
最簡單的 Java記憶體模型 講解
本部落格系列是學習併發程式設計過程中的記錄總結。由於文章比較多,寫的時間也比較散,所以我整理了個目錄貼(傳送門),方便查閱。
併發程式設計系列部落格傳送門
前言
在網上看了很多文章,也看了好幾本書中關於JMM的介紹,我發現JMM確實是Java中比較難以理解的概念。網上很多文章中關於JMM的介紹要麼是照搬了一些書上的內容,要麼就乾脆介紹的就是錯的。本文試著用比較簡潔的語言介紹清楚JMM到底是什麼,解決了Java程式設計中的哪些問題。不求深入,但求讓讀者看地清楚,看完之後能對JMM有個比較直觀的認識。
本文是筆者在總結了網上的多篇文章之後加上自己的理解整理出來的,內容上可能和JMM標準存在偏差,有問題還望留言指出。
什麼是JMM
JMM是一個規範,我從JSR113標準中摘錄了一段對JMM的簡單介紹:
JavaTM virtual machines support multiple threads of execution. Threads are represented by the
Thread class. The only way for a user to create a thread is to create an object of this class; each
thread is associated with such an object. A thread will start when the start() method is invokedon the corresponding Thread object.
The behavior of threads, particularly when not correctly synchronized, can be confusing and
counterintuitive. This specification describes the semantics of multithreaded programs written in
the JavaTM programming language; it includes rules for which values may be seen by a read ofshared memory that is updated by multiple threads. As the specification is similar to the memory
models for different hardware architectures, these semantics are referred to as the JavaTM memory
model.
These semantics do not describe how a multithreaded program should be executed. Rather,
they describe the behaviors that multithreaded programs are allowed to exhibit. Any execution
strategy that generates only allowed behaviors is an acceptable execution strategy.
上面的英文簡要翻譯如下:
Java虛擬機器支援多執行緒執行。在Java中
Thread類代表執行緒,建立一個執行緒的唯一方法就是建立一個Thread類的例項物件。當呼叫了物件的start方法後,相應的執行緒將會執行。執行緒的行為有時會令人困惑而且和我們的直覺相左,特別是線上程沒有正確同步的情況下。本規範描述了JVM平臺上多執行緒程式的語義(含義),具體包括一個執行緒對共享變數的寫入何時能被其他執行緒“看到”。由於本規範和不同硬體平臺上的記憶體模型相似,所以將本規範命名為Java記憶體模型。
從上面這段英文介紹中我們可以得到關於JMM的簡要資訊:
- JMM是一個和多執行緒相關的規範;
- JMM描述了JVM平臺上多執行緒程式的語義(含義),具體包括一個執行緒對共享變數的寫入何時能被其他執行緒“看到”。
但是隻看上面對於JMM的簡單解釋,我相信大多數人還是會很暈,對JMM具體是什麼還是很模糊。
不過我在上面的這段介紹中又發現了一段對JMM介紹的關鍵資訊:
As the specification is similar to the memory models for different hardware architectures, these semantics are referred to as the JavaTM memory model. (JMM和硬體平臺上的記憶體模型相似)
上面的介紹中提到JMM和硬體平臺上的記憶體模型相似,那麼我們就先看看硬體平臺上的記憶體模型究竟是什麼?
記憶體模型
有點計算機基礎的同學都應該知道,程式執行的時候其實就是一條條指令在CPU上執行的過程,而指令的執行又勢必會涉及到資料的讀取和寫入。說到資料,就又不得不提到一個重要的硬體:記憶體。在計算機中,記憶體是資料的“收集站”,資料從鍵盤、網路、檔案也有可能是一些感測器裝置進入到記憶體,然後CPU從記憶體中讀取這些資料並對這些資料進行“加工”後再寫回到記憶體。
上面整個過程看起來很完美,但是就像人與人之間是有差別的一樣,硬體和硬體之間也存在差別。CPU的執行速度就和尤塞恩·博爾特的速度一樣(飛一樣的速度),而記憶體的執行速度和CPU相比就像我的跑步速度和博爾特比一樣,根本不是一個數量級的。CPU和記憶體執行速度的差距會導致整個系統性能的下降,因為CPU每次讀寫資料都要等待記憶體。(木桶理論在計算機中的體現)
但是這個問題根本就難不倒我們偉大的硬體工程師們。“聰明”的工程師們在CPU中加入了一層CPU快取記憶體層。這個快取的運算速度和CPU相當,當指令在CPU上執行的時候,會先將運算需要的資料從記憶體中複製一份到CPU的快取記憶體當中,那麼CPU進行計算時就可以直接從它的快取記憶體讀取資料和向其中寫入資料,當運算結束之後,再將快取記憶體中的資料重新整理到主存當中。(現代CPU其實是有多級快取的,但是為了簡單起見就沒介紹了,因為我覺得這裡不介紹CPU多級快取不會影響對JMM的理解)
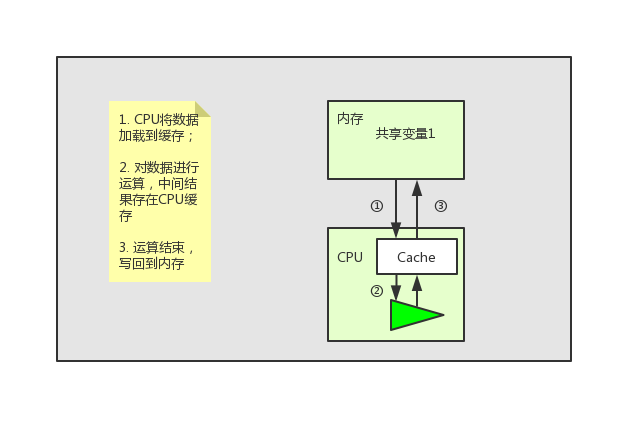
世界好像又重歸於平靜,一切又顯得那麼美好。但是其實問題才剛剛開始。
原子性問題
上面提到CPU進行運算時需要將共享變數先載入到CPU快取中,運算結束後再將最新資料寫回共享記憶體。這種看起來完美的工作方式其實存在一個問題,下面我們就以上面的圖片為列子,說下這個問題。
假如現在系統環境是 單核CPU+多執行緒工作模式,共享變數初始值是1,執行緒1和執行緒2分別對這個共享變數進行加一操作,理論上這個共享變數最後的值是3。我們看看程式的執行行為是否會和我們預期的一致。
執行緒對一個共享變數加一的過程需要分三步進行:
step1: read共享變數到工作記憶體
step2:對共享變數+1
step3:將共享變數寫回主記憶體但是上面的三個步驟並不是原子操作,也就是說可能會被打斷。現在假如執行緒1已經執行完了step1,但是這時CPU時間片用完了,執行緒2獲得執行機會也從記憶體中載入共享變數的值(此時共享變數的值還是1),最後兩個執行緒執行完step2和step3之後共享變數的值是2,並不是3。
出現上面問題的原因就是對共享變數的加一操作並不是原子性操作,所謂原子性操作是指一個或多個操作,要麼全部執行且在執行過程中不被任何因素打斷,要麼全部不執行。在多執行緒環境下原子性問題可能會造成錯誤的執行結果。
原子性問題是記憶體模型存在的第一個問題,但是記憶體模型存在的問題不止這一個。
快取一致性問題
隨著科技的進步,對CPU的需求越來越高。但是摩爾定律的失效註定單個CPU的效能已經很難再大幅度提升。此時“聰明”的硬體工程師又出場了,他們創造性地將多個CPU整合到一個上,這樣CPU的效能不就能成倍地增長了麼。多核CPU的確帶來了CPU效能的提升,但是這卻“害苦”了軟體工程師,因為多核CPU大大提升了多執行緒程式設計的難度。
多核CPU進行多執行緒程式設計時存在的一個顯著問題就是快取一致性問題。
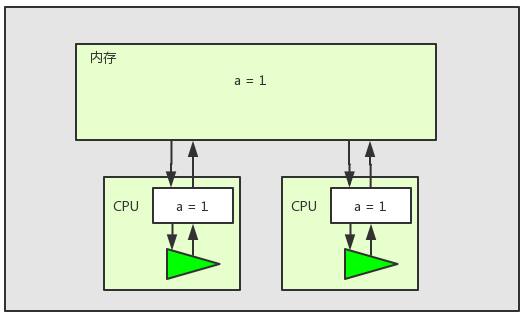
以上圖為例,在多核CPU多執行緒環境下,兩個執行緒對共享變數a進行加1操作。兩個執行緒都將共享變數a在記憶體中的值載入到了工作記憶體中,如上圖所示。但是此時執行緒2失去了CPU時間片,而執行緒1還是繼續執行併成功將變數加一。當執行緒1執行完之後,記憶體中的值如下圖所示:
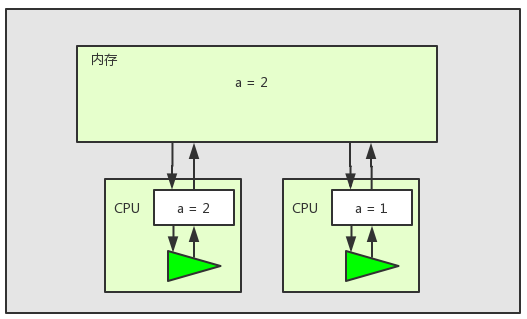
我們發現此時執行緒2中的變數a的值已經是過期的值,並不是變數a最新的值,所以當執行緒2執行完之後變數a並不是我們想要的值3。這個問題就是多核CPU中快取一致性問題。
和上面的原子性問題不同,快取一致性問題只有在多核多執行緒環境下才會出現,而原子性問題只要是在多執行緒環境下都可能會出現。
指令重排序問題
所謂的指令重拍是指CPU為了是內部的處理器單元得到充分的應用,可能會對程式碼進行亂序執行的行為。這個指令重拍的行為在單執行緒環境下不會有任何問題,但是在多執行緒環境下程式就可能出現錯誤的執行結果。
這邊不準備會指令重排進行深入的討論,大家只要知道指令重排序是一種CPU效能優化的行為,而這個行為在多執行緒環境下可能會導致程式錯誤的執行結果。
通過上面分析我們看到:隨著CPU效能的不斷提升,隨之出現了原子性問題、快取一致性問題和指令重排序問題。細心的我們會發現這些問題其實是和多執行緒環境下共享變數訪問的原子性、可見性和有序性問題一一對應的。
記憶體模型的作用
為了既保證CPU的高效執行,有保證共享記憶體讀寫的正確性(原子性、可見性和有序性),人們定義了記憶體模型。記憶體模型是一個規範,這個規範能保證共享記憶體讀寫的正確性。
Java記憶體模型
上面提到記憶體模型的出現是為了解決共享變數讀寫的原子性、可見性和有序性問題,但是沒有具體講怎麼解決的。下面就來看看在Java中的記憶體模型JMM。
Java記憶體模型是記憶體模型在Java語言中的體現。這個模型的主要目標是定義程式中各個共享變數的訪問規則,也就是在虛擬機器中將變數儲存到記憶體以及從記憶體中取出變數這類的底層細節。通過這些規則來規範對記憶體的讀寫操作,保證了併發場景下的可見性、原子性和有序性。
Java記憶體模型規定了所有的變數都儲存在主記憶體中,每條執行緒還有自己的工作記憶體,執行緒的工作記憶體中儲存了該執行緒中是用到的變數的主記憶體副本拷貝,執行緒對變數的所有操作都必須在工作記憶體中進行,而不能直接讀寫主記憶體。不同的執行緒之間也無法直接訪問對方工作記憶體中的變數,執行緒間變數的傳遞均需要自己的工作記憶體和主存之間進行資料同步進行。
而JMM就作用於工作記憶體和主存之間資料同步過程。他規定了如何做資料同步以及什麼時候做資料同步。也就是說Java執行緒之間的通訊由Java記憶體模型控制, JMM決定一個執行緒對共享變數的寫入何時對另一個執行緒可見。
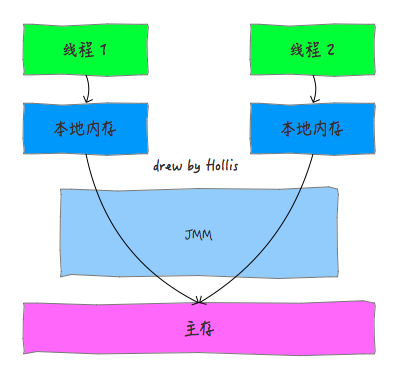
以上圖片來自(https://www.hollischuang.com/archives/2550)
簡單總結
Java的多執行緒之間是通過共享記憶體進行通訊的,而由於採用共享記憶體進行通訊,在通訊過程中會存在一系列如原子性、可見性和有序性的問題。JMM就是為了解決這些問題而出現的,這個模型建立了一些規範,可以保證在多核CPU多執行緒程式設計環境下,對共享變數讀寫的原子性、可見性和有序性。
再簡單點說 JMM就是一個為了解決多核CPU多執行緒程式設計環境下對共享變數訪問存在原子性、可見性和有序性問題 的規範。
本篇部落格只是簡單講了下JMM的概念,以及解決哪些問題。具體JMM怎麼解決原子性、可見性和有序性問題的,後續會寫部落格分析。
參考
- https://yq.aliyun.com/articles/715712
- https://yq.aliyun.com/articles/720689?spm=a2c4e.11163080.searchblog.24.16c62ec1rUruam
- https://www.hollischuang.com/archives/2550