
Elasticsearch系列---補充幾個知識點
概要
bulk api有趣的json格式
前面《簡單入門實戰》一節中,有介紹bulk的使用示例,大家一定很奇怪,還有這麼有趣的JSON格式,必須嚴格照他的換行來做,我想把JSON搞得美觀可讀性好一點,居然給我報錯!
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n它為什麼要這樣規定?
我們想想bulk設計的初衷,批處理的執行效率肯定是第一優先順序,此時效率>可讀性,如果我們允許隨意換行,用標準格式的JSON串,會有什麼區別?
如果是標準格式的JSON串,處理流程一般會是這樣:
- 將整個json陣列全部載入,解析為JSONArray物件,這時記憶體中同時有json串文字和JSONArray物件。
- 迴圈遍歷JSONArray物件,獲取每個請求中的document進行路由資訊。
- 把路由到同一個shard的請求合在一組,開闢一個新的請求陣列,將JSONObject放在數組裡。
- 序列化請求陣列,傳送到對應的節點上去。
- 收集各節點的響應,彙總後返回給Coordinate Node。
- Coordinate Node收到所有的彙總資訊,返回給客戶端。
這種方式唯一的缺點就是佔用記憶體多,一份json串,解析為JSONArray物件,記憶體佔用翻番,bulk裡面多則幾千條請求,如果JSON報文大一點,這記憶體耗費不是開玩笑的,如果bulk佔用的記憶體過多,就可能會擠壓其他請求的記憶體使用量,如搜尋請求、資料分析請求等,整體效能會急速下降,嚴重的情況可能會觸發Full GC,會導致整個JVM工作執行緒暫停。
再看看現有的格式定義:除了delete操作佔一行,其他操作都是佔兩行的,ES收到bulk請求時,就可以簡單的按行進行切割,也不用轉成json物件了,切割完的JSON讀取裡面的meta資訊,直接路由到相應的shard,收集完響應返回即可。
這樣的好處切割邏輯更簡單,都是處理小json字串,記憶體快拿快放,整個ES避免對記憶體的大塊佔用,儘可能保證效能。
增刪改文件內部原理
增刪改的過程整體與查詢文件過程一致,只是多了一個數據同步的步驟,整個過程如圖所示:
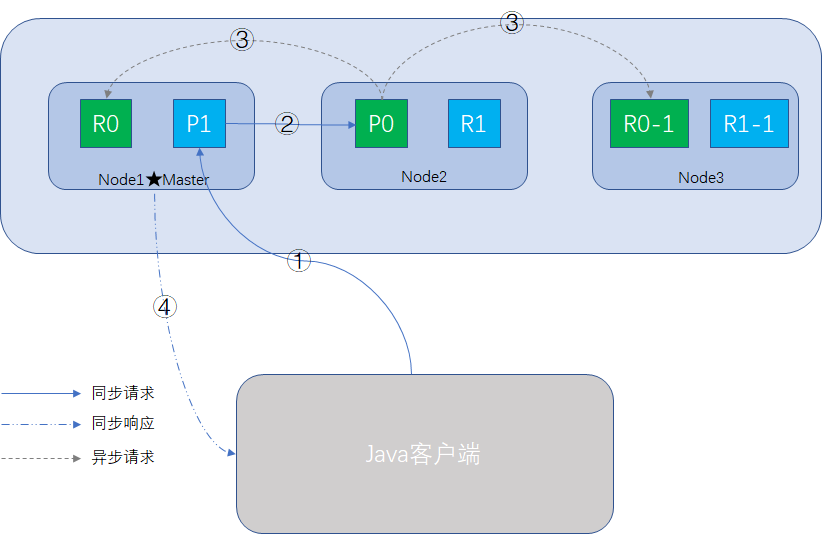
相似的步驟不贅述。
步驟3的前提是primary shard操作成功,非同步請求,所有的replica都返回成功後,node2響應操作成功的訊息給Coordinate Node,最後Coordinate Node向客戶端返回成功訊息,此時所有的primary shard和replica shard均已完成資料同步,資料是一致的。
查詢文件內部原理
當我們使用客戶端(Java或Restful API)向Elasticsearch搜尋文件資料時,可以向任意一個node傳送請求,此時接受請求的node就是Coordinate Node,整個過程如圖所示:
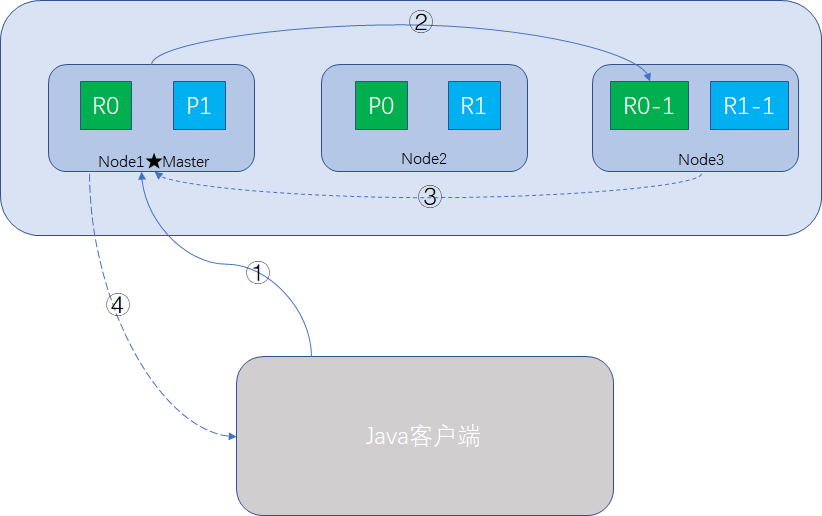
- Coordinate Node接收到請求後,根據_id資訊或routing資訊,確定該document的路由資訊,即在哪個shard裡,比如說P0。
- Coordinate Node轉發請求,使用round-robin隨機輪詢演算法 ,在primary shard或replica shard隨機挑一個,讓讀請求負載均衡,如node-3的R0-1
- 接收請求的node-3搜尋完成後,響應結果給Coordinate Node。
- Coordinate Node將響應結果返回給客戶端。
注意一個問題,如果document還在建立索引過程中,可能只有primary shard有,任何一個replica shard都沒有,此時可能會無法讀取到document,但是等document完成索引建立後,primary shard和replica shard就都有了,這個時間間隔,大概1秒左右。
寫一致性要求
Elasticsearch在嘗試執行一個寫操作時,可以帶上consistency引數,宣告我們的寫一致性的級別,正確地使用這個級別,為了避免因分割槽故障執行寫操作,導致資料不一致,這個引數有三個值供選擇:
- one:只要有一個primary shard是active活躍可用的,就可以執行寫操作
- all:必須所有的primary shard和replica shard都是活躍的,才可以執行這個寫操作
- quorum:預設的值,要求所有的shard中,必須是大部分的shard都是活躍的,可用的,才可以執行這個寫操作
這個大部分,該怎麼算呢?
這個大部分,叫規定數量(quorum),有個計算公式:
int( (primary + number_of_replicas) / 2 ) + 1
- primary 即一個索引下的primary shard數量;
- number_of_replicas即每個primary shard擁有的副本數量,注意不是一個索引所有的副本數量。
如果一個索引有3個primary shard,每個shard擁有1個replica shard,共6個shard,這樣number_of_replicas就是1,代入公式計算:
quorum = int ((3 + 1) / 2) + 1 = 3
所以6個shard中必須有3個是活躍的,才讓你寫,如果你只啟用2個node,這樣活躍的replica shard只會有1個,加上primarys shard ,結果最多是2。這樣是達不到quorun的值,因此將無法索引和刪除任何文件。
此時你必須啟動3個節點,才能滿足quorum寫一致性的要求。
quorum不夠時的超時處理
如果寫操作檢查前,活躍的shard不夠導致無法寫入時,Elasticsearch會等待,希望宕機的node能夠恢復,預設60秒,可以使用timeout引數修改預設值。
單node的寫一致性
照上面的公式算,1個node的,1個索引1個primary shard,number_of_replicas為1的情況,計算公式:
quorum = int ((1 + 1) / 2) + 1 = 2
實際只有一個primary shard是活躍的,豈不是永遠無法寫入?我研發機器只啟動一個node,不照樣增刪改查?
原來是Elasticsearch為了避免單一node的無法寫入問題,加了判斷邏輯:只有number_of_replicas大於1的時候,quorum才會生效。
小結
本篇從效能優先的角度簡單對bulk的設計作了一些補充,並對文件查詢,寫操作的原理過程,一致性級別,quorum的計算做了一些簡單講解,謝謝。
專注Java高併發、分散式架構,更多技術乾貨分享與心得,請關注公眾號:Java架構社群

相關推薦
Elasticsearch系列---補充幾個知識點
概要 bulk api有趣的json格式 前面《簡單入門實戰》一節中,有介紹bulk的使用示例,大家一定很奇怪,還有這麼有趣的JSON格式,必須嚴格照他的換行來做,我想把JSON搞得美觀可讀性好一點,居然給我報錯! {"action": {"meta"}}\n {"data"}\n {"action": {"
elasticsearch中的幾個概念總結
查詢 article ase con 總結 diff 返回 cse nan 1、Geo spatial search : 地理空間搜索,可以在搜索查詢中指定的某一距離內查找所要的內容。也可以返回以當前為圓心,逐漸添加圓的半徑。直到找到所匹配到的內容。
學些 Python 中的幾個知識點
之前只是簡單會用,現在重新按照官網的 Tutorial 來學 python 中一切變數都是引用(指標) 最簡單的例子: def func(ll): ll.append(42) ll = [1, 2] func(ll) print(str(ll)) #輸出 [1, 2, 42] 雖然函式傳參
mongodb、mysql資料庫的幾個知識點
1、MongoDB與關係型資料庫的區別: MongoDB是一個面向文件的資料庫,資料結構為鍵值對組成,文件類似於JSON物件,欄位值可以包含陣列、其他文件。 MongoDB資料庫沒有預定模式,文件的鍵(key)值(value)不是固定的型別與大小,而關係型資料庫中每個表的欄位都
transform的幾個知識點
transform 的幾個知識點 三維座標系 1、w3c中給出了三維空間的座標系,z軸指向螢幕外 2、 CSS3 transform 變換使用的是元素自身座標系 位移 **translateZ(): 需要給父標籤新增透視才能觀察到 透視 透視是通過對元素中靠
javascript中還有幾個知識點沒弄懂!現在沒時間弄懂,到時候回過頭來再理解這幾個知識點,先記錄一下
javascript中還有幾個知識點沒弄懂!現在沒時間弄懂,到時候回過頭來再理解這幾個知識點,先記錄一下 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>
學習大資料掌握這幾個知識點,會少走很多彎路
說到初識Hadoop,這章我們一起來聊聊,更高效的WordCount。 在聊之前我多說兩句,大家既然想學習大資料,那麼就請你放棄你自己認為的自學,或者是看幾本書就能學會的念頭,好好的一步一步的系統的去學習才是王道,畢竟學完之後我們是用來創造價值的,所以一
Sitecore 9 使用 Azure Search的幾個知識點
Sitecore 的patch config檔案(通常在app config的Include資料夾中) 使用role:require和search:require,不需要disabled檔案字尾名了 寫Index的時候,Azure Search要求Field Name必須存在於Schema中( Error
C#基礎學習需要注意的幾個知識點
在學習Unity之前,相信我們都要經歷C#程式語言的學習,大家都知道在C#是一門面向物件的程式語言,具有封裝繼承多型的一些特點,這些知識點淺學並不難,但是當我們在Unity的道路上越走越遠的時候,我
窺探 kernel --- 有關係統呼叫的幾個知識點
郵箱:[email protected] 一般情況下,使用者程序是不能訪問核心空間的。它既不能訪問核心中的資料,也不能訪問核心中的函式。但在linux核心中設定了一組用於實現各種系統功能的函式,成為系統呼叫。使用者可以在應用程式中呼叫它們。 linux
網路安全性的幾個知識點
網路安全的幾個知識點 隨著計算機的普及,它的安全問題也越來越受到所有人的重視。電腦保安既包括硬體、軟體和技術,又包括安全規劃、安全管理和安全監督。計算機系統的安全主要包括網路安全,作業系統安全和資料庫安全三個方面。最近學習了一些網路安全的知識,因為不是很明白,所
幾個知識點: null;/r/n;
1. 在Java中,String的初始值是null;如果處理不當,就會看到這樣的資訊:"xxx null xxx",這個null是怎麼來的呢? String str = null; System.out.println("hello "+str+" world"); 這
scala 元組tuple的幾個知識點
通過下標_n取資料不多說了,下面是幾個比較有意思的知識點 知識點 1、Tuple 和Function 和Producct一樣最多隻支援22個元素 比如 (0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,
redis的幾個知識點
Redis的全稱是Remote Dictionary Server,即遠端字典服務,通常用作伺服器快取服務。 這裡通過Redis的幾個知識點來了解Redis。 Redis的通訊協議 Redis的通訊協議是文字協議,是的,Redis伺服器與客戶端通過RESP(Redis Serialization Pro
Elasticsearch系列---幾個高階功能
### 概要 本篇主要介紹一下搜尋模板、對映模板、高亮搜尋和地理位置的簡單玩法。 ### 標準搜尋模板 搜尋模板search tempalte高階功能之一,可以將我們的一些搜尋進行模板化,使用現有模板時傳入指定的引數就可以了,避免編寫重複程式碼。對常用的功能可以利用模板進行封裝,使用時更簡便。 這點類
miniui幾個常用知識點匯總
簡單 去除 spa 自帶 超過 表格 繪制 val wro 1.在表格中去除系統自帶的序列號,請看代碼: function allAndBrief(id) { if(id==1){ grid.set({
深入淺出maven系列(三)---maven構建ssh工程(父工程與子模組的拆分與耦合) 前一節我們初識了maven並且掌握了maven的常規使用,這一節就來講講它的一個重要的場景,也就是通過maven將一個ssh專案分隔為不同的幾個部門獨立開發,很重要,加油!!!
前一節我們初識了maven並且掌握了maven的常規使用,這一節就來講講它的一個重要的場景,也就是通過maven將一個ssh專案分隔為不同的幾個部門獨立開發,很重要,加油!!! 一、maven父工
webservice 教程學習系列(四)——webservice 中幾個比較重要的術語
(1)wsdl:webservice definition language(直譯webservice定義語言) 1.對應一種型別檔案.wsdl 2.定義了webservice的伺服器端和客戶端應用互動傳遞請求和響應資料的格式和方式; 3.一個webservice對應一個wsdl文件;
webservice 教程學習系列(三)——關於webservice的幾個問題
1.webservice是什麼 (1)給予web服務,伺服器端整出一些資源讓客戶端應用訪問(獲取資源); (2)一個跨語言、跨平臺的規範(抽象); (3)多個跨平臺、跨語言的應用間通訊整合的方案(實際); 例子:以各大網站需要顯示天氣預報的功能為例: (1)氣象中心需要將收集的天氣
Java初級程式設計9個重要的知識點你知道幾個?
關於java程式設計的知識,有人會問哪些是重要的知識點,不知道大家是否都知道呢? 現在小編給大家分享以下9點內容,仔細看咯! 1.多執行緒併發 多執行緒是Java中普遍認為比較難的一塊。多執行緒用好了可以有效提高cpu使用率, 提升整體系統效率, 特別是在有大量IO操作阻塞的情況下