
netty的執行緒模型, 調優 及 獻上寫過註釋的原始碼工程
Netty能幹什麼?
Http伺服器
使用Netty可以編寫一個 Http伺服器, 就像tomcat那樣,能接受使用者傳送的http請求, , 只不過沒有實現Servelt規範, 但是它也能解析攜帶的引數, 對請求的路徑進行路由導航, 從而實現將不同的請求導向不同的handler進行處理
對socket與RPC的支援
Netty可是實現的第二件事就是Socket程式設計,也是它最為廣泛的應用領域
進行微服務開發時不可丟棄的一個點, 服務和服務之間如果使用Http通訊不是不行,但是http的底層使用的也是socket, 相對我們直接使用netty加持socket效果會更好 (比如阿里的Dubbo)
當然Netty能做的事還有很多比如自定義通訊協議等等,,,
對WebSocket的支援
Netty對WebSocket也提供了強大的支援, netty內建的處理器會為我們做好大量的機械性麻煩性的工作, 如WebSocketServerProtocolHandler內建編解碼處理, 心跳檢驗等, 可以讓我們專注於實現自己的業務邏輯
Reactor執行緒模型
Reactor執行緒模型, 顧名思義就像核反應堆一樣, 是一種很勁爆的執行緒模型
最經典的兩種圖就像下面這樣
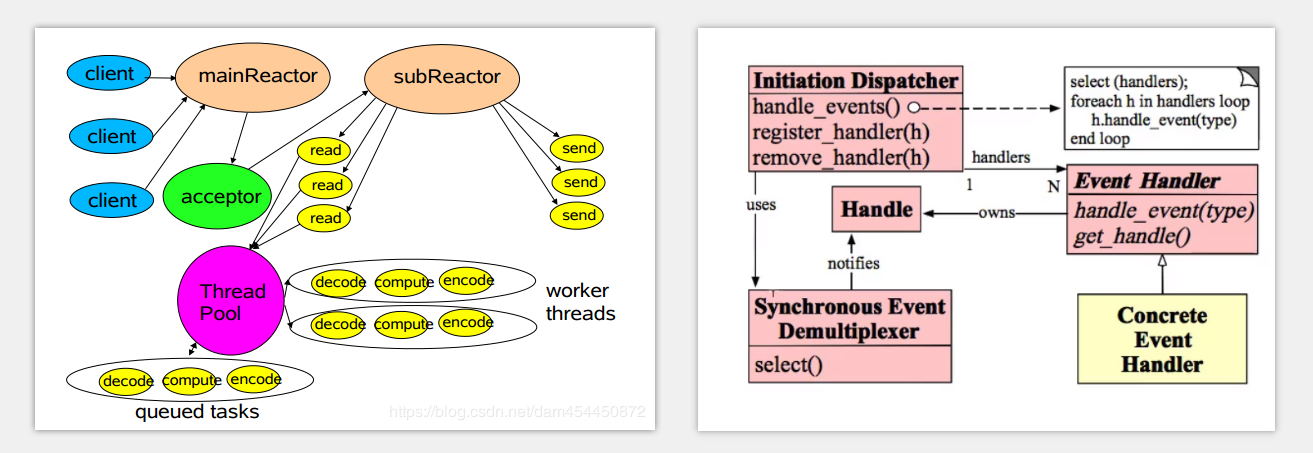
上面兩種圖所描述的都是Reactor執行緒模型
Reactor執行緒模型五大角色
- handle
handle本質上表示是一種資源 , 在不同的作業系統上他們的名稱又不一樣, 比如在windows上成它為檔案控制代碼 , 而在linux中稱它為檔案描述符, 其實我這樣說, handle的概念就顯得比較抽象 不容易理解 , 具體一點說handle是啥呢 ? 比如客戶端向服務端傳送一個連線請求,這個socket請求對作業系統來說, 本質上就是handle
在Reactor執行緒模型中的Handle 就是限制netty併發量的主要原因, 下面的調優主要也是為了突破這個限制
- Synchronius Event Demultiplexer
意為同步事件分離器, 也是一看這個名字完全沒有頭緒它是什麼, 其實, 在本質上它是一個作業系統層面的系統呼叫, 作業系統用它來阻塞的等待事件的發生, 具體一點它來說, 比如它可以是Linux系統上的IO多路複用, select(), 或者是 poll(),epoll() , 或者是Nio程式設計模型中的selector, 總之, 它的特點就是阻塞的等待事件的發生
- EventHandler
事件處理器, 事件處理器是擁有Handle的, 我們可以直觀將將EventHandler理解成是當系統中發生了某個事件後, 針對這個事件進行處理的回撥, 為啥說是回撥, 結合netty的實現中, 我們在啟動netty前, 會往他的pipeline中新增大量的handler ,這些handler的地位其實和 EventHandler的地位相當
- concrete EventHandler
顧明思議, 具體的事件處理器的實現, 換句話說, 這是我們根據自己的需求, 不同的業務邏輯自己去新增上去的處理器
- InitiationDispacher
初始分發器, 它其實就是整個程式設計模型的核心, 沒錯, 他就是Reactor, 具體怎麼理解這個Reactor , 比如我們就能把他看成一個規範, 由它聚合, 支配其他的四大角色之間有條不紊的工作, 迸發出巨大的能量
Reactor執行緒模型五大角色的關係與工作流程
首先: 我們需要將 EventHandler註冊進 Reactor, 通過上圖也能看到, EventHandler 擁有 作業系統底層的 Handle,
並且, Reactor 要求, 當EventHandler 註冊進自己時, 務必將他關聯的handle一併告訴自己, 由Reactor統一進行維護
我們將上面所說的handle , 聯想成Nio程式設計模型中的將channel註冊進Selector時刻意,也是必須繫結上的這個感性趣的事件, 牢記, Reactor是的這個模型的核心, 待會操作一旦系統發現handle有了某些變動,需要由Reactor去通知具體哪個EventHandler來處理這個資源. 如何找到正確的EventHandler依賴的就是這個handle , 或者說它是感興趣的事件
更近一步: 當所有的EventHandler都註冊進了Reactor中後, Reactor就開始了它放縱的一生, 於是它開始調與 同步事件分離器通訊 ,企圖等待一些事件的發生, 什麼事件呢? 比如說 socket的連線事件
當同步事件分離器發現了某個handle的狀態發生了改變, 比如它的狀態變成了ready, 就說明這個handle中發生了感興趣的事件, 這時, 同步事件分離器會將這個handle的情況告訴Reactor , Reactor進一步用這個handle當成key, 獲取出相對應的 EventHandler 開始方法的回撥...
如何實現單機百萬效能調優
當我們進行socket程式設計時, 我們得給Server端繫結上一個埠號, 客戶端一般會被自動分配Server所在的機器上的一個埠號, 區間一般是1025-65535之間, 這樣看上去, 即使伺服器的效能再強, 即使netty再快, 併發數目都被作業系統的特性限制的死死的
突破區域性檔案控制代碼的限制
像 windows中的控制代碼或者是linux的檔案描述符 這種能開啟的資源的數量是有限的, 每一個socket連線都是一個控制代碼或者是描述符, 換句話說, 這一個特性限制了socket連線數, 也就限制了併發數
檢視linux系統中一個程序能開啟的單個檔案數,(它限制了單個jvm能開啟的檔案描述符數,每一個tcp連線對linux來說都是一個檔案)
ulimit -n修改這個限制:
# 在 /etc/security/limits.conf 追加以下內容 , 表示任何使用者的連結最多都能開啟100萬個檔案
* hard nofile 100000
* soft nofile 100000重啟機器生效:
突破全域性檔案控制代碼的限制
檢視當前系統中的全域性檔案控制代碼數
cat /proc/sys/fs/file-max修改這個配置
# 在 /etc/sysctl.conf 中追加如下的內容
fs.file-max = 1000000虛擬機器引數的經驗值
# 堆記憶體
-Xms6.5g -Xmx6.5g
# 新生代的記憶體
-XX:NewSize=5.5g -XXMaxNewSize=5.5g
# 對外記憶體
-XX: MaxDirectMemorySize=1g應用級別的效能調優
問題:
Netty基於Reactor這種執行緒模型的, 進行非阻塞式程式設計, 一般我們在編寫服務端的程式碼時, 都會在 往 服務端的Channel pipeline上新增大量的 入站出站處理器, 客戶端的訊息一般我們都是在 handler中的 ChannelRead() 或者是 ChannelRead0() 中取出來, 再和後臺的業務邏輯結合
客戶端的訊息,會從Pipeline這個雙向連結串列中的header中開始往後傳播, 一直到tail, 這其實是個責任鏈
這時, 如果我們將耗時的操作放在這些處理器中, 毫無疑問, nettey會被拖垮, 系統的併發量也提升不上去
解決方式一:
新開闢一個執行緒池 , 將耗時的業務邏輯放到新開闢的業務去執行
public class MyThreadPoolHandler extends SimpleChannelInboundHandler<String> {
private static ExecutorService threadPool = Executors.newFixedThreadPool(20);
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
threadPool.submit(() -> {
Object result = searchFromMysql(msg);
ctx.writeAndFlush(ctx);
});
}
public Object searchFromMysql(String msg) {
Object obj = null;
// todo obj =
return obj;
}
}解決方式二:
netty 提供的一種原生的解決方式, netty可以將我們的handler 放到一個專門的執行緒池中去處理
public class MyInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 業務執行緒池
NioEventLoopGroup eventLoopGroup = new NioEventLoopGroup(20);
// 使用這個過載的方法,給handler指定執行緒池去執行
pipeline.addLast(eventLoopGroup,new MyHandler());
}
}Netty帶給我的收穫
能立即成為Netty的領域的大佬嗎?
No!
讀過Netty的程式碼,真的並不意味著即刻成為一個netty領域的大佬,相反讀的我發慌, 這麼龐大的知識體系, 得用多久去慢慢消化, 我們看到的大佬要麼是天才, 要麼是在自己多年的使用經驗裡面歷練出來的, 想在netty這個領域有所建樹,真的是需要不斷是去實踐,真的得用多年的工作經驗去總結才行!也許這樣才可能發自內心的感觸到netty為什麼要這麼實現, 如果想著立即多厲害, 也許是做夢了...
真的熟練掌握了Netty嗎?
No!
讀過netty, 也並不是意味著可以瞭解netty整個領域的方方面面, 以及如何恰當的使用netty去解決我們的業務需求, 站在一個學生的角度來看, 這一點我心裡感覺的特別深刻, 同樣的東西,比如同一個ArrayList, 大家都在用, 但是對它的掌握程度的差距甚至能達到使人瞠目結舌的地步, 不得不承認, 技術是需要時間去積累, 需要時間去消化的東西,就像塵封的酒,越釀越香
有什麼收穫?
當然,讀原始碼也不是沒有用,起碼對netty框架整體的架構不是那麼是陌生了,當自己遇到bug時,也敢於點開原始碼去找原因了,這應該是我最大的收穫
獻上註解過的Netty原始碼工程
當時我在學netty時, 是從github上拉取的netty原生工程, 然後在本地重新編譯執行, 這樣我就能在原始碼工程中寫註解, 記筆記...
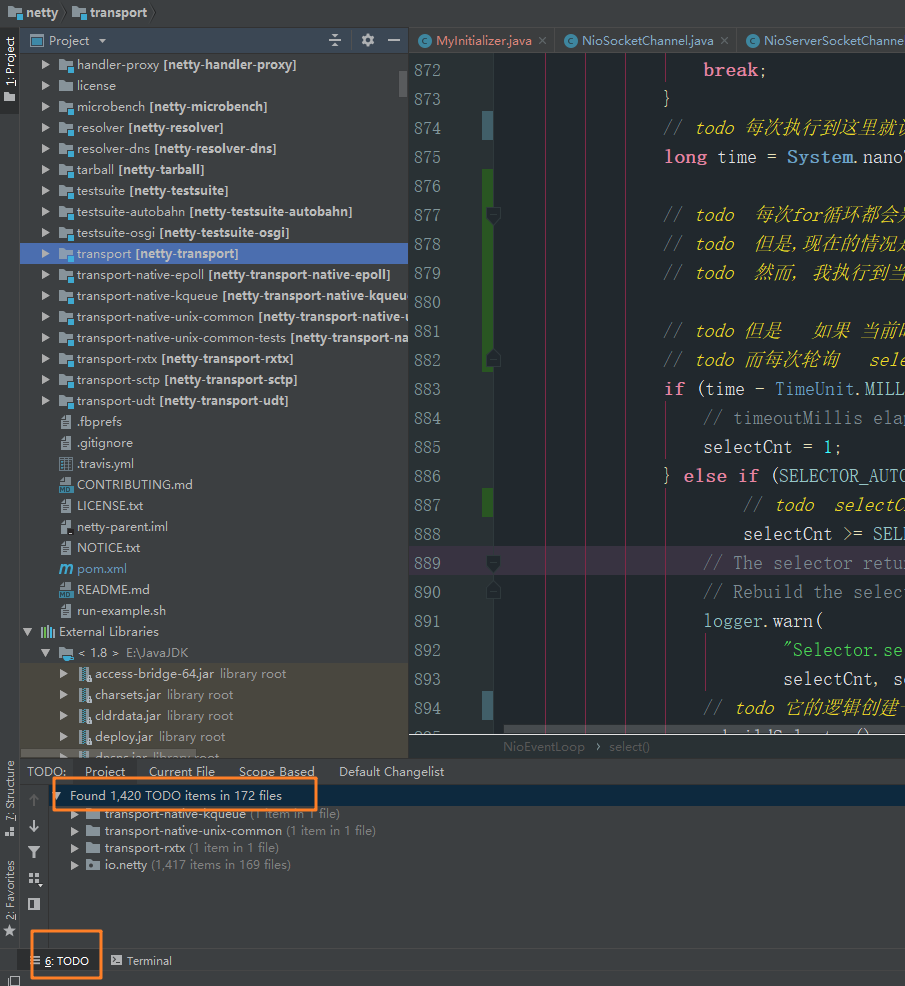
在這個工程裡面大概寫了 1400 多行註釋(所有的筆記都打上了todo 高亮標記) , 也翻譯了一些類和方法上的文件和註釋, 不能說百分百正確, 但是這個過程也是挺走心的, 比如netty是如何解決JDK空輪詢的bug的? 這些在程式碼中都是有跡可循的,如下
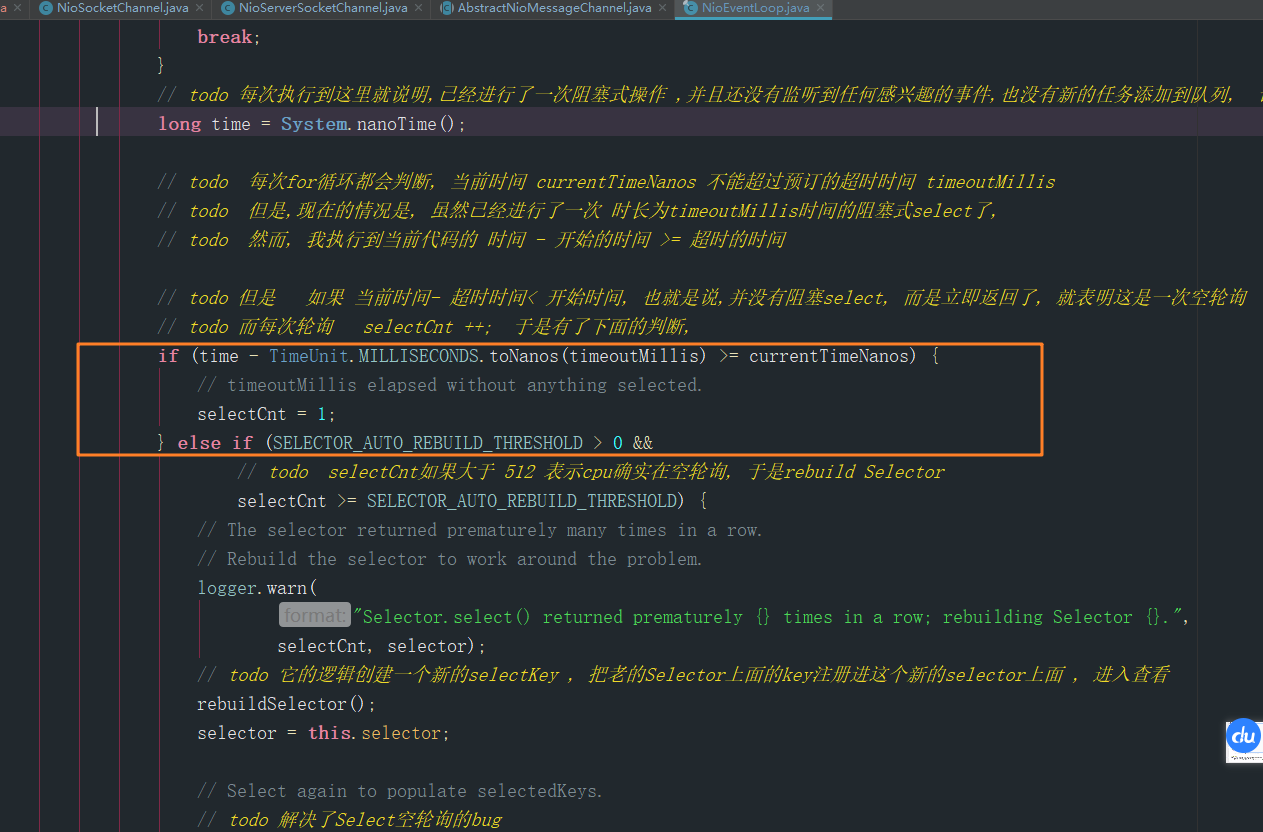
另外一個學習的感觸就是忘東西, 還有就是隨著時間的推移, 接觸到技術會越來越多, 確實很難在同一個時間將學的所有的技術都提升到最高的熟練程度, 好處也有, 可能原來學用了一個星期, 現在重新看只要1天就夠了
github地址: https://github.com/zhuchangwu/netty-project
我更推薦你也這樣自己編譯一個使用,學習netty是一個漫長的過程, 如果你也有一腔熱血 , 可以聯絡我哦...
致敬真神: Netty的創始人trustin lee 和 Netty的開發者們