
【Python3爬蟲】反反爬之解決前端反除錯問題
一、前言
在我們爬取某些網站的時候,會想要開啟 DevTools 檢視元素或者抓包分析,但按下 F12 的時候,卻出現了下面這一幕:

此時網頁暫停載入,也就沒法執行程式碼了,直接中斷掉了,難道這就能阻止我們爬取了?不存在的,還是會有解決方案的。至於怎麼做,請慢慢往下看。
二、除錯
我們在瞭解程式碼的功能的時候,一般使用 JavaScript 除錯工具(例如 DevTools)通過設定斷點的方式來中斷或阻止指令碼程式碼的執行,而斷點也是程式碼除錯中最基本的了。
在 Chrome 中開啟 DevTools,切換到 Source 選項,找到 JS 檔案並開啟,左下角有一個“{}”代表格式化檔案,可以更方便地檢視程式碼。然後就是設定斷點了,找到可能出現問題的地方打上斷點,再重新整理頁面,就可以直接滑鼠移動到相關變數名或者方法上面檢視它的值。如果想在執行到斷點位置執行其它邏輯,可以直接在console區域執行相關指令碼。
三、反除錯
反除錯就是在開啟 DevTools 的時候,就會出現“Paused in debugger”,這個 debugger 導致我們無法除錯 JS。
在反除錯中,有時候會將函式進行重定義,並且改變其行為,就會將某些資訊隱藏起來或者改變其中的一部分資訊。
除了進行重定義,有的會進行混淆,例如使用語法樹,還有的會進行加密,例如"_0x5219a6"這樣的變數名,能很好地隱藏資訊。
四、示例1
1.問題分析
一種簡單的反除錯措施是通過在程式碼中新增 debugger 實現,通過 debugger 阻止非法使用者除錯程式碼,讓其陷入死迴圈,甚至有的還會使用匿名函式,例如:
setInterval(function() { debugger }, 100);
開啟 DevTools 時就會出現“Paused in debugger”,網頁也就載入中斷了。
2.解決方案
這種問題解決起來還是很容易的,總結起來就是四個字:禁止斷點。
在 Source 頁面右側按鈕找到“Deactivate breakpoints”,或者使用快捷鍵 Ctrl + F8,如下圖:

除了這種解決方案,還可以找到 debugger 那一行,然後右鍵選擇“Never pause here”,就會出現一盒黃色的箭頭,如下圖:
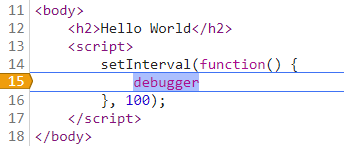
設定完之後,繼續執行程式碼就行了。
不過這種方案和程式碼的編寫風格有關係,例如下面這種情況,設定“Never pause here”就沒用了。
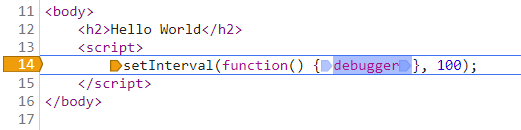
五、示例2
1.問題分析
複雜一點的反除錯措施就不是直接在程式碼中加入 debugger 了,而是將其隱藏起來,這樣就不會很輕易地被人發現了,例如下面這段程式碼:
function t() { try { var a = ["r", "e", "g", "g", "u", "b", "e", "d"].reverse().join(""); ! function e(n) { (1 !== ("" + n / n).length || 0 === n) && function() {} .constructor(a)(), e(++n) }(0) } catch (a) { setTimeout(t, 500) } }
這段程式碼首先是設定變數 a 表示字串“debugger”,然後使用 constructor() 來實現呼叫 debugger 方法,再使用 setTimeout 實現每0.5秒中斷一次。
2.解決方案
將反除錯具名函式重新定義一遍,然後重新開啟 DevTools,就能進行除錯了。對於上面的例子,可以在控制檯中輸入以下內容:
t = function() {}
通過下面的截圖可以發現我們確實已經修改了對於 t 的定義,因而也就不會進入 debugger 了:

相關推薦
【Python3爬蟲】反反爬之解決前端反除錯問題
一、前言 在我們爬取某些網站的時候,會想要開啟 DevTools 檢視元素或者抓包分析,但按下 F12 的時候,卻出現了下面這一幕: 此時網頁暫停載入,也就沒法執行程式碼了,直接中斷掉了,難道這就能阻止我們爬取了?不存在的,還是會有解決方案的。至於怎麼做,請慢慢往下看。
【Python3爬蟲】突破反爬之應對前端反除錯手段
一、前言 在我們爬取某些網站的時候,會想要開啟 DevTools 檢視元素或者抓包分析,但按下 F12 的時候,卻出現了下面這一幕: 此時網頁暫停載入,自動跳轉到 Source 頁面並打開了一個 JS 檔案,在右側可以看到 “Debugger paused&r
【Python3爬蟲】一次應對JS反除錯的記錄
一、前言簡介 在前面已經寫過關於 JS 反除錯的部落格了,地址為:https://www.cnblogs.com/TM0831/p/12154815.html。但這次碰到的網站就不一樣了,這個網站並不是通過不斷除錯消耗記憶體以反除錯的,而是直接將頁面替換修改掉,讓人無法除錯頁面。 二、
【Python3 爬蟲】06_robots.txt查看網站爬取限制情況
使用 mage none logs HR python3 clas 分享 處理 大多數網站都會定義robots.txt文件來限制爬蟲爬去信息,我們在爬去網站之前可以使用robots.txt來查看的相關限制信息例如:我們以【CSDN博客】的限制信息為例子在瀏覽器輸入:http
【Python3 爬蟲】爬取博客園首頁所有文章
表達式 技術 標記 itl 1.0 headers wow64 ignore windows 首先,我們確定博客園首頁地址為:https://www.cnblogs.com/ 我們打開可以看到有各種各樣的文章在首頁,如下圖: 我們以上圖標記的文章為例子吧!打開網頁源碼,搜
【Python3 爬蟲】14_爬取淘寶上的手機圖片
head 並且 淘寶網 pan coff urllib images 圖片列表 pic 現在我們想要使用爬蟲爬取淘寶上的手機圖片,那麽該如何爬取呢?該做些什麽準備工作呢? 首先,我們需要分析網頁,先看看網頁有哪些規律 打開淘寶網站http://www.taobao.com/
【Python3爬蟲】使用Fidder實現APP爬取
telerik tail 實現 鏈接 端口號 dpi () vco 軟件 之前爬取都是網頁上的數據,今天要來說一下怎麽借助Fidder來爬取手機APP上的數據。 一、環境配置 1、Fidder的安裝和配置 沒有安裝Fidder軟件的可以進入這個網址下載,然後就是傻瓜式的
【Python3爬蟲】爬取中國國家地理的62個《古鎮》和363張攝影照片
宣告:爬蟲為學習使用,請各位同學務必不要對當放網站或i伺服器造成傷害。務必不要寫死迴圈。 - 思路:古鎮——古鎮列表(迴圈獲取古鎮詳情href)——xx古鎮詳情(獲取所有img的src) - from bs4 import BeautifulSoup import u
【Python3爬蟲】Scrapy爬取豆瓣電影TOP250
今天要實現的就是使用是scrapy爬取豆瓣電影TOP250榜單上的電影資訊。 步驟如下: 一、爬取單頁資訊 首先是建立一個scrapy專案,在資料夾中按住shift然後點選滑鼠右鍵,選擇在此處開啟命令列視窗,輸入以下程式碼: scrapy startprojec
【Python3爬蟲】爬取美女圖新姿勢--Redis分散式爬蟲初體驗
一、寫在前面 之前寫的爬蟲都是單機爬蟲,還沒有嘗試過分散式爬蟲,這次就是一個分散式爬蟲的初體驗。所謂分散式爬蟲,就是要用多臺電腦同時爬取資料,相比於單機爬蟲,分散式爬蟲的爬取速度更快,也能更好地應對IP的檢測。本文介紹的是利用Redis資料庫實現的分散式爬蟲,Redis是一種常用的菲關係型資料庫,常用資料
【Python3爬蟲】我爬取了七萬條彈幕,看看RNG和SKT打得怎麼樣
一、寫在前面 直播行業已經火熱幾年了,幾個大平臺也有了各自獨特的“彈幕文化”,不過現在很多平臺直播比賽時的彈幕都基本沒法看的,主要是因為網路上的噴子還是挺多的,尤其是在觀看比賽的時候,很多彈幕不是噴選手就是噴戰隊,如果看了這種彈幕,真是讓比賽減分不少。 但和別的平臺
【Python3 爬蟲】04_urllib.request.urlretrieve
ont utf-8 html HA 觸發 request 效果 數量 class urllib模塊提供的urlretrieve()函數,urlretrieve()方法直接將遠程的數據下載到本地 urllib語法 參數url:傳入的網址,網址必須得是個字符串 參數filen
【Python3 爬蟲】Beautiful Soup庫的使用
attrs mouse 爬蟲 image 結構 定義 正則表達式 ttr document 之前學習了正則表達式,但是發現如果用正則表達式寫網絡爬蟲,那是相當的復雜啊!於是就有了Beautiful Soup簡單來說,Beautiful Soup是python的一個庫,最主要
【Python3爬蟲】有道翻譯
inpu handler ram lan chrome+ str sel text json 準備:Python3.5+Chrome+Pycharm 步驟: (1)打開有道翻譯的網頁,然後鼠標右鍵檢查(或者按F12),再輸入一個單詞(例如book),在XHR選項中可以看到這
【Python3爬蟲】網易雲音樂歌單下載
所有 我們 discover outer list with open 分析 roc spa 一、目標: 下載網易雲音樂熱門歌單 二、用到的模塊: requests,multiprocessing,re。 三、步驟: (1)頁面分析:首先打開網易雲音樂,
【Python3爬蟲】Scrapy+MongoDB+MySQL
error: 點擊 本機 scrapy pycharm except 數據存儲 arch pycha 分享一下兩個小爬蟲,都是用Scrapy寫的,一個用MongoDB保存,另一個用MySQL保存。 一、Scrapy+MongoDB 主要代碼: 在settings.
【Python3爬蟲】12306爬蟲
此次要實現的目標是登入12306網站和檢視火車票資訊。 具體步驟 一、登入 登入功能是通過使用selenium實現的,用到了超級鷹來識別驗證碼。沒有超級鷹賬號的先註冊一個賬號,充值一點題分,然後把下載這個Python介面檔案,再在裡面新增一個use_cjy的函式,以後使用的時候傳入檔名就
【Python3爬蟲】Scrapy使用IP代理池和隨機User-Agent
findall 4.3 sdch 5.0 agen and 由於 付費 status 在使用爬蟲的時候,有時候會看到由於目標計算機積極拒絕,無法連接...,這就是因為我們的爬蟲被識別出來了,而這種反爬蟲主要是通過IP識別的,針對這種反爬蟲,我們可以搭建一個自己的IP代理池,
【Python3爬蟲】拉勾網爬蟲
一、思路分析: 在之前寫拉勾網的爬蟲的時候,總是得到下面這個結果(真是頭疼),當你看到下面這個結果的時候,也就意味著被反爬了,因為一些網站會有相應的反爬蟲措施,例如很多網站會檢測某一段時間某個IP的訪問次數,如果訪問頻率太快以至於看起來不像正常訪客,它可能就會禁止這個IP的訪問: 對於拉勾網,我們要找
【python3爬蟲】beautifulsoup4 安裝
- 執行 pip install --user beautifulsoup4 安裝beautifulsoup4 - 執行 python -m pip install --user --upgrade pip 升級pip - Microsoft Windows [版本