
模型量化原理及tflite示例
模型量化
什麼是量化
模型的weights資料一般是float32的,量化即將他們轉換為int8的。當然其實量化有很多種,主流是int8/fp16量化,其他的還有比如
- 二進位制神經網路:在執行時具有二進位制權重和啟用的神經網路,以及在訓練時計算引數的梯度。
- 三元權重網路:權重約束為+1,0和-1的神經網路
- XNOR網路:過濾器和卷積層的輸入是二進位制的。 XNOR 網路主要使用二進位制運算來近似卷積。
現在很多框架或者工具比如nvidia的TensorRT,xilinx的DNNDK,TensorFlow,PyTorch,MxNet 等等都有量化的功能.
量化的優缺點
量化的優點很明顯了,int8佔用記憶體更少,運算更快,量化後的模型可以更好地跑在低功耗嵌入式裝置上。以應用到手機端,自動駕駛等等。
量化的原理
先來看一下計算機如何儲存浮點數與定點數:
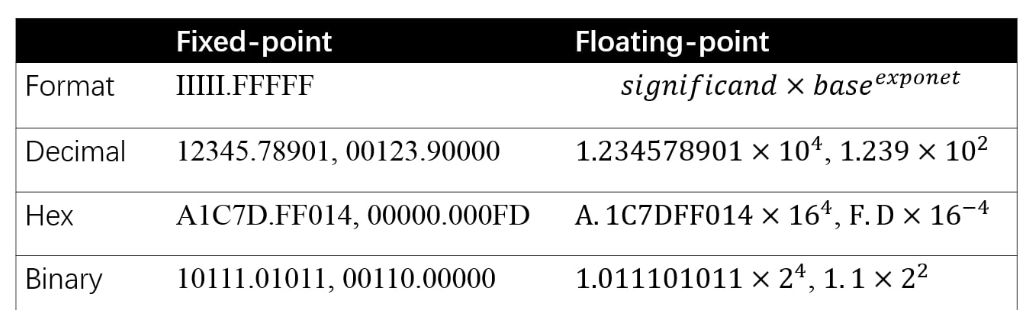
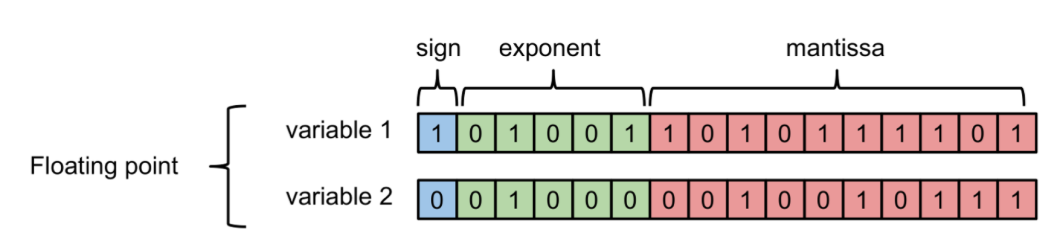
其中負指數決定了浮點數所能表達的絕對值最小的非零數;而正指數決定了浮點數所能表達的絕對值最大的數,也即決定了浮點數的取值範圍。
float的範圍為-2^128 ~ +2^128. 可以看到float的值域分佈是極其廣的。
說回量化的本質是:找到一個對映關係,使得float32與int8能夠一一對應. 。那問題來了,float32能夠表達值域是非常廣的,而int8只能表達[0,255].
怎麼能夠用255個數代表無限多(其實也不是無限多,很多,但是也還是有限個)的浮點數?
幸運地是,實踐證明,神經網路的weights往往是集中在一個非常狹窄的範圍,如下:
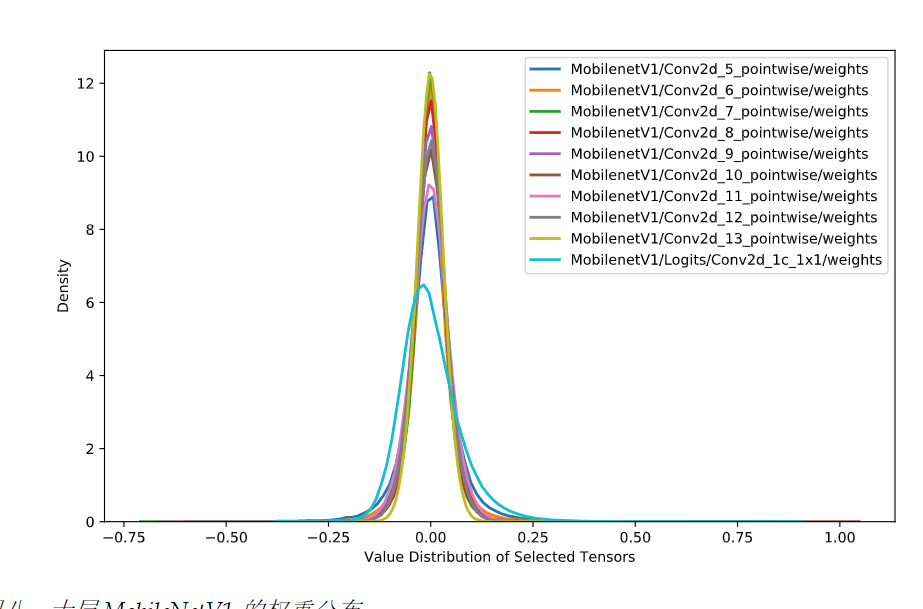
所以這個問題解決了,即我們並不需要對值域-2^128 ~ +2^128的所有值都做對映。但即便是一個很小的範圍,比如[-1,1]能夠表達的浮點數也是非常多的,所以勢必
會有多個浮點數被對映成同一個int8整數.從而造成精度的丟失.
這時候,第二個問題來了,為什麼量化是有效的,為什麼weights變為int8後,並不會讓模型的精度下降太多?
在搜尋了大量的資料以後,我發現目前並沒有一個很嚴謹的理論解釋這個事情.
您可能會問為什麼量化是有效的(具有足夠好的預測準確度),尤其是將 FP32 轉換為 INT8 時已經丟失了資訊?嚴格來說,目前尚未出現相關的嚴謹的理論。一個直覺解釋是,神經網路被過度引數化,進而包含足夠的冗餘資訊,裁剪這些冗餘資訊不會導致明顯的準確度下降。相關證據是,對於給定的量化方法,FP32 網路和 INT8 網路之間的準確度差距對於大型網路來說較小,因為大型網路過度引數化的程度更高
和深度學習模型一樣,很多時候,我們無法解釋為什麼有的引數就是能work,量化也是一樣,實踐證明,量化損失的精度不會太多,do not know why it works,it just works.
如何做量化
由以下公式完成float和int8之間的相互對映.
\(x_{float} = x_{scale} \times (x_{quantized} - x_{zero\_point})\)
其中引數由以下公式確定:

舉個例子,假設原始fp32模型的weights分佈在[-1.0,1.0],要對映到[0,255],則\(x_{scale}=2/255\),\(x_{zero\_point}=255-1/(2/255)=127\)
量化後的乘法和加法:
依舊以上述例子為例:
我們可以得到0.0:127,1.0:255的對映關係.
那麼原先的0.0 X 1.0 = 0.0 注意:並非用127x255再用公式轉回為float,這樣算得到的float=(2/255)x(127x255-127)=253

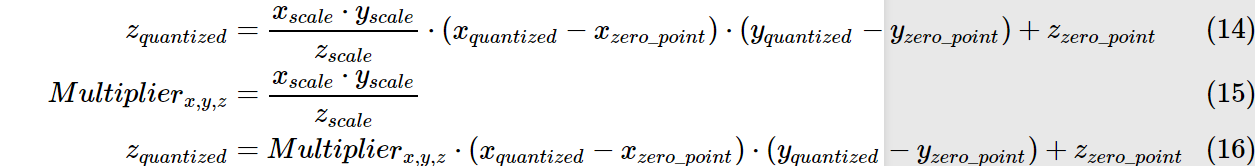
我們假設所有layer的資料分佈都是一致的.則根據上述公式可得\(z_{quantized}=127\),再將其轉換回float32,即0.0.
同理加法:

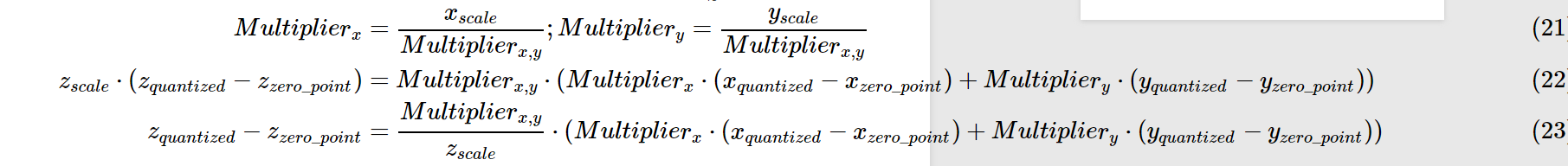
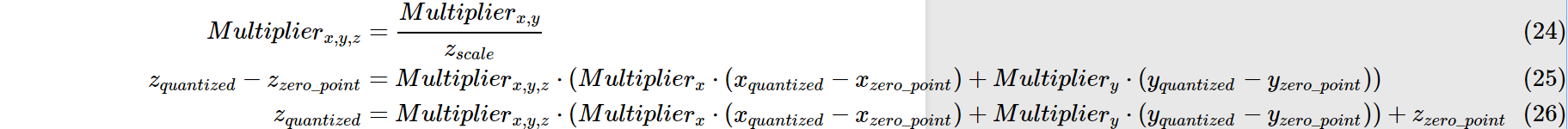
tflite_convert
日常吐槽:tensorflow sucks. tensorflow要不是大公司開發的,絕對不可能這麼流行. 文件混亂,又多又雜,api難理解難使用.
tensorflow中使用tflite_convert做模型量化.用法:
tflite_convert \
--output_file=/tmp/foo.cc \
--graph_def_file=/tmp/mobilenet_v1_0.50_128/frozen_graph.pb \
--inference_type=QUANTIZED_UINT8 \
--input_arrays=input \
--output_arrays=MobilenetV1/Predictions/Reshape_1 \
--default_ranges_min=0 \
--default_ranges_max=6 \
--mean_values=128 \
--std_dev_values=127官方指導:https://www.tensorflow.org/lite/convert/cmdline_examples
關於各引數的說明參見:
https://www.tensorflow.org/lite/convert/cmdline_reference
關於引數mean_values,std_dev_values比較讓人困惑.tf的文件裡,對這個引數的描述有3種形式.
- (mean, std_dev)
- (zero_point, scale)
- (min,max)
轉換關係如下:
std_dev = 1.0 / scale
mean = zero_point
mean = 255.0*min / (min - max)
std_dev = 255.0 / (max - min)結論:
訓練時模型的輸入tensor的值在不同範圍時,對應的mean_values,std_dev_values分別如下:
- range (0,255) then mean = 0, std_dev = 1
- range (-1,1) then mean = 127.5, std_dev = 127.5
- range (0,1) then mean = 0, std_dev = 255
參考:
https://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd
https://stackoverflow.com/questions/54830869/understanding-tf-contrib-lite-tfliteconverter-quantization-parameters/58096430#58096430
https://arleyzhang.github.io/articles/923e2c40/
https://zhuanlan.zhihu.com/p/79744430
https://zhuanlan.zhihu.com/p/58182