
AWS EC2 搭建 Hadoop 和 Spark 叢集
前言
本篇演示如何使用 AWS EC2 雲服務搭建叢集。當然在只有一臺計算機的情況下搭建完全分散式叢集,還有另外幾種方法:一種是本地搭建多臺虛擬機器,好處是免費易操控,壞處是虛擬機器對宿主機配置要求較高,我就一臺普通的筆記本,開兩三個虛擬機器實在承受不起; 另一種方案是使用 AWS EMR ,是亞馬遜專門設計的叢集平臺,能快速啟動叢集,且具有較高的靈活性和擴充套件性,能方便地增加機器。然而其缺點是隻能使用預設的軟體,如下圖:

如果要另外裝軟體,則需要使用 Bootstrap 指令碼,詳見 https://docs.aws.amazon.com/zh_cn/emr/latest/ManagementGuide/emr-plan-software.html?shortFooter=true ,可這並不是一件容易的事情,記得之前想在上面裝騰訊的 Angel 就是死活都裝不上去。 另外,如果在 EMR 上關閉了叢集,則裡面的檔案和配置都不會儲存,下次使用時全部要重新設定,可見其比較適用於一次性使用的場景。
綜上所述,如果使用純 EC2 進行手工搭建,則既不會受本地資源限制,也具有較高的靈活性,可以隨意配置安裝軟體。而其缺點就是要手工搭建要耗費較多時間,而且在雲上操作和在本地操作有些地方是不一樣的,只要有一步出錯可能就要卡殼很久,鑑於網上用 EC2 搭建這方面資料很少,因此這裡寫一篇文章把主要流程記錄下來。
如果之前沒有使用過 EC2,可能需要花一段時間熟悉,比如註冊以及建立金鑰對等步驟,官方提供了相關教程 。另外我的本地機和雲端機使用的都是 Ubuntu 16.04 LTS 64位,如果你的本地機是 Windows,則需要用 Git 或 PuTTY 連線雲端機,詳情參閱 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/putty.html 。
建立 EC2 例項
下面正式開始,這裡設立三臺機器 (例項),一臺作主節點 (master node),兩臺作從節點 (slaves node)。首先建立例項,選擇 Ubuntu Server 16.04 LTS (HVM) ,例項型別選擇價格低廉的 t2.medium 。如果是第一次用,就不要選價格太高的型別了,不然萬一操作失誤了每月賬單可承受不起。



在第 3 步中,因為要同時開三臺機器,Number of Instances 可以直接選擇3。但如果是每臺分別開的話,下面的 Subnet 都要選擇同一個區域,不然機器間無法通訊,詳情參閱 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/using-regions-availability-zones.html 。

第 4 步設定硬碟大小,如果就搭個叢集可能不用動,如果還要裝其他軟體,可能就需要在這裡增加容量了,我是增加到了 15 GB:

第 5 和第 6 步直接Next 即可,到第 7 步 Launch 後選擇或新建金鑰對,就能得到建立好的 3 個例項,這裡可以設定名稱備註,如 master、slave01、slave02 等:

開啟 3 個終端視窗,ssh 連線3個例項,如 ssh -i xxxx.pem [email protected] ,其中 xxxx.pem 是你的本地金鑰對名稱,ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com 是該例項的外部 DNS 主機名,每臺例項都不一樣。這裡需要說明一下,因為這是和本地開虛擬機器的不同之處: EC2 的例項都有公有 IP 和私有 IP 之分,私有 IP 用於雲上例項之間的通訊,而公有 IP 則用於你的本地機與例項之間的通訊,因此這裡 ssh 連線使用的是公有 IP (DNS) 。在下面搭建叢集的步驟中也有需要填寫公有和私有 IP ,注意不要填反了。關於二者的區別參閱 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/using-instance-addressing.html?shortFooter=true#using-instance-addressing-common 。
新增 hadoop 使用者、安裝 Java 環境
以下以 master 節點為例。登陸例項後,預設使用者為 ubuntu,首先需要建立一個 hadoop 使用者:
$ sudo useradd -m hadoop -s /bin/bash # 增加 hadoop使用者
$ sudo passwd hadoop # 設定密碼,需要輸入兩次
$ sudo adduser hadoop sudo # 為 hadoop 使用者增加管理員許可權
$ su hadoop # 切換到 hadoop 使用者,需要輸入密碼
$ sudo apt-get update # 更新 apt 源這一步完成之後,終端使用者名稱會變為 hadoop,且 /home 目錄下會另外生成一個 hadoop 資料夾。

Hadoop 依賴於 Java 環境,所以接下來需要先安裝 JDK,直接從官網下載,這裡下的是 Linux x64 版本 jdk-8u231-linux-x64.tar.gz ,用 scp 遠端傳輸到 master 機。注意這裡只能傳輸到 ubuntu 使用者下,傳到 hadoop 使用者下可能會提示許可權不足。
$ scp -i xxx.pem jdk-8u231-linux-x64.tar.gz [email protected]:/home/ubuntu/ # 本地執行該命令本篇假設所有軟體都安裝在 /usr/lib 目錄下:
$ sudo mv /home/ubuntu/jdk-8u231-linux-x64.tar.gz /home/hadoop # 將檔案移動到 hadoop 使用者下
$ sudo tar -zxf /home/hadoop/jdk-8u231-linux-x64.tar.gz -C /usr/lib/ # 把JDK檔案解壓到/usr/lib目錄下
$ sudo mv /usr/lib/jdk1.8.0_231 /usr/lib/java # 重新命名java資料夾
$ vim ~/.bashrc # 配置環境變數,貌似EC2只能使用 vim新增如下內容:
export JAVA_HOME=/usr/lib/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH$ source ~/.bashrc # 讓配置檔案生效
$ java -version # 檢視 Java 是否安裝成功如果出現以下提示則表示安裝成功:

在 master 節點完成上述步驟後,在兩個 slave 節點完成同樣的步驟 (新增 hadoop 使用者、安裝 Java 環境)
網路配置
這一步是為了便於 Master 和 Slave 節點進行網路通訊,在配置前請先確定是以 hadoop 使用者登入的。首先修改各個節點的主機名,執行 sudo vim /etc/hostname ,在 master 節點上將 ip-xxx-xx-xx-xx 變更為 Master 。其他節點類似,在 slave01 節點上變更為 Slave01,slave02 節點上為 Slave02。
然後執行 sudo vim /etc/hosts 修改自己所用節點的IP對映,以 master 節點為例,新增紅色區域內資訊,注意這裡的 IP 地址是上文所述的私有 IP:

接著在兩個 slave 節點的hosts中新增同樣的資訊。完成後重啟一下,在進入 hadoop 使用者,能看到機器名的變化 (變成 Master 了):
對於 ec2 例項來說,還需要配置安全組 (Security groups),使例項能夠互相訪問 :

選擇劃線區域,我因為是同時建立了三臺例項,所以安全組都一樣,如果不是同時建立的,這可能三臺都要配置。
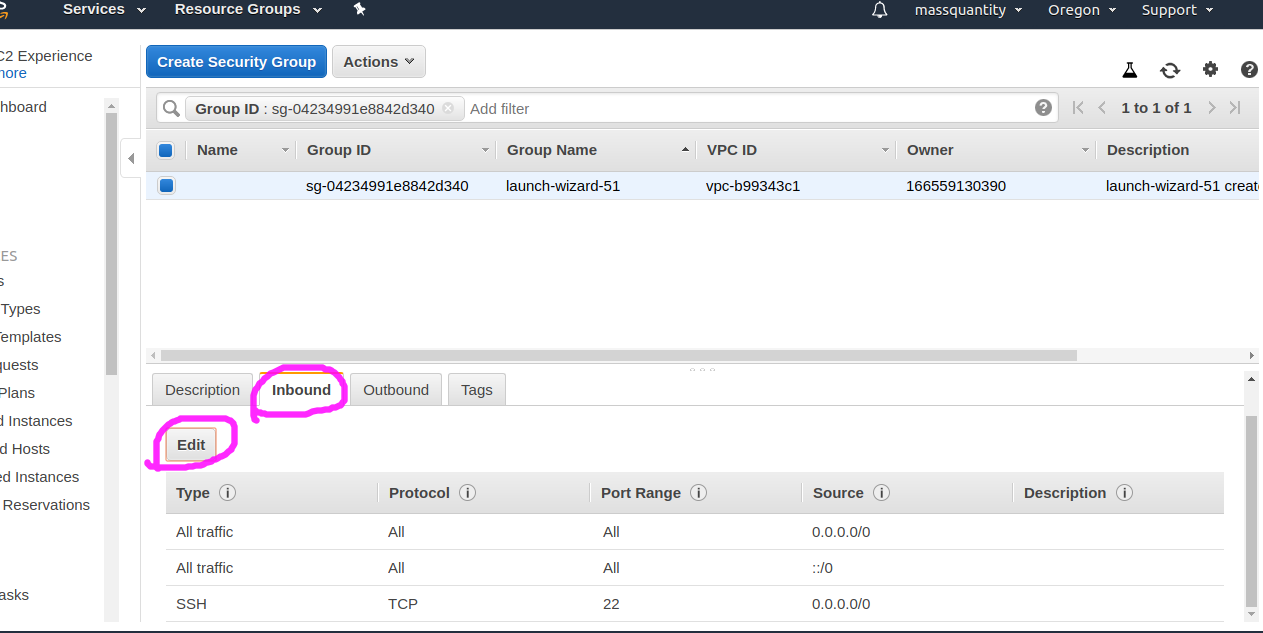
進入後點擊 Inbound 再點 Edit ,再點選 Add Rule,選擇裡面的 All Traffic ,接著儲存退出:

三臺例項都設定完成後,需要互相 ping 一下測試。如果 ping 不通,後面是不會成功的:
$ ping Master -c 3 # 分別在3臺機器上執行這三個命令
$ ping Slave01 -c 3
$ ping Slave02 -c 3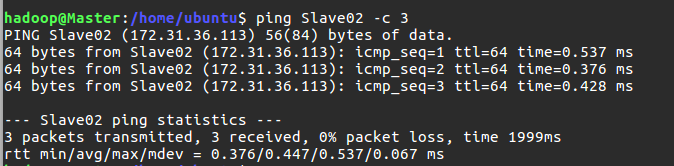
接下來安裝 SSH server, SSH 是一種網路協議,用於計算機之間的加密登入。安裝完 SSH 後,要讓 Master 節點可以無密碼 SSH 登陸到各個 Slave 節點上,在Master節點執行:
$ sudo apt-get install openssh-server
$ ssh localhost # 使用 ssh 登陸本機,需要輸入 yes 和 密碼
$ exit # 退出剛才的 ssh localhost, 注意不要退出hadoop使用者
$ cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
$ ssh-keygen -t rsa # 利用 ssh-keygen 生成金鑰,會有提示,瘋狂按回車就行
$ cat ./id_rsa.pub >> ./authorized_keys # 將金鑰加入授權
$ scp ~/.ssh/id_rsa.pub Slave01:/home/hadoop/ # 將金鑰傳到 Slave01 節點
$ scp ~/.ssh/id_rsa.pub Slave02:/home/hadoop/ # 將金鑰傳到 Slave02 節點接著在 Slave01和 Slave02 節點上,將 ssh 公匙加入授權:
$ mkdir ~/.ssh # 如果不存在該資料夾需先建立,若已存在則忽略
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys這樣,在 Master 節點上就可以無密碼 SSH 到各個 Slave 節點了,可在 Master 節點上執行如下命令進行檢驗,如下圖所示變為 Slave01了,再按 exit 可退回到 Master:
至此網路配置完成。
安裝 Hadoop
去到映象站 https://archive.apache.org/dist/hadoop/core/ 下載,我下載的是 hadoop-2.8.4.tar.gz 。在 Master 節點上執行:
$ sudo tar -zxf /home/ubuntu/hadoop-2.8.4.tar.gz -C /usr/lib # 解壓到/usr/lib中
$ cd /usr/lib/
$ sudo mv ./hadoop-2.8.4/ ./hadoop # 將資料夾名改為hadoop
$ sudo chown -R hadoop ./hadoop # 修改檔案許可權將 hadoop 目錄加到環境變數,這樣就可以在任意目錄中直接使用 hadoop、hdfs 等命令。執行 vim ~/.bashrc ,加入一行:
export PATH=$PATH:/usr/lib/hadoop/bin:/usr/lib/hadoop/sbin儲存後執行 source ~/.bashrc 使配置生效。
完成後開始修改 Hadoop 配置檔案(這裡也順便配置了 Yarn),先執行 cd /usr/lib/hadoop/etc/hadoop ,共有 6 個需要修改 —— hadoop-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1、檔案 hadoop-env.sh 中把 export JAVA_HOME=${JAVA_HOME} 修改為 export JAVA_HOME=/usr/lib/java ,即 Java 安裝路徑。
2、 檔案 slaves 把裡面的 localhost 改為 Slave01和 Slave02 。

3、core-site.xml 改為如下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/lib/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>4、hdfs-site.xml 改為如下配置:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/lib/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/lib/hadoop/tmp/dfs/data</value>
</property>
</configuration>5、檔案 mapred-site.xml (可能需要先重新命名,預設檔名為 mapred-site.xml.template):
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>6、檔案 yarn-site.xml :
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>配置好後,將 Master 上的 /usr/lib/hadoop 資料夾複製到各個 slave 節點上。在 Master 節點上執行:
$ cd /usr/lib
$ tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先壓縮再複製
$ scp ~/hadoop.master.tar.gz Slave01:/home/hadoop
$ scp ~/hadoop.master.tar.gz Slave02:/home/hadoop分別在兩個 slave 節點上執行:
$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/lib
$ sudo chown -R hadoop /usr/lib/hadoop安裝完成後,首次啟動需要先在 Master 節點執行 NameNode 的格式化:
$ hdfs namenode -format # 首次執行需要執行初始化,之後不需要成功的話,會看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若為 “Exitting with status 1” 則是出錯。

接著可以啟動 Hadoop 和 Yarn 了,啟動需要在 Master 節點上進行:
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh start historyserver通過命令 jps 可以檢視各個節點所啟動的程序。正確的話,在 Master 節點上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 程序,如下圖所示:

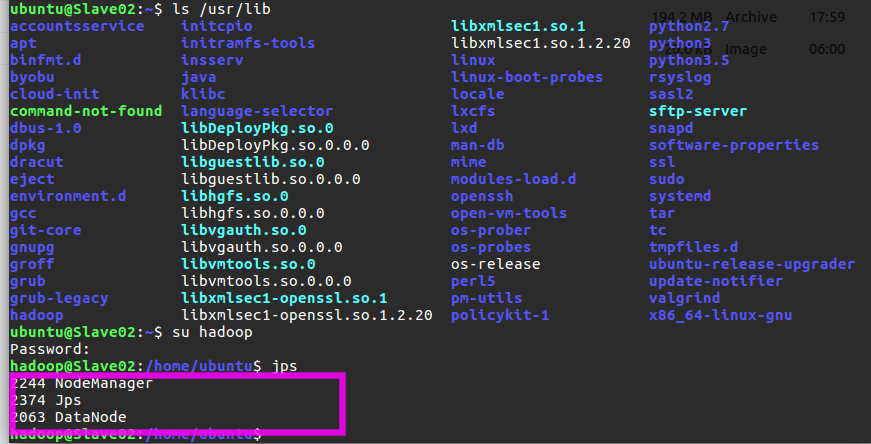
在 Slave 節點可以看到 DataNode 和 NodeManager 程序,如下圖所示:
通過命令 hdfs dfsadmin -report 可檢視叢集狀態,其中 Live datanodes (2) 表明兩個從節點都已正常啟動,如果是 0 則表示不成功:

可以通過下列三個地址檢視 hadoop 的 web UI,其中 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com 是該例項的外部 DNS 主機名,50070、8088、19888 分別是 hadoop、yarn、JobHistoryServer 的預設埠:
ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:50070
ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:8088
ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:19888
執行 Hadoop 分散式例項
$ hadoop fs -mkdir -p /user/hadoop # 在hdfs上建立hadoop賬戶
$ hadoop fs -mkdir input
$ hadoop fs -put /usr/lib/hadoop/etc/hadoop/*.xml input # 將hadoop配置檔案複製到hdfs中
$ hadoop jar /usr/lib/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+' # 執行例項如果成功可以看到以下輸出:


最後關閉 Hadoop 叢集需要執行以下命令:
$ stop-yarn.sh
$ stop-dfs.sh
$ mr-jobhistory-daemon.sh stop historyserver安裝 Spark
去到映象站 https://archive.apache.org/dist/spark/ 下載,由於之前已經安裝了Hadoop,所以我下載的是無 Hadoop 版本的,即 spark-2.3.3-bin-without-hadoop.tgz 。在 Master 節點上執行:
$ sudo tar -zxf /home/ubuntu/spark-2.3.3-bin-without-hadoop.tgz -C /usr/lib # 解壓到/usr/lib中
$ cd /usr/lib/
$ sudo mv ./spark-2.3.3-bin-without-hadoop/ ./spark # 將資料夾名改為spark
$ sudo chown -R hadoop ./spark # 修改檔案許可權將 spark 目錄加到環境變數,執行 vim ~/.bashrc 新增如下配置:
export SPARK_HOME=/usr/lib/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin儲存後執行 source ~/.bashrc 使配置生效。
接著需要配置了兩個檔案,先執行 cd /usr/lib/spark/conf 。
1、 配置 slaves 檔案
mv slaves.template slaves # 將slaves.template重新命名為slavesslaves檔案設定從節點。編輯 slaves 內容,把預設內容localhost替換成兩個從節點的名字:
Slave01
Slave022、配置 spark-env.sh 檔案
mv spark-env.sh.template spark-env.sh編輯 spark-env.sh 新增如下內容:
export SPARK_DIST_CLASSPATH=$(/usr/lib/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/lib/hadoop/etc/hadoop
export SPARK_MASTER_IP=172.31.40.68 # 注意這裡填的是Master節點的私有IP
export JAVA_HOME=/usr/lib/java配置好後,將 Master 上的 /usr/lib/spark 資料夾複製到各個 slave 節點上。在 Master 節點上執行:
$ cd /usr/lib
$ tar -zcf ~/spark.master.tar.gz ./spark
$ scp ~/spark.master.tar.gz Slave01:/home/hadoop
$ scp ~/spark.master.tar.gz Slave02:/home/hadoop然後分別在兩個 slave 節點上執行:
$ sudo tar -zxf ~/spark.master.tar.gz -C /usr/lib
$ sudo chown -R hadoop /usr/lib/spark在啟動 Spark 叢集之前,先確保啟動了 Hadoop 叢集:
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh start historyserver
$ start-master.sh # 啟動 spark 主節點
$ start-slaves.sh # 啟動 spark 從節點可通過 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:8080 訪問 spark web UI 。

執行 Spark 分散式例項
1、通過命令列提交 JAR 包:
$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://Master:7077 /usr/lib/spark/examples/jars/spark-examples_2.11-2.3.3.jar 100 2>&1 | grep "Pi is roughly" 結果如下說明成功:

2、通過 IDEA 遠端連線執行程式:
可以在 本地 IDEA 中編寫程式碼,遠端提交到雲端機上執行,這樣比較方便除錯。需要注意的是 Master 地址填雲端機的公有 IP 地址。下面以一個 WordVec 程式示例,將句子轉換為向量形式:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object Word2Vec {
def main(args: Array[String]) {
Logger.getLogger("org").setLevel(Level.ERROR) // 控制輸出資訊
Logger.getLogger("com").setLevel(Level.ERROR)
val conf = new SparkConf()
.setMaster("spark://ec2-54-190-51-132.us-west-2.compute.amazonaws.com:7077") // 填公有DNS或公有IP地址都可以
.setAppName("Word2Vec")
.set("spark.cores.max", "4")
.set("spark.executor.memory", "2g")
val sc = new SparkContext(conf)
val spark = SparkSession
.builder
.appName("Word2Vec")
.getOrCreate()
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.collect().foreach { case Row(text: Seq[_], features: Vector) =>
println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n") }
}
}IDEA 控制檯輸出:

關閉 Spark 和 Hadoop 叢集有以下命令:
$ stop-master.sh
$ stop-slaves.sh
$ stop-yarn.sh
$ stop-dfs.sh
$ mr-jobhistory-daemon.sh stop historyserver當然最後也是最重要的是,使用完後不要忘了關閉 EC2 例項,不然會 24 小時不間斷產生費用的。