
程式設計師需要了解的硬核知識之組合語言(全)
之前的系列文章從 CPU 和記憶體方面簡單介紹了一下組合語言,但是還沒有系統的瞭解一下組合語言,組合語言作為第二代計算機語言,會用一些容易理解和記憶的字母,單詞來代替一個特定的指令,作為高階程式語言的基礎,有必要系統的瞭解一下組合語言,那麼本篇文章希望大家跟我一起來了解一下組合語言。
組合語言和原生代碼
我們在之前的文章中探討過,計算機 CPU 只能執行原生代碼(機器語言)程式,用 C 語言等高階語言編寫的程式碼,需要經過編譯器編譯後,轉換為原生代碼才能夠被 CPU 解釋執行。
但是原生代碼的可讀性非常差,所以需要使用一種能夠直接讀懂的語言來替換原生代碼,那就是在各原生代碼中,附帶上表示其功能的英文縮寫,比如在加法運算的原生代碼加上add(addition)
cmp(compare)的縮寫等,這些通過縮寫來表示具體原生代碼指令的標誌稱為 助記符,使用助記符的語言稱為組合語言。這樣,通過閱讀組合語言,也能夠了解原生代碼的含義了。
不過,即使是使用匯編語言編寫的原始碼,最終也必須要轉換為原生代碼才能夠執行,負責做這項工作的程式稱為編譯器,轉換的這個過程稱為彙編。在將原始碼轉換為原生代碼這個功能方面,彙編器和編譯器是同樣的。
用匯編語言編寫的原始碼和原生代碼是一一對應的。因而,原生代碼也可以反過來轉換成組合語言編寫的程式碼。把原生代碼轉換為彙編程式碼的這一過程稱為反彙編,執行反彙編的程式稱為反彙編程式。

哪怕是 C 語言編寫的原始碼,編譯後也會轉換成特定 CPU 用的原生代碼。而將其反彙編的話,就可以得到組合語言的原始碼,並對其內容進行調查。不過,原生代碼變成 C 語言原始碼的反編譯,要比原生代碼轉換成彙編程式碼的反彙編要困難,這是因為,C 語言程式碼和原生代碼不是一一對應的關係。
通過編譯器輸出組合語言的原始碼
我們上面提到原生代碼可以經過反彙編轉換成為彙編程式碼,但是隻有這一種轉換方式嗎?顯然不是,C 語言編寫的原始碼也能夠通過編譯器編譯稱為彙編程式碼,下面就來嘗試一下。
首先需要先做一些準備,需要先下載 Borland C++ 5.5 編譯器,為了方便,我這邊直接下載好了讀者直接從我的百度網盤提取即可 (連結:https://pan.baidu.com/s/19LqVICpn5GcV88thD2AnlA 密碼:hz1u)
下載完畢,需要進行配置,下面是配置說明 (https://wenku.baidu.com/view/22e2f418650e52ea551898ad.html),教程很完整跟著配置就可以,下面開始我們的編譯過程
首先用 Windows 記事本等文字編輯器編寫如下程式碼
// 返回兩個引數值之和的函式
int AddNum(int a,int b){
return a + b;
}
// 呼叫 AddNum 函式的函式
void MyFunc(){
int c;
c = AddNum(123,456);
}編寫完成後將其檔名儲存為 Sample4.c ,C 語言原始檔的副檔名,通常用.c 來表示,上面程式是提供兩個輸入引數並返回它們之和。
在 Windows 作業系統下開啟 命令提示符,切換到儲存 Sample4.c 的資料夾下,然後在命令提示符中輸入
bcc32 -c -S Sample4.cbcc32 是啟動 Borland C++ 的命令,-c 的選項是指僅進行編譯而不進行連結,-S 選項被用來指定生成組合語言的原始碼
作為編譯的結果,當前目錄下會生成一個名為Sample4.asm 的組合語言原始碼。組合語言原始檔的副檔名,通常用.asm 來表示,下面就讓我們用編輯器開啟看一下 Sample4.asm 中的內容
.386p
ifdef ??version
if ??version GT 500H
.mmx
endif
endif
model flat
ifndef ??version
?debug macro
endm
endif
?debug S "Sample4.c"
?debug T "Sample4.c"
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_TEXT segment dword public use32 'CODE'
_AddNum proc near
?live1@0:
;
; int AddNum(int a,int b){
;
push ebp
mov ebp,esp
;
;
; return a + b;
;
@1:
mov eax,dword ptr [ebp+8]
add eax,dword ptr [ebp+12]
;
; }
;
@3:
@2:
pop ebp
ret
_AddNum endp
_MyFunc proc near
?live1@48:
;
; void MyFunc(){
;
push ebp
mov ebp,esp
;
; int c;
; c = AddNum(123,456);
;
@4:
push 456
push 123
call _AddNum
add esp,8
;
; }
;
@5:
pop ebp
ret
_MyFunc endp
_TEXT ends
public _AddNum
public _MyFunc
?debug D "Sample4.c" 20343 45835
end這樣,編譯器就成功的把 C 語言轉換成為了彙編程式碼了。
不會轉換成原生代碼的偽指令
第一次看到彙編程式碼的讀者可能感覺起來比較難,不過實際上其實比較簡單,而且可能比 C 語言還要簡單,為了便於閱讀彙編程式碼的原始碼,需要注意幾個要點
組合語言的原始碼,是由轉換成原生代碼的指令(後面講述的操作碼)和針對彙編器的偽指令構成的。偽指令負責把程式的構造以及彙編的方法指示給彙編器(轉換程式)。不過偽指令是無法彙編轉換成為原生代碼的。下面是上面程式擷取的偽指令
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_AddNum proc near
_AddNum endp
_MyFunc proc near
_MyFunc endp
_TEXT ends
end由偽指令 segment 和 ends 圍起來的部分,是給構成程式的命令和資料的集合體上加一個名字而得到的,稱為段定義。段定義的英文表達具有區域的意思,在這個程式中,段定義指的是命令和資料等程式的集合體的意思,一個程式由多個段定義構成。
上面程式碼的開始位置,定義了3個名稱分別為 _TEXT、_DATA、_BSS 的段定義,_TEXT 是指定的段定義,_DATA 是被初始化(有初始值)的資料的段定義,_BSS 是尚未初始化的資料的段定義。這種定義的名稱是由 Borland C++ 定義的,是由 Borland C++ 編譯器自動分配的,所以程式段定義的順序就成為了 _TEXT、_DATA、_BSS ,這樣也確保了記憶體的連續性
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends段定義( segment ) 是用來區分或者劃分範圍區域的意思。組合語言的 segment 偽指令表示段定義的起始,ends 偽指令表示段定義的結束。段定義是一段連續的記憶體空間
而group 這個偽指令表示的是將 _BSS和_DATA 這兩個段定義彙總名為 DGROUP 的組
DGROUP group _BSS,_DATA圍起 _AddNum 和 _MyFun 的 _TEXT segment 和 _TEXT ends ,表示_AddNum 和 _MyFun 是屬於 _TEXT 這一段定義的。
_TEXT segment dword public use32 'CODE'
_TEXT ends因此,即使在原始碼中指令和資料是混雜編寫的,經過編譯和彙編後,也會轉換成為規整的原生代碼。
_AddNum proc 和 _AddNum endp 圍起來的部分,以及_MyFunc proc 和 _MyFunc endp 圍起來的部分,分別表示 AddNum 函式和 MyFunc 函式的範圍。
_AddNum proc near
_AddNum endp
_MyFunc proc near
_MyFunc endp編譯後在函式名前附帶上下劃線_ ,是 Borland C++ 的規定。在 C 語言中編寫的 AddNum 函式,在內部是以 _AddNum 這個名稱處理的。偽指令 proc 和 endp 圍起來的部分,表示的是 過程(procedure) 的範圍。在組合語言中,這種相當於 C 語言的函式的形式稱為過程。
末尾的 end 偽指令,表示的是原始碼的結束。
## 組合語言的語法是 操作碼 + 運算元
在組合語言中,一行表示一對 CPU 的一個指令。組合語言指令的語法結構是 操作碼 + 運算元,也存在只有操作碼沒有運算元的指令。
操作碼錶示的是指令動作,運算元表示的是指令物件。操作碼和運算元一起使用就是一個英文指令。比如從英語語法來分析的話,操作碼是動詞,運算元是賓語。比如這個句子 Give me money這個英文指令的話,Give 就是操作碼,me 和 money 就是運算元。組合語言中存在多個運算元的情況,要用逗號把它們分割,就像是 Give me,money 這樣。
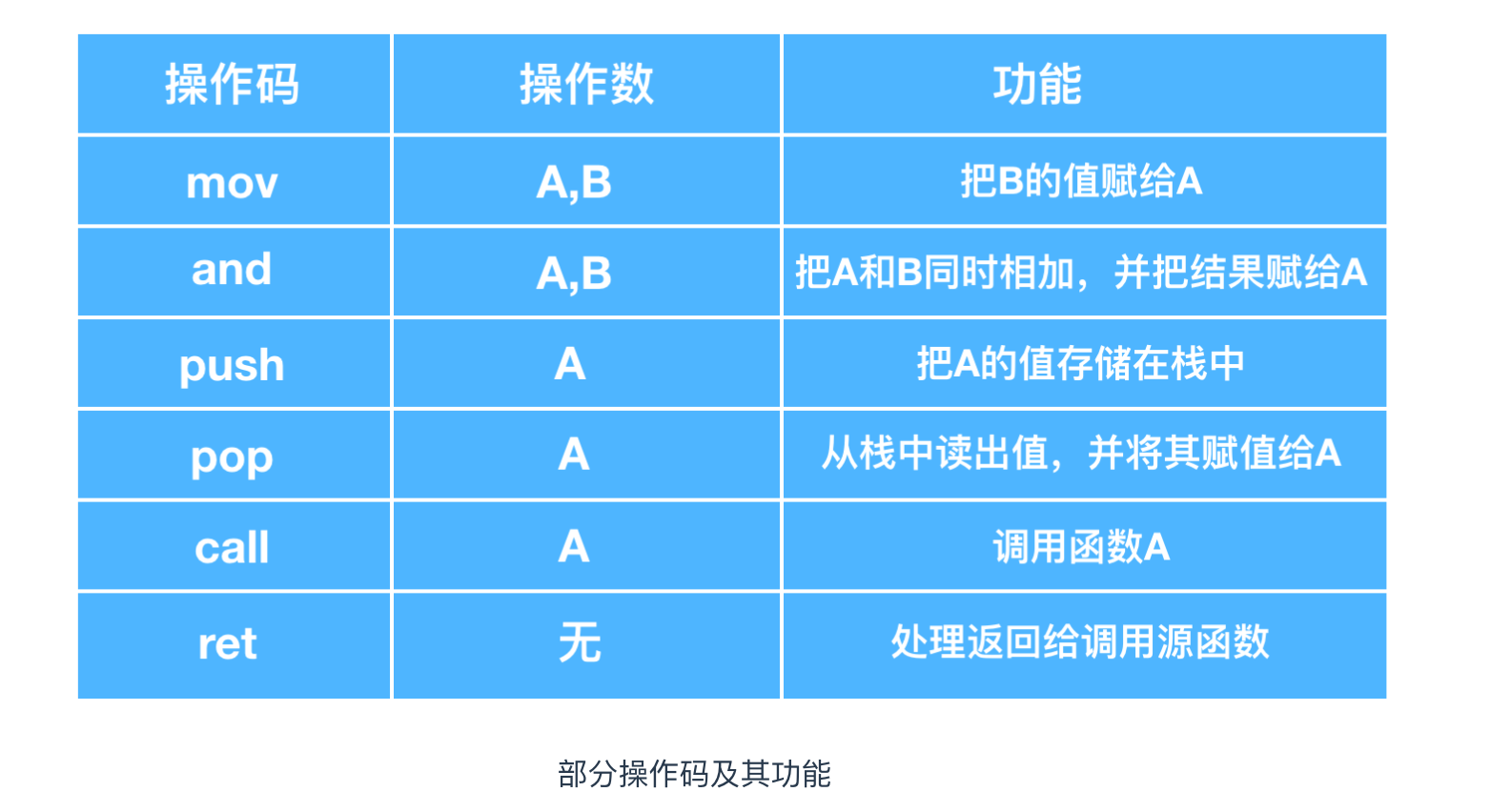
能夠使用何種形式的操作碼,是由 CPU 的種類決定的,下面對操作碼的功能進行了整理。
原生代碼需要載入到記憶體後才能執行,記憶體中儲存著構成原生代碼的指令和資料。程式執行時,CPU會從記憶體中把資料和指令讀出來,然後放在 CPU 內部的暫存器中進行處理。
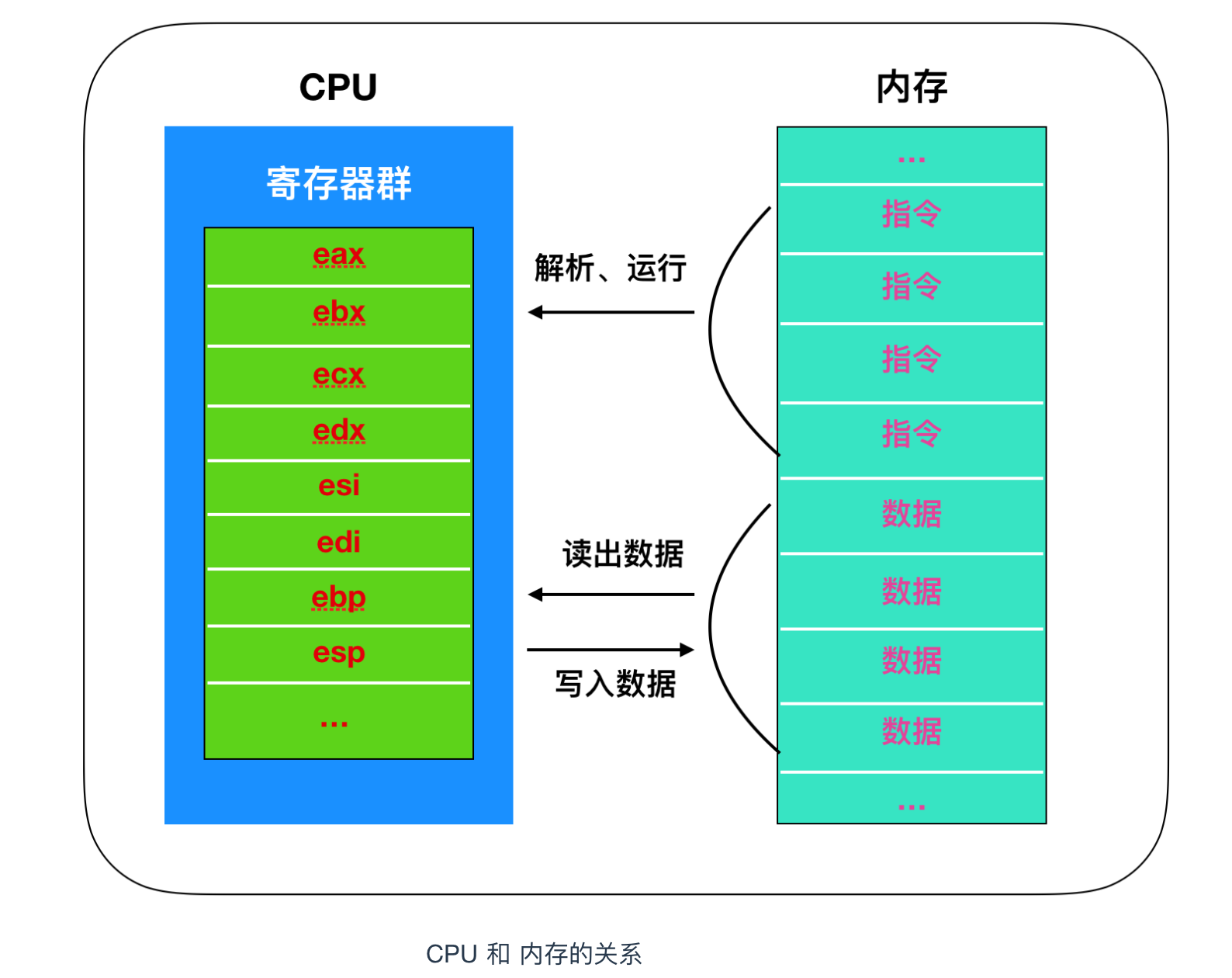
如果 CPU 和記憶體的關係你還不是很瞭解的話,請閱讀作者的另一篇文章 程式設計師需要了解的硬核知識之CPU 詳細瞭解。
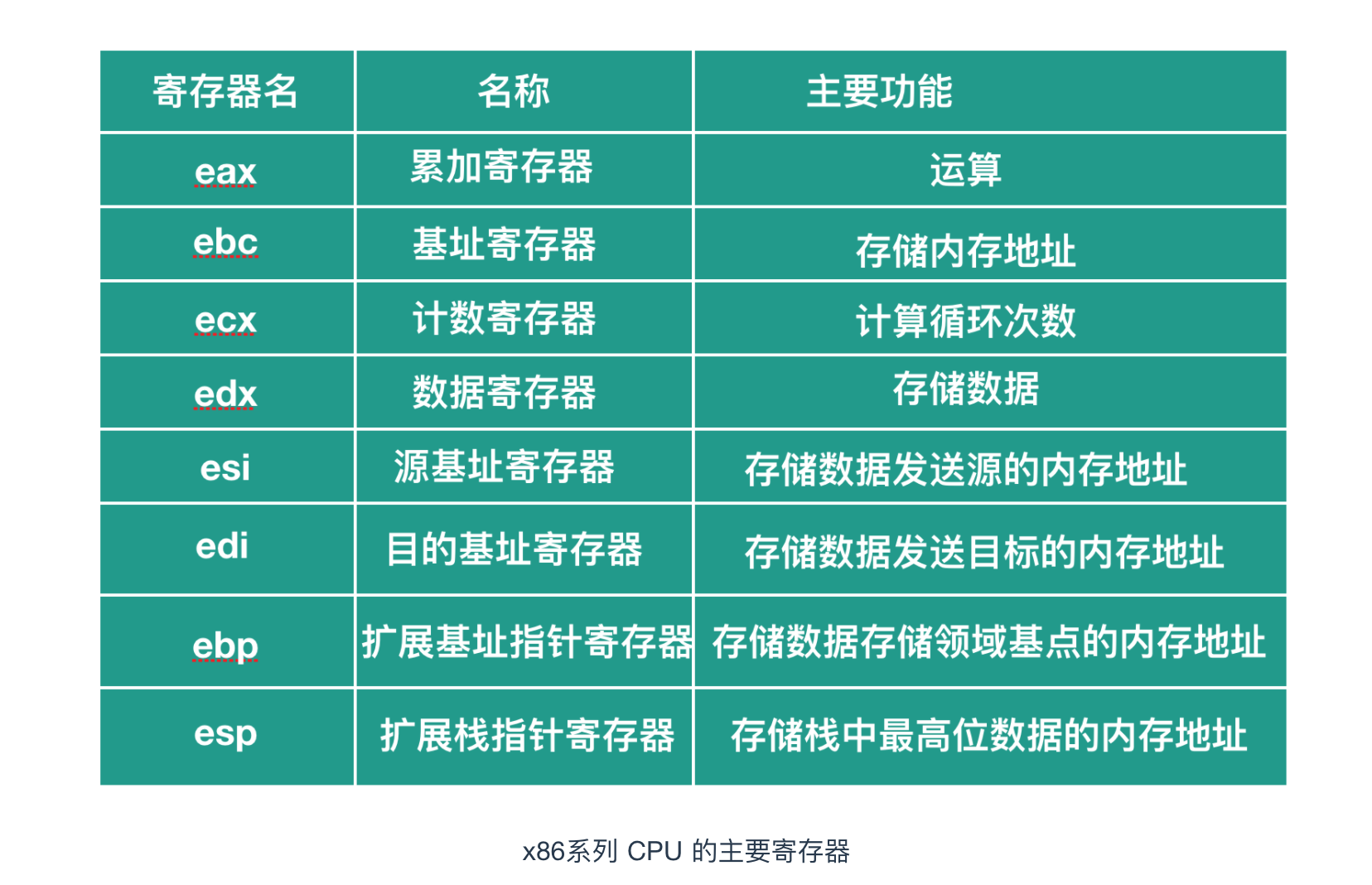
暫存器是 CPU 中的儲存區域,暫存器除了具有臨時儲存和計算的功能之外,還具有運算功能,x86 系列的主要種類和角色如下圖所示
指令解析
下面就對 CPU 中的指令進行分析
最常用的 mov 指令
指令中最常使用的是對暫存器和記憶體進行資料儲存的 mov 指令,mov 指令的兩個運算元,分別用來指定資料的儲存地和讀出源。運算元中可以指定暫存器、常數、標籤(附加在地址前),以及用方括號([]) 圍起來的這些內容。如果指定了沒有用([]) 方括號圍起來的內容,就表示對該值進行處理;如果指定了用方括號圍起來的內容,方括號的值則會被解釋為記憶體地址,然後就會對該記憶體地址對應的值進行讀寫操作。讓我們對上面的程式碼片段進行說明
mov ebp,esp
mov eax,dword ptr [ebp+8]mov ebp,esp 中,esp 暫存器中的值被直接儲存在了 ebp 中,也就是說,如果 esp 暫存器的值是100的話那麼 ebp 暫存器的值也是 100。
而在 mov eax,dword ptr [ebp+8] 這條指令中,ebp 暫存器的值 + 8 後會被解析稱為記憶體地址。如果 ebp
暫存器的值是100的話,那麼 eax 暫存器的值就是 100 + 8 的地址的值。dword ptr 也叫做 double word pointer 簡單解釋一下就是從指定的記憶體地址中讀出4位元組的資料
對棧進行 push 和 pop
程式執行時,會在記憶體上申請分配一個稱為棧的資料空間。棧(stack)的特性是後入先出,資料在儲存時是從記憶體的下層(大的地址編號)逐漸往上層(小的地址編號)累積,讀出時則是按照從上往下進行讀取的。
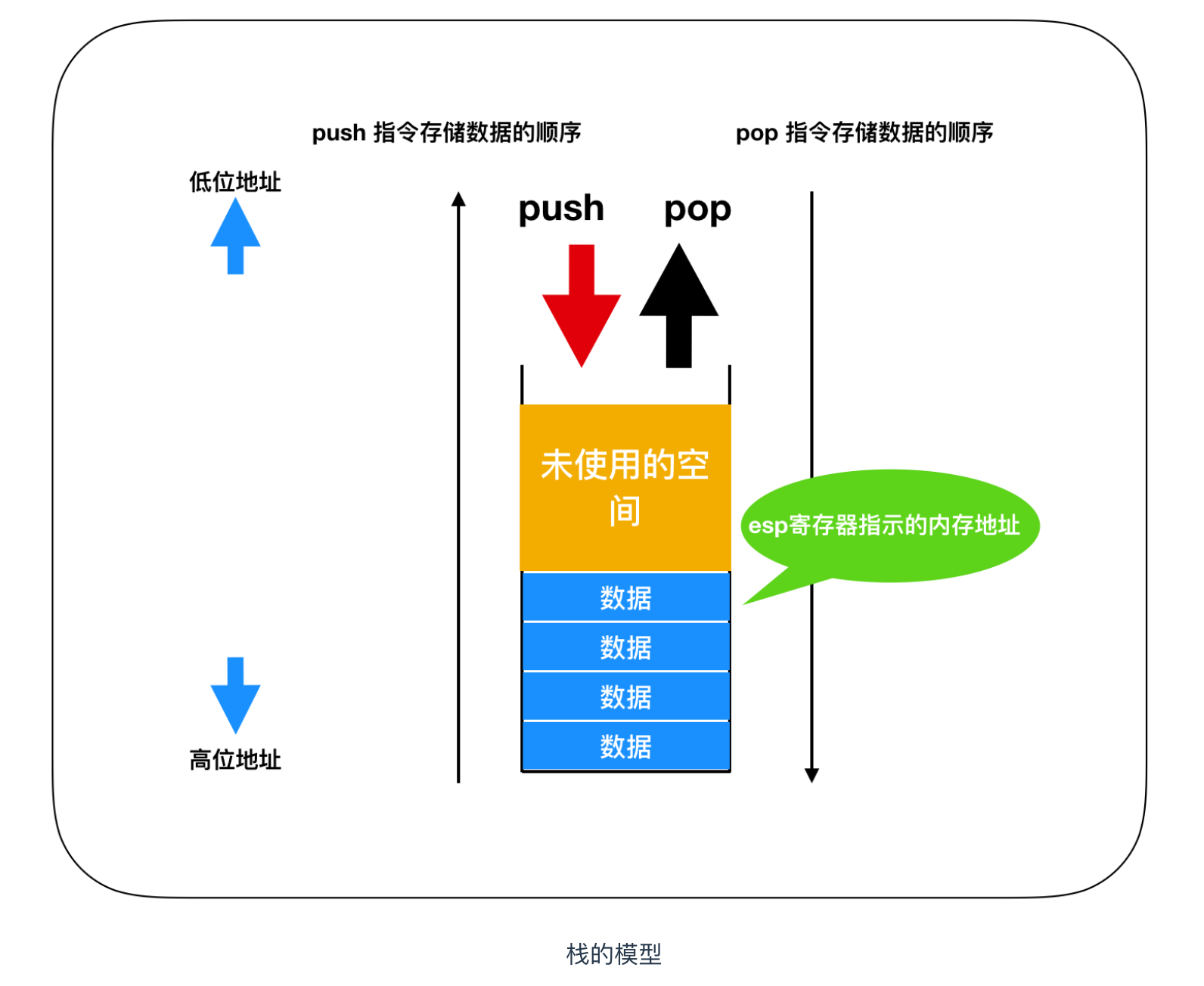
棧是儲存臨時資料的區域,它的特點是通過 push 指令和 pop 指令進行資料的儲存和讀出。向棧中儲存資料稱為 入棧 ,從棧中讀出資料稱為 出棧,32位 x86 系列的 CPU 中,進行1次 push 或者 pop,即可處理 32 位(4位元組)的資料。
函式的呼叫機制
下面我們一起來分析一下函式的呼叫機制,我們以上面的 C 語言編寫的程式碼為例。首先,讓我們從MyFunc 函式呼叫AddNum 函式的組合語言部分開始,來對函式的呼叫機制進行說明。棧在函式的呼叫中發揮了巨大的作用,下面是經過處理後的 MyFunc 函式的彙編處理內容
_MyFunc proc near
push ebp ; 將 ebp 暫存器的值存入棧中 (1)
mov ebp,esp ; 將 esp 暫存器的值存入 ebp 暫存器中 (2)
push 456 ; 將 456 入棧 (3)
push 123 ; 將 123 入棧 (4)
call _AddNum ; 呼叫 AddNum 函式 (5)
add esp,8 ; esp 暫存器的值 + 8 (6)
pop ebp ; 讀出棧中的數值存入 esp 暫存器中 (7)
ret ; 結束 MyFunc 函式,返回到呼叫源 (8)
_MyFunc endp程式碼解釋中的(1)、(2)、(7)、(8)的處理適用於 C 語言中的所有函式,我們會在後面展示 AddNum 函式處理內容時進行說明。這裡希望大家先關注(3) - (6) 這一部分,這對了解函式呼叫機制至關重要。
(3) 和 (4) 表示的是將傳遞給 AddNum 函式的引數通過 push 入棧。在 C 語言原始碼中,雖然記述為函式 AddNum(123,456),但入棧時則會先按照 456,123 這樣的順序。也就是位於後面的數值先入棧。這是 C 語言的規定。(5) 表示的 call 指令,會把程式流程跳轉到 AddNum 函式指令的地址處。在組合語言中,函式名表示的就是函式所在的記憶體地址。AddNum 函式處理完畢後,程式流程必須要返回到編號(6) 這一行。call 指令執行後,call 指令的下一行(也就指的是 (6) 這一行)的記憶體地址(呼叫函式完畢後要返回的記憶體地址)會自動的 push 入棧。該值會在 AddNum 函式處理的最後通過 ret 指令 pop 出棧,然後程式會返回到 (6) 這一行。
(6) 部分會把棧中儲存的兩個引數 (456 和 123) 進行銷燬處理。雖然通過兩次的 pop 指令也可以實現,不過採用 esp 暫存器 + 8 的方式會更有效率(處理 1 次即可)。對棧進行數值的輸入和輸出時,數值的單位是4位元組。因此,通過在負責棧地址管理的 esp 暫存器中加上4的2倍8,就可以達到和執行兩次 pop 命令同樣的效果。雖然記憶體中的資料實際上還殘留著,但只要把 esp 暫存器的值更新為資料儲存地址前面的資料位置,該資料也就相當於銷燬了。
我在編譯 Sample4.c 檔案時,出現了下圖的這條訊息

圖中的意思是指 c 的值在 MyFunc 定義了但是一直未被使用,這其實是一項編譯器優化的功能,由於儲存著 AddNum 函式返回值的變數 c 在後面沒有被用到,因此編譯器就認為 該變數沒有意義,進而也就沒有生成與之對應的組合語言程式碼。
下圖是呼叫 AddNum 這一函式前後棧記憶體的變化

函式的內部處理
上面我們用匯編程式碼分析了一下 Sample4.c 整個過程的程式碼,現在我們著重分析一下 AddNum 函式的原始碼部分,分析一下引數的接收、返回值和返回等機制
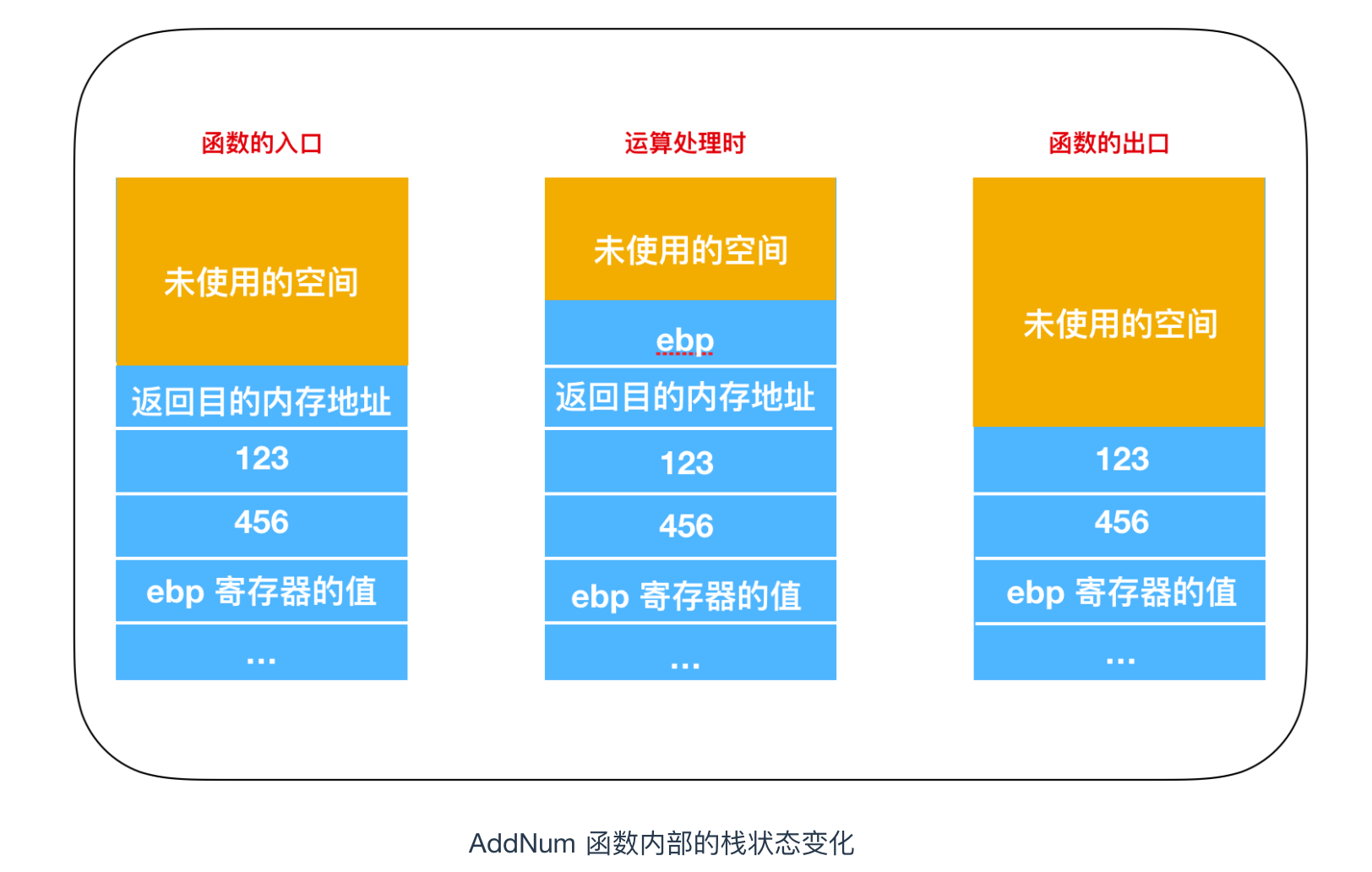
_AddNum proc near
push ebp (1)
mov ebp,esp (2)
mov eax,dword ptr[ebp+8] (3)
add eax,dword ptr[ebp+12] (4)
pop ebp (5)
ret (6)
_AddNum endpebp 暫存器的值在(1)中入棧,在(5)中出棧,這主要是為了把函式中用到的 ebp 暫存器的內容,恢復到函式呼叫前的狀態。
(2) 中把負責管理棧地址的 esp 暫存器的值賦值到了 ebp 暫存器中。這是因為,在 mov 指令中方括號內的引數,是不允許指定 esp 暫存器的。因此,這裡就採用了不直接通過 esp,而是用 ebp 暫存器來讀寫棧內容的方法。
(3) 使用[ebp + 8] 指定棧中儲存的第1個引數123,並將其讀出到 eax 暫存器中。像這樣,不使用 pop 指令,也可以參照棧的內容。而之所以從多個暫存器中選擇了 eax 暫存器,是因為 eax 是負責運算的累加暫存器。
通過(4) 的 add 指令,把當前 eax 暫存器的值同第2個引數相加後的結果儲存在 eax 暫存器中。[ebp + 12] 是用來指定第2個引數456的。在 C 語言中,函式的返回值必須通過 eax 暫存器返回,這也是規定。也就是 函式的引數是通過棧來傳遞,返回值是通過暫存器返回的。
(6) 中 ret 指令執行後,函式返回目的地記憶體地址會自動出棧,據此,程式流程就會跳轉返回到(6) (Call _AddNum) 的下一行。這時,AddNum 函式入口和出口處棧的狀態變化,就如下圖所示
全域性變數和區域性變數
在熟悉了組合語言後,接下來我們來了解一下全域性變數和區域性變數,在函式外部定義的變數稱為全域性變數,在函式內部定義的變數稱為區域性變數,全域性變數可以在任意函式中使用,區域性變數只能在函式定義區域性變數的內部使用。下面,我們就通過組合語言來看一下全域性變數和區域性變數的不同之處。
下面定義的 C 語言程式碼分別定義了局部變數和全域性變數,並且給各變數進行了賦值,我們先看一下原始碼部分
// 定義被初始化的全域性變數
int a1 = 1;
int a2 = 2;
int a3 = 3;
int a4 = 4;
int a5 = 5;
// 定義沒有初始化的全域性變數
int b1,b2,b3,b4,b5;
// 定義函式
void MyFunc(){
// 定義區域性變數
int c1,c2,c3,c4,c5,c6,c7,c8,c9,c10;
// 給區域性變數賦值
c1 = 1;
c2 = 2;
c3 = 3;
c4 = 4;
c5 = 5;
c6 = 6;
c7 = 7;
c8 = 8;
c9 = 9;
c10 = 10;
// 把區域性變數賦值給全域性變數
a1 = c1;
a2 = c2;
a3 = c3;
a4 = c4;
a5 = c5;
b1 = c6;
b2 = c7;
b3 = c8;
b4 = c9;
b5 = c10;
}上面的程式碼挺暴力的,不過沒關係,能夠便於我們分析其彙編原始碼就好,我們用 Borland C++ 編譯後的彙編程式碼如下,編譯完成後的原始碼比較長,這裡我們只拿出來一部分作為分析使用(我們改變了一下段定義順序,刪除了部分註釋)
_DATA segment dword public use32 'DATA'
align 4
_a1 label dword
dd 1
align 4
_a2 label dword
dd 2
align 4
_a3 label dword
dd 3
align 4
_a4 label dword
dd 4
align 4
_a5 label dword
dd 5
_DATA ends
_BSS segment dword public use32 'BSS'
align 4
_b1 label dword
db 4 dup(?)
align 4
_b2 label dword
db 4 dup(?)
align 4
_b3 label dword
db 4 dup(?)
align 4
_b4 label dword
db 4 dup(?)
align 4
_b5 label dword
db 4 dup(?)
_BSS ends
_TEXT segment dword public use32 'CODE'
_MyFunc proc near
push ebp
mov ebp,esp
add esp,-20
push ebx
push esi
mov eax,1
mov edx,2
mov ecx,3
mov ebx,4
mov esi,5
mov dword ptr [ebp-4],6
mov dword ptr [ebp-8],7
mov dword ptr [ebp-12],8
mov dword ptr [ebp-16],9
mov dword ptr [ebp-20],10
mov dword ptr [_a1],eax
mov dword ptr [_a2],edx
mov dword ptr [_a3],ecx
mov dword ptr [_a4],ebx
mov dword ptr [_a5],esi
mov eax,dword ptr [ebp-4]
mov dword ptr [_b1],eax
mov edx,dword ptr [ebp-8]
mov dword ptr [_b2],edx
mov ecx,dword ptr [ebp-12]
mov dword ptr [_b3],ecx
mov eax,dword ptr [ebp-16]
mov dword ptr [_b4],eax
mov edx,dword ptr [ebp-20]
mov dword ptr [_b5],edx
pop esi
pop ebx
mov esp,ebp
pop ebp
ret
_MyFunc endp
_TEXT ends編譯後的程式,會被歸類到名為段定義的組。
- 初始化的全域性變數,會彙總到名為 _DATA 的段定義中
_DATA segment dword public use32 'DATA'
...
_DATA ends- 沒有初始化的全域性變數,會彙總到名為 _BSS 的段定義中
_BSS segment dword public use32 'BSS'
...
_BSS ends- 被段定義 _TEXT 圍起來的彙編程式碼則是 Borland C++ 的定義
_TEXT segment dword public use32 'CODE'
_MyFunc proc near
...
_MyFunc endp
_TEXT ends我們在分析上面彙編程式碼之前,先來認識一下更多的彙編指令,此表是對上面部分操作碼及其功能的接續
| 操作碼 | 運算元 | 功能 |
|---|---|---|
| add | A,B | 把A和B的值相加,並把結果賦值給A |
| call | A | 呼叫函式A |
| cmp | A,B | 對A和B進行比較,比較結果會自動存入標誌暫存器中 |
| inc | A | 對A的值 + 1 |
| ige | 標籤名 | 和 cmp 命令組合使用。跳轉到標籤行 |
| jl | 標籤名 | 和 cmp 命令組合使用。跳轉到標籤行 |
| jle | 標籤名 | 和 cmp 命令組合使用。跳轉到標籤行 |
| jmp | 標籤名 | 和 cmp 命令組合使用。跳轉到標籤行 |
| mov | A,B | 把 B 的值賦給 A |
| pop | A | 從棧中讀取數值並存入A |
| push | A | 把A的值存入棧中 |
| ret | 無 | 將處理返回到呼叫源 |
| xor | A,B | A和B的位進行亦或比較,並將結果存入A中 |
我們首先來看一下 _DATA 段定義的內容。_a1 label dword 定義了 _a1 這個標籤。標籤表示的是相對於段定義起始位置的位置。由於_a1 在 _DATA 段定義的開頭位置,所以相對位置是0。 _a1 就相當於是全域性變數a1。編譯後的函式名和變數名前面會加一個(_),這也是 Borland C++ 的規定。dd 1 指的是,申請分配了4位元組的記憶體空間,儲存著1這個初始值。 dd指的是 define double word表示有兩個長度為2的位元組領域(word),也就是4位元組的意思。
Borland C++ 中,由於int 型別的長度是4位元組,因此彙編器就把 int a1 = 1 變換成了 _a1 label dword 和 dd 1。同樣,這裡也定義了相當於全域性變數的 a2 - a5 的標籤 _a2 - _a5,它們各自的初始值 2 - 5 也被儲存在各自的4位元組中。
接下來,我們來說一說 _BSS 段定義的內容。這裡定義了相當於全域性變數 b1 - b5 的標籤 _b1 - _b5。其中的db 4dup(?) 表示的是申請分配了4位元組的領域,但值尚未確定(這裡用 ? 來表示)的意思。db(define byte) 表示有1個長度是1位元組的記憶體空間。因而,db 4 dup(?) 的情況下,就是4位元組的記憶體空間。
注意:db 4 dup(?) 不要和 dd 4 混淆了,前者表示的是4個長度是1位元組的記憶體空間。而 db 4 表示的則是雙位元組( = 4 位元組) 的記憶體空間中儲存的值是 4
臨時確保區域性變數使用的記憶體空間
我們知道,區域性變數是臨時儲存在暫存器和棧中的。函式內部利用棧進行區域性變數的儲存,函式呼叫完成後,區域性變數值被銷燬,但是暫存器可能用於其他目的。所以,區域性變數只是函式在處理期間臨時儲存在暫存器和棧中的。
回想一下上述程式碼是不是定義了10個區域性變數?這是為了表示儲存區域性變數的不僅僅是棧,還有暫存器。為了確保 c1 - c10 所需的域,暫存器空閒的時候就會使用暫存器,暫存器空間不足的時候就會使用棧。
讓我們繼續來分析上面程式碼的內容。_TEXT段定義表示的是 MyFunc 函式的範圍。在 MyFunc 函式中定義的區域性變數所需要的記憶體領域。會被儘可能的分配在暫存器中。大家可能認為使用高效能的暫存器來替代普通的記憶體是一種資源浪費,但是編譯器不這麼認為,只要暫存器有空間,編譯器就會使用它。由於暫存器的訪問速度遠高於記憶體,所以直接訪問暫存器能夠高效的處理。區域性變數使用暫存器,是 Borland C++ 編譯器最優化的執行結果。
程式碼清單中的如下內容表示的是向暫存器中分配區域性變數的部分
mov eax,1
mov edx,2
mov ecx,3
mov ebx,4
mov esi,5僅僅對區域性變數進行定義是不夠的,只有在給區域性變數賦值時,才會被分配到暫存器的記憶體區域。上述程式碼相當於就是給5個區域性變數 c1 - c5 分別賦值為 1 - 5。eax、edx、ecx、ebx、esi 是 x86 系列32位 CPU 暫存器的名稱。至於使用哪個暫存器,是由編譯器來決定的 。
x86 系列 CPU 擁有的暫存器中,程式可以操作的是十幾,其中空閒的最多會有幾個。因而,區域性變數超過暫存器數量的時候,可分配的暫存器就不夠用了,這種情況下,編譯器就會把棧派上用場,用來儲存剩餘的區域性變數。
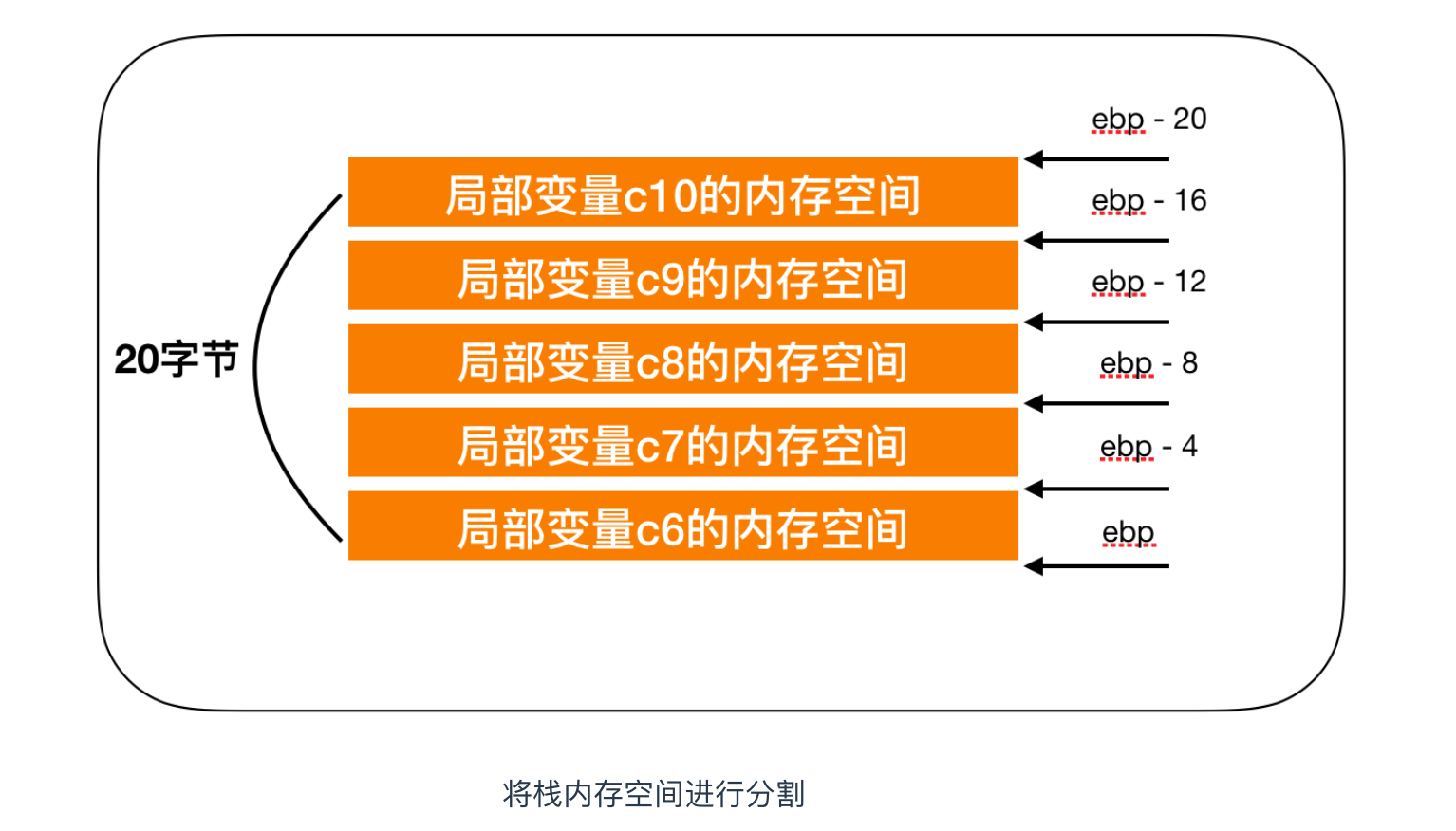
在上述程式碼這一部分,給區域性變數c1 - c5 分配完暫存器後,可用的暫存器數量就不足了。於是,剩下的5個區域性變數c6 - c10 就被分配給了棧的記憶體空間。如下面程式碼所示
mov dword ptr [ebp-4],6
mov dword ptr [ebp-8],7
mov dword ptr [ebp-12],8
mov dword ptr [ebp-16],9
mov dword ptr [ebp-20],10函式入口 add esp,-20 指的是,對棧資料儲存位置的 esp 暫存器(棧指標)的值做減20的處理。為了確保記憶體變數 c6 - c10 在棧中,就需要保留5個 int 型別的區域性變數(4位元組 * 5 = 20 位元組)所需的空間。mov ebp,esp這行指令表示的意思是將 esp 暫存器的值賦值到 ebp 暫存器。之所以需要這麼處理,是為了通過在函數出口處 mov esp ebp 這一處理,把 esp 暫存器的值還原到原始狀態,從而對申請分配的棧空間進行釋放,這時棧中用到的區域性變數就消失了。這也是棧的清理處理。在使用暫存器的情況下,區域性變數則會在暫存器被用於其他用途時自動消失,如下圖所示。

mov dword ptr [ebp-4],6
mov dword ptr [ebp-8],7
mov dword ptr [ebp-12],8
mov dword ptr [ebp-16],9
mov dword ptr [ebp-20],10這五行程式碼是往棧空間代入數值的部分,由於在向棧申請記憶體空間前,藉助了 mov ebp, esp 這個處理,esp 暫存器的值被儲存到了 esp 暫存器中,因此,通過使用[ebp - 4]、[ebp - 8]、[ebp - 12]、[ebp - 16]、[ebp - 20] 這樣的形式,就可以申請分配20位元組的棧記憶體空間切分成5個長度為4位元組的空間來使用。例如,mov dword ptr [ebp-4],6 表示的就是,從申請分配的記憶體空間的下端(ebp暫存器指示的位置)開始向前4位元組的地址([ebp - 4]) 中,儲存著6這一4位元組資料。
迴圈控制語句的處理
上面說的都是順序流程,那麼現在就讓我們分析一下迴圈流程的處理,看一下 for 迴圈以及 if 條件分支等 c 語言程式的 流程控制是如何實現的,我們還是以程式碼以及編譯後的結果為例,看一下程式控制流程的處理過程。
// 定義MySub 函式
void MySub(){
// 不做任何處理
}
// 定義MyFunc 函式
void Myfunc(){
int i;
for(int i = 0;i < 10;i++){
// 重複呼叫MySub十次
MySub();
}
}上述程式碼將區域性變數 i 作為迴圈條件,迴圈呼叫十次MySub 函式,下面是它主要的彙編程式碼
xor ebx, ebx ; 將暫存器清0
@4 call _MySub ; 呼叫MySub函式
inc ebx ; ebx暫存器的值 + 1
cmp ebx,10 ; 將ebx暫存器的值和10進行比較
jl short @4 ; 如果小於10就跳轉到 @4C 語言中的 for 語句是通過在括號中指定迴圈計數器的初始值(i = 0)、迴圈的繼續條件(i < 10)、迴圈計數器的更新(i++) 這三種形式來進行迴圈處理的。與此相對的彙編程式碼就是通過比較指令(cmp) 和 跳轉指令(jl)來實現的。
下面我們來對上述程式碼進行說明
MyFunc 函式中用到的區域性變數只有 i ,變數 i 申請分配了 ebx 暫存器的記憶體空間。for 語句括號中的 i = 0 被轉換為 xor ebx,ebx 這一處理,xor 指令會對左起第一個運算元和右起第二個運算元進行 XOR 運算,然後把結果儲存在第一個運算元中。由於這裡把第一個運算元和第二個運算元都指定為了 ebx,因此就變成了對相同數值的 XOR 運算。也就是說不管當前暫存器的值是什麼,最終的結果都是0。類似的,我們使用 mov ebx,0 也能得到相同的結果,但是 xor 指令的處理速度更快,而且編譯器也會啟動最優化功能。
XOR 指的就是異或操作,它的運算規則是 如果a、b兩個值不相同,則異或結果為1。如果a、b兩個值相同,異或結果為0。
相同數值進行 XOR 運算,運算結果為0。XOR 的運算規則是,值不同時結果為1,值相同時結果為0。例如 01010101 和 01010101 進行運算,就會分別對各個數字位進行 XOR 運算。因為每個數字位都相同,所以運算結果為0。
ebx 暫存器的值初始化後,會通過 call 指定呼叫 _MySub 函式,從 _MySub 函式返回後,會執行inc ebx 指令,對 ebx 的值進行 + 1 操作,這個操作就相當於 i++ 的意思,++ 表示的就是當前數值 + 1。
這裡需要知道 i++ 和 ++i 的區別
i++ 是先賦值,複製完成後再對 i執行 + 1 操作
++i 是先進行 +1 操作,完成後再進行賦值
inc 下一行的 cmp 是用來對第一個運算元和第二個運算元的數值進行比較的指令。 cmp ebx,10 就相當於 C 語言中的 i < 10 這一處理,意思是把 ebx 暫存器的值與10進行比較。組合語言中比較指令的結果,會儲存在 CPU 的標誌暫存器中。不過,標誌暫存器的值,程式是無法直接參考的。那如何判斷比較結果呢?
組合語言中有多個跳轉指令,這些跳轉指令會根據標誌暫存器的值來判斷是否進行跳轉操作,例如最後一行的 jl,它會根據 cmp ebx,10 指令所儲存在標誌暫存器中的值來判斷是否跳轉,jl 這條指令表示的就是 jump on less than(小於的話就跳轉)。發現如果 i 比 10 小,就會跳轉到 @4 所在的指令處繼續執行。
那麼彙編程式碼的意思也可以用 C 語言來改寫一下,加深理解
i ^= i;
L4: MySub();
i++;
if(i < 10) goto L4;程式碼第一行 i ^= i 指的就是 i 和 i 進行異或運算,也就是 XOR 運算,MySub() 函式用 L4 標籤來替代,然後進行 i 自增操作,如果i 的值小於 10 的話,就會一直迴圈 MySub() 函式。
條件分支的處理方法
條件分支的處理方式和迴圈的處理方式很相似,使用的也是 cmp 指令和跳轉指令。下面是用 C 語言編寫的條件分支的程式碼
// 定義MySub1 函式
void MySub1(){
// 不做任何處理
}
// 定義MySub2 函式
void MySub2(){
// 不做任何處理
}
// 定義MySub3 函式
void MySub3(){
// 不做任何處理
}
// 定義MyFunc 函式
void MyFunc(){
int a = 123;
// 根據條件呼叫不同的函式
if(a > 100){
MySub1();
}
else if(a < 50){
MySub2();
}
else
{
MySub3();
}
}很簡單的一個實現了條件判斷的 C 語言程式碼,那麼我們把它用 Borland C++ 編譯之後的結果如下
_MyFunc proc near
push ebp
mov ebp,esp
mov eax,123 ; 把123存入 eax 暫存器中
cmp eax,100 ; 把 eax 暫存器的值同100進行比較
jle short @8 ; 比100小時,跳轉到@8標籤
call _MySub1 ; 呼叫MySub1函式
jmp short @11 ; 跳轉到@11標籤
@8:
cmp eax,50 ; 把 eax 暫存器的值同50進行比較
jge short @10 ; 比50大時,跳轉到@10標籤
call _MySub2 ; 呼叫MySub2函式
jmp short @11 ; 跳轉到@11標籤
@10:
call _MySub3 ; 呼叫MySub3函式
@11:
pop ebp
ret
_MyFunc endp上面程式碼用到了三種跳轉指令,分別是jle(jump on less or equal) 比較結果小時跳轉,jge(jump on greater or equal) 比較結果大時跳轉,還有不管結果怎樣都會進行跳轉的jmp,在這些跳轉指令之前還有用來比較的指令 cmp,構成了上述彙編程式碼的主要邏輯形式。
瞭解程式執行邏輯的必要性
通過對上述彙編程式碼和 C 語言原始碼進行比較,想必大家對程式的執行方式有了新的理解,而且,從彙編原始碼中獲取的知識,也有助於瞭解 Java 等高階語言的特性,比如 Java 中就有 native 關鍵字修飾的變數,那麼這個變數的底層就是使用 C 語言編寫的,還有一些 Java 中的語法糖只有通過彙編程式碼才能知道其執行邏輯。在某些情況下,對於查詢 bug 的原因也是有幫助的。
上面我們瞭解到的程式設計方式都是序列處理的,那麼序列處理有什麼特點呢?
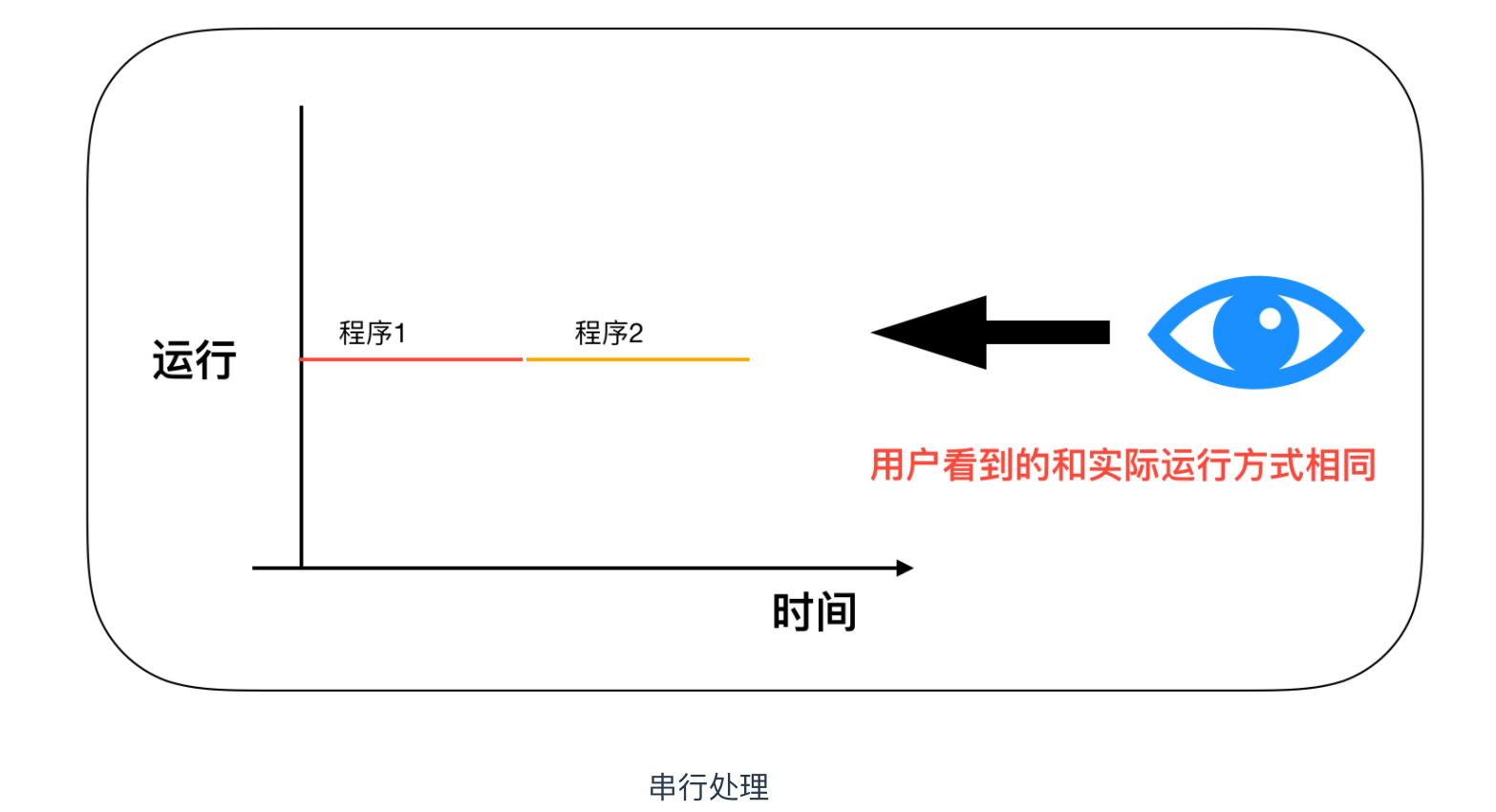
序列處理最大的一個特點就是專心只做一件事情,一件事情做完之後才會去做另外一件事情。
計算機是支援多執行緒的,多執行緒的核心就是 CPU切換,如下圖所示
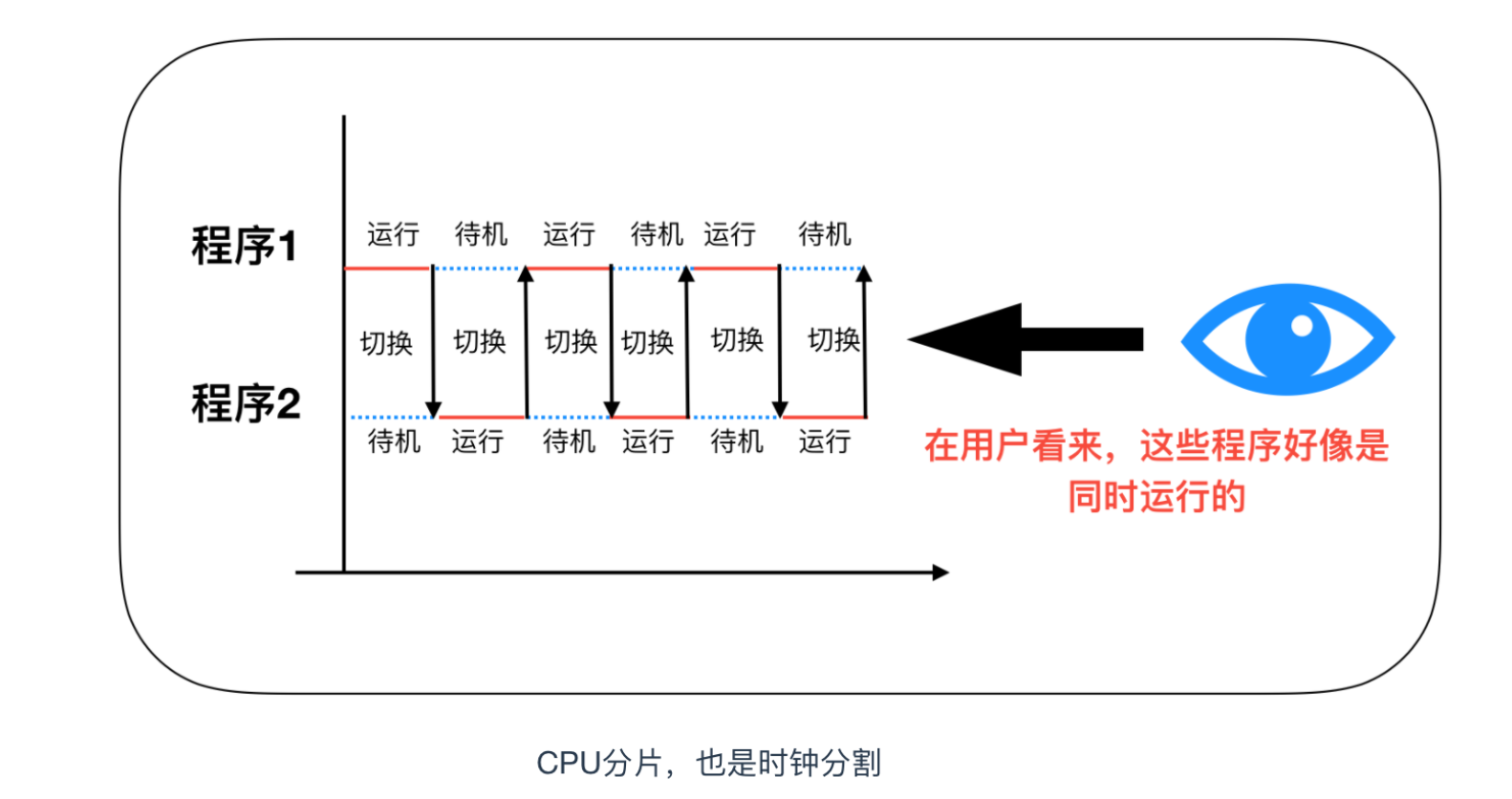
我們還是舉個實際的例子,讓我們來看一段程式碼
// 定義全域性變數
int counter = 100;
// 定義MyFunc1()
void MyFunc(){
counter *= 2;
}
// 定義MyFunc2()
void MyFunc2(){
counter *= 2;
}上述程式碼是更新 counter 的值的 C 語言程式,MyFunc1() 和 MyFunc2() 的處理內容都是把 counter 的值擴大至原來的二倍,然後再把 counter 的值賦值給 counter 。這裡,我們假設使用多執行緒處理,同時呼叫了一次MyFunc1 和 MyFunc2 函式,這時,全域性變數 counter 的值,理應程式設計 100 * 2 * 2 = 400。如果你開啟了多個執行緒的話,你會發現 counter 的數值有時也是 200,對於為什麼出現這種情況,如果你不瞭解程式的執行方式,是很難找到原因的。
我們將上面的程式碼轉換成組合語言的程式碼如下
mov eax,dword ptr[_counter] ; 將 counter 的值讀入 eax 暫存器
add eax,eax ; 將 eax 暫存器的值擴大2倍。
mov dword ptr[_counter],eax ; 將 eax 暫存器的值存入 counter 中。在多執行緒程式中,用匯編語言表示的程式碼每執行一行,處理都有可能切換到其他執行緒中。因而,假設 MyFun1 函式在讀出 counter 數值100後,還未來得及將它的二倍值200寫入 counter 時,正巧 MyFun2 函式讀出了 counter 的值100,那麼結果就將變為 200 。

為了避免該bug,我們可以採用以函式或 C 語言程式碼的行為單位來禁止執行緒切換的鎖定方法,或者使用某種執行緒安全的方式來避免該問題的出現。
現在基本上沒有人用匯編語言來編寫程式了,因為 C、Java等高階語言的效率要比組合語言快很多。不過,組合語言的經驗還是很重要的,通過藉助組合語言,我們可以更好的瞭解計算機執行機制。
文章參考:
《程式是怎樣跑起來的》第十章
關注公眾號後臺回覆 191106 即可獲得《程式是怎樣跑起來的》電子書
