
原始碼分析 RocketMQ DLedger 多副本之 Leader 選主
目錄
- 1、DLedger關於選主的核心類圖
- 1.1 DLedgerConfig
- 1.2 MemberState
- 1.3 raft協議相關
- 1.4 DLedgerRpcService
- 1.5 DLedgerLeaderElector
- 1.6 DLedgerServer
- 2、原始碼分析Leader選舉
- 2.1 DLedgerLeaderElector 類圖
- 2.2 啟動選舉狀態管理器
- 2.3 選舉狀態機狀態流轉
- 2.4 投票與投票請求
- 2.5 心跳包與心跳包響應
溫馨提示:《RocketMQ技術內幕》作者傾力打造的全新專欄:RocketMQ 多副本(主從切換):
1、《RocketMQ 多副本前置篇:初探raft協議》
本文將按照《RocketMQ 多副本前置篇:初探raft協議》的思路來學習RocketMQ選主邏輯。首先先回顧一下關於Leader的一些思考:
- 節點狀態
需要引入3種節點狀態:Follower(跟隨者)、Candidate(候選者),該狀態下的節點會發起投票請求,Leader(主節點)。 - 選舉計時器
Follower、Candidate兩個狀態時,需要維護一個定時器,每次定時時間從150ms-300ms直接進行隨機,即每個節點的定時過期不一樣,Follower狀態時,定時器到點後,觸發一輪投票。節點在收到投票請求、Leader的心跳請求並作出響應後,需要重置定時器。 - 投票輪次Team
Candidate狀態的節點,每發起一輪投票,Team加一。 - 投票機制
每一輪一個節點只能為一個節點投贊成票,例如節點A中維護的輪次為3,並且已經為節點B投了贊成票,如果收到其他節點,投票輪次為3,則會投反對票,如果收到輪次為4的節點,是又可以投贊成票的。 - 成為Leader的條件
必須得到叢集中初始數量的大多數,例如如果叢集中有3臺,則必須得到兩票,如果其中一臺伺服器宕機,剩下的兩個節點,還能進行選主嗎?答案是可以的,因為可以得到2票,超過初始叢集中3的一半,所以通常叢集中的機器各位儘量為奇數,因為4臺的可用性與3臺的一樣。
溫馨提示:本文是從原始碼的角度分析 DLedger 選主實現原理,可能比較鼓譟,文末給出了選主流程圖。
@(本節目錄)
1、DLedger關於選主的核心類圖
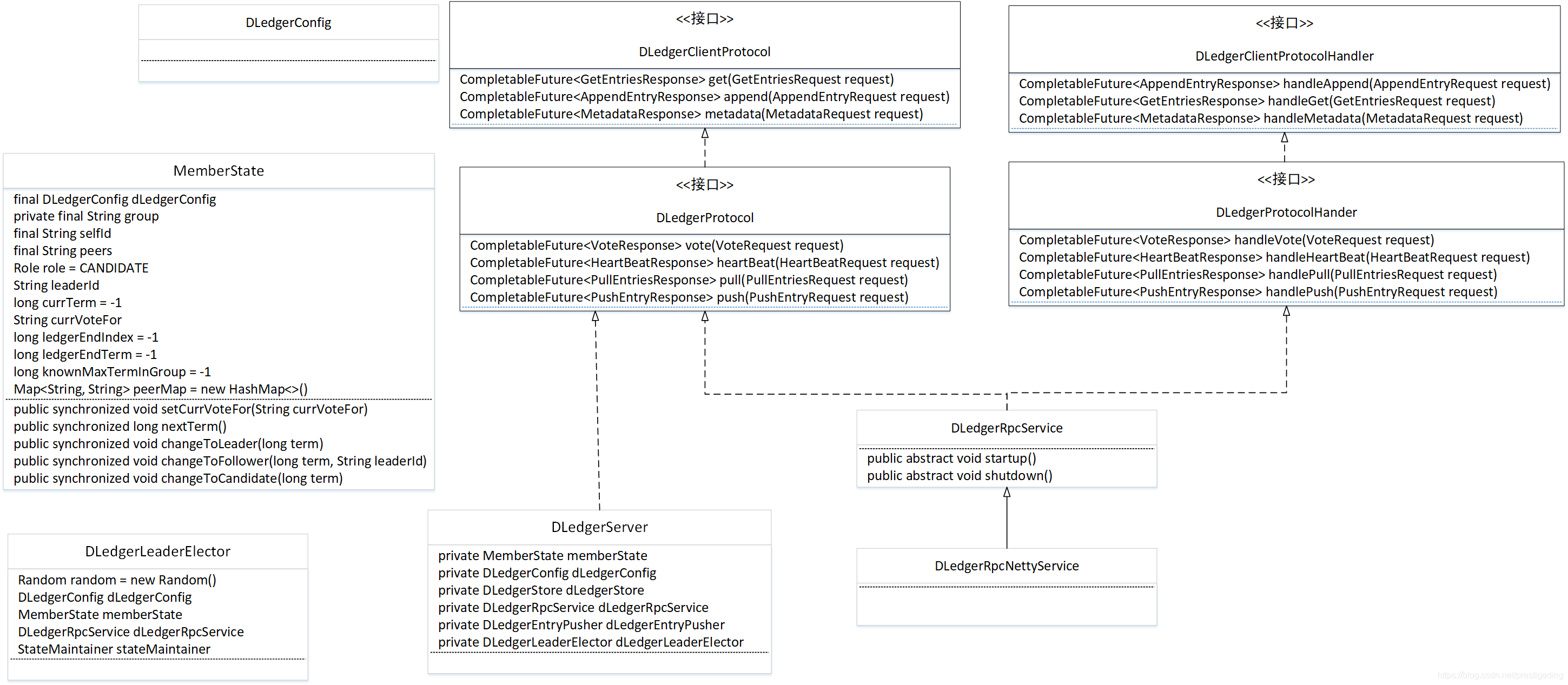
1.1 DLedgerConfig
多副本模組相關的配置資訊,例如叢集節點資訊。
1.2 MemberState
節點狀態機,即raft協議中的follower、candidate、leader三種狀態的狀態機實現。
1.3 raft協議相關
1.3.1 DLedgerClientProtocol
DLedger客戶端協議,主要定義如下三個方法,在後面的日誌複製部分會重點闡述。
- CompletableFuture< GetEntriesResponse> get(GetEntriesRequest request)
客戶端從伺服器獲取日誌條目(獲取資料) - CompletableFuture< AppendEntryResponse> append(AppendEntryRequest request)
客戶端向伺服器追加日誌(儲存資料) - CompletableFuture< MetadataResponse> metadata(MetadataRequest request)
獲取元資料。
1.3.2 DLedgerProtocol
DLedger服務端協議,主要定義如下三個方法。
- CompletableFuture< VoteResponse> vote(VoteRequest request)
發起投票請求。 - CompletableFuture< HeartBeatResponse> heartBeat(HeartBeatRequest request)
Leader向從節點發送心跳包。 - CompletableFuture< PullEntriesResponse> pull(PullEntriesRequest request)
拉取日誌條目,在日誌複製部分會詳細介紹。 - CompletableFuture< PushEntryResponse> push(PushEntryRequest request)
推送日誌條件,在日誌複製部分會詳細介紹。
1.3.3 協議處理Handler
DLedgerClientProtocolHandler、DLedgerProtocolHander協議處理器。
1.4 DLedgerRpcService
DLedger Server(節點)之間的網路通訊,預設基於Netty實現,其實現類為:DLedgerRpcNettyService。
1.5 DLedgerLeaderElector
Leader選舉實現器。
1.6 DLedgerServer
Dledger Server,Dledger節點的封裝類。
接下來將從DLedgerLeaderElector開始剖析DLedger是如何實現Leader選舉的。(基於raft協議)。
2、原始碼分析Leader選舉
2.1 DLedgerLeaderElector 類圖
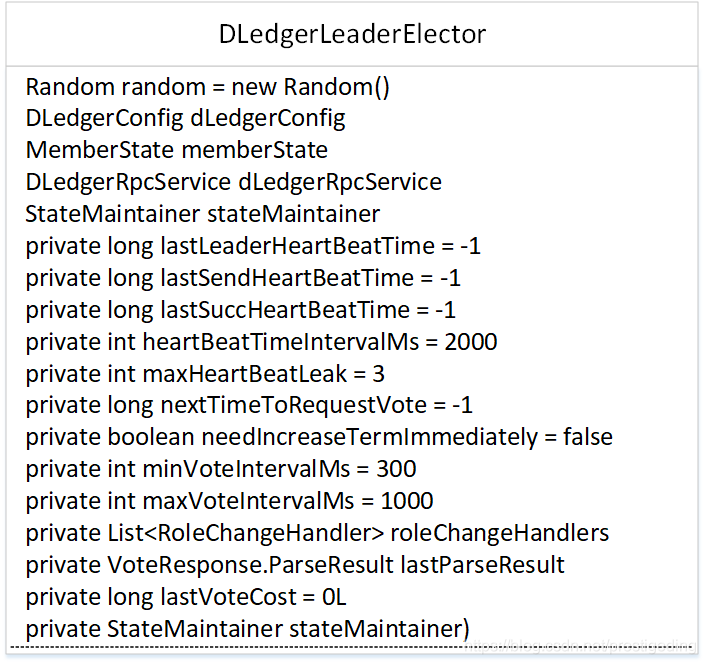
我們先一一來介紹其屬性的含義:
- Random random
隨機數生成器,對應raft協議中選舉超時時間是一隨機數。 - DLedgerConfig dLedgerConfig
配置引數。 - MemberState memberState
節點狀態機。 - DLedgerRpcService dLedgerRpcService
rpc服務,實現向叢集內的節點發送心跳包、投票的RPC實現。
l- ong lastLeaderHeartBeatTime
上次收到心跳包的時間戳。 - long lastSendHeartBeatTime
上次傳送心跳包的時間戳。 - long lastSuccHeartBeatTime
上次成功收到心跳包的時間戳。 - int heartBeatTimeIntervalMs
一個心跳包的週期,預設為2s。 - int maxHeartBeatLeak
允許最大的N個心跳週期內未收到心跳包,狀態為Follower的節點只有超過 maxHeartBeatLeak * heartBeatTimeIntervalMs 的時間內未收到主節點的心跳包,才會重新進入 Candidate 狀態,重新下一輪的選舉。 - long nextTimeToRequestVote
傳送下一個心跳包的時間戳。 - boolean needIncreaseTermImmediately
是否應該立即發起投票。 - int minVoteIntervalMs
最小的傳送投票間隔時間,預設為300ms。 - int maxVoteIntervalMs
最大的傳送投票的間隔,預設為1000ms。 - List< RoleChangeHandler> roleChangeHandlers
註冊的節點狀態處理器,通過 addRoleChangeHandler 方法新增。 - long lastVoteCost
上一次投票的開銷。 - StateMaintainer stateMaintainer
狀態機管理器。
2.2 啟動選舉狀態管理器
通過 DLedgerLeaderElector 的 startup 方法啟動狀態管理機,程式碼如下:
DLedgerLeaderElector#startup
public void startup() {
stateMaintainer.start(); // @1
for (RoleChangeHandler roleChangeHandler : roleChangeHandlers) { // @2
roleChangeHandler.startup();
}
}程式碼@1:啟動狀態維護管理器。
程式碼@2:遍歷狀態改變監聽器並啟動它,可通過DLedgerLeaderElector 的 addRoleChangeHandler 方法增加狀態變化監聽器。
其中的是啟動狀態管理器執行緒,其run方法實現:
public void run() {
while (running.get()) {
try {
doWork();
} catch (Throwable t) {
if (logger != null) {
logger.error("Unexpected Error in running {} ", getName(), t);
}
}
}
latch.countDown();
} 從上面來看,主要是迴圈呼叫doWork方法,接下來重點看其doWork的實現:
public void doWork() {
try {
if (DLedgerLeaderElector.this.dLedgerConfig.isEnableLeaderElector()) { // @1
DLedgerLeaderElector.this.refreshIntervals(dLedgerConfig); // @2
DLedgerLeaderElector.this.maintainState(); // @3
}
sleep(10); // @4
} catch (Throwable t) {
DLedgerLeaderElector.logger.error("Error in heartbeat", t);
}
}程式碼@1:如果該節點參與Leader選舉,則首先呼叫@2重置定時器,然後驅動狀態機(@3),是接下來重點需要剖析的。
程式碼@4:沒執行一次選主,休息10ms。
DLedgerLeaderElector#maintainState
private void maintainState() throws Exception {
if (memberState.isLeader()) {
maintainAsLeader();
} else if (memberState.isFollower()) {
maintainAsFollower();
} else {
maintainAsCandidate();
}
}根據當前的狀態機狀態,執行對應的操作,從raft協議中可知,總共存在3種狀態:
- leader
領導者,主節點,該狀態下,需要定時向從節點發送心跳包,用來傳播資料、確保其領導地位。 - follower
從節點,該狀態下,會開啟定時器,嘗試進入到candidate狀態,以便發起投票選舉,同時一旦收到主節點的心跳包,則重置定時器。 - candidate
候選者,該狀態下的節點會發起投票,嘗試選擇自己為主節點,選舉成功後,不會存在該狀態下的節點。
我們在繼續往下看之前,需要知道 memberState 的初始值是什麼?我們追溯到建立 MemberState 的地方,發現其初始狀態為 CANDIDATE。那我們接下從 maintainAsCandidate 方法開始跟進。
溫馨提示:在raft協議中,節點的狀態預設為follower,DLedger的實現從candidate開始,一開始,叢集內的所有節點都會嘗試發起投票,這樣第一輪要達成選舉幾乎不太可能。
2.3 選舉狀態機狀態流轉
整個狀態機的驅動,由執行緒反覆執行maintainState方法。下面重點來分析其狀態的驅動。
2.3.1 maintainAsCandidate 方法
DLedgerLeaderElector#maintainAsCandidate
if (System.currentTimeMillis() < nextTimeToRequestVote && !needIncreaseTermImmediately) {
return;
}
long term;
long ledgerEndTerm;
long ledgerEndIndex;Step1:首先先介紹幾個變數的含義:
- nextTimeToRequestVote
下一次發發起的投票的時間,如果當前時間小於該值,說明計時器未過期,此時無需發起投票。 - needIncreaseTermImmediately
是否應該立即發起投票。如果為true,則忽略計時器,該值預設為false,當收到從主節點的心跳包並且當前狀態機的輪次大於主節點的輪次,說明叢集中Leader的投票輪次小於從幾點的輪次,應該立即發起新的投票。 - term
投票輪次。 - ledgerEndTerm
Leader節點當前的投票輪次。 - ledgerEndIndex
當前日誌的最大序列,即下一條日誌的開始index,在日誌複製部分會詳細介紹。
DLedgerLeaderElector#maintainAsCandidate
synchronized (memberState) {
if (!memberState.isCandidate()) {
return;
}
if (lastParseResult == VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT || needIncreaseTermImmediately) {
long prevTerm = memberState.currTerm();
term = memberState.nextTerm();
logger.info("{}_[INCREASE_TERM] from {} to {}", memberState.getSelfId(), prevTerm, term);
lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
} else {
term = memberState.currTerm();
}
ledgerEndIndex = memberState.getLedgerEndIndex();
ledgerEndTerm = memberState.getLedgerEndTerm();
}Step2:初始化team、ledgerEndIndex 、ledgerEndTerm 屬性,其實現關鍵點如下:
- 如果上一次的投票結果為待下一次投票或應該立即開啟投票,並且根據當前狀態機獲取下一輪的投票輪次,稍後會著重講解一下狀態機輪次的維護機制。
- 如果上一次的投票結果不是WAIT_TO_VOTE_NEXT(等待下一輪投票),則投票輪次依然為狀態機內部維護的輪次。
DLedgerLeaderElector#maintainAsCandidate
if (needIncreaseTermImmediately) {
nextTimeToRequestVote = getNextTimeToRequestVote();
needIncreaseTermImmediately = false;
return;
}Step3:如果needIncreaseTermImmediately為true,則重置該標記位為false,並重新設定下一次投票超時時間,其實現程式碼如下:
private long getNextTimeToRequestVote() {
return System.currentTimeMillis() + lastVoteCost + minVoteIntervalMs + random.nextInt(maxVoteIntervalMs - minVoteIntervalMs);
}下一次倒計時:當前時間戳 + 上次投票的開銷 + 最小投票間隔(300ms) + (1000- 300 )之間的隨機值。
final List<CompletableFuture<VoteResponse>> quorumVoteResponses = voteForQuorumResponses(term, ledgerEndTerm, ledgerEndIndex);Step4:向叢集內的其他節點發起投票請,並返回投票結果列表,稍後會重點分析其投票過程。可以預見,接下來就是根據各投票結果進行仲裁。
final AtomicLong knownMaxTermInGroup = new AtomicLong(-1);
final AtomicInteger allNum = new AtomicInteger(0);
final AtomicInteger validNum = new AtomicInteger(0);
final AtomicInteger acceptedNum = new AtomicInteger(0);
final AtomicInteger notReadyTermNum = new AtomicInteger(0);
final AtomicInteger biggerLedgerNum = new AtomicInteger(0);
final AtomicBoolean alreadyHasLeader = new AtomicBoolean(false);Step5:在進行投票結果仲裁之前,先來介紹幾個區域性變數的含義:
- knownMaxTermInGroup
已知的最大投票輪次。 - allNum
所有投票票數。 - validNum
有效投票數。 - acceptedNum
獲得的投票數。 - notReadyTermNum
未準備投票的節點數量,如果對端節點的投票輪次小於發起投票的輪次,則認為對端未準備好,對端節點使用本次的輪次進入 - Candidate 狀態。 - biggerLedgerNum
發起投票的節點的ledgerEndTerm小於對端節點的個數。 - alreadyHasLeader
是否已經存在Leader。
for (CompletableFuture<VoteResponse> future : quorumVoteResponses) {
// 省略部分程式碼
}Step5:遍歷投票結果,收集投票結果,接下來重點看其內部實現。
if (x.getVoteResult() != VoteResponse.RESULT.UNKNOWN) {
validNum.incrementAndGet();
}Step6:如果投票結果不是UNKNOW,則有效投票數量增1。
synchronized (knownMaxTermInGroup) {
switch (x.getVoteResult()) {
case ACCEPT:
acceptedNum.incrementAndGet();
break;
case REJECT_ALREADY_VOTED:
break;
case REJECT_ALREADY_HAS_LEADER:
alreadyHasLeader.compareAndSet(false, true);
break;
case REJECT_TERM_SMALL_THAN_LEDGER:
case REJECT_EXPIRED_VOTE_TERM:
if (x.getTerm() > knownMaxTermInGroup.get()) {
knownMaxTermInGroup.set(x.getTerm());
}
break;
case REJECT_EXPIRED_LEDGER_TERM:
case REJECT_SMALL_LEDGER_END_INDEX:
biggerLedgerNum.incrementAndGet();
break;
case REJECT_TERM_NOT_READY:
notReadyTermNum.incrementAndGet();
break;
default:
break;
}
}Step7:統計投票結構,幾個關鍵點如下:
- ACCEPT
贊成票,acceptedNum加一,只有得到的贊成票超過叢集節點數量的一半才能成為Leader。 - REJECT_ALREADY_VOTED
拒絕票,原因是已經投了其他節點的票。 - REJECT_ALREADY_HAS_LEADER
拒絕票,原因是因為叢集中已經存在Leaer了。alreadyHasLeader設定為true,無需在判斷其他投票結果了,結束本輪投票。 - REJECT_TERM_SMALL_THAN_LEDGER
拒絕票,如果自己維護的term小於遠端維護的ledgerEndTerm,則返回該結果,如果對端的team大於自己的team,需要記錄對端最大的投票輪次,以便更新自己的投票輪次。 - REJECT_EXPIRED_VOTE_TERM
拒絕票,如果自己維護的term小於遠端維護的term,更新自己維護的投票輪次。 - REJECT_EXPIRED_LEDGER_TERM
拒絕票,如果自己維護的 ledgerTerm小於對端維護的ledgerTerm,則返回該結果。如果是此種情況,增加計數器- biggerLedgerNum的值。 - REJECT_SMALL_LEDGER_END_INDEX
拒絕票,如果對端的ledgerTeam與自己維護的ledgerTeam相等,但是自己維護的dedgerEndIndex小於對端維護的值,返回該值,增加biggerLedgerNum計數器的值。 - REJECT_TERM_NOT_READY
拒絕票,對端的投票輪次小於自己的team,則認為對端還未準備好投票,對端使用自己的投票輪次,是自己進入到Candidate狀態。
try {
voteLatch.await(3000 + random.nextInt(maxVoteIntervalMs), TimeUnit.MILLISECONDS);
} catch (Throwable ignore) {
}Step8:等待收集投票結果,並設定超時時間。
lastVoteCost = DLedgerUtils.elapsed(startVoteTimeMs);
VoteResponse.ParseResult parseResult;
if (knownMaxTermInGroup.get() > term) {
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote();
changeRoleToCandidate(knownMaxTermInGroup.get());
} else if (alreadyHasLeader.get()) {
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote() + heartBeatTimeIntervalMs * maxHeartBeatLeak;
} else if (!memberState.isQuorum(validNum.get())) {
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote();
} else if (memberState.isQuorum(acceptedNum.get())) {
parseResult = VoteResponse.ParseResult.PASSED;
} else if (memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) {
parseResult = VoteResponse.ParseResult.REVOTE_IMMEDIATELY;
} else if (memberState.isQuorum(acceptedNum.get() + biggerLedgerNum.get())) {
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote();
} else {
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote();
}Step9:根據收集的投票結果判斷是否能成為Leader。
溫馨提示:在講解關鍵點之前,我們先定義先將(當前時間戳 + 上次投票的開銷 + 最小投票間隔(300ms) + (1000- 300 )之間的隨機值)定義為“ 1個常規計時器”。
其關鍵點如下:
- 如果對端的投票輪次大於發起投票的節點,則該節點使用對端的輪次,重新進入到Candidate狀態,並且重置投票計時器,其值為“1個常規計時器”
- 如果已經存在Leader,該節點重新進入到Candidate,並重置定時器,該定時器的時間: “1個常規計時器” + heartBeatTimeIntervalMs * maxHeartBeatLeak ,其中 heartBeatTimeIntervalMs 為一次心跳間隔時間,
maxHeartBeatLeak 為 允許最大丟失的心跳包,即如果Flower節點在多少個心跳週期內未收到心跳包,則認為Leader已下線。 - 如果收到的有效票數未超過半數,則重置計時器為“ 1個常規計時器”,然後等待重新投票,注意狀態為WAIT_TO_REVOTE,該狀態下的特徵是下次投票時不增加投票輪次。
- 如果得到的贊同票超過半數,則成為Leader。
- 如果得到的贊成票加上未準備投票的節點數超過半數,則應該立即發起投票,故其結果為REVOTE_IMMEDIATELY。
- 如果得到的贊成票加上對端維護的ledgerEndIndex超過半數,則重置計時器,繼續本輪次的選舉。
- 其他情況,開啟下一輪投票。
if (parseResult == VoteResponse.ParseResult.PASSED) {
logger.info("[{}] [VOTE_RESULT] has been elected to be the leader in term {}", memberState.getSelfId(), term);
changeRoleToLeader(term);
}Step10:如果投票成功,則狀態機狀態設定為Leader,然後狀態管理在驅動狀態時會呼叫DLedgerLeaderElector#maintainState時,將進入到maintainAsLeader方法。
2.3.2 maintainAsLeader 方法
經過maintainAsCandidate 投票選舉後,被其他節點選舉成為領導後,會執行該方法,其他節點的狀態還是Candidate,並在計時器過期後,又嘗試去發起選舉。接下來重點分析成為Leader節點後,該節點會做些什麼?
DLedgerLeaderElector#maintainAsLeader
private void maintainAsLeader() throws Exception {
if (DLedgerUtils.elapsed(lastSendHeartBeatTime) > heartBeatTimeIntervalMs) { // @1
long term;
String leaderId;
synchronized (memberState) {
if (!memberState.isLeader()) { // @2
//stop sending
return;
}
term = memberState.currTerm();
leaderId = memberState.getLeaderId();
lastSendHeartBeatTime = System.currentTimeMillis(); // @3
}
sendHeartbeats(term, leaderId); // @4
}
}程式碼@1:首先判斷上一次傳送心跳的時間與當前時間的差值是否大於心跳包傳送間隔,如果超過,則說明需要傳送心跳包。
程式碼@2:如果當前不是leader節點,則直接返回,主要是為了二次判斷。
程式碼@3:重置心跳包傳送計時器。
程式碼@4:向叢集內的所有節點發送心跳包,稍後會詳細介紹心跳包的傳送。
2.3.3 maintainAsFollower方法
當 Candidate 狀態的節點在收到主節點發送的心跳包後,會將狀態變更為follower,那我們先來看一下在follower狀態下,節點會做些什麼事情?
private void maintainAsFollower() {
if (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > 2 * heartBeatTimeIntervalMs) {
synchronized (memberState) {
if (memberState.isFollower() && (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > maxHeartBeatLeak * heartBeatTimeIntervalMs)) {
logger.info("[{}][HeartBeatTimeOut] lastLeaderHeartBeatTime: {} heartBeatTimeIntervalMs: {} lastLeader={}", memberState.getSelfId(), new Timestamp(lastLeaderHeartBeatTime), heartBeatTimeIntervalMs, memberState.getLeaderId());
changeRoleToCandidate(memberState.currTerm());
}
}
}
}如果maxHeartBeatLeak (預設為3)個心跳包週期內未收到心跳,則將狀態變更為Candidate。
狀態機的驅動就介紹到這裡,在上面的流程中,其實我們忽略了兩個重要的過程,一個是發起投票請求與投票請求響應、傳送心跳包與心跳包響應,那我們接下來將重點介紹這兩個過程。
2.4 投票與投票請求
節點的狀態為 Candidate 時會向叢集內的其他節點發起投票請求(個人覺得理解為拉票更好),向對方詢問是否願意選舉我為Leader,對端節點會根據自己的情況對其投贊成票、拒絕票,如果是拒絕票,還會給出拒絕原因,具體由voteForQuorumResponses、handleVote 這兩個方法來實現,接下來我們分別對這兩個方法進行詳細分析。
2.4.1 voteForQuorumResponses
發起投票請求。
private List<CompletableFuture<VoteResponse>> voteForQuorumResponses(long term, long ledgerEndTerm,
long ledgerEndIndex) throws Exception { // @1
List<CompletableFuture<VoteResponse>> responses = new ArrayList<>();
for (String id : memberState.getPeerMap().keySet()) { // @2
VoteRequest voteRequest = new VoteRequest(); // @3 start
voteRequest.setGroup(memberState.getGroup());
voteRequest.setLedgerEndIndex(ledgerEndIndex);
voteRequest.setLedgerEndTerm(ledgerEndTerm);
voteRequest.setLeaderId(memberState.getSelfId());
voteRequest.setTerm(term);
voteRequest.setRemoteId(id);
CompletableFuture<VoteResponse> voteResponse; // @3 end
if (memberState.getSelfId().equals(id)) { // @4
voteResponse = handleVote(voteRequest, true);
} else {
//async
voteResponse = dLedgerRpcService.vote(voteRequest); // @5
}
responses.add(voteResponse);
}
return responses;
}程式碼@1:首先先解釋一下引數的含義:
- long term
發起投票的節點當前的投票輪次。 - long ledgerEndTerm
發起投票節點維護的已知的最大投票輪次。 - long ledgerEndIndex
發起投票節點維護的已知的最大日誌條目索引。
程式碼@2:遍歷叢集內的節點集合,準備非同步發起投票請求。這個集合在啟動的時候指定,不能修改。
程式碼@3:構建投票請求。
程式碼@4:如果是傳送給自己的,則直接呼叫handleVote進行投票請求響應,如果是傳送給叢集內的其他節點,則通過網路傳送投票請求,對端節點呼叫各自的handleVote對叢集進行響應。
接下來重點關注 handleVote 方法,重點探討其投票處理邏輯。
2.4.2 handleVote 方法
由於handleVote 方法會併發被呼叫,因為可能同時收到多個節點的投票請求,故本方法都被synchronized方法包含,鎖定的物件為狀態機 memberState 物件。
if (!memberState.isPeerMember(request.getLeaderId())) {
logger.warn("[BUG] [HandleVote] remoteId={} is an unknown member", request.getLeaderId());
return CompletableFuture.completedFuture(newVoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNKNOWN_LEADER));
}
if (!self && memberState.getSelfId().equals(request.getLeaderId())) {
logger.warn("[BUG] [HandleVote] selfId={} but remoteId={}", memberState.getSelfId(), request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNEXPECTED_LEADER));
}Step1:為了邏輯的完整性對其請求進行檢驗,除非有BUG存在,否則是不會出現上述問題的。
if (request.getTerm() < memberState.currTerm()) { // @1
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_VOTE_TERM));
} else if (request.getTerm() == memberState.currTerm()) { // @2
if (memberState.currVoteFor() == null) {
//let it go
} else if (memberState.currVoteFor().equals(request.getLeaderId())) {
//repeat just let it go
} else {
if (memberState.getLeaderId() != null) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY__HAS_LEADER));
} else {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_VOTED));
}
}
} else { // @3
//stepped down by larger term
changeRoleToCandidate(request.getTerm());
needIncreaseTermImmediately = true;
//only can handleVote when the term is consistent
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_NOT_READY));
}Step2:判斷髮起節點、響應節點維護的team進行投票“仲裁”,分如下3種情況討論:
- 如果發起投票節點的 term 小於當前節點的 term
此種情況下投拒絕票,也就是說在 raft 協議的世界中,誰的 term 越大,越有話語權。 - 如果發起投票節點的 term 等於當前節點的 term
如果兩者的 term 相等,說明兩者都處在同一個投票輪次中,地位平等,接下來看該節點是否已經投過票。- 如果未投票、或已投票給請求節點,則繼續後面的邏輯(請看step3)。
- 如果該節點已存在的Leader節點,則拒絕並告知已存在Leader節點。
- 如果該節點還未有Leader節點,但已經投了其他節點的票,則拒絕請求節點,並告知已投票。
- 如果發起投票節點的 term 大於當前節點的 term
拒絕請求節點的投票請求,並告知自身還未準備投票,自身會使用請求節點的投票輪次立即進入到Candidate狀態。
if (request.getLedgerEndTerm() < memberState.getLedgerEndTerm()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_LEDGER_TERM));
} else if (request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && request.getLedgerEndIndex() < memberState.getLedgerEndIndex()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_SMALL_LEDGER_END_INDEX));
}
if (request.getTerm() < memberState.getLedgerEndTerm()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.getLedgerEndTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_SMALL_THAN_LEDGER));
}Step3:判斷請求節點的 ledgerEndTerm 與當前節點的 ledgerEndTerm,這裡主要是判斷日誌的複製進度。
- 如果請求節點的 ledgerEndTerm 小於當前節點的 ledgerEndTerm 則拒絕,其原因是請求節點的日誌複製進度比當前節點低,這種情況是不能成為主節點的。
- 如果 ledgerEndTerm 相等,但是 ledgerEndIndex 比當前節點小,則拒絕,原因與上一條相同。
- 如果請求的 term 小於 ledgerEndTerm 以同樣的理由拒絕。
memberState.setCurrVoteFor(request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.ACCEPT));Step4:經過層層條件帥選,將寶貴的贊成票投給請求節點。
經過幾輪投票,最終一個節點能成功被推舉出來,選為主節點。主節點為了維持其領導地位,需要定時向從節點發送心跳包,接下來我們重點看一下心跳包的傳送與響應。
2.5 心跳包與心跳包響應
2.5.1 sendHeartbeats
Step1:遍歷叢集中的節點,非同步傳送心跳包。
CompletableFuture<HeartBeatResponse> future = dLedgerRpcService.heartBeat(heartBeatRequest);
future.whenComplete((HeartBeatResponse x, Throwable ex) -> {
try {
if (ex != null) {
throw ex;
}
switch (DLedgerResponseCode.valueOf(x.getCode())) {
case SUCCESS:
succNum.incrementAndGet();
break;
case EXPIRED_TERM:
maxTerm.set(x.getTerm());
break;
case INCONSISTENT_LEADER:
inconsistLeader.compareAndSet(false, true);
break;
case TERM_NOT_READY:
notReadyNum.incrementAndGet();
break;
default:
break;
}
if (memberState.isQuorum(succNum.get())
|| memberState.isQuorum(succNum.get() + notReadyNum.get())) {
beatLatch.countDown();
}
} catch (Throwable t) {
logger.error("Parse heartbeat response failed", t);
} finally {
allNum.incrementAndGet();
if (allNum.get() == memberState.peerSize()) {
beatLatch.countDown();
}
}
});
}Step2:統計心跳包傳送響應結果,關鍵點如下:
- SUCCESS
心跳包成功響應。 - EXPIRED_TERM
主節點的投票 term 小於從節點的投票輪次。 - INCONSISTENT_LEADER
從節點已經有了新的主節點。 - TERM_NOT_READY
從節點未準備好。
這些響應值,我們在處理心跳包時重點探討。
beatLatch.await(heartBeatTimeIntervalMs, TimeUnit.MILLISECONDS);
if (memberState.isQuorum(succNum.get())) { // @1
lastSuccHeartBeatTime = System.currentTimeMillis();
} else {
logger.info("[{}] Parse heartbeat responses in cost={} term={} allNum={} succNum={} notReadyNum={} inconsistLeader={} maxTerm={} peerSize={} lastSuccHeartBeatTime={}",
memberState.getSelfId(), DLedgerUtils.elapsed(startHeartbeatTimeMs), term, allNum.get(), succNum.get(), notReadyNum.get(), inconsistLeader.get(), maxTerm.get(), memberState.peerSize(), new Timestamp(lastSuccHeartBeatTime));
if (memberState.isQuorum(succNum.get() + notReadyNum.get())) { // @2
lastSendHeartBeatTime = -1;
} else if (maxTerm.get() > term) { // @3
changeRoleToCandidate(maxTerm.get());
} else if (inconsistLeader.get()) { // @4
changeRoleToCandidate(term);
} else if (DLedgerUtils.elapsed(lastSuccHeartBeatTime) > maxHeartBeatLeak * heartBeatTimeIntervalMs) {
changeRoleToCandidate(term);
}
}對收集的響應結果做仲裁,其實現關鍵點:
- 如果成功的票數大於進群內的半數,則表示叢集狀態正常,正常按照心跳包間隔傳送心跳包(見程式碼@1)。
- 如果成功的票數加上未準備的投票的節點數量超過叢集內的半數,則立即傳送心跳包(見程式碼@2)。
- 如果從節點的投票輪次比主節點的大,則使用從節點的投票輪次,或從節點已經有了另外的主節點,節點狀態從 Leader 轉換為 Candidate。
接下來我們重點看一下心跳包的處理邏輯。
2.5.2 handleHeartBeat
if (request.getTerm() < memberState.currTerm()) {
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode()));
} else if (request.getTerm() == memberState.currTerm()) {
if (request.getLeaderId().equals(memberState.getLeaderId())) {
lastLeaderHeartBeatTime = System.currentTimeMillis();
return CompletableFuture.completedFuture(new HeartBeatResponse());
}
}Step1:如果主節點的 term 小於 從節點的term,傳送反饋給主節點,告知主節點的 term 已過時;如果投票輪次相同,並且傳送心跳包的節點是該節點的主節點,則返回成功。
下面重點討論主節點的 term 大於從節點的情況。
synchronized (memberState) {
if (request.getTerm() < memberState.currTerm()) { // @1
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode()));
} else if (request.getTerm() == memberState.currTerm()) { // @2
if (memberState.getLeaderId() == null) {
changeRoleToFollower(request.getTerm(), request.getLeaderId());
return CompletableFuture.completedFuture(new HeartBeatResponse());
} else if (request.getLeaderId().equals(memberState.getLeaderId())) {
lastLeaderHeartBeatTime = System.currentTimeMillis();
return CompletableFuture.completedFuture(new HeartBeatResponse());
} else {
//this should not happen, but if happened
logger.error("[{}][BUG] currTerm {} has leader {}, but received leader {}", memberState.getSelfId(), memberState.currTerm(), memberState.getLeaderId(), request.getLeaderId());
return CompletableFuture.completedFuture(new HeartBeatResponse().code(DLedgerResponseCode.INCONSISTENT_LEADER.getCode()));
}
} else {
//To make it simple, for larger term, do not change to follower immediately
//first change to candidate, and notify the state-maintainer thread
changeRoleToCandidate(request.getTerm());
needIncreaseTermImmediately = true;
//TOOD notify
return CompletableFuture.completedFuture(new HeartBeatResponse().code(DLedgerResponseCode.TERM_NOT_READY.getCode()));
}
}Step2:加鎖來處理(這裡更多的是從節點第一次收到主節點的心跳包)
程式碼@1:如果主節的投票輪次小於當前投票輪次,則返回主節點投票輪次過期。
程式碼@2:如果投票輪次相同。
- 如果當前節點的主節點欄位為空,則使用主節點的ID,並返回成功。
- 如果當前節點的主節點就是傳送心跳包的節點,則更新上一次收到心跳包的時間戳,並返回成功。
- 如果從節點的主節點與傳送心跳包的節點ID不同,說明有另外一個Leaer,按道理來說是不會發送的,如果發生,則返回已存在- 主節點,標記該心跳包處理結束。
程式碼@3:如果主節點的投票輪次大於從節點的投票輪次,則認為從節點併為準備好,則從節點進入Candidate 狀態,並立即發起一次投票。
心跳包的處理就介紹到這裡。
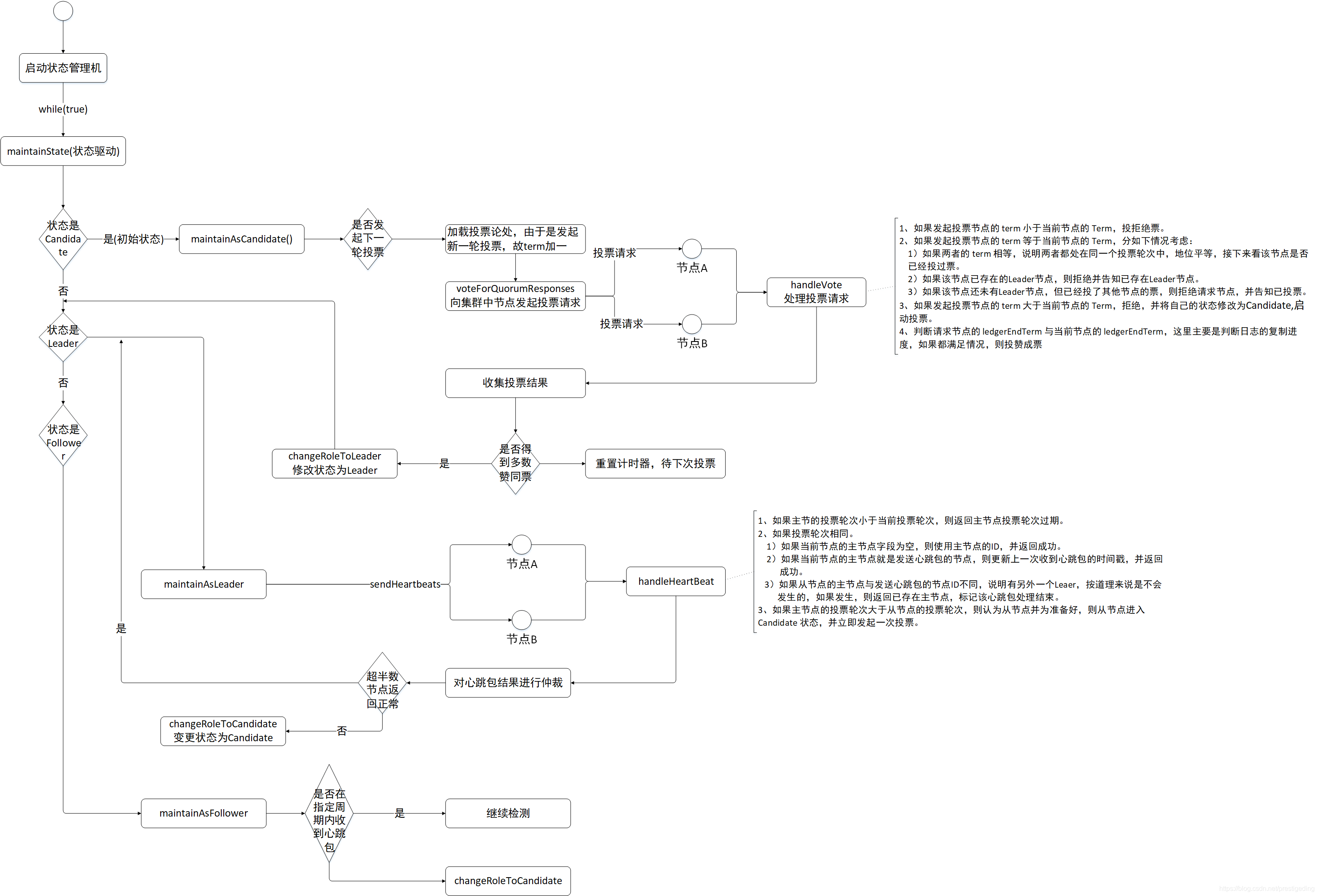
RocketMQ 多副本之 Leader 選舉的原始碼分析就介紹到這裡了,為了加強對原始碼的理解,先梳理流程圖如下:
本文就介紹到這裡了,如果對您有一定的幫助,麻煩幫忙點個贊,謝謝。
作者介紹:丁威,《RocketMQ技術內幕》作者,RocketMQ 社群佈道師,公眾號:中介軟體興趣圈 維護者,目前已陸續發表原始碼分析Java集合、Java 併發包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等原始碼專欄。可以點選連結加入中介軟體知識星球 ,一起探討高併發、分散式服務架構,交流原始碼。
相關推薦
原始碼分析 RocketMQ DLedger 多副本之 Leader 選主
目錄 1、DLedger關於選主的核心類圖 1.1 DLedgerConfig 1.2 MemberState 1.3 raft協議相關 1.4 DLedgerRpcService
原始碼分析 RocketMQ DLedger(多副本) 之日誌複製(傳播)
目錄 1、DLedgerEntryPusher 1.1 核心類圖 1.2 構造方法 1.3 startup 2、EntryDispatcher 詳解 2.1
基於 raft 協議的 RocketMQ DLedger 多副本日誌複製設計原理
目錄 1、RocketMQ DLedger 多副本日誌複製流程圖 1.1 RocketMQ DLedger 日誌轉發(append) 請求流程圖 1.2 RocketMQ DLedger 日誌仲裁流程圖 1.
原始碼分析RocketMQ之訊息ACK機制(消費進度)
首先簡要闡述一下訊息消費進度首先消費者訂閱訊息消費佇列(MessageQueue),當生產者將訊息負載傳送到MessageQueue中時,消費訂閱者開始消費訊息,訊息消費過程中,為了避免重複消費,需要一
原始碼分析RocketMQ之訊息消費
1、訊息消費關注點 1)訊息消費方式:拉取、推送 2)消費者組與消費模式 consumerGroup; MessageModel messageModel; 多個消費者組成一個消費組,兩種模式:叢集(訊息被其中任何一個訊息者消費)、廣播模式(全部消費者消費
RocketMQ 整合 DLedger(多副本)即主從切換實現平滑升級的設計技巧
目錄 1、閱讀原始碼之前的思考 2、從 Broker 啟動流程看 DLedger 2.1 構建 DefaultMessageStore 2.2 增加節點狀態變更事件監聽器 2.3 呼叫 Def
【kubernetes/k8s原始碼分析】 client-go包之Informer原始碼分析
Informer 簡介 Informer 是 Client-go 中的一個核心工具包。如果 Kubernetes 的某個元件,需要 List/Get Kubernetes 中的 Object(包括pod,service等等),可以直接使用
Spring-Cloud-Gateway原始碼分析系列 | Spring-Cloud-Gateway之GatewayProperties初始化載入
推薦 Spring Boot/Cloud 視訊: 在Spring-Cloud-Gateway初始化時我們在GatewayAutoConfiguration配置中看到了有初始化載入GatewayProperties例項的配置,接下來學習下GatewayPrope
[Abp 原始碼分析]十三、多語言(本地化)處理
0.簡介 如果你所開發的需要走向世界的話,那麼肯定需要針對每一個使用者進行不同的本地化處理,有可能你的客戶在日本,需要使用日語作為顯示文字,也有可能你的客戶在美國,需要使用英語作為顯示文字。如果你還是一樣的寫死錯誤資訊,或者描述資訊,那麼就無法做到多語言適配。 Abp 框架本身提供了一套多語言機制來幫助我們實
《Java 原始碼分析》:Java NIO 之 Selector(第一部分Selector.open())
《Java 原始碼分析》 :Java NIO 之 Selector(第一部分Selector.open()) 關於Selector類主要涉及兩個重要的方法,如下: 1、Selector.open() 2、select() 由於篇幅限制,這篇主要從
spring4.2.9 java專案環境下ioc原始碼分析(四)——refresh之obtainFreshBeanFactory方法(@2處理Resource、載入Document及解析前準備)
接上篇文章,上篇文章講到載入完返回Rescouce。先找到要解析的程式碼位置,在AbstractBeanDefinitionReader類的loadBeanDefinitions(String location, Set<Resource> actualResou
【kubernetes/k8s原始碼分析】kubectl-controller-manager之job原始碼分析
job介紹 Job: 批量一次性任務,並保證處理的一個或者多個Pod成功結束 非並行Job: 固定完成次數的並行Job: 帶有工作佇列的並行Job: SPEC引數 .spec.completions:
【kubernetes/k8s原始碼分析】kubectl-controller-manager之cronjob原始碼分析
crontab的基本格式 支援 , - * / 四個字元 *:表示匹配任意值,如果在Minutes 中使用表示每分鐘 &
【kubernetes/k8s原始碼分析】kubectl-controller-manager之HPA原始碼分析
本文基於kubernetes版本:v1.12.1 HPA介紹 https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/ Th
【kubernetes/k8s原始碼分析】kubectl-controller-manager之pod gc原始碼分析
引數: --controllers strings:配置需要enable的列表 這裡也包括podgc All con
spring4.2.9 java專案環境下ioc原始碼分析(六)——refresh之obtainFreshBeanFactory方法(@4預設標籤bean,beans解析、最終註冊)
接上篇文章,解析了import和alias標籤,只是開胃菜比較簡單,下面介紹bean標籤的載入,也是預設名稱空間下解析的重點。protected void processBeanDefinition(Element ele, BeanDefinitionParserDeleg
spring4.2.9 java專案環境下ioc原始碼分析(五)——refresh之obtainFreshBeanFactory方法(@3預設標籤import,alias解析)
接上篇文章,到了具體解析的時候了,具體的分為兩種情況,一種是預設名稱空間的標籤<bean>;另一種是自定義名稱空間的標籤比如<context:xxx>,<tx:xxx>等。先看下預設的名稱空間的標籤解析。protected void par
spring4.2.9 java專案環境下ioc原始碼分析 (十四)——refresh之onRefresh方法
這個方法是空的。解釋是在特定的上下文中初始化特別的beans。可以看到其也是用於初始化的。看了StaticWebApplicationContext、AbstractRefreshableWebApplicationContext、GenericWebApplicationC
spring4.2.9 java專案環境下ioc原始碼分析(三)——refresh之obtainFreshBeanFactory方法(@1準備工作與載入Resource)
obtainFreshBeanFactory方法從字面的意思看獲取新的Bean工廠,實際上這是一個過程,一個載入Xml資源並解析,根據解析結果組裝BeanDefinitions,然後初始化BeanFactory的過程。在載入Xml檔案之前,spring還做了一些其他的工作,比
七.linux開發之uboot移植(七)——uboot原始碼分析2-啟動第二階段之start_armboot函式分析1
一.uboot啟動第二階段之start_armboot函式簡介 1.start_armboot函式簡介 (1)這個函式在uboot/lib_arm/board.c的第444行開始到908行結束。 (2)、即一個函式組成uboot第二階段 2、