯誤決策。例如,全域性變數的使用,讓libevent很難在多執行緒環境中使用。watcher結構體很大,因為它們包含了I/O,定時器和訊號處理器。額外的元件如HTTP和DNS伺服器,因為拙劣的實現品質和安全問題而備受折磨。定時器不精確,而且無法很好地處理時間跳變。
總而言之,libev試圖做好一件事而已(目標是成為POSIX的事件庫),這是最高效的方法。libevent則嘗試給你全套解決方案(事件庫,非阻塞IO庫,http庫,DNS客戶端)libev 完全是單執行緒的,沒有DNS解析。
libev解決了epoll, kqueuq等API不同的問題。保證使用livev的程式可以在大多數 *nix 平臺上執行(對windows不太友好)。但是 libev 的缺點也是顯而易見,由於基本只是封裝了 Event Library,用起來有諸多不便。比如 accept(3) 連線以後需要手動 setnonblocking 。從 socket 讀寫時需要檢測 EAGAIN 、EWOULDBLOCK 和 EINTER 。這也是大多數人認為非同步程式難寫的根本原因。
4.3 libuv
libuv是Joyent給Node做的I/O Library。libuv 需要多執行緒庫支援,其在內部維護了一個執行緒池來 處理諸如getaddrinfo(3) 這樣的無法非同步的呼叫。同時,對windows使用者友好,Windows下用IOCP實現,官網http://docs.libuv.org/en/v1.x/
4.4 boost.Asio
Boost.Asio類庫,其就是以Proactor這種設計模式來實現。
參見:Proactor(The Boost.Asio library is based on the Proactor pattern. This design note outlines the advantages and disadvantages of this approach.),
其設計文件連結:http://asio.sourceforge.net/boost_asio_0_3_7/libs/asio/doc/design/index.html
http://stackoverflow.com/questions/11423426/how-does-libuv-compare-to-boost-asio
4.5 linux aio
linux有兩種aio(非同步機制),一是glibc提供的(bug很多,幾乎不可用),一是核心提供的(BSD/mac也提供)。當然,機制不等於程式設計框架。
最後,本文介紹的同步Reactor模型比較多,後面的章節會以boost.Asio庫為基礎講解為什麼需要非同步編