
AI煉丹 - 深度學習必備庫 numpy
目錄
- 深度學習必備庫 - Numpy
- 1. 基礎資料結構ndarray陣列
- 1.1 為什麼引入ndarray陣列
- 1.2 如何建立ndarray陣列
- 1.3 ndarray 陣列的基本運算
- 1.4 ndarray陣列的索引和切片
- 1.5 ndarray陣列的統計計算
- 2. 隨機數np.random
- 2.1 建立隨機ndarray陣列
- 2.2 設定隨機種子
- 2.3 隨機打亂ndarray陣列順序
- 2.4 隨機選取元素
- 3. 線性代數操作
- 4. Numpy儲存與匯入檔案
- 5. Numpy應用舉例
- 5.1 計算啟用函式
- 5.2 影象處理
- 1. 基礎資料結構ndarray陣列
深度學習必備庫 - Numpy

Numpy是Numerical Python的簡稱,是Python中高效能科學計算和資料分析的基礎包。Numpy提供了一個多維陣列型別ndarray,它具有向量算術運算和複雜廣播的能力,可以實現快速的計算並且能節省儲存空間。
在本文中將會介紹:
1. 基礎資料結構ndarray陣列
ndarray陣列是Numpy中的基礎資料結構式, 本小結將介紹:
1.1 為什麼引入ndarray陣列
在Python中使用list列表可以非常靈活的處理多個元素的操作,但是其效率卻比較低。ndarray陣列相比於Python中的list列表具有以下特點:
ndarray陣列中所有元素的資料型別是相同的,資料地址是連續的,批量運算元組元素時速度更快;list列表中元素的資料型別可以不同,需要通過定址方式找到下一個元素
ndarray陣列中實現了比較成熟的廣播機制,矩陣運算時不需要寫for迴圈
Numpy底層是用c語言編寫的,內建了平行計算功能,執行速度高於純Python程式碼
例1. ndarray陣列和list列表分別完成對每個元素增加1的計算
# Python原生的list
# 假設有兩個list
a = [1, 2, 3, 4, 5]
b = [2, 3, 4, 5, 6]
# 完成如下計算
# 1 對a的每個元素 + 1
# a = a + 1 不能這麼寫,會報錯
# a[:] = a[:] + 1 也不能這麼寫,也會報錯
for i in range(5):
a[i] = a[i] + 1
a
[2, 3, 4, 5, 6]
########################################################
# 使用ndarray
import numpy as np
a = np.array([1, 2, 3, 4, 5])
a = a + 1
a
array([2, 3, 4, 5, 6])例2. ndarray陣列和list列表分別完成相加計算
# 計算 a和b中對應位置元素的和,是否可以這麼寫? python中的+運算?
a = [1, 2, 3, 4, 5]
b = [2, 3, 4, 5, 6]
c = a + b
# 檢查輸出發現,不是想要的結果
c
[1, 2, 3, 4, 5, 2, 3, 4, 5, 6]
########################################################
# 使用for迴圈,完成兩個list對應位置元素相加
c = []
for i in range(5):
c.append(a[i] + b[i])
c
[3, 5, 7, 9, 11]
#########################################################
# 使用numpy中的ndarray完成兩個ndarray相加
import numpy as np
a = np.array([1, 2, 3, 4, 5])
b = np.array([2, 3, 4, 5, 6])
c = a + b
c
array([ 3, 5, 7, 9, 11])ndarray陣列的向量計算能力使得不需要寫for迴圈,就可以非常方便的完成數學計算,在操作向量或者矩陣時,可以像操作普通的數值變數一樣編寫程式,使得程式碼極其簡潔。
另外,ndarray陣列還提供了廣播機制: 當兩個陣列的形狀並不相同的時候,可以通過擴充套件陣列的方法來實現相加、相減、相乘等操作,簡單點理解就是兩個陣列中,從末尾開始計算,陣列的維度符合運算要求(後緣維度),就可以進行計算。
例3. 廣播機制,1維陣列和2維陣列相加
# 二維陣列維度 2x5
# array([[ 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10]])
d = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]])
# c是一維陣列,維度5
# array([ 4, 6, 8, 10, 12])
c = np.array([ 4, 6, 8, 10, 12])
e = d + c
e
array([[ 5, 8, 11, 14, 17],
[10, 13, 16, 19, 22]])1.2 如何建立ndarray陣列
- 從list列表開始建立
- 指定起止範圍及間隔建立
- 建立值全為0的ndarray陣列
- 建立值全為1的ndarray陣列
例4. 建立ndarray的幾種常見方法
import numpy as np
# 從list建立array
a = [1,2,3,4,5,6]
b = np.array(a)
b
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
#########################################################
# 通過np.array建立
# 通過指定start, stop (不包括stop),interval來產生一個1為的ndarray
# 類似於python中常用的range函式,用法一致
a = np.arange(0, 20, 2)
a
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
#########################################################
# 建立全0的ndarray
a = np.zeros([3,3]) # 注意此處為zeros,[],()都可以
# a = np.zeros((3,3))
a
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
#########################################################
# 建立全1的ndarray
a = np.ones([3,3])
a
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
#########################################################
# 建立單位矩陣的ndarray
a = np.eyes(3) # 因為單位矩陣,所以是eye,只需傳入一個引數
a
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])檢視ndarray陣列的屬性
ndarray的屬性包括形狀shape、資料型別dtype、元素個數size和維度ndim等,下面的程式展示如何檢視這些屬性
例5. 檢視ndarray屬性
# 陣列的資料型別 ndarray.dtype
# 陣列的形狀 ndarray.shape,1維陣列(N, ),二維陣列(M, N),三維陣列(M, N, K)
# 陣列的維度大小,ndarray.ndim, 其大小等於ndarray.shape所包含元素的個數
# 陣列中包含的元素個數 ndarray.size,其大小等於各個維度的長度的乘積
a = np.ones([3, 3])
print('a, dtype: {}, shape: {}, size: {}, ndim: {}'.format(a.dtype, a.shape, a.size, a.ndim))
a, dtype: float64, shape: (3, 3), size: 9, ndim: 2例6. 改變ndarray陣列的資料型別和形狀
# 轉化資料型別
# 不同資料型別的陣列可以進行計算,但計算完之後的結果會改變
a = np.ones((3, 3))
b = a.astype(np.int64)
c = a.astype(np.float32)
d = b + c
print('b, dtype: {}, shape: {}'.format(b.dtype, b.shape))
print('c, dtype: {}, shape: {}'.format(c.dtype, c.shape))
print('d, dtype: {}, shape: {}'.format(d.dtype, d.shape))
b, dtype: int64, shape: (3, 3)
c, dtype: float32, shape: (3, 3)
d, dtype: float64, shape: (3, 3)
#######################################################
# 改變形狀
c = a.reshape([1, 9])
print('c, dtype: {}, shape: {}'.format(c.dtype, c.shape))
1.3 ndarray 陣列的基本運算
ndarray陣列可以像普通的數值型變數一樣進行加減乘除操作,這一小節將介紹兩種形式的基本運算:
- 標量和ndarray陣列之間的運算
- 兩個ndarray陣列之間的運算
例7. 標量和ndarray陣列之間的運算
# 標量除以陣列,用標量除以陣列的每一個元素
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
1. / arr
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
#######################################################
# 標量乘以陣列,用標量乘以陣列的每一個元素
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
2.0 * arr
array([[ 2., 4., 6.],
[ 8., 10., 12.]])
#######################################################
# 標量加上陣列,用標量加上陣列的每一個元素
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
2.0 + arr
array([[3., 4., 5.],
[6., 7., 8.]])
#######################################################
# 標量減去陣列,用標量減去陣列的每一個元素
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
2.0 - arr
array([[ 1., 0., -1.],
[-2., -3., -4.]])例8. 兩個ndarray陣列之間的運算
# 陣列 減去 陣列, 用對應位置的元素相減
arr1 = np.array([[1., 2., 3.], [4., 5., 6.]])
arr2 = np.array([[11., 12., 13.], [21., 22., 23.]])
arr1 - arr2
array([[12., 14., 16.],
[25., 27., 29.]])
#######################################################
# 陣列 乘以 陣列,用對應位置的元素相乘
arr1 * arr2
array([[ 11., 24., 39.],
[ 84., 110., 138.]])
#######################################################
# 陣列開根號,將每個位置的元素都開根號
arr ** 0.5
array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974]])
1.4 ndarray陣列的索引和切片
在程式中,通常需要訪問或者修改ndarray陣列某個位置的元素,也就是要用到ndarray陣列的索引;有些情況下可能需要訪問或者修改一些區域的元素,則需要使用陣列的切片。索引和切片的使用方式與Python中的list類似,ndarray陣列可以基於 -n ~ n-1 的下標進行索引,切片物件可以通過內建的 slice 函式,並設定 start, stop 及 step 引數進行,從原陣列中切割出一個新陣列。
例9. ndarray陣列索引和切片
# 1維陣列索引和切片
a = np.arange(30)
a[10] # 從0開始計算第10號位置
10
#######################################################
a = np.arange(30)
b = a[4:7]
b
array([4, 5, 6])
#######################################################
# 將一個標量值賦值給一個切片時,該值會自動傳播到整個選區(如下圖所示)
# 切片並不是生成一列新的陣列,而僅僅只把其中一段拿出來操作,對切片的操作會影響原始資料
a = np.arange(30)
a[4:7] = 10
a
array([ 0, 1, 2, 3, 10, 10, 10, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29])
#######################################################
# 陣列切片是原始陣列的檢視。這意味著資料不會被複制,
# 檢視上的任何修改都會直接反映到源陣列上
a = np.arange(30)
arr_slice = a[4:7]
arr_slice[0] = 100
a, arr_slice
(array([ 0, 1, 2, 3, 100, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29]), array([100, 5, 6]))
#######################################################
# 通過copy給新陣列建立不同的記憶體空間
a = np.arange(30)
arr_slice = a[4:7]
arr_slice = np.copy(arr_slice)
arr_slice[0] = 100
a, arr_slice
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]),
array([100, 5, 6]))
#######################################################
# 多維陣列索引和切片
a = np.arange(30)
arr3d = a.reshape(5, 3, 2) # 可以理解為按從大塊往小塊分
arr3d
array([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]],
[[12, 13],
[14, 15],
[16, 17]],
[[18, 19],
[20, 21],
[22, 23]],
[[24, 25],
[26, 27],
[28, 29]]])
#######################################################
# 只有一個索引指標時,會在第0維上索引,後面的維度保持不變
arr3d[0]
array([[0, 1],
[2, 3],
[4, 5]])
# 兩個索引指標
arr3d[0][1]
array([2, 3])
1.5 ndarray陣列的統計計算
例10. ndarray的陣列統計運算:
- mean 均值
- std 標準差
- var 方差
- sum 求和
- max 最大值
- min 最小值
# 計算均值,使用arr.mean() 或 np.mean(arr),二者是等價的
arr = np.array([[1,2,3], [4,5,6], [7,8,9]])
arr.mean(), np.mean(arr)
(5.0, 5.0)
# 求和
arr.sum(), np.sum(arr)
(45, 45)
# 求最大值
arr.max(), np.max(arr)
(9, 9)
# 求最小值
arr.min(), np.min(arr)
(1, 1)
#######################################################
# 指定計算的維度
# axis = 0 表示列
# axis = 1 表示行
# 沿著第1維求平均,也就是將[1, 2, 3]取平均等於2,[4, 5, 6]取平均等於5,[7, 8, 9]取平均等於8
arr.mean(axis = 1)
array([2., 5., 8.])
# 沿著第0維求和,也就是將[1, 4, 7]求和等於12,[2, 5, 8]求和等於15,[3, 6, 9]求和等於18
arr.sum(axis=0)
array([12, 15, 18])
# 沿著第0維求最大值,也就是將[1, 4, 7]求最大值等於7,[2, 5, 8]求最大值等於8,[3, 6, 9]求最大值等於9
arr.max(axis=0)
array([7, 8, 9])
# 沿著第1維求最小值,也就是將[1, 2, 3]求最小值等於1,[4, 5, 6]求最小值等於4,[7, 8, 9]求最小值等於7
arr.min(axis=1)
array([1, 4, 7])
# 計算標準差
arr.std()
2.581988897471611
# 計算方差
arr.var()
6.666666666666667
# 找出最大元素的索引
arr.argmax(), arr.argmax(axis=0), arr.argmax(axis=1)
(8, array([2, 2, 2]), array([2, 2, 2]))
# 找出最小元素的索引
arr.argmin(), arr.argmin(axis=0), arr.argmin(axis=1)
(0, array([0, 0, 0]), array([0, 0, 0]))
2. 隨機數np.random
2.1 建立隨機ndarray陣列
例10. 建立隨機陣列
# 生成均勻分佈隨機數,隨機數取值範圍在[0, 1)之間
a = np.random.rand(3, 3)
a
array([[0.08833981, 0.68535982, 0.95339335],
[0.00394827, 0.51219226, 0.81262096],
[0.61252607, 0.72175532, 0.29187607]])
# 生成均勻分佈隨機數,指定隨機數取值範圍和陣列形狀
a = np.random.uniform(low = -1.0, high = 1.0, size=(2,2))
a
array([[ 0.83554825, 0.42915157],
[ 0.08508874, -0.7156599 ]])
# 生成標準正態分佈隨機數
a = np.random.randn(3, 3)
a
array([[ 1.484537 , -1.07980489, -1.97772828],
[-1.7433723 , 0.26607016, 2.38496733],
[ 1.12369125, 1.67262221, 0.09914922]])
# 生成正態分佈隨機數,指定均值loc和方差scale
a = np.random.normal(loc = 1.0, scale = 1.0, size = (3,3))
a
array([[2.39799638, 0.72875201, 1.61320418],
[0.73268281, 0.45069099, 1.1327083 ],
[0.52385799, 2.30847308, 1.19501328]])2.2 設定隨機種子
例11. 隨機種子
# 可以多次執行,觀察程式輸出結果是否一致
# 如果不設定隨機數種子,觀察多次執行輸出結果是否一致
np.random.seed(10)
a = np.random.rand(3, 3)
a
array([[0.77132064, 0.02075195, 0.63364823],
[0.74880388, 0.49850701, 0.22479665],
[0.19806286, 0.76053071, 0.16911084]])2.3 隨機打亂ndarray陣列順序
# 生成一維陣列
a = np.arange(0, 30)
# 打亂一維陣列順序
print('before random shuffle: ', a)
np.random.shuffle(a)
print('after random shuffle: ', a)
('before random shuffle: ', array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]))
('after random shuffle: ', array([10, 21, 26, 7, 0, 23, 2, 17, 18, 20, 12, 6, 9, 3, 25, 5, 13,
14, 24, 29, 1, 28, 11, 15, 27, 16, 19, 4, 22, 8]))
# 生成一維陣列
a = np.arange(0, 30)
# 將一維陣列轉化成2維陣列
a = a.reshape(10, 3)
# 打亂一維陣列順序
print('before random shuffle: \n{}'.format(a))
np.random.shuffle(a)
print('after random shuffle: \n{}'.format(a))
before random shuffle:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
[12 13 14]
[15 16 17]
[18 19 20]
[21 22 23]
[24 25 26]
[27 28 29]]
after random shuffle:
[[15 16 17]
[12 13 14]
[27 28 29]
[ 3 4 5]
[ 9 10 11]
[21 22 23]
[18 19 20]
[ 0 1 2]
[ 6 7 8]
[24 25 26]]2.4 隨機選取元素
例12. 隨機選取元素
# 隨機選取一選部分元素
a = np.arange(30)
b = np.random.choice(a, size=5)
b
array([ 0, 24, 12, 5, 4])3. 線性代數操作
Numpy中實現了線性代數中常用的各種操作,並形成了numpy.linalg線性代數相關的模組。其中包括:
- diag 以一維陣列的形式返回方陣的對角線(或非對角線)元素,或將一維陣列轉換為方陣(非對角線元素為0)
- dot 矩陣乘法
- trace 計算對角線元素的和
- det 計算矩陣行列式
- eig 計算方陣的特徵值和特徵向量
- inv 計算方陣的逆
例13. numpy的線性代數操作
# 矩陣相乘
a = np.arange(12)
b = a.reshape([3, 4])
c = a.reshape([4, 3])
# 矩陣b的第二維大小,必須等於矩陣c的第一維大小
d = b.dot(c) # 等價於 np.dot(b, c)
print('a: \n{}'.format(a))
print('b: \n{}'.format(b))
print('c: \n{}'.format(c))
print('d: \n{}'.format(d))
a:
[ 0 1 2 3 4 5 6 7 8 9 10 11]
b:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
c:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
d:
[[ 42 48 54]
[114 136 158]
[186 224 262]]
# numpy.linalg 中有一組標準的矩陣分解運算以及諸如求逆和行列式之類的東西
# np.linalg.diag 以一維陣列的形式返回方陣的對角線(或非對角線)元素,
# 或將一維陣列轉換為方陣(非對角線元素為0)
e = np.diag(d)
f = np.diag(e)
print('d: \n{}'.format(d))
print('e: \n{}'.format(e))
print('f: \n{}'.format(f))
d:
[[ 42 48 54]
[114 136 158]
[186 224 262]]
e:
[ 42 136 262]
f:
[[ 42 0 0]
[ 0 136 0]
[ 0 0 262]]
# trace, 計算對角線元素的和
g = np.trace(d)
g
440
# det,計算行列式
h = np.linalg.det(d)
h
1.3642420526593978e-11
# eig,計算特徵值和特徵向量
i = np.linalg.eig(d)
i
(array([4.36702561e+02, 3.29743887e+00, 3.13152204e-14]),
array([[ 0.17716392, 0.77712552, 0.40824829],
[ 0.5095763 , 0.07620532, -0.81649658],
[ 0.84198868, -0.62471488, 0.40824829]]))
# inv,計算方陣的逆
tmp = np.random.rand(3, 3)
j = np.linalg.inv(tmp)
j
array([[-0.59449952, 1.39735912, -0.06654123],
[ 1.56034184, -0.40734618, -0.48055062],
[ 0.10659811, -0.62164179, 1.30437759]])4. Numpy儲存與匯入檔案
例14. numpy檔案操作
# 使用np.fromfile從文字檔案'housing.data'讀入資料
# 這裡要設定引數sep = ' ',表示使用空白字元來分隔資料
# 空格或者回車都屬於空白字元,讀入的資料被轉化成1維陣列
d = np.fromfile('./work/housing.data', sep = ' ')
d
array([6.320e-03, 1.800e+01, 2.310e+00, ..., 3.969e+02, 7.880e+00,
1.190e+01])
# Numpy還提供了save和load介面,直接將陣列儲存成檔案(儲存為.npy格式),或者從.npy檔案中讀取陣列
# 產生隨機陣列a
a = np.random.rand(3,3)
np.save('a.npy', a)
# 從磁碟檔案'a.npy'讀入陣列
b = np.load('a.npy')
5. Numpy應用舉例
5.1 計算啟用函式
例15. 計算啟用函式
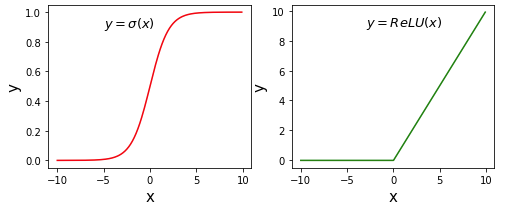
使用ndarray陣列可以很方便的構建數學函式,而且能利用其底層的向量計算能力快速實現計算。神經網路中比較常用啟用函式是Sigmoid和ReLU,其定義如下。

下面使用numpy和matplotlib計算函式值並畫出圖形
# ReLU和Sigmoid啟用函式示意圖
import numpy as np
# %matplotlib inline # 在Jupyter notebook 中在圖框中顯示
import matplotlib.pyplot as plt
import matplotlib.patches as patches
#設定圖片大小
plt.figure(figsize=(8, 3))
# x是1維陣列,陣列大小是從-10. 到10.的實數,每隔0.1取一個點
x = np.arange(-10, 10, 0.1)
# 計算 Sigmoid函式
s = 1.0 / (1 + np.exp(- x))
# 計算ReLU函式
# clip 函式, x表示輸入的值, a_min表示小於a_min都賦值為a_min; a_max同理; None表示不進行操作。
y = np.clip(x, a_min = 0., a_max = None)
#########################################################
# 以下部分為畫圖程式
# 設定兩個子圖視窗,將Sigmoid的函式影象畫在左邊
# 121 表示 一行2列, 佔第一列
f = plt.subplot(121)
# 畫出函式曲線
plt.plot(x, s, color='r')
# 新增文字說明
plt.text(-5., 0.9, r'$y=\sigma(x)$', fontsize=13)
# 設定座標軸格式
currentAxis=plt.gca()
currentAxis.xaxis.set_label_text('x', fontsize=15)
currentAxis.yaxis.set_label_text('y', fontsize=15)
# 將ReLU的函式影象畫在左邊
# 122 表示 一行2列, 佔第二列
f = plt.subplot(122)
# 畫出函式曲線
plt.plot(x, y, color='g')
# 新增文字說明
plt.text(-3.0, 9, r'$y=ReLU(x)$', fontsize=13)
# 設定座標軸格式
currentAxis=plt.gca()
currentAxis.xaxis.set_label_text('x', fontsize=15)
currentAxis.yaxis.set_label_text('y', fontsize=15)
plt.show()
5.2 影象處理
例16. 影象翻轉和裁剪
影象是由畫素點構成的矩陣,其數值可以用ndarray來表示。可以將上面章節中介紹的操作用在影象資料對應的ndarray上,並且通過影象直觀的展示出它的效果來。
# 匯入需要的包
# 後續會有教程解釋 matplotlib 和 PIL 這兩個庫
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
# 讀入圖片
image = Image.open('./car.jpg') # 可改成絕對路徑
image = np.array(image)
# 檢視資料形狀,其形狀是[H, W, 3],
# 其中H代表高度, W是寬度,3代表RGB三個通道
plt.imshow(image)(612, 612, 3)

# 垂直方向翻轉
# 這裡使用陣列切片的方式來完成,
# 相當於將圖片最後一行挪到第一行,
# 倒數第二行挪到第二行,...,
# 第一行挪到倒數第一行
# 對於行指標,使用::-1來表示切片,
# 負數步長表示以最後一個元素為起點,向左走尋找下一個點
# 對於列指標和RGB通道,僅使用:表示該維度不改變
image2 = image[::-1, :, :]
plt.imshow(image2)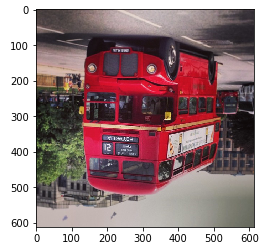
# 水平方向翻轉
image3 = image[:, ::-1, :]
plt.imshow(image3)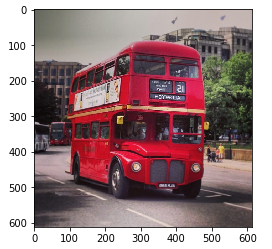
# 儲存圖片
im3 = Image.fromarray(image3)
im3.save('im3.jpg')# 高度方向裁剪
H, W = image.shape[0], image.shape[1]
# 注意此處用整除,H_start必須為整數
H1 = H // 2
H2 = H
image4 = image[H1:H2, :, :]
plt.imshow(image4)
# 調整亮度
image6 = image * 0.5
plt.imshow(image6.astype('uint8'))
#間隔行列取樣,影象尺寸會減半,清晰度變差
image10 = image[::2, ::2, :]
plt.imshow(image10)
image10.shape(306, 306, 3)

相關推薦
AI煉丹 - 深度學習必備庫 numpy
目錄 深度學習必備庫 - Numpy 1. 基礎資料結構ndarray陣列 1.1 為什麼引入ndarray陣列 1.2 如何建立ndarray陣列 1.3 ndarray 陣列的基本運算
python數據可視化、數據挖掘、機器學習、深度學習 常用庫、IDE等
深度學習 貝葉斯 int clip plot 隨機森林 isp mean notebook 一、可視化方法 條形圖 餅圖 箱線圖(箱型圖) 氣泡圖 直方圖 核密度估計(KDE)圖 線面圖 網絡圖 散點圖 樹狀圖 小提琴圖 方形圖 三維圖
圖像識別VPU——易用的嵌入式AI支持深度學習平臺介紹
dem 解碼 控制 令行 好的 測距 輕松 分析 ada 公司玩了大半年的嵌入式AI平臺,現在產品進入量產模式,也接觸了很多嵌入式方案,有了一些心得體會,本人不才,在這裏介紹一下一款簡單易用的嵌入式AI方案——Movidius Myriad 2 VPU(MA2450) 和
更快更強,深度學習新庫fastai“落戶”PyTorch
幾天前,有人統計了歷年ICLR論文錄用者使用的深度學習框架,發現雖然TensorFlow還高居榜首,但PyTorch近一年來的使用資料已經翻了3倍,可以和TF比肩。這是個令人驚訝的訊息,也讓不少從業者開始正視這一發展趨勢,籌備“雙修”事宜。在下文中,論智給讀者帶來的是fast.ai釋出的一個簡便、好用的P
深度學習必備基礎知識
線性分類器 1.線性分類器得分函式 CIFAR-10:一
AI-041: Python深度學習3 - 三個Karas例項-3
例項3: 通過波士頓的房屋資料預測房價 這是一個迴歸問題,因為最終輸出的房價是一個連續值。 載入資料: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_t
AI-040: Python深度學習3 - 三個Karas例項-2
例項2: 通過路透社資料集來將文字區分46個不同主題 這裡與上一個例項不同的地方:這是個多元分類問題,因此最終輸出是46維向量 載入資料 from keras.datasets import reuters (train_data, train_labels), (test_data
Ubuntu14.04上深度學習Caffe庫安裝指南(CUDA7.5 + opencv3.1)
Ubuntu14.04上Caffe安裝指南 安裝的準備工作 首先,安裝官方版Caffe時,如果要使用Cuda,需要確認自己確實有NVIDIA GPU。 安裝Ubuntu時,將/boot 分割槽分大概200M左右,太小了會導致升級系統時/boot空間不足
【深度學習】基於Numpy實現的神經網路進行手寫數字識別
直接先用前面設定的網路進行識別,即進行推理的過程,而先忽視學習的過程。 推理的過程其實就是前向傳播的過程。 深度學習也是分成兩步:學習 + 推理。學習就是訓練模型,更新引數;推理就是用學習到的引數來處理新的資料。 from keras.datasets.mnist impor
吳恩達Coursera深度學習課程 deeplearning.ai (2-1) 深度學習實踐--程式設計作業
初始化 一個好的初始化可以做到: 梯度下降的快速收斂 收斂到的對訓練集只有較少錯誤的值 載入資料 import numpy as np import matplotlib.pyplot as plt import sklearn impo
[深度學習][CS231n] Python Numpy教程
十一七天樂,翻譯自 http://cs231n.github.io/python-numpy-tutorial/ 屬於CS231n Convolutional Neural Networks for Visual Recognition課程中關於Python和numpy的科普教程
深度學習必備:隨機梯度下降(SGD)優化演算法及視覺化
補充在前:實際上在我使用LSTM為流量基線建模時候,發現有效的啟用函式是elu、relu、linear、prelu、leaky_relu、softplus,對應的梯度演算法是adam、mom、rmsprop、sgd,效果最好的組合是:prelu+rmsprop。我的程式碼如下: # Simple examp
【火爐煉AI】深度學習001-神經網路的基本單元-感知器
【火爐煉AI】深度學習001-神經網路的基本單元-感知器 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2 ) 在人工智慧領域,深度學習已經脫穎而出,越來越成為大型複雜問題的首選解決方案。深度學習相對
【火爐煉AI】深度學習002-構建並訓練單層神經網路模型
【火爐煉AI】深度學習002-構建並訓練單層神經網路模型 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2 ) 前面我們介紹了神經網路的基本結構單元-感知器,現在我們再升一級,看看神經網路的基本結構和
【火爐煉AI】深度學習003-構建並訓練深度神經網路模型
【火爐煉AI】深度學習003-構建並訓練深度神經網路模型 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2 ) 前面我們講解過單層神經網路模型,發現它結構簡單,難以解決一些實際的比較複雜的問題,故而現
【火爐煉AI】深度學習004-Elman迴圈神經網路
【火爐煉AI】深度學習004-Elman迴圈神經網路 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2 ) Elman神經網路是最早的迴圈神經網路,由Elman於1990年提出,又稱為SRN(Simp
【火爐煉AI】深度學習005-簡單幾行Keras代碼解決二分類問題
director flat 如何 次數 模型訓練 全連接 assert dog otl 【火爐煉AI】深度學習005-簡單幾行Keras代碼解決二分類問題 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.
【火爐煉AI】深度學習005-簡單幾行Keras程式碼解決二分類問題
【火爐煉AI】深度學習005-簡單幾行Keras程式碼解決二分類問題 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2, Keras 2.1.6, Tensorflow 1.9.0) 很多文章和教材都
【火爐煉AI】深度學習006-移花接木-用Keras遷移學習提升效能
【火爐煉AI】深度學習006-移花接木-用Keras遷移學習提升效能 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2, Keras 2.1.6, Tensorflow 1.9.0) 上一篇文章我們用
【火爐煉AI】深度學習007-Keras微調進一步提升效能
【火爐煉AI】深度學習007-Keras微調進一步提升效能 (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2, Keras 2.1.6, Tensorflow 1.9.0) 本文使用微調(Fine-t