
Redis面試熱點工程架構篇之資料同步
溫馨提示 更佳閱讀體驗:【決戰西二旗】|Redis面試熱點之工程架構篇[2]
前言
前面用了3篇文章介紹了一些底層實現和工程架構相關的問題,鑑於Redis的熱點問題還是比較多的,因此今天繼續來看工程架構相關的問題,感興趣的可以先回顧一下之前的3篇文章,如下:
【決戰西二旗】|Redis面試熱點之底層實現篇
【決戰西二旗】|Redis面試熱點之底層實現篇(續)
【決戰西二旗】|Redis面試熱點之工程架構篇
通過本文你將瞭解到以下內容:
- Redis的資料同步機制
持久化和資料同步的關係、Redis分散式儲存的CAP選擇、Redis資料同步複製和非同步複製、全量複製和增量複製的原理、無盤複製等。
Q:談談你對Redis資料同步(複製)的理解吧!
持久化和資料同步的關係
理解持久化和資料同步的關係,需要從單點故障和高可用兩個角度來分析:
單點宕機故障
假如我們現在只有一臺作為快取的Redis機器,通過持久化將熱點資料寫到磁碟,某時刻該Redis單點機器發生故障宕機,此期間快取失效,主儲存服務將承受所有的請求壓力倍增,監控程式將宕機Redis機器拉起。
重啟之後,該機器可以Load磁碟RDB資料進行快速恢復,恢復的時間取決於資料量的多少,一般秒級到分鐘級不等,恢復完成保證之前的熱點資料還在,這樣儲存系統的CacheMiss就會降低,有效降低了快取擊穿的影響。
在單點Redis中持久化機制非常有用,只寫文字容易讓大家睡著,我畫了張圖:
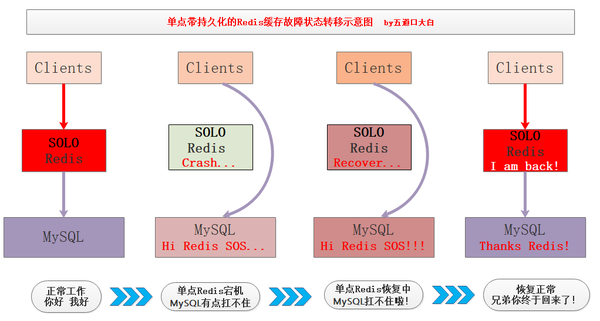
高可用的Redis系統
作為一個高可用的快取系統單點宕機是不允許的,因此就出現了主從架構,對主節點的資料進行多個備份,如果主節點掛點,可以立刻切換狀態最好的從節點為主節點,對外提供寫服務,並且其他從節點向新主節點同步資料,確保整個Redis快取系統的高可用。
如圖展示了一個一主兩從讀寫分離的Redis系統主節點故障遷移的過程,整個過程並沒有停止正常工作,大大提高了系統的高可用:
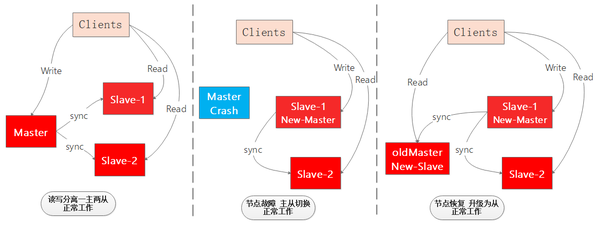
從上面的兩點分析可以得出個小結論【劃重點】:
持久化讓單點故障不再可怕,資料同步為高可用插上翅膀。
我們理解了資料同步對Redis的重要作用,接下來繼續看資料同步的實現原理和過程、重難點等細節問題吧!
Redis系統中的CAP理論
對分散式儲存有了解的讀者一定知道CAP理論,說來慚愧筆者在2018年3月份換工作的時候,去Face++曠視科技面後端開發崗位時就遇到了CAP理論,除了CAP理論問題之外其他問題都在射程內,所以最終還是拿了Offer。
但是印象很深T大畢業的面試官說前面的問題答得都不錯,為啥CAP問題答得這麼菜…其實我當時只知道CAP理論就像高富帥一樣,不那麼容易達到...細節不清楚...各位吃瓜讀者,筆者前面說這個小事情的目的是想表達:CAP理論對於理解分散式儲存非常重要,下回你們面試被問到CAP別怪我沒提醒。
在理論電腦科學中,CAP定理又被稱作布魯爾定理Brewer's theorem,這個定理起源於加州大學伯克利分校的電腦科學家埃裡克·布魯爾在2000年的分散式計算原理研討會PODC上提出的一個猜想。
在2002年麻省理工學院的賽斯·吉爾伯特和南希·林奇發表了布魯爾猜想的證明,使之成為一個定理。它指出對於一個分散式計算系統來說,不可能同時滿足以下三點:
- C Consistent 一致性 連貫性
- A Availability 可用性
- P Partition Tolerance 分割槽容忍性
來看一張阮一峰大佬畫的圖:
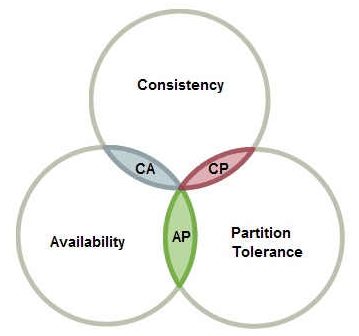
舉個簡單的例子,說明一下CP和AP的相容性:
CP和AP問題
理解CP和AP的關鍵在於分割槽容忍性P,網路分割槽在分散式儲存中再平常不過了,即使機器在一個機房,也不可能全都在一個機架或一臺交換機。
這樣在區域網就會出現網路抖動,筆者做過1年多DPI對於網路傳輸中最深刻的三個名詞:丟包、亂序、重傳。所以我們看來風平浪靜的網路,在伺服器來說可能是風大浪急,一不小心就不通了,所以當網路出現斷開時,這時就出現了網路分割槽問題。
對於Redis資料同步而言,假設從結點和主結點在兩個機架上,某時刻發生網路斷開,如果此時Redis讀寫分離,那麼從結點的資料必然無法與主繼續同步資料。在這種情況下,如果繼續在從結點讀取資料就造成資料不一致問題,如果強制保證資料一致從結點就無法提供服務造成不可用問題,從而看出在P的影響下C和A無法兼顧。
其他幾種情況就不深入了,從上面我們可以得出結論:當Redis多臺機器分佈在不同的網路中,如果出現網路故障,那麼資料一致性和服務可用性無法兼顧,Redis系統對此必須做出選擇,事實上Redis選擇了可用性,或者說Redis選擇了另外一種最終一致性。
最終一致性
Redis選擇了最終一致性,也就是不保證主從資料在任何時刻都是一致的,並且Redis主從同步預設是非同步的,親愛的盆友們不要暈!不要蒙圈!
我來一下解釋同步複製和非同步複製(注意:考慮讀者的感受 我並沒有寫成同步同步和非同步同步 哈哈):
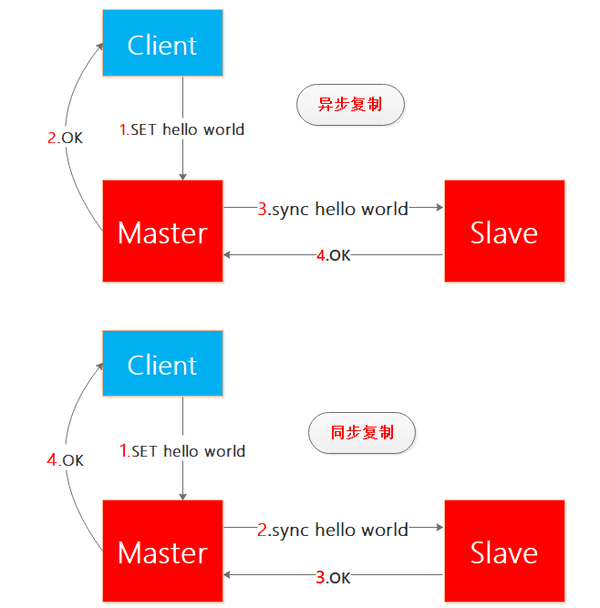
一圖勝千言,看紅色的數字就知道同步複製和非同步複製的區別了:
- 非同步複製:當客戶端向主結點寫了hello world,主節點寫成功之後就向客戶端回覆OK,這樣主節點和客戶端的互動就完成了,之後主節點向從結點同步hello world,從結點完成之後向主節點回復OK,整個過程客戶端不需要等待從結點同步完成,因此整個過程是非同步實現的。
- 同步複製:當客戶端向主結點寫了hello world,主節點向從結點同步hello world,從結點完成之後向主節點回復OK,之後主節點向客戶端回覆OK,整個過程客戶端需要等待從結點同步完成,因此整個過程是同步實現的。
Redis選擇非同步複製可以避免客戶端的等待,更符合現實要求,不過這個複製方式可以修改,根據自己需求而定吧。
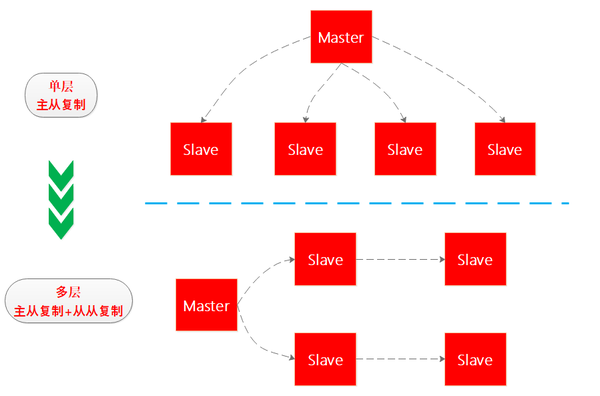
從從複製
假如Redis高可用系統中有一主四從,如果四個從同時向主節點進行資料同步,主節點的壓力會比較大,考慮到Redis的最終一致性,因此Redis後續推出了從從複製,從而將單層複製結構演進為多層複制結構,筆者畫了個圖看下:
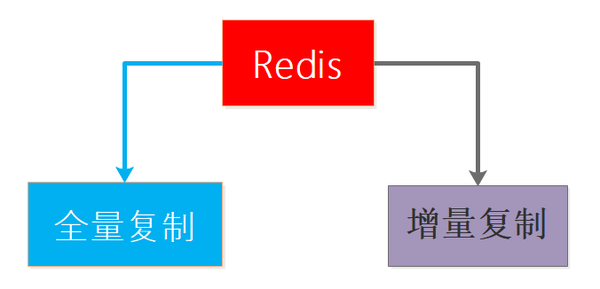
全量複製和增量複製
全量複製是從結點因為故障恢復或者新新增從結點時出現的初始化階段的資料複製,這種複製是將主節點的資料全部同步到從結點來完成的,所以成本大但又不可避免。
增量複製是主從結點正常工作之後的每個時刻進行的資料複製方式,涓涓細流同步資料,這種同步方式又輕又快,優點確實不少,不過如果沒有全量複製打下基礎增量複製也沒戲,所以二者不是矛盾存在而是相互依存的。
全量複製過程分析
Redis的全量複製過程主要分三個階段:
- 快照階段:從結點向主結點發起SYNC全量複製命令,主節點執行bgsave將記憶體中全部資料生成快照併發送給從結點,從結點釋放舊記憶體載入並解析新快照,主節點同時將此階段所產生的新的寫命令儲存到緩衝區。
- 緩衝階段:主節點向從節點同步儲存在緩衝區的操作命令,這部分命令主節點是bgsave之後到從結點載入快照這個時間段內的新增命令,需要記錄要不然就出現資料丟失。
- 增量階段:緩衝區同步完成之後,主節點正常向從結點同步增量操作命令,至此主從保持基本一致的步調。
借鑑參考1的一張圖表,寫的很好,我就不再重複畫圖了:

考慮一個多從併發全量複製問題:
如果此時有多個從結點同時向主結點發起全量同步請求會怎樣?
Redis主結點是個聰明又誠實的傢伙,比如現在有3個從結點A/B/C陸續向主節點發起SYNC全量同步請求。
- 主節點在對A進行bgsave的同時,B和C的SYNC命令到來了,那麼主節點就一鍋燴,把針對A的快照資料和緩衝區資料同時同步給ABC,這樣提高了效率又保證了正確性。
- 主節點對A的快照已經完成並且現在正在進行緩衝區同步,那麼只能等A完成之後,再對B和C進行和A一樣的操作過程,來實現新節點的全量同步,所以主節點並沒有偷懶而是重複了這個過程,雖然繁瑣但是保證了正確性。
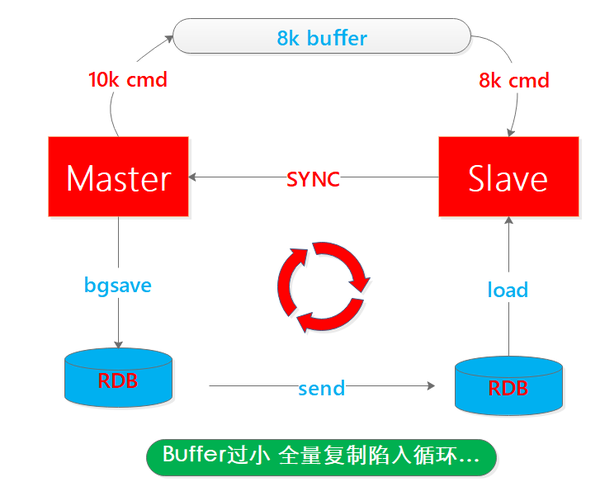
再考慮一個快照複製迴圈問題:
主節點執行bgsave是比較耗時且耗記憶體的操作,期間從結點也經歷裝載舊資料->釋放記憶體->裝載新資料的過程,記憶體先升後降再升的動態過程,從而知道無論主節點執行快照還是從結點裝載資料都是需要時間和資源的。
拋開對效能的影響,試想如果主節點快照時間是1分鐘,在期間有1w條新命令到來,這些新命令都將寫到緩衝區,如果緩衝區比較小隻有8k,那麼在快照完成之後,主節點緩衝區也只有8k命令丟失了2k命令,那麼此時從結點進行全量同步就缺失了資料,是一次錯誤的全量同步。
無奈之下,從結點會再次發起SYNC命令,從而陷入迴圈,因此緩衝區大小的設定很重要,二話不說再來一張圖:
增量複製過程分析
增量複製過程稍微簡單一些,但是非常有用,試想複雜的網路環境下,並不是每次斷開都無法恢復,如果每次斷開恢復後就要進行全量複製,那豈不是要把主節點搞死,所以增量複製算是對複雜網路環境下資料複製過程的一個優化,允許一段時間的落後,最終追上就行。
增量複製是個典型的生產者-消費者模型,使用定長環形陣列(佇列)來實現,如果buffer滿了那麼新資料將覆蓋老資料,因此從結點在複製資料的同時向主節點反饋自己的偏移量,從而確保資料不缺失。
這個過程非常好理解,kakfa這種MQ也是這樣的,所以在合理設定buffer大小的前提下,理論上從的消費能力是大於主的生產能力的,大部分只有在網路斷開時間過長時會出現buffer被覆蓋,從結點消費滯後的情況,此時只能進行全量複製了。

無盤複製
理解無盤複製之前先看下什麼是有盤複製呢?
所謂盤是指磁碟,可能是機械磁碟或者SSD,但是無論哪一種相比記憶體都更慢,我們都知道IO操作在服務端的耗時是佔大頭的,因此對於全量複製這種高IO耗時的操作來說,尤其當服務併發比較大且還在進行其他操作時對Redis服務本身的影響是比較大大,之前的模式時這樣的:
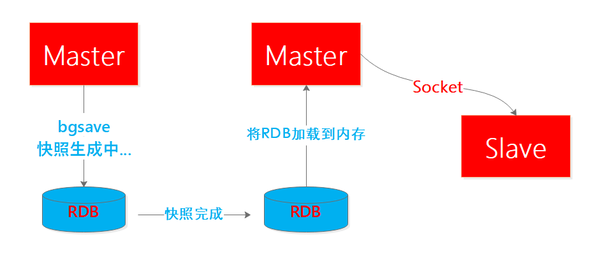
在Redis2.8.18版本之後,開發了無盤複製,也就是避免了生成的RDB檔案落盤再載入再網路傳輸的過程,而是流式的遍歷傳送過程,主節點一邊遍歷記憶體資料,一邊將資料序列化傳送給從結點,從結點沒有變化,仍然將資料依次儲存到本地磁碟,完成傳輸之後進行記憶體載入,可見無盤複製是對IO更友好。
小結
時間原因只能寫這麼多了,和大家一起學習不是把桶填滿而是把火點燃。
回顧一下:本文主要講述了持久化和資料同步的關係、Redis分散式儲存的CAP選擇、Redis資料同步複製和非同步複製、全量複製和增量複製的原理、無盤複製等,相信耐心的讀者一定會有所收穫的。
最後可以思考一個問題:
Redis的資料同步仍然會出現資料丟失的情況,比如主節點往緩衝區寫了10k條操作命令,此時主掛掉了,從結點只消費了9k操作命令,那麼切主之後從結點的資料就丟失了1k,即使舊主節點恢復也只能作為從節點向新主節點發起全量複製,那麼我們該如何優化這種情況呢?
巨人的肩膀
- https://segmentfault.com/a/1190000012390817
- 錢文品-《Redis深度歷險核心原理和應用實踐》