
基於深度學習的影象分割在高德的實踐
一、前言
影象分割(Image Segmentation)是計算機視覺領域中的一項重要基礎技術,是影象理解中的重要一環。影象分割是將數字影象細分為多個影象子區域的過程,通過簡化或改變影象的表示形式,讓影象能夠更加容易被理解。更簡單地說,影象分割就是為數字影象中的每一個畫素附加標籤,使得具有相同標籤的畫素具有某種共同的視覺特性。
影象分割技術自 60 年代數字影象處理誕生開始便有了研究,隨著近年來深度學習研究的逐步深入,影象分割技術也隨之有了巨大的發展。早期的影象分割演算法不能很好地分割一些具有抽象語義的目標,比如文字、動物、行人、車輛。這是因為早期的影象分割演算法基於簡單的畫素值或一些低層的特徵,如邊緣、紋理等,人工設計的一些描述很難準確描述這些語義,這一經典問題被稱之為“語義鴻溝”。
得益於深度學習能夠“自動學習特徵”的這一特點,第三代影象分割很好地避免了人工設計特徵帶來的“語義鴻溝”,從最初只能基於畫素值以及低層特徵進行分割,到現在能夠完成一些根據高層語義的分割需求。
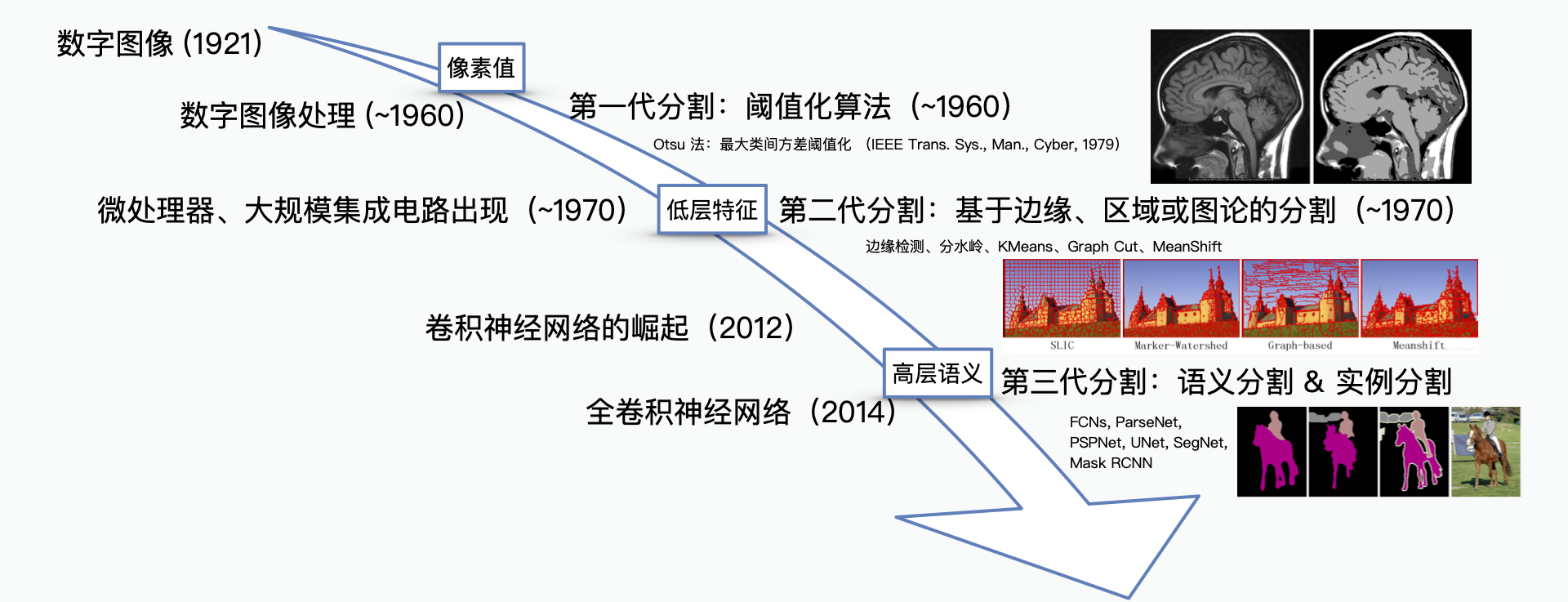
(影象分割的發展歷史)
高德地圖擁有影象/視訊大資料,在眾多業務場景上都需要理解影象中的內容。例如,在資料的自動化生產中,通常需要尋找文字、路面、房屋、橋樑、指示牌、路面標線等目標。這些資料裡有些是通過採集車輛或衛星拍攝,也有些資料則是通過使用者手機拍攝,如下圖所示:

面對這些場景語義複雜、內容差異巨大的影象,高德是如何通過影象分割對其進行理解的?本文介紹了影象分割在高德地圖從解決一些小問題的“手段”,逐步成長為高度自動化資料生產線的強大技術助力。
二、探索期:一些早期的嘗試
在街邊的資料採集中,我們需要自動化生產出採集到的小區、店鋪等 POI (Point of Interest)資料。我們通過 OCR 演算法識別其中文字,但苦惱於無法確定採集影象中到底有幾個 POI。例如,下圖中“領秀麗人”與“燕子童裝”兩家店鋪,人眼可以很容易區分,但是對於機器則不然。一些簡單的策略,比如背景顏色,容易帶來很多的錯誤。

例如,遇到兩個樣式十分相近的掛牌的時候,我們利用無監督的 gPb-owt-ucm 演算法 [1] 在檢測多級輪廓的基礎上結合改進的分水嶺演算法將影象切分為多個區域,並利用 Cascade Boosting 的文字檢測結果將圖中帶有文字的區域進行了分割。
三、成長期:自然場景下的語義分割
於 2014 年底問世的全卷積神經網路 [2](FCNs, Fully Convolutional Networks)無疑是繼 2012 年問鼎 ImageNet 大賽以來深度學習發展的又一里程碑。FCNs 提供了第一個端到端式的深度學習影象分割解決方案。FCNs 在 CNN 的基礎上可以從任意尺寸的輸入進行逐畫素的分類。我們也在第一時間將其落地到高德自身的應用場景中,例如文字區域的分割。自然場景下的文字由於其背景、光照複雜,文字朝向、字型多樣,使得人工構建特徵十分困難。
很快地,我們發現 FCNs 還並不能很好地滿足我們的需求。雖然 FCNs 在解決語義鴻溝問題上提供瞭解決方案,但在一般情況下只能給出一個“粗糙”的區域分割結果,不能實現很好的“例項分割”,對於目標虛警、目標粘連、目標多尺度、邊緣精度等問題上也沒有很好地解決。一個典型的例子就是在分割文字區域時,“捱得近”的文字區域特別容易粘在一起,導致在計算影象中的文字行數時造成計數錯誤。

因此,我們提出了一個多工網路來實現自己的例項分割框架。針對目標粘連的問題,我們在原始網路中追加了一個分割任務,其目標是分割出每個文字行的“中軸線”,然後通過中軸線區域來拆分粘連的文字行區域。拆分的方法則是一個類似於 Dijkstra 的演算法求解每個文字區域畫素到區域內中軸線的距離,並以最短距離的中軸線作為畫素歸屬。

另外一個比較困擾的問題是 FCNs 結果中的虛警,即非文字區域被分割為文字區域。雖然相較於一些傳統方法,FCNs 結果中的虛警已經少了很多,但為了達到更好的分割正確率,我們在原有網路基礎上增加了一個並行的 R-CNN 子網路進行文字的檢測,並利用這些檢測結果抑制虛警的產生(False Alarms Suppression)。
為了通過端到端的學習使得網路達到更好的效果,我們設計了一個一致性損失函式(Consistency Loss Function),來保證網路主幹下分割子網路和檢測子網路能夠相互指導、調優。從優化後分割網路輸出的能量圖可以看到,虛警的概率明顯降低了。若想要了解詳細細節,可以參考我們 17 年公佈在 arxiv 上的文章[3]。

四、成熟期:分割的精細化與例項化
得益於 Mask R-CNN 框架 [4] 的提出,例項化的影象分割變得更加容易。以之前提到的商戶掛牌的分割為例,掛牌區域的分割也十分容易出現粘連,且掛牌樣式多樣,不存在文字行這樣明顯的“中軸線”。目標檢測方法可以對提取掛牌的外包矩形。但問題在於,自然場景下掛牌的拍攝往往存在非垂直視角,因此在影象上並不是一個矩形,通常的檢測演算法則會帶來不準確的邊緣估計。Mask R-CNN 通過良好地整合檢測與分割兩個分支,實現了通用的例項化影象分割框架。其中目標檢測分支通過 RPN 提取目標區域,並對其進行分類實現目標的例項化;然後在這些目標區域中進行分割,從而提取出精準的邊緣。
一些更加複雜的場景理解需求,也對影象分割分割精細程度提出了更高的要求。這主要體現在兩個方面:(1)邊緣的準確度(2)不同尺度目標的召回能力。
在高精地圖的資料資料生產需要分割出影象中的路面,然而高精地圖對於精度的要求在釐米級,換算到影象上誤差僅在 1~2 個畫素點。觀察原始分割的結果不難發現,分割的不準確位置一般都是出現在區域邊緣上,區域內部是比較容易學習的。
因此,我們設計了一個特殊的損失函式,人為地增大真值邊緣區域產生的懲罰性誤差,從而加強對邊緣的學習效果,如圖所示,左側為可行駛路面區域分割,右側是路面及地面標線分割。

道路場景下需要理解的目標種類繁多,一方面其本身有大有小,另一方面由於拍攝的景深變化,呈現在影象上的尺度也大小各異。特別的是,有些特殊目標,例如燈杆、車道線等目標是“細長”的,在影象上具有較大長度,但寬度很小。這些目標的特性都使得精細的影象分割變得困難。

首先,由於受到網路感受野的限制,過大和過小的目標都不容易準確分割,比如道路場景下的路面與燈杆,衛星影像中的道路與建築群。針對該問題,目前的 PSPNet [5], DeepLab [6], FPN [7] 等網路結構都能在不同程度上解決。
其次,由於目標尺度不同,導致分割網路樣本數量的比例極不均衡(每一個畫素可以認為是一個樣本),我們將原先用於目標檢測任務的 Focal Loss [8] 遷移到影象分割網路中來。Focal Loss 的特點在於可以讓誤差集中在訓練的不好的資料上。這一特性使得難以學習的小尺度目標能夠被更加準確地分割出來。

五、未來的展望
影象分割技術目前朝著越來越精確的方向上發展,例如 Mask Scoring R-CNN [9]、Hybrid Task Cascade [10] 的提出,在 Mask R-CNN 的基礎上持續優化了其分割的精確程度。然而站在應用角度,基於深度學習的影象分割相較於當量的分類任務則顯得“笨重”。
出於影象分割任務對精度的要求,輸入影象不會像分類任務一樣被壓縮至一個很小的尺寸,帶來的則是計算量的指數級增加,使得影象分割任務的實時性較難保證。針對這個問題,ICNet, Mobile 等網路結構通過快速下采樣減少了卷積初期的計算量,但也帶來了效果上的折損。基於知識蒸餾(Knowledge Distillation)的訓練方法,則像個更好的優化方案,通過大網路指導小網路學習,使得小網路的訓練效果優於單獨訓練。知識蒸餾在訓練過程中規避了網路剪枝所需要的經驗與技巧,直接使用較低開銷的小網路完成原先只能大網路實現的複雜任務。
對於高德地圖來說,影象分割已經是一個不可或缺的基礎技術,並在各個資料自動化生產線中得到了廣泛應用,助力高德地圖的高度自動化資料生產。未來,我們也將持續在地圖應用場景下打造更加精準、輕量的影象分割技術方案。
六、參考文獻
[1] Arbelaez, Pablo, et al. "Contour detection and hierarchical image segmentation." IEEE transactions on pattern analysis and machine intelligence 33.5 (2010): 898-916.
[2] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[3] Jiang, Fan, Zhihui Hao, and Xinran Liu. "Deep scene text detection with connected component proposals." arXiv preprint arXiv:1708.05133 (2017).
[4] He, Kaiming, et al. "Mask r-cnn." Proceedings of the IEEE international conference on computer vision. 2017.
[5] Zhao, Hengshuang, et al. "Pyramid scene parsing network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[6] Chen, Liang-Chieh, et al. "Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs." IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 834-848.
[7] Lin, Tsung-Yi, et al. "Feature pyramid networks for object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[8] Lin, Tsung-Yi, et al. "Focal loss for dense object detection." Proceedings of the IEEE international conference on computer vision. 2017.
[9] Huang, Zhaojin, et al. "Mask scoring r-cnn." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[10] Chen, Kai, et al. "Hybrid task cascade for instance segmentation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.

相關推薦
深度學習 影象分割開原始碼(附連結,超級全)
轉自github,感謝作者mrgloom的整理 Awesome Semantic Segmentation Networks by architecture Semantic segmentation Instance aware segmentation
基於深度學習的影象分割在高德的實踐
一、前言 影象分割(Image Segmentation)是計算機視覺領域中的一項重要基礎技術,是影象理解中的重要一環。影象分割是將數字影象細分為多個影象子區域的過程,通過簡化或改變影象的表示形式,讓影象能夠更加容易被理解。更簡單地說,影象分割就是為數字影象中的每一個畫素附加標籤,使得具有相同標籤的畫素具有某
基於深度學習的影象語義分割技術概述之4常用方法 5.4未來研究方向
https://blog.csdn.net/u014593748/article/details/72794459 本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmen
基於深度學習和遷移學習的遙感影象場景分類實踐(AlexNet、ResNet)
卷積神經網路(CNN)在影象處理方面有很多出色的表現,在ImageNet上有很多成功的模型都是基於CNN的。AlexNet是具有歷史意義的一個網路,2012年提出來當年獲得了當年的ImageNet LSVRC比賽的冠軍,此後ImageNet LSVRC的冠軍都是都是用CNN做的,並且層
基於深度學習的影象語義分割演算法綜述(截止20180715)
這篇文章講述卷積神經網路在影象語義分割(semantic image segmentation)的應用。影象分割這項計算機視覺任務需要判定一張圖片中特定區域的所屬類別。 這個影象裡有什麼?它在影象中哪個位置? 更具體地說,影象語義分割的目標是將影象的每個畫素所
基於深度學習的影象分割總結
一、影象分割類別 隨著深度學習的發展,在分割任務中出現了許多優秀的網路。根據實際分割應用任務的不同,可以大致將分割分為三個研究方向:語義分割、例項分割、全景分割。這三種分割在某種意義上是具有一定的聯絡的。 語義分割: 畫素級別的語義分割,對影象中的每個畫素都劃分出對應的
基於深度學習的影象分割: Learning to Segment Object Candidates -- Facebook
轉載請表明:http://blog.csdn.net/ikerpeng/article/details/52453830內容概要:採用的是 兩步走的 Object detection的 深度學習框架,首先通過框架的第一部分的分支給出 目標 proposal; 然後 在prop
基於深度學習的影象分割和keras 的實現
影象分割 深度學習尤其是卷積神經網路在影象處理的許多領域都獲得了很大的成功,在分類,識別等方面都已經獲得了很大的成功.在深度學習把影象分類和識別達到極致之後。深度學習開始在影象分割方面開始進行收割了。影象分割的意思就是對於影象中每個畫素進行分類操作。
基於深度學習的影象語義分割演算法綜述
作者: 葉 虎 編輯:趙一帆 前 言本文翻譯
基於深度學習的影象語義分割技術概述之4常用方法
本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmentation:原文連結 4 深度學習影象分割的常用方法 深度學習在多種高階計算機視
基於深度學習的影象語義分割技術概述之背景與深度網路架構
本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmentation: 原文連結 摘要 影象語義分割正在逐漸成為計算機視覺及機器學習研究人員的研究熱點。大
基於深度學習的圖像語義分割技術概述之5.1度量標準
-s 公平性 的確 由於 表示 n-2 sub 包含 提升 本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmentation:原文鏈接 5.1度量標準 為何需
學習筆記之——基於深度學習的影象超解析度重構
最近開展影象超解析度( Image Super Resolution)方面的研究,做了一些列的調研,並結合本人的理解總結成本博文~(本博文僅用於本人的學習筆記,不做商業用途) 本博文涉及的paper已經打包,供各位看客下載哈~h
基於深度學習的影象檢索 image retrieval based on deep learning (code ,程式碼)
本次程式碼分享主要是用的caffe框架,至於caffe框架的安裝過程不再說明。程式碼修改自“cross weights”的一篇2016年的文章,但是名字忘記了,誰記得,提醒我下。 一、環境要求 1、python &nb
基於深度學習的影象質量排序
國內外各大網際網路公司(比如騰訊、阿里和Yelp)的線上廣告業務都在關注展示什麼樣的影象能吸引更多點選。在美團,商家的首圖是由商家或運營人工指定的,如何選擇首圖才能更好地吸引使用者呢?影象質量排序演算法目標就是做到自動選擇更優質的首圖,以吸引使用者點選。 傳統的影象質量排序方法主要從美學角度進行
基於深度學習的影象修復—心中無碼
一、前言 影象修復在應用上非常吸引人,通常設計師需要使用 Photoshop 根據影象周圍修復空缺部分。這一過程非常耗時和細緻,因此很早就有研究嘗試使用機器學習模型自動化這一過程。 這篇文章介紹了 DeepCreamPy 專案,它可以自動修復漫畫影象中的空缺部分和馬賽克。該專案使用部分卷
基於深度學習的CT影象肺結節自動檢測技術六—模型預測
#模型預測的相關功能 from chapter4 import get_unet from chapter5 import get_3dnnnet, stack_2dcube_to_3darray, prepare_image_for_net3D, MEAN_
基於深度學習的CT影象肺結節自動檢測技術五—3dcnn優化模型
import os import random from keras import layers from keras import backend as K from keras.layers import Input, Convolution3D, MaxP
基於深度學習的CT影象肺結節自動檢測技術一——資料預處理(歸一化,資料增強,資料標記)
開發環境 Anaconda:jupyter notebook /pycharm pip install SimpleItk # 讀取CT醫學影象 pip install tqdm # 可擴充套件的Python進度條,封裝
opencv學習筆記五十七:基於分水嶺的影象分割
#include<opencv2\opencv.hpp> using namespace cv; using namespace std; int main(int arc, char** argv) { Mat src = imread("1.jpg");