
HBase學習筆記(一)——基礎入門
1、what:什麼是HBase
HBase的原型是Google的BigTable論文,受到了該論文思想的啟發,目前作為Hadoop的子專案來開發維護,用於支援結構化的資料儲存。
HBase是一個高可靠性、高效能、面向列、可伸縮的分散式儲存系統,利用HBASE技術可在廉價PC Server上搭建起大規模結構化儲存叢集。
HBase的目標是儲存並處理大型的資料,更具體來說是僅需使用普通的硬體配置,就能夠處理由成千上萬的行和列所組成的大型資料。【非大勿用】
HBase是Google Bigtable的開源實現,但是也有很多不同之處。比如:Google Bigtable利用GFS作為其檔案儲存系統,HBase利用Hadoop HDFS作為其檔案儲存系統;Google執行MAPREDUCE來處理Bigtable中的海量資料,HBase同樣利用Hadoop MapReduce來處理HBase中的海量資料;Google Bigtable利用Chubby作為協同服務,HBase利用Zookeeper作為對應。
上面的話太官方,挨個看都認識,連起來不理解。簡單粗暴的總結:就是一款NoSQL資料庫,面向列儲存,用於儲存處理海量資料。
核心在於它是一個存資料的地方,可是在此之前學習過了HDFS和Mysql,那HBase為什麼還會出現呢?後邊細說~
2、why:為什麼會有HBase?
先說一下Mysql,我們都知道Mysql是一個關係型資料庫,平時開發使用的非常頻繁。一個網站或者系統最核心的表就是使用者表,而當用戶表的資料達到幾千萬甚至幾億級別的時候,對單條資料的檢索將會耗費數秒甚至分鐘級別。實際的清空可能更加複雜不堪。
看下邊一張表:
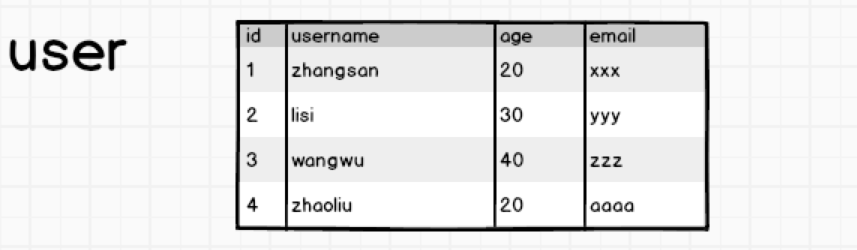
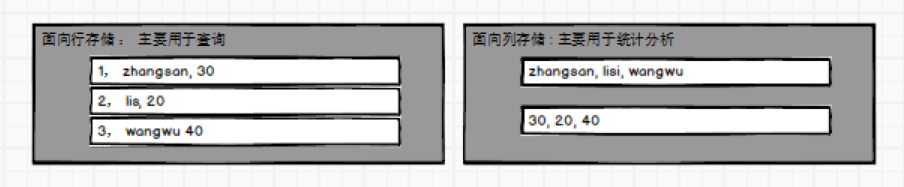
有這麼一張使用者表,假如我要根據id=1查詢出來這條資料對應的使用者姓名,很簡單,會給我們返回zhangsan。但是,當我們查的時候,想一下,查名字的時候age和email會不會被查出來?答案是肯定的,Mysql的資料儲存是以行為單位的,面向行儲存。那問題就出現了,我只需要找出zhangsan的名字,卻需要查詢一整行的資料,如果列非常多,那麼查詢效率可想而知了。
查詢的操作速度會受到以下兩個因素的制約:
- 表被併發的插入、編輯以及刪除操作。
- 查詢語句通常不是簡單的對一個表進行操作,有可能是多個表關聯後的複雜查詢,甚至有可能是group by或者order by操作,此時,效能下降很明顯。
如果一張表的列過多,會影響查詢效率,我們稱這樣表為寬表。怎麼優化呢,拆開來,豎直拆分:
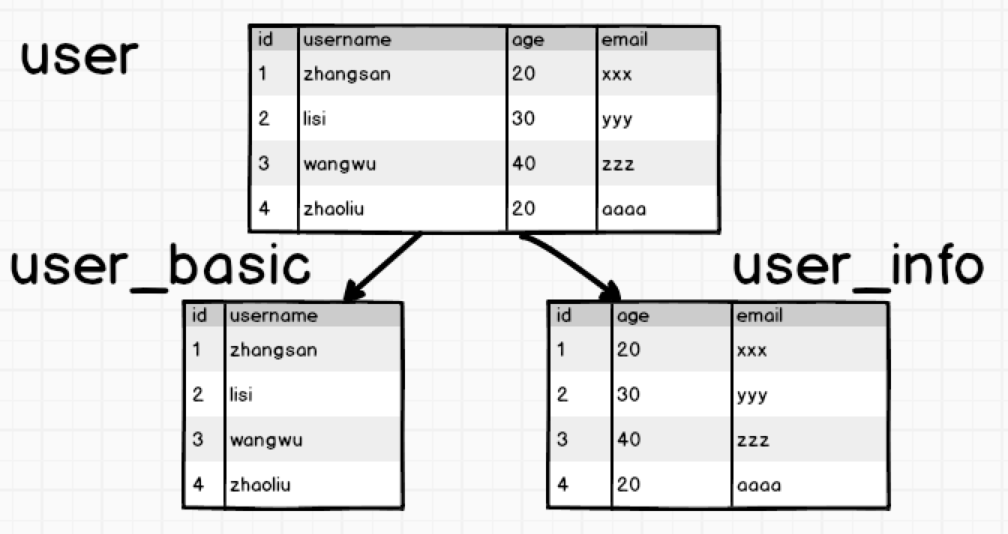
這樣的情況下,我們要查詢username的時候只需要查詢user_basic表,沒有多餘的欄位,查詢效率就會很快。
如果一張表的行過多,會影響查詢效率,我們將這樣的表稱之為高表,可以採用水平拆表的方式提高效率:
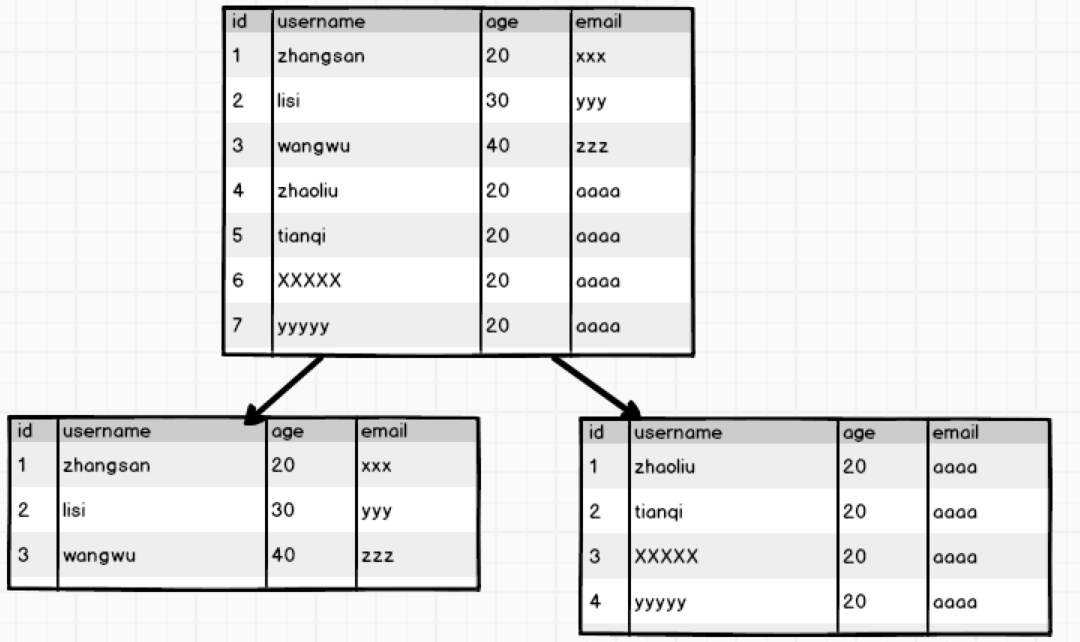
這種水平拆分應用比較多的 場景就是日誌表,日誌資訊每天產生很多,可以按月進行水平拆分,這樣就實現了高表變矮。
ok,這種拆分方式貌似可以解決寬表和高表的問題,但是如果有一天公司的業務變了,比如原來沒有微信,現在有了微信,需要加入使用者的微信欄位。這時候需要改變表的結構資訊,該怎麼辦?最簡單的想法是多加一列,像這樣:
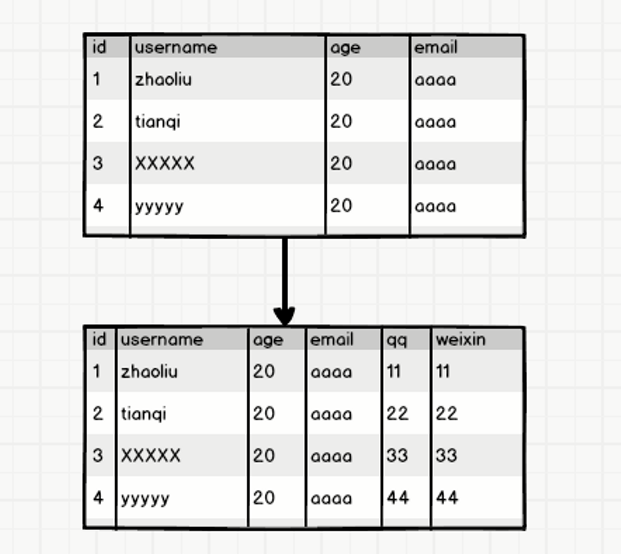
多考慮一下就知道這樣做很不妥帖,比如說有些早期使用者沒有微信,這一列是設定預設值還是採取其他的做法就得權衡一下。如果需要擴充套件很多的列出來,而且不是所有的使用者都有這些屬性,那麼拓展起來就更加複雜了。
這時候,想到了JSON格式的字串,這是一種以字串的形式表示的物件,而且屬性欄位可以動態拓展,於是有了下邊這種做法,兩種做法加以對比:
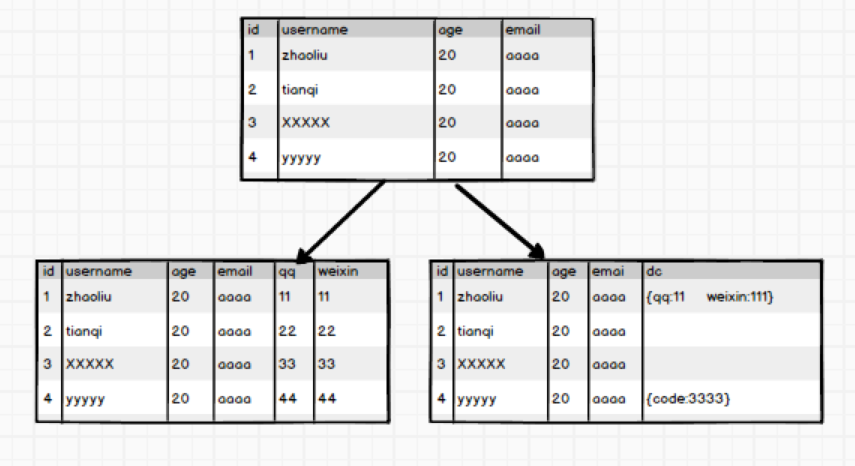
ok,這樣儲存資料它不挺好的嘛,HBase出來幹嘛??Mysql有一點,資料達到一定的閾值,無論怎麼優化,它都無法達到高效能的發揮。而大資料領域的資料,動輒PB級,這種儲存應用明顯是不能很好的滿足需求的。針對上邊的問題,HBase都有很好的解決方案~~
3、How:HBase怎麼實現的?
先不說為什麼用,接著上邊說到的幾個問題:高表寬表,資料列動態擴充套件,把提到的幾個解決辦法:水平垂直切分,列擴充套件方法,雜糅在一起。
有這麼一張表,怕它又寬又高,又會動態擴充套件列,那麼在設計之初,就把這個表給他拆開,為了列的動態拓展,直接儲存JSON格式:
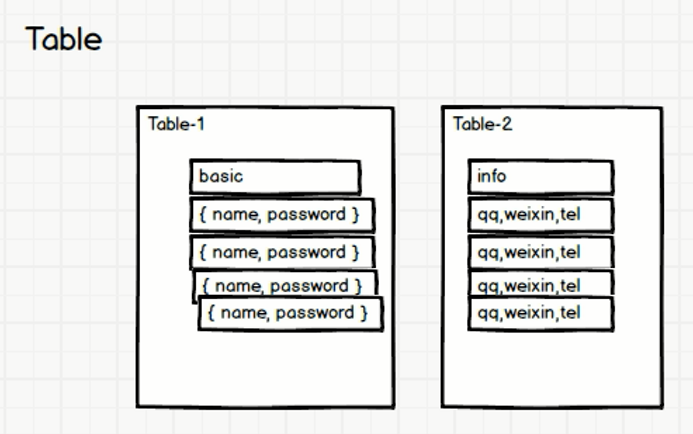
這樣就解決了寬表問題,高表怎麼辦呢?
一個表的兩部分,各存一部分行:

解決了高表,寬表,動態擴充套件列的問題~~完美plus~
如果還要進一步提高效能怎麼辦?Mysql->Redis !!! 快取啊!
查詢出來的資料放入到快取中,下一次查詢直接從快取中拿資料。插入資料怎麼辦呢?也可以這樣理解,我把要插入的資料放進快取中,再也不用管了,直接由資料庫從快取拿資料插入到資料庫。此時程式不需要等待資料插入成功,提高了並行工作的效率。
可是這樣做有了很大的風險,伺服器宕機的話,快取中的資料沒來得及插入到資料庫中,那不就丟資料了嘛。參考Redis的持久化策略,可以給插入資料這個操作新增一個操作日誌,用於持久化插入操作,宕機重啟後從日誌恢復。
這樣設計架構就變成了這個樣子:
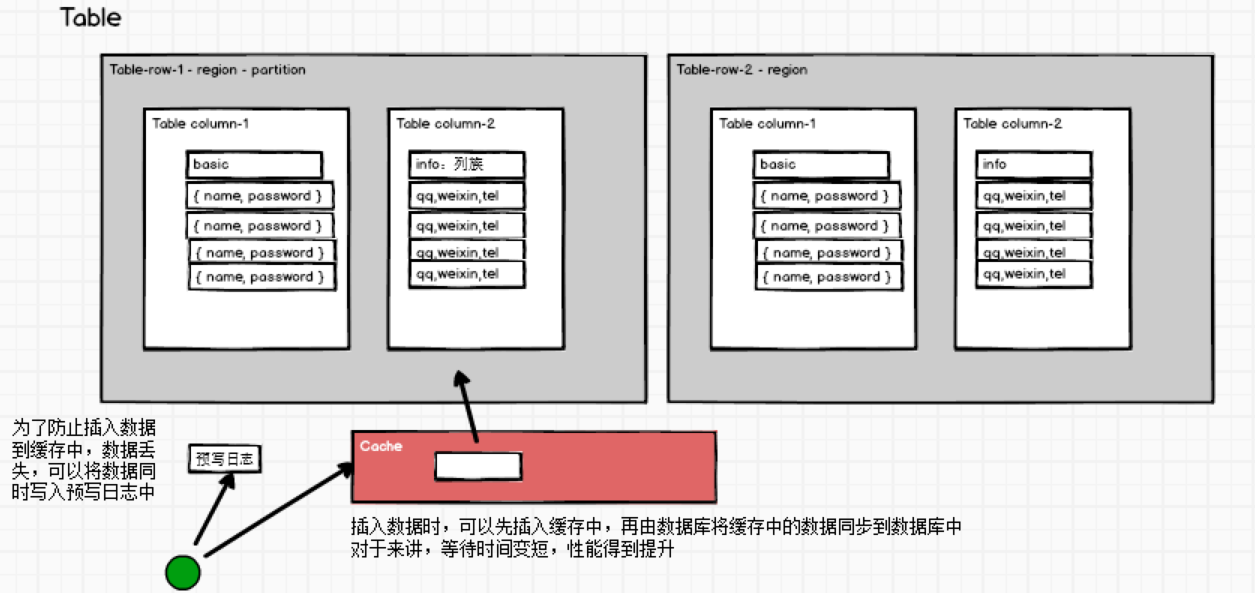
上邊這種解決方式,實際上就是HBase實現的大致思路,詳細的內容會在後邊慢慢說。
簡單粗暴總結:HBase就是一個面向列儲存的非關係型資料庫。兩者的區別主要是:
HBase是的儲存時基於HDFS的,HDFS有著高容錯性的特點,被設計用來部署在低廉的硬體上,而且它提供高吞吐量以訪問應用程式的資料,時候那些有著超大資料集的應用程式。基於Hadoop意味著HBase與生俱來的超強的擴充套件性和吞吐量。
HBase採用的時key/value的儲存方式,這意味著,及時隨著資料量的增大,也幾乎不會導致查詢效能的下降。HBase又是一個面向列儲存的資料庫,當表的欄位很多時,可以把其中幾個欄位獨立出來放在一部分機器上,而另外幾個欄位放到另一部分機器上,充分分散了負載的壓力。如此複雜的儲存結構和分散式的儲存方式,帶來的代價就是:即便是儲存很少的資料,也不會很快。
HBase並不是足夠快,而是資料量很大的時候它慢的不明顯。
什麼時候使用HBase呢,主要是以下兩種情況:
- 單表資料量超過千萬,而且併發量很大;
- 資料分析需求較弱,或者不需要那麼實時靈活。
參考資料:
[1] 李海波. 大資料技術之HBase
[2] 楊曦. HBase不睡覺