
Caffe原始碼-幾種優化演算法
SGD簡介
caffe中的SGDSolver類中實現了帶動量的梯度下降法,其原理如下,$lr$為學習率,$m$為動量引數。
- 計算新的動量:
history_data = local_rate * param_diff + momentum * history_data
$\nu_{t+1}=lr\nabla_{\theta_{t}}+m\nu_{t}$ - 計算更新時使用的梯度:
param_diff = history_data
$\Delta\theta_{t+1}=\nu_{t+1}$ - 應用更新:
param_data = param_data - param_diff
$\theta_{t+1}=\theta_{t}-\Delta\theta_{t+1}$
步驟1和步驟2均在SGDSolver類的ComputeUpdateValue()函式中實現,步驟3對每個優化方法來說都是相同的,程式碼可參考之前的部落格:Caffe原始碼-SGDSolver類。
NAG(Nesterov Accelerated Gradient)簡介
NAG演算法在NesterovSolver類中實現,NAG與SGD相比唯一區別在於梯度的計算上。如上,SGD使用的梯度是引數$\theta_{t}$在當前位置的梯度$\nabla_{\theta_{t}}$,而NAG中使用的是當前引數$\theta_{t}$在施加了動量之後的位置的梯度$\nabla_{(\theta_{t}-m*\nu_{t})}$,其原理為:
- 應用臨時更新:$\tilde{\theta}{t+1}=\theta{t}-m*\nu_{t}$
- 計算該位置的梯度:$\nabla_{\tilde{\theta}_{t+1}}$
- 計算新的動量:$\nu_{t+1}=lr*\nabla_{\tilde{\theta}_{t+1}}+m*\nu_{t}$
- 得到更新時使用的梯度:$\Delta\theta_{t+1}=\nu_{t+1}$
- 應用更新:$\theta_{t+1}=\theta_{t}-\Delta\theta_{t+1}$
網路上有一張常見的圖用於表示SGD和NAG的過程。
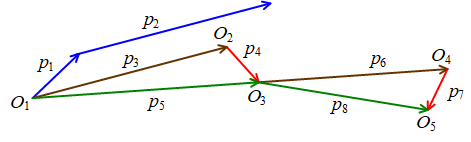
對於SGD演算法,藍色向量$p_{1}$為當前引數$\theta_{t}$在該位置的梯度$lr\nabla_{\theta_{t}}$,藍色向量$p_{2}$為動量$m
對於NAG演算法,$O_{1}$為引數$\theta_{t}$的初始位置,棕色向量$p_{3}=p_{2}$,先計算運用動量後的引數$\tilde{\theta}{t+1}$的位置$O{2}$,然後計算該位置梯度$\nabla_{\tilde{\theta}{t+1}}$,即為圖中的紅色向量$p{4}$,而$p_{5}=p_{3}+p_{4}$即為引數一次的更新量$\Delta\theta_{t+1}=\nu_{t+1}$。之後仿照該步驟計算下一次迭代的動量$m*\nu_{t+1}$(棕色向量$p_{6}$)和梯度$\nabla_{\tilde{\theta}{t+2}}$(紅色向量$p{7}$),得到更新量$p_{8}$。
NAG演算法的原理還是很好理解的,但是實現起來卻有一個非常難理解的地方,即如何計算引數臨時更新位置的梯度$\nabla_{\tilde{\theta}{t+1}}$?神經網路這種複雜的系統中想要根據當前位置的梯度$\nabla{\theta_{t}}$來估算另一位置的梯度$\nabla_{\tilde{\theta}{t+1}}$幾乎是不可能的。網路上關於該演算法的實現細節非常少,不過結合caffe程式碼和其他的開原始碼等,可以判斷出,NAG演算法每次迭代時儲存的引數是臨時引數$\tilde{\theta}{t+1}$(位置$O_{2}$),而非初始$O_{1}$位置處的引數$\theta_{t}$,這樣每次反向傳播計算出的梯度實際上就是紅色向量$p_{4}$。然後每次更新時,會根據動量$p_{3}$先將引數從位置$O_{2}$退回$O_{1}$,然後計算得到一次迭代的更新量$p_{5}$,使引數更新$\theta_{t+1}$(位置$O_{3}$),並儲存下一次迭代時需要使用的臨時引數$\tilde{\theta}{t+2}$(位置$O{4}$)。
nesterov_solver.cpp原始碼
//根據當前迭代次數對應的學習率rate,計算網路中第param_id個可學習引數在更新時使用的梯度
template <typename Dtype>
void NesterovSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params(); //網路中的所有可學習引數
const vector<float>& net_params_lr = this->net_->params_lr(); //網路中每個引數對應的學習率係數
Dtype momentum = this->param_.momentum(); //求解器設定的動量
Dtype local_rate = rate * net_params_lr[param_id]; //得到當前引數對應的學習率
switch (Caffe::mode()) {
case Caffe::CPU: { //CPU模式
// save history momentum for stepping back
caffe_copy(net_params[param_id]->count(), this->history_[param_id]->cpu_data(),
this->update_[param_id]->mutable_cpu_data()); //將歷史資料history_拷貝至update_中,update_data = history_data
// update history //history_data = local_rate * net_params_diff + momentum * history_data
caffe_cpu_axpby(net_params[param_id]->count(), local_rate, net_params[param_id]->cpu_diff(), momentum,
this->history_[param_id]->mutable_cpu_data());
// compute update: step back then over step //update_data = (1 + momentum) * history_data + (-momentum) * update_data
caffe_cpu_axpby(net_params[param_id]->count(), Dtype(1) + momentum,
this->history_[param_id]->cpu_data(), -momentum,
this->update_[param_id]->mutable_cpu_data());
// copy //net_params_diff = update_data
caffe_copy(net_params[param_id]->count(), this->update_[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
break;
}
case Caffe::GPU: {
#ifndef CPU_ONLY
// gpu的操作同理
// h_temp = history_data
// history_data = momentum * h_temp + local_rate * net_params_diff
// net_params_diff = (1+momentum) * history_data - momentum * h_temp
nesterov_update_gpu(net_params[param_id]->count(), net_params[param_id]->mutable_gpu_diff(),
this->history_[param_id]->mutable_gpu_data(), momentum, local_rate);
#else
NO_GPU;
#endif
break;
}
default:
LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
}
}對應上述的說明,程式碼中的各步操作為:
- 當前迭代的動量$\nu_{t}$:
update_data = history_data net_params_diff為臨時位置的引數的梯度$\nabla_{\tilde{\theta}{t+1}}$,計算新的動量:history_data = local_rate * net_params_diff + momentum * history_data
$\nu{t+1}=lr*\nabla_{\tilde{\theta}_{t+1}}+m*\nu_{t}$- 計算下一次迭代的臨時引數相對於當前臨時引數的更新量$\Delta\tilde{\theta}{t+2}$:
update_data = (1 + momentum) * history_data + (-momentum) * update_data
$\Delta\tilde{\theta}{t+2}=(1+m)\nu_{t+1}-m\nu_{t}$
注意,當前臨時引數在位置$O_{2}$,需要減去向量$p_{3}$($p_{3}=m\nu_{t}$),再加上向量$p_{5}$和$p_{6}$($p_{5}=\nu_{t+1},p_{6}=m\nu_{t+1}$)才能得到新的臨時位置$O_{4}$。 - 儲存引數更新量:
net_params_diff = update_data - 應用更新:$\tilde{\theta}{t+2}=\tilde{\theta}{t+1}-\Delta\tilde{\theta}_{t+2}$
AdaGrad簡介
AdaGrad演算法通過縮放每個引數反比於其所有梯度歷史平方值總和的平方跟,可使得具有較大梯度的引數能夠快速下降,使具有小偏導的引數能夠緩慢下降。
其原理如下,初始累積變數$r=0$,$\delta$為較小常數,防止除法除數過小而不穩定。
- 累加平方梯度($\odot$為逐元素點乘):$r_{t+1}=r_{t}+\nabla_{\theta_{t}}\odot\nabla_{\theta_{t}}$
- 計算梯度的更新量:$\Delta\theta_{t+1}=\frac{lr}{\delta+\sqrt{r_{t+1}}}\odot\nabla_{\theta_{t}}$
- 應用更新:$\theta_{t+1}=\theta_{t}-\Delta\theta_{t+1}$
adagrad_solver.cpp原始碼
template <typename Dtype>
void AdaGradSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params();
const vector<float>& net_params_lr = this->net_->params_lr();
Dtype delta = this->param_.delta();
Dtype local_rate = rate * net_params_lr[param_id];
switch (Caffe::mode()) {
case Caffe::CPU: {
// compute square of gradient in update
caffe_powx(net_params[param_id]->count(),
net_params[param_id]->cpu_diff(), Dtype(2),
this->update_[param_id]->mutable_cpu_data()); //update_data = net_params ^ 2
// update history
caffe_add(net_params[param_id]->count(),
this->update_[param_id]->cpu_data(),
this->history_[param_id]->cpu_data(),
this->history_[param_id]->mutable_cpu_data()); //history_data = update_data + history_data
// prepare update
caffe_powx(net_params[param_id]->count(), this->history_[param_id]->cpu_data(), Dtype(0.5),
this->update_[param_id]->mutable_cpu_data()); //update_data = history_data ^ 0.5
caffe_add_scalar(net_params[param_id]->count(),
delta, this->update_[param_id]->mutable_cpu_data()); //update_data += delta
caffe_div(net_params[param_id]->count(),
net_params[param_id]->cpu_diff(),
this->update_[param_id]->cpu_data(),
this->update_[param_id]->mutable_cpu_data()); //update_data = net_params_diff / update_data
// scale and copy
caffe_cpu_axpby(net_params[param_id]->count(), local_rate,
this->update_[param_id]->cpu_data(), Dtype(0),
net_params[param_id]->mutable_cpu_diff()); //net_params_diff = local_rate * update_data + 0 * net_params_diff
break;
}
case Caffe::GPU: { //gpu操作同理
#ifndef CPU_ONLY
// gi = net_params_diff;
// hi = history_data = history_data + gi*gi;
// net_params_diff = local_rate * gi / (sqrt(hi) + delta);
adagrad_update_gpu(net_params[param_id]->count(),
net_params[param_id]->mutable_gpu_diff(),
this->history_[param_id]->mutable_gpu_data(), delta, local_rate);
#else
NO_GPU;
#endif
break;
}
default:
LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
}
}AdaGrad/RMSProp/AdaDelta/Adam演算法的caffe程式碼很容易找到對應的公式,不再詳細介紹。
RMSProp簡介
RMSProp演算法在AdaGrad基礎上增加一個衰減係數$\rho$,以便將很早之前的歷史梯度資料丟棄。
其原理如下,初始累積變數$r=0$,$\delta$同樣為較小常數。
- 累加平方梯度:$r_{t+1}=\rhor_{t}+(1-\rho)\nabla_{\theta_{t}}\odot\nabla_{\theta_{t}}$
- 計算梯度的更新量:$\Delta\theta_{t+1}=\frac{lr}{\delta+\sqrt{r_{t+1}}}\odot\nabla_{\theta_{t}}$
- 應用更新:$\theta_{t+1}=\theta_{t}-\Delta\theta_{t+1}$
rmsprop_solver.cpp原始碼
template <typename Dtype>
void RMSPropSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params(); //所有可學習引數
const vector<float>& net_params_lr = this->net_->params_lr(); //引數對應的學習率係數
// get the learning rate
Dtype delta = this->param_.delta(); //常數delta
Dtype rms_decay = this->param_.rms_decay(); //衰減速率
Dtype local_rate = rate * net_params_lr[param_id]; //引數對應的學習率
switch (Caffe::mode()) {
case Caffe::CPU:
// compute square of gradient in update
caffe_powx(net_params[param_id]->count(), net_params[param_id]->cpu_diff(), Dtype(2),
this->update_[param_id]->mutable_cpu_data()); //update_data = net_params_diff ^ 2
// update history //history_data = (1-rms_decay) * update_data + rms_decay * history_data
caffe_cpu_axpby(net_params[param_id] -> count(), Dtype(1-rms_decay), this->update_[param_id]->cpu_data(),
rms_decay, this->history_[param_id]-> mutable_cpu_data());
// prepare update
caffe_powx(net_params[param_id]->count(), this->history_[param_id]->cpu_data(), Dtype(0.5),
this->update_[param_id]->mutable_cpu_data()); //update_data = history_data ^ 0.5
caffe_add_scalar(net_params[param_id]->count(),
delta, this->update_[param_id]->mutable_cpu_data()); //update_data += delta
//update_data = net_params_diff / update_data
caffe_div(net_params[param_id]->count(), net_params[param_id]->cpu_diff(),
this->update_[param_id]->cpu_data(), this->update_[param_id]->mutable_cpu_data());
// scale and copy
caffe_cpu_axpby(net_params[param_id]->count(), local_rate,
this->update_[param_id]->cpu_data(), Dtype(0),
net_params[param_id]->mutable_cpu_diff()); //net_params_diff = local_rate * update_data + 0 * net_params_diff
break;
case Caffe::GPU:
#ifndef CPU_ONLY
// g = net_params_diff
// h = history_data
// gi = g[i];
// hi = h[i] = rms_decay*h[i] + (1-rms_decay)*gi*gi;
// g[i] = local_rate * g[i] / (sqrt(hi) + delta);
rmsprop_update_gpu(net_params[param_id]->count(),
net_params[param_id]->mutable_gpu_diff(),
this->history_[param_id]->mutable_gpu_data(),
rms_decay, delta, local_rate);
#else
NO_GPU;
#endif
break;
default:
LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
}
}AdaDelta簡介
AdaDelta也像RMSProp演算法一樣在AdaGrad基礎上增加一個衰減係數$\rho$,並且還額外維護一個狀態量$x$。
其原理如下,初始累積變數$x=0, r=0$,$\delta$同樣為較小常數。
- 累加平方梯度:$r_{t+1}=\rhor_{t}+(1-\rho)\nabla_{\theta_{t}}\odot\nabla_{\theta_{t}}$
- 計算不帶學習率的梯度的更新量:$\Delta\tilde{\theta}{t+1}=\sqrt{\frac{x{t}+\delta}{r_{t+1}+\delta}}\odot\nabla_{\theta_{t}}$
- 更新狀態量:$x_{t+1}=\rhox_{t}+(1-\rho)\Delta\tilde{\theta}{t+1}\odot\Delta\tilde{\theta}{t+1}$
- 計算帶學習率的梯度的更新量:$\Delta\theta_{t+1}=lr*\Delta\tilde{\theta}_{t+1}$
與參考 4中的說明不同,caffe程式碼中仍然有使用學習率$lr$。 - 應用更新:$\theta_{t+1}=\theta_{t}-\Delta\theta_{t+1}$
adadelta_solver.cpp原始碼
template <typename Dtype>
void AdaDeltaSolver<Dtype>::AdaDeltaPreSolve() { //AdaDeltaSolver類在構造時會呼叫該函式
// Add the extra history entries for AdaDelta after those from SGDSolver::PreSolve
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params(); //當前網路中的所有可學習引數
for (int i = 0; i < net_params.size(); ++i) {
const vector<int>& shape = net_params[i]->shape(); //第i個可學習引數的形狀
//在SGDSolver<Dtype>::PreSolve中history_已經存入一個與引數blob相同形狀的空blob,此處再存入一個
this->history_.push_back(shared_ptr<Blob<Dtype> >(new Blob<Dtype>(shape)));
}
}
#ifndef CPU_ONLY
template <typename Dtype>
void adadelta_update_gpu(int N, Dtype* g, Dtype* h, Dtype* h2, Dtype momentum,
Dtype delta, Dtype local_rate);
#endif
template <typename Dtype>
void AdaDeltaSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params(); //網路中的所有可學習引數
const vector<float>& net_params_lr = this->net_->params_lr(); //每個引數對應的學習率係數
Dtype delta = this->param_.delta(); //AdaDelta方法中的一個引數
Dtype momentum = this->param_.momentum(); //動量係數
Dtype local_rate = rate * net_params_lr[param_id]; //得到當前引數對應的學習率
size_t update_history_offset = net_params.size(); //網路的引數個數
//history_在AdaDeltaPreSolve()中又存入了一次與所有引數形狀相同的空blob,下面將
//history_[param_id]表示成 history_former, history_[update_history_offset + param_id]表示成 history_latter
switch (Caffe::mode()) {
case Caffe::CPU: {
// compute square of gradient in update
caffe_powx(net_params[param_id]->count(), net_params[param_id]->cpu_diff(), Dtype(2),
this->update_[param_id]->mutable_cpu_data()); //update_data = net_params_diff ^ 2
// update history of gradients //history_former_data = (1 - momentum) * update_data + momentum * history_former_data
caffe_cpu_axpby(net_params[param_id]->count(), Dtype(1) - momentum, this->update_[param_id]->cpu_data(),
momentum, this->history_[param_id]->mutable_cpu_data());
// add delta to history to guard against dividing by zero later
caffe_set(net_params[param_id]->count(), delta,
this->temp_[param_id]->mutable_cpu_data()); //temp_中每個元素都置為delta, temp_data = delta
caffe_add(net_params[param_id]->count(),
this->temp_[param_id]->cpu_data(),
this->history_[update_history_offset + param_id]->cpu_data(),
this->update_[param_id]->mutable_cpu_data()); //update_data = temp_data + history_latter_data
caffe_add(net_params[param_id]->count(),
this->temp_[param_id]->cpu_data(),
this->history_[param_id]->cpu_data(),
this->temp_[param_id]->mutable_cpu_data()); //temp_data = temp_data + history_former_data
// divide history of updates by history of gradients
caffe_div(net_params[param_id]->count(),
this->update_[param_id]->cpu_data(),
this->temp_[param_id]->cpu_data(),
this->update_[param_id]->mutable_cpu_data()); //update_data = update_data / temp_data
// jointly compute the RMS of both for update and gradient history
caffe_powx(net_params[param_id]->count(),
this->update_[param_id]->cpu_data(), Dtype(0.5),
this->update_[param_id]->mutable_cpu_data()); //update_data = update_data ^ 0.5
// compute the update
caffe_mul(net_params[param_id]->count(),
net_params[param_id]->cpu_diff(),
this->update_[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff()); //net_params_diff = net_params_diff * update_data
// compute square of update
caffe_powx(net_params[param_id]->count(),
net_params[param_id]->cpu_diff(), Dtype(2),
this->update_[param_id]->mutable_cpu_data()); //update_data = net_params_diff ^ 2
// update history of updates //history_latter_data = (1 - momentum) * update_data + momentum * history_latter_data
caffe_cpu_axpby(net_params[param_id]->count(), Dtype(1) - momentum,
this->update_[param_id]->cpu_data(), momentum,
this->history_[update_history_offset + param_id]->mutable_cpu_data());
// apply learning rate
caffe_cpu_scale(net_params[param_id]->count(), local_rate,
net_params[param_id]->cpu_diff(),
net_params[param_id]->mutable_cpu_diff()); //net_params_diff = local_rate * net_params_diff
break;
}
case Caffe::GPU: {
#ifndef CPU_ONLY
// g = net_params_diff;
// h = history_former_data;
// h2 = history_latter_data;
// gi = g[i];
// hi = h[i] = momentum * h[i] + (1-momentum) * gi * gi;
// gi = gi * sqrt((h2[i] + delta) / (hi + delta));
// h2[i] = momentum * h2[i] + (1-momentum) * gi * gi;
// g[i] = local_rate * gi;
adadelta_update_gpu(net_params[param_id]->count(),
net_params[param_id]->mutable_gpu_diff(),
this->history_[param_id]->mutable_gpu_data(),
this->history_[update_history_offset + param_id]->mutable_gpu_data(),
momentum, delta, local_rate);
#else
NO_GPU;
#endif
break;
}
default:
LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
}
}Adam簡介
Adam演算法包含兩個衰減引數$\rho_{1}$和$\rho_{2}$,一般$\rho_{1}=0.9, \rho_{2}=0.999$。還包含一階矩和二階矩變數$s, r$,時間步$t$。
初始時$s=0, r=0, t=0$,$\delta$同樣為較小常數。
- 更新一階矩:$s_{t+1}=\rho_{1}s_{t}+(1-\rho_{1})\nabla_{\theta_{t}}$
- 更新二階矩:$r_{t+1}=\rho_{2}r_{t}+(1-\rho_{2})\nabla_{\theta_{t}}\odot\nabla_{\theta_{t}}$
- 修正一階矩的偏差:$\tilde{s}{t+1}=\frac{s{t+1}}{1-\rho_{1}^{t+1}}$
- 修正二階矩的偏差:$\tilde{r}{t+1}=\frac{r{t+1}}{1-\rho_{2}^{t+1}}$
計算梯度的更新量:$\Delta\theta_{t+1}=lr*\frac{\tilde{s}{t+1}}{\sqrt{\tilde{r}{t+1}}+\delta}$
應用更新:$\theta_{t+1}=\theta_{t}-\Delta\theta_{t+1}$
adam_solver.cpp原始碼
template <typename Dtype>
void AdamSolver<Dtype>::AdamPreSolve() {
// Add the extra history entries for Adam after those from SGDSolver::PreSolve
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params(); //所有可學習引數
for (int i = 0; i < net_params.size(); ++i) {
const vector<int>& shape = net_params[i]->shape(); //第i個可學習引數對應的形狀
this->history_.push_back(shared_ptr<Blob<Dtype> >(new Blob<Dtype>(shape))); //history_再存入一個與引數大小相同的空blob
}
}
#ifndef CPU_ONLY
template <typename Dtype>
void adam_update_gpu(int N, Dtype* g, Dtype* m, Dtype* v, Dtype beta1,
Dtype beta2, Dtype eps_hat, Dtype corrected_local_rate);
#endif
template <typename Dtype>
void AdamSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params(); //所有可學習引數
const vector<float>& net_params_lr = this->net_->params_lr(); //引數的學習率係數
Dtype local_rate = rate * net_params_lr[param_id]; //當前引數的學習率
const Dtype beta1 = this->param_.momentum(); //兩個動量係數
const Dtype beta2 = this->param_.momentum2();
// we create aliases for convenience
size_t update_history_offset = net_params.size(); //history_的大小為2 * update_history_offset
Blob<Dtype>* val_m = this->history_[param_id].get();
Blob<Dtype>* val_v = this->history_[param_id + update_history_offset].get();
Blob<Dtype>* val_t = this->temp_[param_id].get();
const int t = this->iter_ + 1; //步數
const Dtype correction = std::sqrt(Dtype(1) - pow(beta2, t)) /
(Dtype(1.) - pow(beta1, t)); //correction = sqrt(1 - beta2 ^ t) / (1 - beta1 ^ t)
const int N = net_params[param_id]->count(); //引數的元素個數
const Dtype eps_hat = this->param_.delta(); //微小值
switch (Caffe::mode()) {
case Caffe::CPU: {
// update m <- \beta_1 m_{t-1} + (1-\beta_1)g_t
caffe_cpu_axpby(N, Dtype(1)-beta1, net_params[param_id]->cpu_diff(), beta1,
val_m->mutable_cpu_data()); //val_m = (1 - beta1) * net_params_diff + beta1 * val_m
// update v <- \beta_2 m_{t-1} + (1-\beta_2)g_t^2
caffe_mul(N, net_params[param_id]->cpu_diff(), net_params[param_id]->cpu_diff(),
val_t->mutable_cpu_data()); //val_t = net_params_diff * net_params_diff
caffe_cpu_axpby(N, Dtype(1)-beta2, val_t->cpu_data(), beta2,
val_v->mutable_cpu_data()); //val_v = (1 - beta2) * val_t + beta2 * val_v
// set update
caffe_powx(N, val_v->cpu_data(), Dtype(0.5),
val_t->mutable_cpu_data()); //val_t = val_v ^ 0.5
caffe_add_scalar(N, eps_hat, val_t->mutable_cpu_data()); //val_t += eps_hat
caffe_div(N, val_m->cpu_data(), val_t->cpu_data(),
val_t->mutable_cpu_data()); //val_t = val_m / val_t
caffe_cpu_scale(N, local_rate*correction, val_t->cpu_data(),
net_params[param_id]->mutable_cpu_diff()); //net_params_diff = local_rate*correction * val_t
break;
}
case Caffe::GPU: {
#ifndef CPU_ONLY
// g = net_params_diff
// m = val_m
// v = val_v
// gi = g[i];
// mi = m[i] = m[i]*beta1 + gi*(1-beta1);
// vi = v[i] = v[i]*beta2 + gi*gi*(1-beta2);
// g[i] = local_rate * correction * mi / (sqrt(vi) + eps_hat);
adam_update_gpu(N, net_params[param_id]->mutable_gpu_diff(),
val_m->mutable_gpu_data(), val_v->mutable_gpu_data(), beta1, beta2,
eps_hat, local_rate*correction);
#else
NO_GPU;
#endif
break;
}
default:
LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
}
}小結
- 很多地方的動量的符號與本文不用,是用$\nu_{t+1}=-lr\nabla_{\theta_{t}}+m\nu_{t}$,然後$\theta_{t+1}=\theta_{t}+\nu_{t+1}$,其實原理是一致的,本文只是為了保持與caffe的程式碼一致。
參考
- https://stats.stackexchange.com/questions/179915/whats-the-difference-between-momentum-based-gradient-descent-and-nesterovs-acc
- https://jlmelville.github.io/mize/nesterov.html
- https://zhuanlan.zhihu.com/p/22810533
- https://zh.d2l.ai/chapter_optimization/adadelta.html
- 《Deep Learning》-- Ian Goodfellow and Yoshua Bengio and Aaron Courville
Caffe的原始碼筆者是第一次閱讀,一邊閱讀一邊記錄,對程式碼的理解和分析可能會存在錯誤或遺漏,希望各位讀者批評指正,謝謝支援