
Elasticsearch基本概念和使用
Elasticsearch基本概念和使用
1.操作索引
1.1.基本概念
Elasticsearch也是基於Lucene的全文檢索庫,本質也是儲存資料,很多概念與MySQL類似的。
對比關係:
索引(indices)--------------------------------Databases 資料庫
型別(type)-----------------------------Table 資料表
文件(Document)----------------Row 行
欄位(Field)-------------------Columns 列
詳細說明:
| 概念 | 說明 |
|---|---|
| 索引庫(indices) | indices是index的複數,代表許多的索引, |
| 型別(type) | 型別是模擬mysql中的table概念,一個索引庫下可以有不同型別的索引,比如商品索引,訂單索引,其資料格式不同。不過這會導致索引庫混亂,因此未來版本中會移除這個概念 |
| 文件(document) | 存入索引庫原始的資料。比如每一條商品資訊,就是一個文件 |
| 欄位(field) | 文件中的屬性 |
| 對映配置(mappings) | 欄位的資料型別、屬性、是否索引、是否儲存等特性 |
是不是與Lucene和solr中的概念類似。
另外,在SolrCloud中,有一些叢集相關的概念,在Elasticsearch也有類似的:
- 索引集(Indices,index的複數):邏輯上的完整索引
- 分片(shard):資料拆分後的各個部分
- 副本(replica):每個分片的複製
要注意的是:Elasticsearch本身就是分散式的,因此即便你只有一個節點,Elasticsearch預設也會對你的資料進行分片和副本操作,當你向叢集新增新資料時,資料也會在新加入的節點中進行平衡。
1.2.建立索引
1.2.1.語法
Elasticsearch採用Rest風格API,因此其API就是一次http請求,你可以用任何工具發起http請求
建立索引的請求格式:
請求方式:PUT
請求路徑:/索引庫名
請求引數:json格式:
{ "settings": { "number_of_shards": 3, "number_of_replicas": 2 } }- settings:索引庫的設定
- number_of_shards:分片數量
- number_of_replicas:副本數量
- settings:索引庫的設定
1.2.2.測試
我們先用RestClient來試試

響應:

可以看到索引建立成功了。
1.2.3.使用kibana建立
kibana的控制檯,可以對http請求進行簡化,示例:
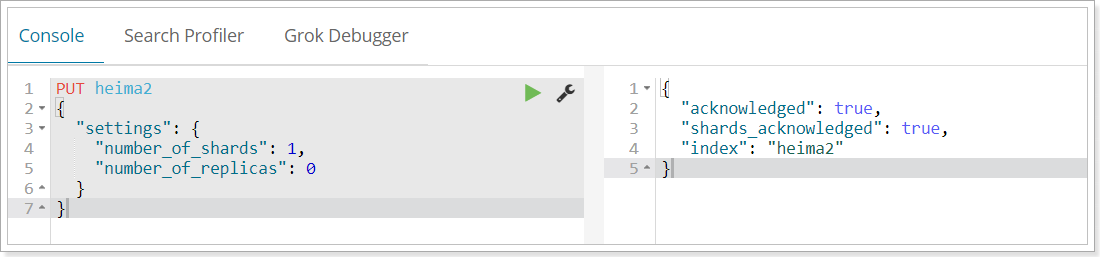
相當於是省去了elasticsearch的伺服器地址
而且還有語法提示,非常舒服。
1.3.檢視索引設定
語法
Get請求可以幫我們檢視索引資訊,格式:
GET /索引庫名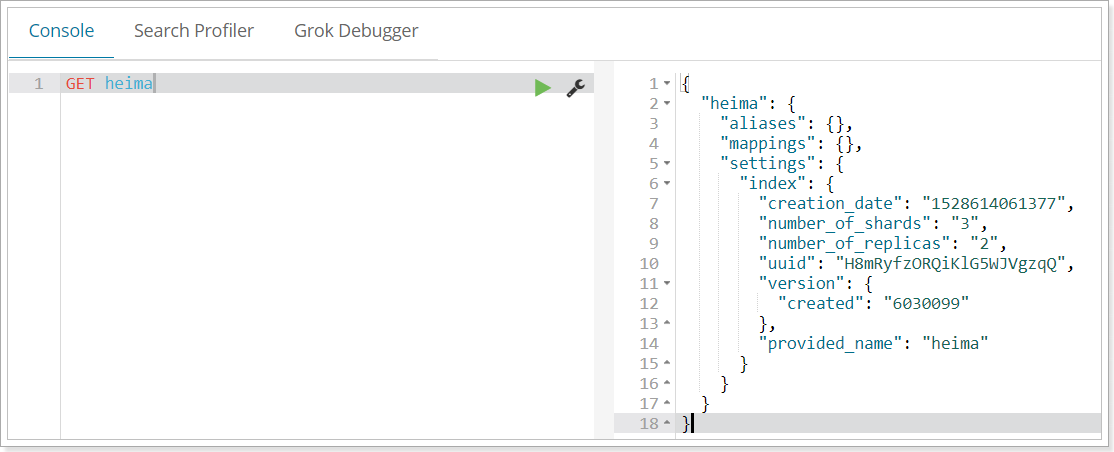
或者,我們可以使用*來查詢所有索引庫配置:
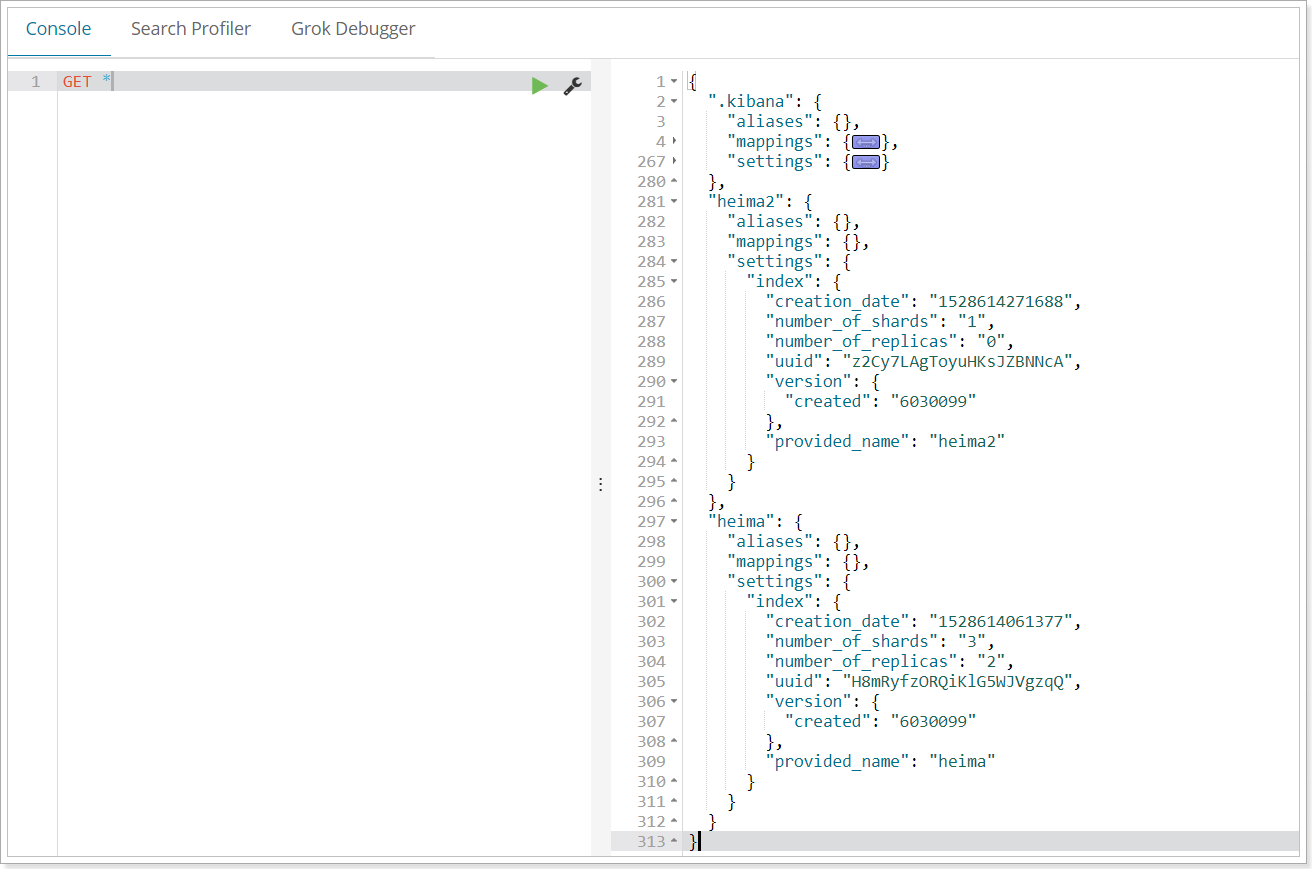
1.4.刪除索引
刪除索引使用DELETE請求
語法
DELETE /索引庫名示例

再次檢視heima2:
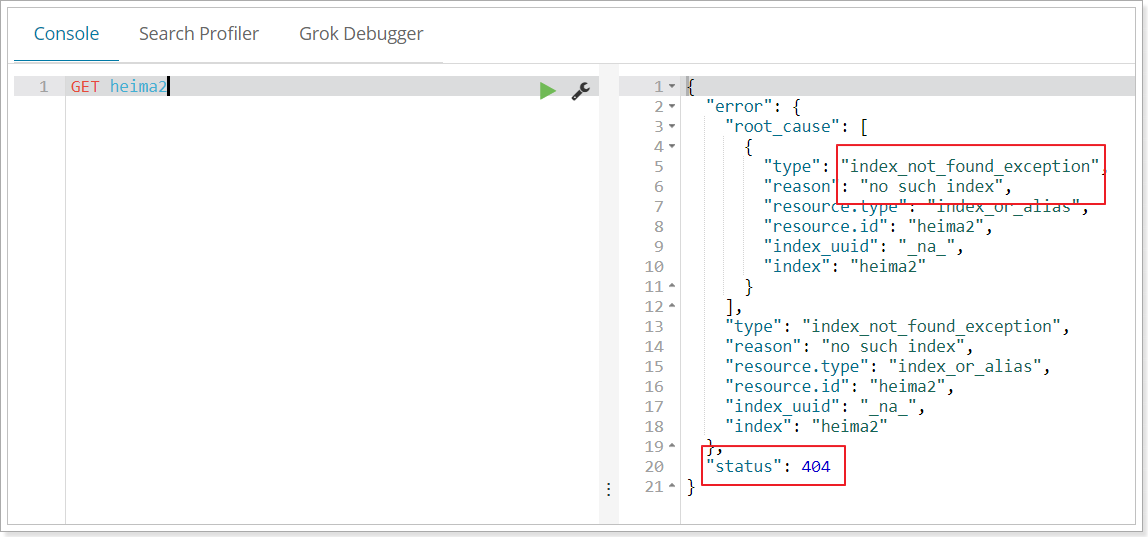
當然,我們也可以用HEAD請求,檢視索引是否存在:

1.5.對映配置
索引有了,接下來肯定是新增資料。但是,在新增資料之前必須定義對映。
什麼是對映?
對映是定義文件的過程,文件包含哪些欄位,這些欄位是否儲存,是否索引,是否分詞等
只有配置清楚,Elasticsearch才會幫我們進行索引庫的建立(不一定)
1.5.1.建立對映欄位
語法
請求方式依然是PUT
PUT /索引庫名/_mapping/型別名稱
{
"properties": {
"欄位名": {
"type": "型別",
"index": true,
"store": true,
"analyzer": "分詞器"
}
}
}- 型別名稱:就是前面將的type的概念,類似於資料庫中的不同表
欄位名:任意填寫 ,可以指定許多屬性,例如: - type:型別,可以是text、long、short、date、integer、object等
- index:是否索引,預設為true
- store:是否儲存,預設為false
- analyzer:分詞器,這裡的
ik_max_word即使用ik分詞器
示例
發起請求:
PUT heima/_mapping/goods
{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": "false"
},
"price": {
"type": "float"
}
}
}
響應結果:
{
"acknowledged": true
}
1.5.2.檢視對映關係
語法:
GET /索引庫名/_mapping示例:
GET /heima/_mapping響應:
{
"heima": {
"mappings": {
"goods": {
"properties": {
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "float"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}1.5.3.欄位屬性詳解
1.5.3.1.type
Elasticsearch中支援的資料型別非常豐富:

我們說幾個關鍵的:
String型別,又分兩種:
- text:可分詞,不可參與聚合
- keyword:不可分詞,資料會作為完整欄位進行匹配,可以參與聚合
Numerical:數值型別,分兩類
- 基本資料型別:long、interger、short、byte、double、float、half_float
- 浮點數的高精度型別:scaled_float
- 需要指定一個精度因子,比如10或100。elasticsearch會把真實值乘以這個因子後儲存,取出時再還原。
Date:日期型別
elasticsearch可以對日期格式化為字串儲存,但是建議我們儲存為毫秒值,儲存為long,節省空間。
1.5.3.2.index
index影響欄位的索引情況。
- true:欄位會被索引,則可以用來進行搜尋。預設值就是true
- false:欄位不會被索引,不能用來搜尋
index的預設值就是true,也就是說你不進行任何配置,所有欄位都會被索引。
但是有些欄位是我們不希望被索引的,比如商品的圖片資訊,就需要手動設定index為false。
1.5.3.3.store
是否將資料進行額外儲存。
在學習lucene和solr時,我們知道如果一個欄位的store設定為false,那麼在文件列表中就不會有這個欄位的值,使用者的搜尋結果中不會顯示出來。
但是在Elasticsearch中,即便store設定為false,也可以搜尋到結果。
原因是Elasticsearch在建立文件索引時,會將文件中的原始資料備份,儲存到一個叫做_source的屬性中。而且我們可以通過過濾_source來選擇哪些要顯示,哪些不顯示。
而如果設定store為true,就會在_source以外額外儲存一份資料,多餘,因此一般我們都會將store設定為false,事實上,store的預設值就是false。
1.5.3.4.boost
激勵因子,這個與lucene中一樣
其它的不再一一講解,用的不多,大家參考官方文件:
1.6.新增資料
1.6.1.隨機生成id
通過POST請求,可以向一個已經存在的索引庫中新增資料。
語法:
POST /索引庫名/型別名
{
"key":"value"
}示例:
POST /heima/goods/
{
"title":"小米手機",
"images":"http://image.leyou.com/12479122.jpg",
"price":2699.00
}響應:
{
"_index": "heima",
"_type": "goods",
"_id": "r9c1KGMBIhaxtY5rlRKv",
"_version": 1,
"result": "created",
"_shards": {
"total": 3,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 2
}通過kibana檢視資料:
get _search
{
"query":{
"match_all":{}
}
}{
"_index": "heima",
"_type": "goods",
"_id": "r9c1KGMBIhaxtY5rlRKv",
"_version": 1,
"_score": 1,
"_source": {
"title": "小米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
}_source:源文件資訊,所有的資料都在裡面。_id:這條文件的唯一標示,與文件自己的id欄位沒有關聯
1.6.2.自定義id
如果我們想要自己新增的時候指定id,可以這麼做:
POST /索引庫名/型別/id值
{
...
}
示例:
POST /heima/goods/2
{
"title":"大米手機",
"images":"http://image.leyou.com/12479122.jpg",
"price":2899.00
}得到的資料:
{
"_index": "heima",
"_type": "goods",
"_id": "2",
"_score": 1,
"_source": {
"title": "大米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2899
}
}1.6.3.智慧判斷
在學習Solr時我們發現,我們在新增資料時,只能使用提前配置好對映屬性的欄位,否則就會報錯。
不過在Elasticsearch中並沒有這樣的規定。
事實上Elasticsearch非常智慧,你不需要給索引庫設定任何mapping對映,它也可以根據你輸入的資料來判斷型別,動態新增資料對映。
測試一下:
POST /heima/goods/3
{
"title":"超米手機",
"images":"http://image.leyou.com/12479122.jpg",
"price":2899.00,
"stock": 200,
"saleable":true
}我們額外添加了stock庫存,和saleable是否上架兩個欄位。
來看結果:
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_version": 1,
"_score": 1,
"_source": {
"title": "超米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2899,
"stock": 200,
"saleable": true
}
}在看下索引庫的對映關係:
{
"heima": {
"mappings": {
"goods": {
"properties": {
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "float"
},
"saleable": {
"type": "boolean"
},
"stock": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}stock和saleable都被成功映射了。
如果儲存的是String型別資料,ES無智慧判斷,他就會存入兩個欄位。例如:
存入一個name欄位,智慧形成兩個欄位:
- name:text型別
- name.keyword:keyword型別
1.7.修改資料
把剛才新增的請求方式改為PUT,就是修改了。不過修改必須指定id,
- id對應文件存在,則修改
- id對應文件不存在,則新增
比如,我們把id為3的資料進行修改:
PUT /heima/goods/3
{
"title":"超大米手機",
"images":"http://image.leyou.com/12479122.jpg",
"price":3899.00,
"stock": 100,
"saleable":true
}結果:
{
"took": 17,
"timed_out": false,
"_shards": {
"total": 9,
"successful": 9,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_score": 1,
"_source": {
"title": "超大米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 3899,
"stock": 100,
"saleable": true
}
}
]
}
}1.8.刪除資料
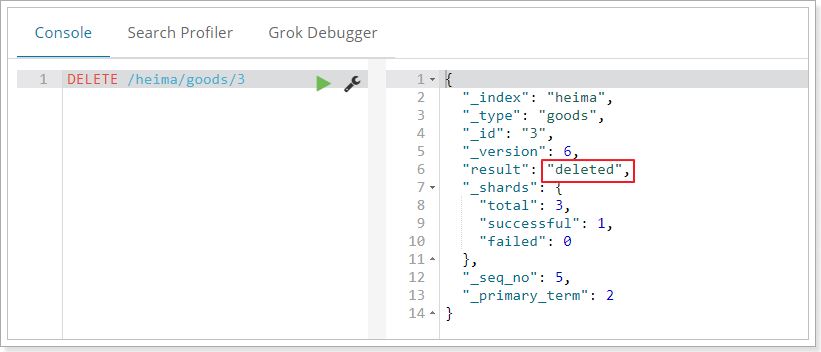
刪除使用DELETE請求,同樣,需要根據id進行刪除:
語法
DELETE /索引庫名/型別名/id值示例:
2.查詢
我們從4塊來講查詢:
- 基本查詢
_source過濾- 結果過濾
- 高階查詢
- 排序
2.1.基本查詢:
基本語法
GET /索引庫名/_search
{
"query":{
"查詢型別":{
"查詢條件":"查詢條件值"
}
}
}這裡的query代表一個查詢物件,裡面可以有不同的查詢屬性
- 查詢型別:
- 例如:
match_all,match,term,range等等
- 例如:
- 查詢條件:查詢條件會根據型別的不同,寫法也有差異,後面詳細講解
2.1.1 查詢所有(match_all)
示例:
GET /heima/_search
{
"query":{
"match_all": {}
}
}query:代表查詢物件match_all:代表查詢所有
結果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "2",
"_score": 1,
"_source": {
"title": "大米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2899
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "r9c1KGMBIhaxtY5rlRKv",
"_score": 1,
"_source": {
"title": "小米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
}
]
}
}- took:查詢花費時間,單位是毫秒
- time_out:是否超時
- _shards:分片資訊
- hits:搜尋結果總覽物件
- total:搜尋到的總條數
- max_score:所有結果中文件得分的最高分
- hits:搜尋結果的文件物件陣列,每個元素是一條搜尋到的文件資訊
- _index:索引庫
- _type:文件型別
- _id:文件id
- _score:文件得分
- _source:文件的源資料
2.1.2 匹配查詢(match)
我們先加入一條資料,便於測試:
PUT /heima/goods/3
{
"title":"小米電視4A",
"images":"http://image.leyou.com/12479122.jpg",
"price":3899.00
}現在,索引庫中有2部手機,1臺電視:
- or關係
match型別查詢,會把查詢條件進行分詞,然後進行查詢,多個詞條之間是or的關係
GET /heima/_search
{
"query":{
"match":{
"title":"小米電視"
}
}
}結果:
"hits": {
"total": 2,
"max_score": 0.6931472,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "tmUBomQB_mwm6wH_EC1-",
"_score": 0.6931472,
"_source": {
"title": "小米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_score": 0.5753642,
"_source": {
"title": "小米電視4A",
"images": "http://image.leyou.com/12479122.jpg",
"price": 3899
}
}
]
}在上面的案例中,不僅會查詢到電視,而且與小米相關的都會查詢到,多個詞之間是or的關係。
- and關係
某些情況下,我們需要更精確查詢,我們希望這個關係變成and,可以這樣做:
GET /heima/_search
{
"query":{
"match": {
"title": {
"query": "小米電視",
"operator": "and"
}
}
}
}結果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_score": 0.5753642,
"_source": {
"title": "小米電視4A",
"images": "http://image.leyou.com/12479122.jpg",
"price": 3899
}
}
]
}
}本例中,只有同時包含小米和電視的詞條才會被搜尋到。
- or和and之間?
在 or 與 and 間二選一有點過於非黑即白。 如果使用者給定的條件分詞後有 5 個查詢詞項,想查詢只包含其中 4 個詞的文件,該如何處理?將 operator 操作符引數設定成 and 只會將此文件排除。
有時候這正是我們期望的,但在全文搜尋的大多數應用場景下,我們既想包含那些可能相關的文件,同時又排除那些不太相關的。換句話說,我們想要處於中間某種結果。
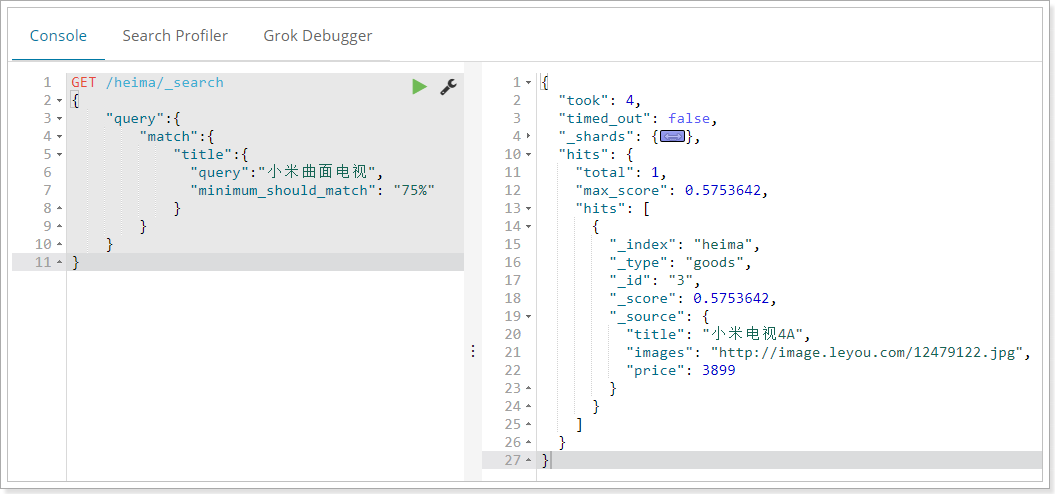
match 查詢支援 minimum_should_match 最小匹配引數, 這讓我們可以指定必須匹配的詞項數用來表示一個文件是否相關。我們可以將其設定為某個具體數字,更常用的做法是將其設定為一個百分數,因為我們無法控制使用者搜尋時輸入的單詞數量:
GET /heima/_search
{
"query":{
"match":{
"title":{
"query":"小米曲面電視",
"minimum_should_match": "75%"
}
}
}
}本例中,搜尋語句可以分為3個詞,如果使用and關係,需要同時滿足3個詞才會被搜尋到。這裡我們採用最小品牌數:75%,那麼也就是說只要匹配到總詞條數量的75%即可,這裡3*75% 約等於2。所以只要包含2個詞條就算滿足條件了。
結果:
2.1.3 多欄位查詢(multi_match)
multi_match與match類似,不同的是它可以在多個欄位中查詢
GET /heima/_search
{
"query":{
"multi_match": {
"query": "小米",
"fields": [ "title", "subTitle" ]
}
}
}本例中,我們會在title欄位和subtitle欄位中查詢小米這個詞
2.1.4 詞條匹配(term)
term 查詢被用於精確值 匹配,這些精確值可能是數字、時間、布林或者那些未分詞的字串
GET /heima/_search
{
"query":{
"term":{
"price":2699.00
}
}
}結果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "r9c1KGMBIhaxtY5rlRKv",
"_score": 1,
"_source": {
"title": "小米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
}
]
}
}2.1.5 多詞條精確匹配(terms)
terms 查詢和 term 查詢一樣,但它允許你指定多值進行匹配。如果這個欄位包含了指定值中的任何一個值,那麼這個文件滿足條件:
GET /heima/_search
{
"query":{
"terms":{
"price":[2699.00,2899.00,3899.00]
}
}
}結果:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "2",
"_score": 1,
"_source": {
"title": "大米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2899
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "r9c1KGMBIhaxtY5rlRKv",
"_score": 1,
"_source": {
"title": "小米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_score": 1,
"_source": {
"title": "小米電視4A",
"images": "http://image.leyou.com/12479122.jpg",
"price": 3899
}
}
]
}
}2.2.結果過濾
預設情況下,elasticsearch在搜尋的結果中,會把文件中儲存在_source的所有欄位都返回。
如果我們只想獲取其中的部分欄位,我們可以新增_source的過濾
2.2.1.直接指定欄位
示例:
GET /heima/_search
{
"_source": ["title","price"],
"query": {
"term": {
"price": 2699
}
}
}返回的結果:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "r9c1KGMBIhaxtY5rlRKv",
"_score": 1,
"_source": {
"price": 2699,
"title": "小米手機"
}
}
]
}
}2.2.2.指定includes和excludes
我們也可以通過:
- includes:來指定想要顯示的欄位
- excludes:來指定不想要顯示的欄位
二者都是可選的。
示例:
GET /heima/_search
{
"_source": {
"includes":["title","price"]
},
"query": {
"term": {
"price": 2699
}
}
}與下面的結果將是一樣的:
GET /heima/_search
{
"_source": {
"excludes": ["images"]
},
"query": {
"term": {
"price": 2699
}
}
}2.3 高階查詢
2.3.1 布林組合(bool)
bool把各種其它查詢通過must(與)、must_not(非)、should(或)的方式進行組合
GET /heima/_search
{
"query":{
"bool":{
"must": { "match": { "title": "大米" }},
"must_not": { "match": { "title": "電視" }},
"should": { "match": { "title": "手機" }}
}
}
}結果:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "2",
"_score": 0.5753642,
"_source": {
"title": "大米手機",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2899
}
}
]
}
}2.3.2 範圍查詢(range)
range 查詢找出那些落在指定區間內的數字或者時間
GET /heima/_search
{
"query":{
"range": {
"price": {
"gte": 1000.0,
"lt": 2800.00
}
}
}
}range查詢允許以下字元:
| 操作符 | 說明 |
|---|---|
| gt | 大於 |
| gte | 大於等於 |
| lt | 小於 |
| lte | 小於等於 |
2.3.3 模糊查詢(fuzzy)
我們新增一個商品:
POST /heima/goods/4
{
"title":"apple手機",
"images":"http://image.leyou.com/12479122.jpg",
"price":6899.00
}fuzzy 查詢是 term 查詢的模糊等價。它允許使用者搜尋詞條與實際詞條的拼寫出現偏差,但是偏差的編輯距離不得超過2:
GET /heima/_search
{
"query": {
"fuzzy": {
"title": "appla"
}
}
}上面的查詢,也能查詢到apple手機
我們可以通過fuzziness來指定允許的編輯距離:
GET /heima/_search
{
"query": {
"fuzzy": {
"title": {
"value":"appla",
"fuzziness":1
}
}
}
}2.4 過濾(filter)
條件查詢中進行過濾
所有的查詢都會影響到文件的評分及排名。如果我們需要在查詢結果中進行過濾,並且不希望過濾條件影響評分,那麼就不要把過濾條件作為查詢條件來用。而是使用filter方式:
GET /heima/_search
{
"query":{
"bool":{
"must":{ "match": { "title": "小米手機" }},
"filter":{
"range":{"price":{"gt":2000.00,"lt":3800.00}}
}
}
}
}注意:filter中還可以再次進行bool組合條件過濾。
無查詢條件,直接過濾
如果一次查詢只有過濾,沒有查詢條件,不希望進行評分,我們可以使用constant_score取代只有 filter 語句的 bool 查詢。在效能上是完全相同的,但對於提高查詢簡潔性和清晰度有很大幫助。
GET /heima/_search
{
"query":{
"constant_score": {
"filter": {
"range":{"price":{"gt":2000.00,"lt":3000.00}}
}
}
}2.5 排序
2.5.1 單欄位排序
sort 可以讓我們按照不同的欄位進行排序,並且通過order指定排序的方式
GET /heima/_search
{
"query": {
"match": {
"title": "小米手機"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}2.5.2 多欄位排序
假定我們想要結合使用 price和 _score(得分) 進行查詢,並且匹配的結果首先按照價格排序,然後按照相關性得分排序:
GET /goods/_search
{
"query":{
"bool":{
"must":{ "match": { "title": "小米手機" }},
"filter":{
"range":{"price":{"gt":200000,"lt":300000}}
}
}
},
"sort": [
{ "price": { "order": "desc" }},
{ "_score": { "order": "desc" }}
]
}3. 聚合aggregations
聚合可以讓我們極其方便的實現對資料的統計、分析。例如:
- 什麼品牌的手機最受歡迎?
- 這些手機的平均價格、最高價格、最低價格?
- 這些手機每月的銷售情況如何?
實現這些統計功能的比資料庫的sql要方便的多,而且查詢速度非常快,可以實現實時搜尋效果。
3.1 基本概念
Elasticsearch中的聚合,包含多種型別,最常用的兩種,一個叫桶,一個叫度量:
桶(bucket)
桶的作用,是按照某種方式對資料進行分組,每一組資料在ES中稱為一個桶,例如我們根據國籍對人劃分,可以得到中國桶、英國桶,日本桶……或者我們按照年齡段對人進行劃分:0~10,10~20,20~30,30~40等。
Elasticsearch中提供的劃分桶的方式有很多:
- Date Histogram Aggregation:根據日期階梯分組,例如給定階梯為周,會自動每週分為一組
- Histogram Aggregation:根據數值階梯分組,與日期類似
- Terms Aggregation:根據詞條內容分組,詞條內容完全匹配的為一組
- Range Aggregation:數值和日期的範圍分組,指定開始和結束,然後按段分組
- ……
綜上所述,我們發現bucket aggregations 只負責對資料進行分組,並不進行計算,因此往往bucket中往往會巢狀另一種聚合:metrics aggregations即度量
度量(metrics)
分組完成以後,我們一般會對組中的資料進行聚合運算,例如求平均值、最大、最小、求和等,這些在ES中稱為度量
比較常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同時返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前幾
- Value Count Aggregation:求總數
- ……
為了測試聚合,我們先批量匯入一些資料
建立索引:
PUT /cars
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"transactions": {
"properties": {
"color": {
"type": "keyword"
},
"make": {
"type": "keyword"
}
}
}
}
}注意:在ES中,需要進行聚合、排序、過濾的欄位其處理方式比較特殊,因此不能被分詞。這裡我們將color和make這兩個文字型別的欄位設定為keyword型別,這個型別不會被分詞,將來就可以參與聚合
匯入資料
POST /cars/transactions/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }3.2 聚合為桶
首先,我們按照 汽車的顏色color來劃分桶
GET /cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
}
}
}
}- size: 查詢條數,這裡設定為0,因為我們不關心搜尋到的資料,只關心聚合結果,提高效率
- aggs:宣告這是一個聚合查詢,是aggregations的縮寫
- popular_colors:給這次聚合起一個名字,任意。
- terms:劃分桶的方式,這裡是根據詞條劃分
- field:劃分桶的欄位
- terms:劃分桶的方式,這裡是根據詞條劃分
- popular_colors:給這次聚合起一個名字,任意。
結果:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"popular_colors": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "red",
"doc_count": 4
},
{
"key": "blue",
"doc_count": 2
},
{
"key": "green",
"doc_count": 2
}
]
}
}
}- hits:查詢結果為空,因為我們設定了size為0
- aggregations:聚合的結果
- popular_colors:我們定義的聚合名稱
- buckets:查詢到的桶,每個不同的color欄位值都會形成一個桶
- key:這個桶對應的color欄位的值
- doc_count:這個桶中的文件數量
通過聚合的結果我們發現,目前紅色的小車比較暢銷!
3.3 桶內度量
前面的例子告訴我們每個桶裡面的文件數量,這很有用。 但通常,我們的應用需要提供更復雜的文件度量。 例如,每種顏色汽車的平均價格是多少?
因此,我們需要告訴Elasticsearch使用哪個欄位,使用何種度量方式進行運算,這些資訊要巢狀在桶內,度量的運算會基於桶內的文件進行
現在,我們為剛剛的聚合結果新增 求價格平均值的度量:
GET /cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
},
"aggs":{
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}- aggs:我們在上一個aggs(popular_colors)中新增新的aggs。可見
度量也是一個聚合,度量是在桶內的聚合 - avg_price:聚合的名稱
- avg:度量的型別,這裡是求平均值
- field:度量運算的欄位
結果:
...
"aggregations": {
"popular_colors": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "red",
"doc_count": 4,
"avg_price": {
"value": 32500
}
},
{
"key": "blue",
"doc_count": 2,
"avg_price": {
"value": 20000
}
},
{
"key": "green",
"doc_count": 2,
"avg_price": {
"value": 21000
}
}
]
}
}
...可以看到每個桶中都有自己的avg_price欄位,這是度量聚合的結果
3.4 桶內巢狀桶
剛剛的案例中,我們在桶內巢狀度量運算。事實上桶不僅可以巢狀運算, 還可以再巢狀其它桶。也就是說在每個分組中,再分更多組。
比如:我們想統計每種顏色的汽車中,分別屬於哪個製造商,按照make欄位再進行分桶
GET /cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
},
"aggs":{
"avg_price": {
"avg": {
"field": "price"
}
},
"maker":{
"terms":{
"field":"make"
}
}
}
}
}
}- 原來的color桶和avg計算我們不變
- maker:在巢狀的aggs下新添一個桶,叫做maker
- terms:桶的劃分型別依然是詞條
- filed:這裡根據make欄位進行劃分
部分結果:
...
{"aggregations": {
"popular_colors": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "red",
"doc_count": 4,
"maker": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "honda",
"doc_count": 3
},
{
"key": "bmw",
"doc_count": 1
}
]
},
"avg_price": {
"value": 32500
}
},
{
"key": "blue",
"doc_count": 2,
"maker": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "ford",
"doc_count": 1
},
{
"key": "toyota",
"doc_count": 1
}
]
},
"avg_price": {
"value": 20000
}
},
{
"key": "green",
"doc_count": 2,
"maker": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "ford",
"doc_count": 1
},
{
"key": "toyota",
"doc_count": 1
}
]
},
"avg_price": {
"value": 21000
}
}
]
}
}
}
...- 我們可以看到,新的聚合
maker被巢狀在原來每一個color的桶中。 - 每個顏色下面都根據
make欄位進行了分組 - 我們能讀取到的資訊:
- 紅色車共有4輛
- 紅色車的平均售價是 $32,500 美元。
- 其中3輛是 Honda 本田製造,1輛是 BMW 寶馬製造。
3.5.劃分桶的其它方式
前面講了,劃分桶的方式有很多,例如:
- Date Histogram Aggregation:根據日期階梯分組,例如給定階梯為周,會自動每週分為一組
- Histogram Aggregation:根據數值階梯分組,與日期類似
- Terms Aggregation:根據詞條內容分組,詞條內容完全匹配的為一組
- Range Aggregation:數值和日期的範圍分組,指定開始和結束,然後按段分組
剛剛的案例中,我們採用的是Terms Aggregation,即根據詞條劃分桶。
接下來,我們再學習幾個比較實用的:
3.5.1.階梯分桶Histogram
原理:
histogram是把數值型別的欄位,按照一定的階梯大小進行分組。你需要指定一個階梯值(interval)來劃分階梯大小。
舉例:
比如你有價格欄位,如果你設定interval的值為200,那麼階梯就會是這樣的:
0,200,400,600,...
上面列出的是每個階梯的key,也是區間的啟點。
如果一件商品的價格是450,會落入哪個階梯區間呢?計算公式如下:
bucket_key = Math.floor((value - offset) / interval) * interval + offsetvalue:就是當前資料的值,本例中是450
offset:起始偏移量,預設為0
interval:階梯間隔,比如200
因此你得到的key = Math.floor((450 - 0) / 200) * 200 + 0 = 400
操作一下:
比如,我們對汽車的價格進行分組,指定間隔interval為5000:
GET /cars/_search
{
"size":0,
"aggs":{
"price":{
"histogram": {
"field": "price",
"interval": 5000
}
}
}
}結果:
{
"took": 21,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"price": {
"buckets": [
{
"key": 10000,
"doc_count": 2
},
{
"key": 15000,
"doc_count": 1
},
{
"key": 20000,
"doc_count": 2
},
{
"key": 25000,
"doc_count": 1
},
{
"key": 30000,
"doc_count": 1
},
{
"key": 35000,
"doc_count": 0
},
{
"key": 40000,
"doc_count": 0
},
{
"key": 45000,
"doc_count": 0
},
{
"key": 50000,
"doc_count": 0
},
{
"key": 55000,
"doc_count": 0
},
{
"key": 60000,
"doc_count": 0
},
{
"key": 65000,
"doc_count": 0
},
{
"key": 70000,
"doc_count": 0
},
{
"key": 75000,
"doc_count": 0
},
{
"key": 80000,
"doc_count": 1
}
]
}
}
}你會發現,中間有大量的文件數量為0 的桶,看起來很醜。
我們可以增加一個引數min_doc_count為1,來約束最少文件數量為1,這樣文件數量為0的桶會被過濾
示例:
GET /cars/_search
{
"size":0,
"aggs":{
"price":{
"histogram": {
"field": "price",
"interval": 5000,
"min_doc_count": 1
}
}
}
}結果:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"price": {
"buckets": [
{
"key": 10000,
"doc_count": 2
},
{
"key": 15000,
"doc_count": 1
},
{
"key": 20000,
"doc_count": 2
},
{
"key": 25000,
"doc_count": 1
},
{
"key": 30000,
"doc_count": 1
},
{
"key": 80000,
"doc_count": 1
}
]
}
}
}完美,!
如果你用kibana將結果變為柱形圖,會更好看:
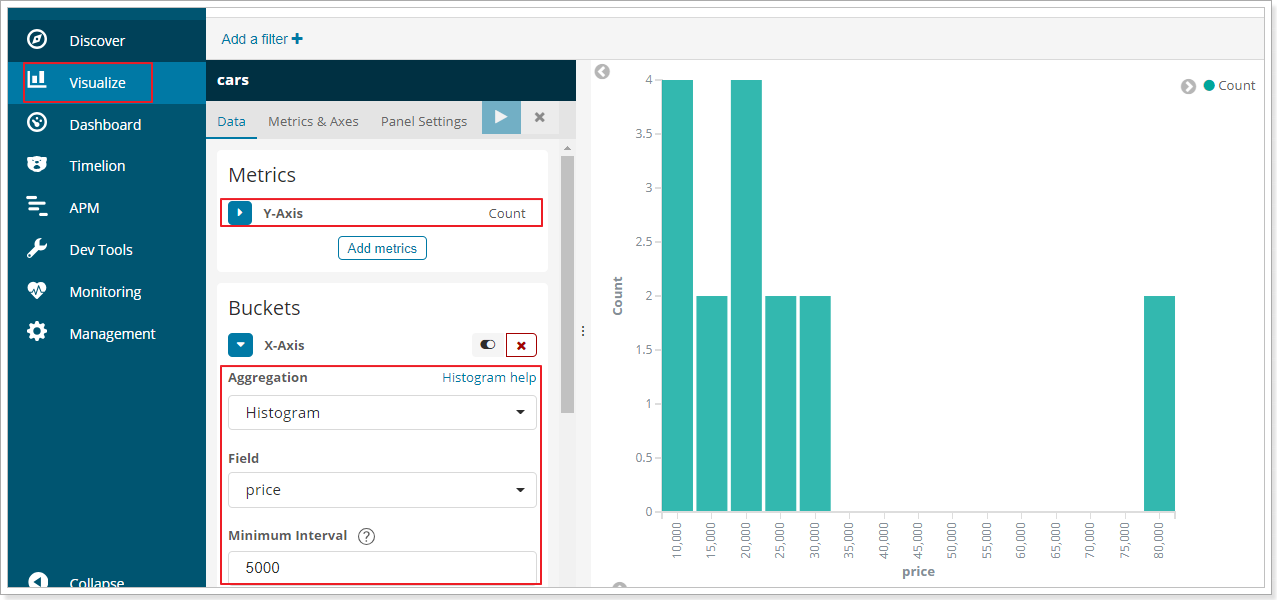
3.5.2.範圍分桶range
範圍分桶與階梯分桶類似,也是把數字按照階段進行分組,只不過range方式需要你自己指定每一組的起始和結束大小